An R Package for Normality in Stationary Processes
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Stationary Processes and Their Statistical Properties
Stationary Processes and Their Statistical Properties Brian Borchers March 29, 2001 1 Stationary processes A discrete time stochastic process is a sequence of random variables Z1, Z2, :::. In practice we will typically analyze a single realization z1, z2, :::, zn of the stochastic process and attempt to esimate the statistical properties of the stochastic process from the realization. We will also consider the problem of predicting zn+1 from the previous elements of the sequence. We will begin by focusing on the very important class of stationary stochas- tic processes. A stochastic process is strictly stationary if its statistical prop- erties are unaffected by shifting the stochastic process in time. In particular, this means that if we take a subsequence Zk+1, :::, Zk+m, then the joint distribution of the m random variables will be the same no matter what k is. Stationarity requires that the mean of the stochastic process be a constant. E[Zk] = µ. and that the variance is constant 2 V ar[Zk] = σZ : Also, stationarity requires that the covariance of two elements separated by a distance m is constant. That is, Cov(Zk;Zk+m) is constant. This covariance is called the autocovariance at lag m, and we will use the notation γm. Since Cov(Zk;Zk+m) = Cov(Zk+m;Zk), we need only find γm for m 0. The ≥ correlation of Zk and Zk+m is the autocorrelation at lag m. We will use the notation ρm for the autocorrelation. It is easy to show that γk ρk = : γ0 1 2 The autocovariance and autocorrelation ma- trices The covariance matrix for the random variables Z1, :::, Zn is called an auto- covariance matrix. -

Methods of Monte Carlo Simulation II
Methods of Monte Carlo Simulation II Ulm University Institute of Stochastics Lecture Notes Dr. Tim Brereton Summer Term 2014 Ulm, 2014 2 Contents 1 SomeSimpleStochasticProcesses 7 1.1 StochasticProcesses . 7 1.2 RandomWalks .......................... 7 1.2.1 BernoulliProcesses . 7 1.2.2 RandomWalks ...................... 10 1.2.3 ProbabilitiesofRandomWalks . 13 1.2.4 Distribution of Xn .................... 13 1.2.5 FirstPassageTime . 14 2 Estimators 17 2.1 Bias, Variance, the Central Limit Theorem and Mean Square Error................................ 19 2.2 Non-AsymptoticErrorBounds. 22 2.3 Big O and Little o Notation ................... 23 3 Markov Chains 25 3.1 SimulatingMarkovChains . 28 3.1.1 Drawing from a Discrete Uniform Distribution . 28 3.1.2 Drawing From A Discrete Distribution on a Small State Space ........................... 28 3.1.3 SimulatingaMarkovChain . 28 3.2 Communication .......................... 29 3.3 TheStrongMarkovProperty . 30 3.4 RecurrenceandTransience . 31 3.4.1 RecurrenceofRandomWalks . 33 3.5 InvariantDistributions . 34 3.6 LimitingDistribution. 36 3.7 Reversibility............................ 37 4 The Poisson Process 39 4.1 Point Processes on [0, )..................... 39 ∞ 3 4 CONTENTS 4.2 PoissonProcess .......................... 41 4.2.1 Order Statistics and the Distribution of Arrival Times 44 4.2.2 DistributionofArrivalTimes . 45 4.3 SimulatingPoissonProcesses. 46 4.3.1 Using the Infinitesimal Definition to Simulate Approx- imately .......................... 46 4.3.2 SimulatingtheArrivalTimes . 47 4.3.3 SimulatingtheInter-ArrivalTimes . 48 4.4 InhomogenousPoissonProcesses. 48 4.5 Simulating an Inhomogenous Poisson Process . 49 4.5.1 Acceptance-Rejection. 49 4.5.2 Infinitesimal Approach (Approximate) . 50 4.6 CompoundPoissonProcesses . 51 5 ContinuousTimeMarkovChains 53 5.1 TransitionFunction. 53 5.2 InfinitesimalGenerator . 54 5.3 ContinuousTimeMarkovChains . -
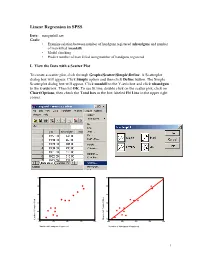
Linear Regression in SPSS
Linear Regression in SPSS Data: mangunkill.sav Goals: • Examine relation between number of handguns registered (nhandgun) and number of man killed (mankill) • Model checking • Predict number of man killed using number of handguns registered I. View the Data with a Scatter Plot To create a scatter plot, click through Graphs\Scatter\Simple\Define. A Scatterplot dialog box will appear. Click Simple option and then click Define button. The Simple Scatterplot dialog box will appear. Click mankill to the Y-axis box and click nhandgun to the x-axis box. Then hit OK. To see fit line, double click on the scatter plot, click on Chart\Options, then check the Total box in the box labeled Fit Line in the upper right corner. 60 60 50 50 40 40 30 30 20 20 10 10 Killed of People Number Number of People Killed 400 500 600 700 800 400 500 600 700 800 Number of Handguns Registered Number of Handguns Registered 1 Click the target button on the left end of the tool bar, the mouse pointer will change shape. Move the target pointer to the data point and click the left mouse button, the case number of the data point will appear on the chart. This will help you to identify the data point in your data sheet. II. Regression Analysis To perform the regression, click on Analyze\Regression\Linear. Place nhandgun in the Dependent box and place mankill in the Independent box. To obtain the 95% confidence interval for the slope, click on the Statistics button at the bottom and then put a check in the box for Confidence Intervals. -

