NERO: a Near High-Bandwidth Memory Stencil Accelerator for Weather Prediction Modeling
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
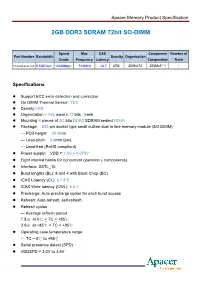
2GB DDR3 SDRAM 72Bit SO-DIMM
Apacer Memory Product Specification 2GB DDR3 SDRAM 72bit SO-DIMM Speed Max CAS Component Number of Part Number Bandwidth Density Organization Grade Frequency Latency Composition Rank 0C 78.A2GCB.AF10C 8.5GB/sec 1066Mbps 533MHz CL7 2GB 256Mx72 256Mx8 * 9 1 Specifications z Support ECC error detection and correction z On DIMM Thermal Sensor: YES z Density:2GB z Organization – 256 word x 72 bits, 1rank z Mounting 9 pieces of 2G bits DDR3 SDRAM sealed FBGA z Package: 204-pin socket type small outline dual in line memory module (SO-DIMM) --- PCB height: 30.0mm --- Lead pitch: 0.6mm (pin) --- Lead-free (RoHS compliant) z Power supply: VDD = 1.5V + 0.075V z Eight internal banks for concurrent operation ( components) z Interface: SSTL_15 z Burst lengths (BL): 8 and 4 with Burst Chop (BC) z /CAS Latency (CL): 6,7,8,9 z /CAS Write latency (CWL): 5,6,7 z Precharge: Auto precharge option for each burst access z Refresh: Auto-refresh, self-refresh z Refresh cycles --- Average refresh period 7.8㎲ at 0℃ < TC < +85℃ 3.9㎲ at +85℃ < TC < +95℃ z Operating case temperature range --- TC = 0℃ to +95℃ z Serial presence detect (SPD) z VDDSPD = 3.0V to 3.6V Apacer Memory Product Specification Features z Double-data-rate architecture; two data transfers per clock cycle. z The high-speed data transfer is realized by the 8 bits prefetch pipelined architecture. z Bi-directional differential data strobe (DQS and /DQS) is transmitted/received with data for capturing data at the receiver. z DQS is edge-aligned with data for READs; center aligned with data for WRITEs. -

Performance Impact of Memory Channels on Sparse and Irregular Algorithms
Performance Impact of Memory Channels on Sparse and Irregular Algorithms Oded Green1,2, James Fox2, Jeffrey Young2, Jun Shirako2, and David Bader3 1NVIDIA Corporation — 2Georgia Institute of Technology — 3New Jersey Institute of Technology Abstract— Graph processing is typically considered to be a Graph algorithms are typically latency-bound if there is memory-bound rather than compute-bound problem. One com- not enough parallelism to saturate the memory subsystem. mon line of thought is that more available memory bandwidth However, the growth in parallelism for shared-memory corresponds to better graph processing performance. However, in this work we demonstrate that the key factor in the utilization systems brings into question whether graph algorithms are of the memory system for graph algorithms is not necessarily still primarily latency-bound. Getting peak or near-peak the raw bandwidth or even the latency of memory requests. bandwidth of current memory subsystems requires highly Instead, we show that performance is proportional to the parallel applications as well as good spatial and temporal number of memory channels available to handle small data memory reuse. The lack of spatial locality in sparse and transfers with limited spatial locality. Using several widely used graph frameworks, including irregular algorithms means that prefetched cache lines have Gunrock (on the GPU) and GAPBS & Ligra (for CPUs), poor data reuse and that the effective bandwidth is fairly low. we evaluate key graph analytics kernels using two unique The introduction of high-bandwidth memories like HBM and memory hierarchies, DDR-based and HBM/MCDRAM. Our HMC have not yet closed this inefficiency gap for latency- results show that the differences in the peak bandwidths sensitive accesses [19]. -

