Security Posture Based Incident Forecasting
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

System Node Reference
IceWarp Unified Communications System Node Reference Version 10.4 Print ed on 10 December, 2012 Contents System Node 1 Services .......................................................................................................................................................................... 2 Service Ports ...................................................................................................................................................... 2 General .............................................................................................................................................................. 4 Service – Properties ............................................................................................................................... 7 Service – Logging ................................................................................................................................... 9 Service – Access ................................................................................................................................... 10 Service – Other .................................................................................................................................... 11 SOCKS and Minger Server .................................................................................................................... 12 SOCKS .................................................................................................................................................. 12 Minger Server ..................................................................................................................................... -

Thanos Tsouanas --- C.V
Curriculum Vitæ Thanos Tsouanas 02/05/2017 I Personal details hello photo full name: Athanasios (Thanos) Tsouanas date of birth: 22/02/1983 place of birth: Athens, Greece nationality: Hellenic office address: IMD, Universidade Federal do Rio Grande do Norte Av. Cap. Mor Gouveia, S/N CEP: 59063-400, Natal{RN, Brasil phone number: (+55) (84) 9 8106-9789 (mobile, Telegram, WhatsApp) email address: [email protected] personal website: http://www.tsouanas.org/ GitHub: http://github.com/tsouanas Spoken languages Greek (native); English (proficient); Brazilian Portuguese (fluent). I Studies & academic positions 2016 { Associate professor (permanent position) in Instituto Metr´opole Digital of Universidade Federal do Rio Grande do Norte (UFRN), Brazil. 2015 Postdoctoral researcher in the Mathematics Department of Universidade Federal do Rio Grande do Norte (UFRN), Brazil. 2014 PhD from Ecole´ Normale Superieure´ de Lyon, under the supervision of Olivier Laurent, in the field of theoretical computer science. I was employed by CNRS under the Marie Curie fellowship \MALOA", and had a 1-month secondment split between the University of Oxford (in the team of Luke Ong) and Ecole´ Polytechnique (in the team of Dale Miller). Thesis title: On the Semantics of Disjunctive Logic Programs1 2010 Master of Science degree from MPLA (graduate program in Logic, Algorithms and Computation of the University of Athens and of the Technical University of Athens),2 mathematical logic specialty, grade 8.23/10. 2007 Bachelor's degree from the Department of Mathematics of the University of Athens, specialty of pure mathematics, grade \excellent" (8.51/10). Seminars and schools • Logoi school on Linear Logic and Geometry of Interaction. -

AXIGEN Mail Server™ Has Been Designed to Enable Businesses to Cut Costs Without Cutting Corners
Combating the increasing cost of email Why you should read this white paper Businesses usually adopt a commonsense approach when it comes to spending the IT budget with cost being a major influencer in purchasing decisions. However, when it comes to choosing a mail server, many businesses seem to pay less attention to the costs and, as a result, end up spending far more money than is necessary. This white paper will explain how businesses can significantly reduce the costs of their email communication while continuing to provide users with a best-in-class messaging and collaboration solution. White paper Introduction Today, email is absolutely mission-critical. Communication and collaboration keep your business running. Email and electronically enabled collaboration have become so embedded in normal day-to-day operations that many businesses simply could not function without them. These services enable everything from productivity enhancing collaboration between employees to external communications with customers and business partners and demand 24x7 availability. Many businesses, however, have found that the cost of providing employees with the latest in messaging and collaboration technology is rapidly escalating. To meet modern business needs, mail servers have had to become more complex – and with that additional complexity come additional management burdens and costs. Furthermore, some mail servers have an upgrade process that is both extremely complex and extremely costly and which may necessitate the purchase of replacement server hardware. Combined, these factors place a considerable drain on corporate resources. The problem is especially severe for small and medium sized businesses (SMBs) which usually do not have access to the same financial or technical resources as large enterprises. -