Examples of Stationary Time Series
Statistics 910, #2 1 Examples of Stationary Time Series Overview 1. Stationarity 2. Linear processes 3. Cyclic models 4. Nonlinear models Stationarity Strict stationarity (Defn 1.6) Probability distribution of the stochastic process fXtgis invariant under a shift in time, P (Xt1 ≤ x1;Xt2 ≤ x2;:::;Xtk ≤ xk) = F (xt1 ; xt2 ; : : : ; xtk ) = F (xh+t1 ; xh+t2 ; : : : ; xh+tk ) = P (Xh+t1 ≤ x1;Xh+t2 ≤ x2;:::;Xh+tk ≤ xk) for any time shift h and xj. Weak stationarity (Defn 1.7) (aka, second-order stationarity) The mean and autocovariance of the stochastic process are finite and invariant under a shift in time, E Xt = µt = µ Cov(Xt;Xs) = E (Xt−µt)(Xs−µs) = γ(t; s) = γ(t−s) The separation rather than location in time matters. Equivalence If the process is Gaussian with finite second moments, then weak stationarity is equivalent to strong stationarity. Strict stationar- ity implies weak stationarity only if the necessary moments exist. Relevance Stationarity matters because it provides a framework in which averaging makes sense. Unless properties like the mean and covariance are either fixed or \evolve" in a known manner, we cannot average the observed data. What operations produce a stationary process? Can we recognize/identify these in data? Statistics 910, #2 2 Moving Average White noise Sequence of uncorrelated random variables with finite vari- ance, ( 2 often often σw = 1 if t = s; E Wt = µ = 0 Cov(Wt;Ws) = 0 otherwise The input component (fXtg in what follows) is often modeled as white noise. Strict white noise replaces uncorrelated by independent. Moving average A stochastic process formed by taking a weighted average of another time series, often formed from white noise. -