Different Types of RAM RAM RAM Stands for Random Access Memory. It Is Place Where Computer Stores Its Operating System. Applicat
Different types of RAM RAM RAM stands for Random Access Memory. It is place where computer stores its Operating System. Application Program and current data. when you refer to computer memory they mostly it mean RAM. The two main forms of modern RAM are Static RAM (SRAM) and Dynamic RAM (DRAM). DRAM memories (Dynamic Random Access Module), which are inexpensive . They are used essentially for the computer's main memory SRAM memories(Static Random Access Module), which are fast and costly. SRAM memories are used in particular for the processer's cache memory. Early memories existed in the form of chips called DIP (Dual Inline Package). Nowaday's memories generally exist in the form of modules, which are cards that can be plugged into connectors for this purpose. They are generally three types of RAM module they are 1. DIP 2. SIMM 3. DIMM 4. SDRAM 1. DIP(Dual In Line Package) Older computer systems used DIP memory directely, either soldering it to the motherboard or placing it in sockets that had been soldered to the motherboard. Most memory chips are packaged into small plastic or ceramic packages called dual inline packages or DIPs . A DIP is a rectangular package with rows of pins running along its two longer edges. These are the small black boxes you see on SIMMs, DIMMs or other larger packaging styles. However , this arrangment caused many problems. Chips inserted into sockets suffered reliability problems as the chips would (over time) tend to work their way out of the sockets. 2. SIMM A SIMM, or single in-line memory module, is a type of memory module containing random access memory used in computers from the early 1980s to the late 1990s . -

Product Guide SAMSUNG ELECTRONICS RESERVES the RIGHT to CHANGE PRODUCTS, INFORMATION and SPECIFICATIONS WITHOUT NOTICE
May. 2018 DDR4 SDRAM Memory Product Guide SAMSUNG ELECTRONICS RESERVES THE RIGHT TO CHANGE PRODUCTS, INFORMATION AND SPECIFICATIONS WITHOUT NOTICE. Products and specifications discussed herein are for reference purposes only. All information discussed herein is provided on an "AS IS" basis, without warranties of any kind. This document and all information discussed herein remain the sole and exclusive property of Samsung Electronics. No license of any patent, copyright, mask work, trademark or any other intellectual property right is granted by one party to the other party under this document, by implication, estoppel or other- wise. Samsung products are not intended for use in life support, critical care, medical, safety equipment, or similar applications where product failure could result in loss of life or personal or physical harm, or any military or defense application, or any governmental procurement to which special terms or provisions may apply. For updates or additional information about Samsung products, contact your nearest Samsung office. All brand names, trademarks and registered trademarks belong to their respective owners. © 2018 Samsung Electronics Co., Ltd. All rights reserved. - 1 - May. 2018 Product Guide DDR4 SDRAM Memory 1. DDR4 SDRAM MEMORY ORDERING INFORMATION 1 2 3 4 5 6 7 8 9 10 11 K 4 A X X X X X X X - X X X X SAMSUNG Memory Speed DRAM Temp & Power DRAM Type Package Type Density Revision Bit Organization Interface (VDD, VDDQ) # of Internal Banks 1. SAMSUNG Memory : K 8. Revision M: 1st Gen. A: 2nd Gen. 2. DRAM : 4 B: 3rd Gen. C: 4th Gen. D: 5th Gen. -

Dual-DIMM DDR2 and DDR3 SDRAM Board Design Guidelines, External
5. Dual-DIMM DDR2 and DDR3 SDRAM Board Design Guidelines June 2012 EMI_DG_005-4.1 EMI_DG_005-4.1 This chapter describes guidelines for implementing dual unbuffered DIMM (UDIMM) DDR2 and DDR3 SDRAM interfaces. This chapter discusses the impact on signal integrity of the data signal with the following conditions in a dual-DIMM configuration: ■ Populating just one slot versus populating both slots ■ Populating slot 1 versus slot 2 when only one DIMM is used ■ On-die termination (ODT) setting of 75 Ω versus an ODT setting of 150 Ω f For detailed information about a single-DIMM DDR2 SDRAM interface, refer to the DDR2 and DDR3 SDRAM Board Design Guidelines chapter. DDR2 SDRAM This section describes guidelines for implementing a dual slot unbuffered DDR2 SDRAM interface, operating at up to 400-MHz and 800-Mbps data rates. Figure 5–1 shows a typical DQS, DQ, and DM signal topology for a dual-DIMM interface configuration using the ODT feature of the DDR2 SDRAM components. Figure 5–1. Dual-DIMM DDR2 SDRAM Interface Configuration (1) VTT Ω RT = 54 DDR2 SDRAM DIMMs (Receiver) Board Trace FPGA Slot 1 Slot 2 (Driver) Board Trace Board Trace Note to Figure 5–1: (1) The parallel termination resistor RT = 54 Ω to VTT at the FPGA end of the line is optional for devices that support dynamic on-chip termination (OCT). © 2012 Altera Corporation. All rights reserved. ALTERA, ARRIA, CYCLONE, HARDCOPY, MAX, MEGACORE, NIOS, QUARTUS and STRATIX words and logos are trademarks of Altera Corporation and registered in the U.S. Patent and Trademark Office and in other countries. -