Mailarchiva Enterprise Edition V1.9
MailArchiva Enterprise Edition Administration Guide Willkommen Bienvenidos Welkom Bienvenue Welcome MailArchiva Enterprise Edition v1.9 INSTALLATION AND AMINISTRATION GUIDE For Windows / Linux MailArchiva Enterprise Edition Administration Guide 1 INDEX 1 INDEX ............................................................................................................. 2 2 IMPORTANT NOTICE ....................................................................................... 4 3 CONTACT INFORMATION ................................................................................. 4 TECHNICAL REQUIREMENTS .................................................................................. 5 4 OVERVIEW ...................................................................................................... 6 5 HIGH-LEVEL FEATURES ................................................................................... 7 6 ARCHITECTURE ............................................................................................... 9 7 INSTALLATION .............................................................................................. 10 7.1 EXCHANGE SERVER CONFIGURATION .................................................................... 11 7.2 SERVER INSTALLATION (ON WINDOWS ) ................................................................ 14 7.3 SERVER INSTALLATION (ON LINUX ) ..................................................................... 15 7.4 MICROSOFT EXCHANGE ................................................................................... -

Efficient Spam Filtering System Based on Smart Cooperative Subjective and Objective Methods*
Int. J. Communications, Network and System Sciences, 2013, 6, 88-99 http://dx.doi.org/10.4236/ijcns.2013.62011 Published Online February 2013 (http://www.scirp.org/journal/ijcns) Efficient Spam Filtering System Based on Smart * Cooperative Subjective and Objective Methods Samir A. Elsagheer Mohamed1,2 1College of Computer, Qassim University, Qassim, KSA 2Electrical Engineering Department, Faculty of Engineering, Aswan University, Aswan, Egypt Email: [email protected], [email protected] Received September 17, 2012; revised January 16, 2013; accepted January 25, 2013 ABSTRACT Most of the spam filtering techniques are based on objective methods such as the content filtering and DNS/reverse DNS checks. Recently, some cooperative subjective spam filtering techniques are proposed. Objective methods suffer from the false positive and false negative classification. Objective methods based on the content filtering are time con- suming and resource demanding. They are inaccurate and require continuous update to cope with newly invented spammer’s tricks. On the other side, the existing subjective proposals have some drawbacks like the attacks from mali- cious users that make them unreliable and the privacy. In this paper, we propose an efficient spam filtering system that is based on a smart cooperative subjective technique for content filtering in addition to the fastest and the most reliable non-content-based objective methods. The system combines several applications. The first is a web-based system that we have developed based on the proposed technique. A server application having extra features suitable for the enter- prises and closed work groups is a second part of the system. Another part is a set of standard web services that allow any existing email server or email client to interact with the system. -

I. Instaling and Configuring the AXIGEN MAIL SERVER
15 Minutes to Setup AXIGEN with AV and AS FAST.RELIABLE.SECURE.MESSAGING This article illustrates a situation where you need to set up your own mail server (be it your home mail server, or a small office one). It actually shows that, if using an integrated service mail server, anyone can do the job, all in a matter of minutes. AXIGEN Mail Server, the solution chosen for this example, can send and receive e- mails securely via "mydomain.com" and is able to retrieve them in a WebMail interface - this means that it includes all mail services needed for a fully functional mail server (SMTP, IMAP, POP3, WebMail, WebAdmin). To get an idea of the amount of time you can spare by installing such a solution, just think of all the different open source applications you would need to install instead (i.e. an MTA, Squirrelmail for Webmail, QmailAdmin for web configuration, Courier for IMAP and POP3 and many others.) AXIGEN Mail Server can virtually integrate with any Antivirus/Antispam application and it comes with built-in connectors ClamAV Antivirus and SpamAssassin. The second part of this article shows you how to install these applications and configure these connectors for use with AXIGEN. Thus, at the end of this process which can take up half an hour at most, you will not only have your mail server up and running, but also virus and spam protection for your incoming and outgoing mail traffic. AXIGEN runs on several Linux distributions (Gentoo, Redhat/Fedora Core, Slackware, Debian, Ubuntu, Mandrake/Mandriva, SUSE), on BSD versions (FreeBSD, OpenBSD and NetBSD) and on Solaris but for the purpose of this article, let's suppose you are setting up your mail system on a Fedora Core 6 platform. -