Stationary Processes
Stationary processes Alejandro Ribeiro Dept. of Electrical and Systems Engineering University of Pennsylvania [email protected] http://www.seas.upenn.edu/users/~aribeiro/ November 25, 2019 Stoch. Systems Analysis Stationary processes 1 Stationary stochastic processes Stationary stochastic processes Autocorrelation function and wide sense stationary processes Fourier transforms Linear time invariant systems Power spectral density and linear filtering of stochastic processes Stoch. Systems Analysis Stationary processes 2 Stationary stochastic processes I All probabilities are invariant to time shits, i.e., for any s P[X (t1 + s) ≥ x1; X (t2 + s) ≥ x2;:::; X (tK + s) ≥ xK ] = P[X (t1) ≥ x1; X (t2) ≥ x2;:::; X (tK ) ≥ xK ] I If above relation is true process is called strictly stationary (SS) I First order stationary ) probs. of single variables are shift invariant P[X (t + s) ≥ x] = P [X (t) ≥ x] I Second order stationary ) joint probs. of pairs are shift invariant P[X (t1 + s) ≥ x1; X (t2 + s) ≥ x2] = P [X (t1) ≥ x1; X (t2) ≥ x2] Stoch. Systems Analysis Stationary processes 3 Pdfs and moments of stationary process I For SS process joint cdfs are shift invariant. Whereby, pdfs also are fX (t+s)(x) = fX (t)(x) = fX (0)(x) := fX (x) I As a consequence, the mean of a SS process is constant Z 1 Z 1 µ(t) := E [X (t)] = xfX (t)(x) = xfX (x) = µ −∞ −∞ I The variance of a SS process is also constant Z 1 Z 1 2 2 2 var [X (t)] := (x − µ) fX (t)(x) = (x − µ) fX (x) = σ −∞ −∞ I The power of a SS process (second moment) is also constant Z 1 Z 1 2 2 2 2 2 E X (t) := x fX (t)(x) = x fX (x) = σ + µ −∞ −∞ Stoch. -

Solutions to Exercises in Stationary Stochastic Processes for Scientists and Engineers by Lindgren, Rootzén and Sandsten Chapman & Hall/CRC, 2013
Solutions to exercises in Stationary stochastic processes for scientists and engineers by Lindgren, Rootzén and Sandsten Chapman & Hall/CRC, 2013 Georg Lindgren, Johan Sandberg, Maria Sandsten 2017 CENTRUM SCIENTIARUM MATHEMATICARUM Faculty of Engineering Centre for Mathematical Sciences Mathematical Statistics 1 Solutions to exercises in Stationary stochastic processes for scientists and engineers Mathematical Statistics Centre for Mathematical Sciences Lund University Box 118 SE-221 00 Lund, Sweden http://www.maths.lu.se c Georg Lindgren, Johan Sandberg, Maria Sandsten, 2017 Contents Preface v 2 Stationary processes 1 3 The Poisson process and its relatives 5 4 Spectral representations 9 5 Gaussian processes 13 6 Linear filters – general theory 17 7 AR, MA, and ARMA-models 21 8 Linear filters – applications 25 9 Frequency analysis and spectral estimation 29 iii iv CONTENTS Preface This booklet contains hints and solutions to exercises in Stationary stochastic processes for scientists and engineers by Georg Lindgren, Holger Rootzén, and Maria Sandsten, Chapman & Hall/CRC, 2013. The solutions have been adapted from course material used at Lund University on first courses in stationary processes for students in engineering programs as well as in mathematics, statistics, and science programs. The web page for the course during the fall semester 2013 gives an example of a schedule for a seven week period: http://www.maths.lu.se/matstat/kurser/fms045mas210/ Note that the chapter references in the material from the Lund University course do not exactly agree with those in the printed volume. v vi CONTENTS Chapter 2 Stationary processes 2:1. (a) 1, (b) a + b, (c) 13, (d) a2 + b2, (e) a2 + b2, (f) 1. -

Random Processes
Chapter 6 Random Processes Random Process • A random process is a time-varying function that assigns the outcome of a random experiment to each time instant: X(t). • For a fixed (sample path): a random process is a time varying function, e.g., a signal. – For fixed t: a random process is a random variable. • If one scans all possible outcomes of the underlying random experiment, we shall get an ensemble of signals. • Random Process can be continuous or discrete • Real random process also called stochastic process – Example: Noise source (Noise can often be modeled as a Gaussian random process. An Ensemble of Signals Remember: RV maps Events à Constants RP maps Events à f(t) RP: Discrete and Continuous The set of all possible sample functions {v(t, E i)} is called the ensemble and defines the random process v(t) that describes the noise source. Sample functions of a binary random process. RP Characterization • Random variables x 1 , x 2 , . , x n represent amplitudes of sample functions at t 5 t 1 , t 2 , . , t n . – A random process can, therefore, be viewed as a collection of an infinite number of random variables: RP Characterization – First Order • CDF • PDF • Mean • Mean-Square Statistics of a Random Process RP Characterization – Second Order • The first order does not provide sufficient information as to how rapidly the RP is changing as a function of timeà We use second order estimation RP Characterization – Second Order • The first order does not provide sufficient information as to how rapidly the RP is changing as a function -