Case Study on Integrated Architecture for In-Memory and In-Storage Computing
electronics Article Case Study on Integrated Architecture for In-Memory and In-Storage Computing Manho Kim 1, Sung-Ho Kim 1, Hyuk-Jae Lee 1 and Chae-Eun Rhee 2,* 1 Department of Electrical Engineering, Seoul National University, Seoul 08826, Korea; [email protected] (M.K.); [email protected] (S.-H.K.); [email protected] (H.-J.L.) 2 Department of Information and Communication Engineering, Inha University, Incheon 22212, Korea * Correspondence: [email protected]; Tel.: +82-32-860-7429 Abstract: Since the advent of computers, computing performance has been steadily increasing. Moreover, recent technologies are mostly based on massive data, and the development of artificial intelligence is accelerating it. Accordingly, various studies are being conducted to increase the performance and computing and data access, together reducing energy consumption. In-memory computing (IMC) and in-storage computing (ISC) are currently the most actively studied architectures to deal with the challenges of recent technologies. Since IMC performs operations in memory, there is a chance to overcome the memory bandwidth limit. ISC can reduce energy by using a low power processor inside storage without an expensive IO interface. To integrate the host CPU, IMC and ISC harmoniously, appropriate workload allocation that reflects the characteristics of the target application is required. In this paper, the energy and processing speed are evaluated according to the workload allocation and system conditions. The proof-of-concept prototyping system is implemented for the integrated architecture. The simulation results show that IMC improves the performance by 4.4 times and reduces total energy by 4.6 times over the baseline host CPU. -

ECE 571 – Advanced Microprocessor-Based Design Lecture 17
ECE 571 { Advanced Microprocessor-Based Design Lecture 17 Vince Weaver http://web.eece.maine.edu/~vweaver [email protected] 3 April 2018 Announcements • HW8 is readings 1 More DRAM 2 ECC Memory • There's debate about how many errors can happen, anywhere from 10−10 error/bit*h (roughly one bit error per hour per gigabyte of memory) to 10−17 error/bit*h (roughly one bit error per millennium per gigabyte of memory • Google did a study and they found more toward the high end • Would you notice if you had a bit flipped? • Scrubbing { only notice a flip once you read out a value 3 Registered Memory • Registered vs Unregistered • Registered has a buffer on board. More expensive but can have more DIMMs on a channel • Registered may be slower (if it buffers for a cycle) • RDIMM/UDIMM 4 Bandwidth/Latency Issues • Truly random access? No, burst speed fast, random speed not. • Is that a problem? Mostly filling cache lines? 5 Memory Controller • Can we have full random access to memory? Why not just pass on CPU mem requests unchanged? • What might have higher priority? • Why might re-ordering the accesses help performance (back and forth between two pages) 6 Reducing Refresh • DRAM Refresh Mechanisms, Penalties, and Trade-Offs by Bhati et al. • Refresh hurts performance: ◦ Memory controller stalls access to memory being refreshed ◦ Refresh takes energy (read/write) On 32Gb device, up to 20% of energy consumption and 30% of performance 7 Async vs Sync Refresh • Traditional refresh rates ◦ Async Standard (15.6us) ◦ Async Extended (125us) ◦ SDRAM - -