4.2 Autoregressive (AR) Moving Average Models Are Causal Linear Processes by Definition. There Is Another Class of Models, Based
4.2 Autoregressive (AR) Moving average models are causal linear processes by definition. There is another class of models, based on a recursive formulation similar to the exponentially weighted moving average. Definition 4.11 (Autoregressive AR(p)). Suppose φ1,...,φp ∈ R are constants 2 2 and (Wi) ∼ WN(σ ). The AR(p) process with parameters σ , φ1,...,φp is defined through p Xi = Wi + φjXi−j, (3) Xj=1 whenever such stationary process (Xi) exists. Remark 4.12. The process in Definition 4.11 is sometimes called a stationary AR(p) process. It is possible to consider a ‘non-stationary AR(p) process’ for any φ1,...,φp satisfying (3) for i ≥ 0 by letting for example Xi = 0 for i ∈ [−p+1, 0]. Example 4.13 (Variance and autocorrelation of AR(1) process). For the AR(1) process, whenever it exits, we must have 2 2 γ0 = Var(Xi) = Var(φ1Xi−1 + Wi)= φ1γ0 + σ , which implies that we must have |φ1| < 1, and σ2 γ0 = 2 . 1 − φ1 We may also calculate for j ≥ 1 j γj = E[XiXi−j]= E[(φ1Xi−1 + Wi)Xi−j]= φ1E[Xi−1Xi−j]= φ1γ0, j which gives that ρj = φ1. Example 4.14. Simulation of an AR(1) process. phi_1 <- 0.7 x <- arima.sim(model=list(ar=phi_1), 140) # This is the explicit simulation: gamma_0 <- 1/(1-phi_1^2) x_0 <- rnorm(1)*sqrt(gamma_0) x <- filter(rnorm(140), phi_1, method = "r", init = x_0) Example 4.15. Consider a stationary AR(1) process. We may write n−1 n j Xi = φ1Xi−1 + Wi = ··· = φ1 Xi−n + φ1Wi−j. -

A Robust Rescaled Moment Test for Normality in Regression
Journal of Mathematics and Statistics 5 (1): 54-62, 2009 ISSN 1549-3644 © 2009 Science Publications A Robust Rescaled Moment Test for Normality in Regression 1Md.Sohel Rana, 1Habshah Midi and 2A.H.M. Rahmatullah Imon 1Laboratory of Applied and Computational Statistics, Institute for Mathematical Research, University Putra Malaysia, 43400 Serdang, Selangor, Malaysia 2Department of Mathematical Sciences, Ball State University, Muncie, IN 47306, USA Abstract: Problem statement: Most of the statistical procedures heavily depend on normality assumption of observations. In regression, we assumed that the random disturbances were normally distributed. Since the disturbances were unobserved, normality tests were done on regression residuals. But it is now evident that normality tests on residuals suffer from superimposed normality and often possess very poor power. Approach: This study showed that normality tests suffer huge set back in the presence of outliers. We proposed a new robust omnibus test based on rescaled moments and coefficients of skewness and kurtosis of residuals that we call robust rescaled moment test. Results: Numerical examples and Monte Carlo simulations showed that this proposed test performs better than the existing tests for normality in the presence of outliers. Conclusion/Recommendation: We recommend using our proposed omnibus test instead of the existing tests for checking the normality of the regression residuals. Key words: Regression residuals, outlier, rescaled moments, skewness, kurtosis, jarque-bera test, robust rescaled moment test INTRODUCTION out that the powers of t and F tests are extremely sensitive to the hypothesized error distribution and may In regression analysis, it is a common practice over deteriorate very rapidly as the error distribution the years to use the Ordinary Least Squares (OLS) becomes long-tailed. -

Interacting Particle Systems MA4H3
Interacting particle systems MA4H3 Stefan Grosskinsky Warwick, 2009 These notes and other information about the course are available on http://www.warwick.ac.uk/˜masgav/teaching/ma4h3.html Contents Introduction 2 1 Basic theory3 1.1 Continuous time Markov chains and graphical representations..........3 1.2 Two basic IPS....................................6 1.3 Semigroups and generators.............................9 1.4 Stationary measures and reversibility........................ 13 2 The asymmetric simple exclusion process 18 2.1 Stationary measures and conserved quantities................... 18 2.2 Currents and conservation laws........................... 23 2.3 Hydrodynamics and the dynamic phase transition................. 26 2.4 Open boundaries and matrix product ansatz.................... 30 3 Zero-range processes 34 3.1 From ASEP to ZRPs................................ 34 3.2 Stationary measures................................. 36 3.3 Equivalence of ensembles and relative entropy................... 39 3.4 Phase separation and condensation......................... 43 4 The contact process 46 4.1 Mean field rate equations.............................. 46 4.2 Stochastic monotonicity and coupling....................... 48 4.3 Invariant measures and critical values....................... 51 d 4.4 Results for Λ = Z ................................. 54 1 Introduction Interacting particle systems (IPS) are models for complex phenomena involving a large number of interrelated components. Examples exist within all areas of natural and social sciences, such as traffic flow on highways, pedestrians or constituents of a cell, opinion dynamics, spread of epi- demics or fires, reaction diffusion systems, crystal surface growth, chemotaxis, financial markets... Mathematically the components are modeled as particles confined to a lattice or some discrete geometry. Their motion and interaction is governed by local rules. Often microscopic influences are not accesible in full detail and are modeled as effective noise with some postulated distribution. -

Lecture 1: Stationary Time Series∗
Lecture 1: Stationary Time Series∗ 1 Introduction If a random variable X is indexed to time, usually denoted by t, the observations {Xt, t ∈ T} is called a time series, where T is a time index set (for example, T = Z, the integer set). Time series data are very common in empirical economic studies. Figure 1 plots some frequently used variables. The upper left figure plots the quarterly GDP from 1947 to 2001; the upper right figure plots the the residuals after linear-detrending the logarithm of GDP; the lower left figure plots the monthly S&P 500 index data from 1990 to 2001; and the lower right figure plots the log difference of the monthly S&P. As you could see, these four series display quite different patterns over time. Investigating and modeling these different patterns is an important part of this course. In this course, you will find that many of the techniques (estimation methods, inference proce- dures, etc) you have learned in your general econometrics course are still applicable in time series analysis. However, there are something special of time series data compared to cross sectional data. For example, when working with cross-sectional data, it usually makes sense to assume that the observations are independent from each other, however, time series data are very likely to display some degree of dependence over time. More importantly, for time series data, we could observe only one history of the realizations of this variable. For example, suppose you obtain a series of US weekly stock index data for the last 50 years. -

Testing Normality: a GMM Approach Christian Bontempsa and Nour
Testing Normality: A GMM Approach Christian Bontempsa and Nour Meddahib∗ a LEEA-CENA, 7 avenue Edouard Belin, 31055 Toulouse Cedex, France. b D´epartement de sciences ´economiques, CIRANO, CIREQ, Universit´ede Montr´eal, C.P. 6128, succursale Centre-ville, Montr´eal (Qu´ebec), H3C 3J7, Canada. First version: March 2001 This version: June 2003 Abstract In this paper, we consider testing marginal normal distributional assumptions. More precisely, we propose tests based on moment conditions implied by normality. These moment conditions are known as the Stein (1972) equations. They coincide with the first class of moment conditions derived by Hansen and Scheinkman (1995) when the random variable of interest is a scalar diffusion. Among other examples, Stein equation implies that the mean of Hermite polynomials is zero. The GMM approach we adopt is well suited for two reasons. It allows us to study in detail the parameter uncertainty problem, i.e., when the tests depend on unknown parameters that have to be estimated. In particular, we characterize the moment conditions that are robust against parameter uncertainty and show that Hermite polynomials are special examples. This is the main contribution of the paper. The second reason for using GMM is that our tests are also valid for time series. In this case, we adopt a Heteroskedastic-Autocorrelation-Consistent approach to estimate the weighting matrix when the dependence of the data is unspecified. We also make a theoretical comparison of our tests with Jarque and Bera (1980) and OPG regression tests of Davidson and MacKinnon (1993). Finite sample properties of our tests are derived through a comprehensive Monte Carlo study.