Adm-Pcie-9H3 V1.5
ADM-PCIE-9H3 10th September 2019 Datasheet Revision: 1.5 AD01365 Applications Board Features • High-Performance Network Accelerator • 1x OpenCAPI Interface • Data CenterData Processor • 1x QSFP-DD Cages • High Performance Computing (HPC) • Shrouded heatsink with passive and fan cooling • System Modelling options • Market Analysis FPGA Features • 2x 4GB HBM Gen2 memory (32 AXI Ports provide 460GB/s Access Bandwidth) • 3x 100G Ethernet MACs (incl. KR4 RS-FEC) • 3x 150G Interlaken cores • 2x PCI Express x16 Gen3 / x8 Gen4 cores Summary The ADM-PCIE-9H3 is a high-performance FPGA processing card intended for data center applications using Virtex UltraScale+ High Bandwidth Memory FPGAs from Xilinx. The ADM-PCIE-9H3 utilises the Xilinx Virtex Ultrascale Plus FPGA family that includes on substrate High Bandwidth Memory (HBM Gen2). This provides exceptional memory Read/Write performance while reducing the overall power consumption of the board by negating the need for external SDRAM devices. There are also a number of high speed interface options available including 100G Ethernet MACs and OpenCAPI connectivity, to make the most of these interfaces the ADM-PCIE-9H3 is fitted with a QSFP-DD Cage (8x28Gbps lanes) and one OpenCAPI interface for ultra low latency communications. Target Device Host Interface Xilinx Virtex UltraScale Plus: XCVU33P-2E 1x PCI Express Gen3 x16 or 1x/2x* PCI Express (FSVH2104) Gen4 x8 or OpenCAPI LUTs = 440k(872k) Board Format FFs = 879k(1743k) DSPs = 2880(5952) 1/2 Length low profile x16 PCIe form Factor BRAM = 23.6Mb(47.3Mb) WxHxD = 19.7mm x 80.1mm x 181.5mm URAM = 90.0Mb(180.0Mb) Weight = TBCg 2x 4GB HBM Gen2 memory (32 AXI Ports Communications Interfaces provide 460GB/s Access Bandwidth) 1x QSFP-DD 8x28Gbps - 10/25/40/100G 3x 100G Ethernet MACs (incl. -

High Bandwidth Memory for Graphics Applications Contents
High Bandwidth Memory for Graphics Applications Contents • Differences in Requirements: System Memory vs. Graphics Memory • Timeline of Graphics Memory Standards • GDDR2 • GDDR3 • GDDR4 • GDDR5 SGRAM • Problems with GDDR • Solution ‐ Introduction to HBM • Performance comparisons with GDDR5 • Benchmarks • Hybrid Memory Cube Differences in Requirements System Memory Graphics Memory • Optimized for low latency • Optimized for high bandwidth • Short burst vector loads • Long burst vector loads • Equal read/write latency ratio • Low read/write latency ratio • Very general solutions and designs • Designs can be very haphazard Brief History of Graphics Memory Types • Ancient History: VRAM, WRAM, MDRAM, SGRAM • Bridge to modern times: GDDR2 • The first modern standard: GDDR4 • Rapidly outclassed: GDDR4 • Current state: GDDR5 GDDR2 • First implemented with Nvidia GeForce FX 5800 (2003) • Midway point between DDR and ‘true’ DDR2 • Stepping stone towards DDR‐based graphics memory • Second‐generation GDDR2 based on DDR2 GDDR3 • Designed by ATI Technologies , first used by Nvidia GeForce FX 5700 (2004) • Based off of the same technological base as DDR2 • Lower heat and power consumption • Uses internal terminators and a 32‐bit bus GDDR4 • Based on DDR3, designed by Samsung from 2005‐2007 • Introduced Data Bus Inversion (DBI) • Doubled prefetch size to 8n • Used on ATI Radeon 2xxx and 3xxx, never became commercially viable GDDR5 SGRAM • Based on DDR3 SDRAM memory • Inherits benefits of GDDR4 • First used in AMD Radeon HD 4870 video cards (2008) • Current -

Architectures for High Performance Computing and Data Systems Using Byte-Addressable Persistent Memory
Architectures for High Performance Computing and Data Systems using Byte-Addressable Persistent Memory Adrian Jackson∗, Mark Parsonsy, Michele` Weilandz EPCC, The University of Edinburgh Edinburgh, United Kingdom ∗[email protected], [email protected], [email protected] Bernhard Homolle¨ x SVA System Vertrieb Alexander GmbH Paderborn, Germany x [email protected] Abstract—Non-volatile, byte addressable, memory technology example of such hardware, used for data storage. More re- with performance close to main memory promises to revolutionise cently, flash memory has been used for high performance I/O computing systems in the near future. Such memory technology in the form of Solid State Disk (SSD) drives, providing higher provides the potential for extremely large memory regions (i.e. > 3TB per server), very high performance I/O, and new ways bandwidth and lower latency than traditional Hard Disk Drives of storing and sharing data for applications and workflows. (HDD). This paper outlines an architecture that has been designed to Whilst flash memory can provide fast input/output (I/O) exploit such memory for High Performance Computing and High performance for computer systems, there are some draw backs. Performance Data Analytics systems, along with descriptions of It has limited endurance when compare to HDD technology, how applications could benefit from such hardware. Index Terms—Non-volatile memory, persistent memory, stor- restricted by the number of modifications a memory cell age class memory, system architecture, systemware, NVRAM, can undertake and thus the effective lifetime of the flash SCM, B-APM storage [29]. It is often also more expensive than other storage technologies. -

DDR3 SODIMM Product Datasheet
DDR3 SODIMM Product Datasheet 廣 穎 電 通 股 份 有 限 公 司 Silicon Power Computer & Communications Inc. TEL: 886-2 8797-8833 FAX: 886-2 8751-6595 台北市114內湖區洲子街106號7樓 7F, No.106, ZHO-Z ST. NEIHU DIST, 114, TAIPEI, TAIWAN, R.O.C This document is a general product description and is subject to change without notice DDR3 SODIMM Product Datasheet Index Index...................................................................................................................................................................... 2 Revision History ................................................................................................................................................ 3 Description .......................................................................................................................................................... 4 Features ............................................................................................................................................................... 5 Pin Assignments................................................................................................................................................ 7 Pin Description................................................................................................................................................... 8 Environmental Requirements......................................................................................................................... 9 Absolute Maximum DC Ratings.................................................................................................................... -

DDR4 2400 R-DIMM / VLP R-DIMM / ECC U-DIMM / ECC SO-DIMM Features
DDR4 2400 R-DIMM / VLP R-DIMM / ECC U-DIMM / ECC SO-DIMM Available in densities ranging from 4GB to 16GB per module and clocked up to 2400MHz for a maximum 17GB/s bandwidth, ADATA DDR4 server memory modules are all certified Intel® Haswell-EP compatible to ensure superior performance. Products ship in four convenient form factors to accommodate diverse needs and applications: R-DIMM and ECC U-DIMM for servers and enterprises, VLP R-DIMM for high-end blade servers, and ECC SO-SIMM for micro servers. Running at a mere 1.2V, ADATA DDR4 memory modules use 20% less energy than conventional lower-performance DDR3 modules, in effect delivering more computational power for less energy draw. ADATA DDR4 server memory modules are an excellent choice for users looking to balance performance, environmental responsibility, and cost effectiveness. Features ECC U-DIMM High speed up to 2400MHz Transfer bandwidths up to 17GB/s Energy efficient: save up to 20% compared to DDR3 8-layer PCB provides improved signal transfer R-DIMM and system stability PCB gold plating: 30u and up Intel Haswell-EP compatible for extreme performance VLP R-DIMM ECC SO-DIMM Specifications Type ECC-DIMM R-DIMM VLP R-DIMM ECC SO-DIMM Standard Standard Very low profile Standard Form factor (1.18" height) (1.18" height) (0.7" height) (1.18" height) Enterprise servers / Enterprise servers / Suitable for Blade servers Micro servers data centers data centers Interface 288-pin 288-pin 288-pin 260-pin Capacity 4GB / 8GB / 16GB 4GB / 8GB / 16GB 4GB / 8GB /16GB 4GB / 8GB / 16GB Rank