Server Administration
Server administration Remo Suppi Boldrito PID_00148466 GNUFDL • PID_00148466 Server administration Copyright © 2009, FUOC. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or any later version published by the Free Software Foundation; with no Invariant Sections, no Front-Cover Texts, and no Back-Cover Texts. A copy of the license is included in the section entitled "GNU Free Documentation License" GNUFDL • PID_00148466 Server administration Index Introduction............................................................................................... 5 1. Domain name system (DNS)............................................................ 7 1.1. Cache names server .................................................................... 7 1.2. Forwarders ................................................................................... 10 1.3. Configuration of an own domain .............................................. 11 2. NIS (YP)................................................................................................. 14 2.1. ¿How do we initiate a local NIS client in Debian? ..................... 14 2.2. What resources must be specified in order to use NIS? .............. 15 2.3. How should we execute a master NIS server? ............................ 16 2.4. How should we configure a server? ............................................ 17 3. Remote connection services: telnet and ssh............................... 19 3.1. Telnet and telnetd -

Eudora® Email 7.1 User Guide for Windows
Eudora® Email 7.1 User Guide for Windows This manual was written for use with the Eudora® for Windows software version 7.1. This manual and the Eudora software described in it are copyrighted, with all rights reserved. This manual and the Eudora software may not be copied, except as otherwise provided in your software license or as expressly permitted in writing by QUALCOMM Incorporated. Export of this technology may be controlled by the United States Government. Diversion contrary to U.S. law prohibited. Copyright © 2006 by QUALCOMM Incorporated. All rights reserved. QUALCOMM, Eudora, Eudora Pro, Eudora Light, and QChat are registered trademarks of QUALCOMM Incorporated. PureVoice, SmartRate, MoodWatch, WorldMail, Eudora Internet Mail Server, and the Eudora logo are trademarks of QUALCOMM Incorporated. Microsoft, Outlook, Outlook Express, and Windows are either registered trademarks or trademarks of Microsoft Incorporated in the United States and/or other countries. Adobe, Acrobat, and Acrobat Exchange are registered trademarks of Adobe Systems Incorporated. Apple and the Apple logo are registered trademarks, and QuickTime is a trademark of Apple Computer, Inc. Netscape, Netscape Messenger, and Netscape Messenger are registered trademarks of the Netscape Communications Corporation in the United States and other countries. Netscape's logos and Netscape product and service names are also trademarks of Netscape Communications Corporation, which may be registered in other countries. All other trademarks and service marks are the property of their respective owners. Use of the Eudora software and other software and fonts accompanying your license (the "Software") and its documentation are governed by the terms set forth in your license. -

Index Images Download 2006 News Crack Serial Warez Full 12 Contact
index images download 2006 news crack serial warez full 12 contact about search spacer privacy 11 logo blog new 10 cgi-bin faq rss home img default 2005 products sitemap archives 1 09 links 01 08 06 2 07 login articles support 05 keygen article 04 03 help events archive 02 register en forum software downloads 3 security 13 category 4 content 14 main 15 press media templates services icons resources info profile 16 2004 18 docs contactus files features html 20 21 5 22 page 6 misc 19 partners 24 terms 2007 23 17 i 27 top 26 9 legal 30 banners xml 29 28 7 tools projects 25 0 user feed themes linux forums jobs business 8 video email books banner reviews view graphics research feedback pdf print ads modules 2003 company blank pub games copyright common site comments people aboutus product sports logos buttons english story image uploads 31 subscribe blogs atom gallery newsletter stats careers music pages publications technology calendar stories photos papers community data history arrow submit www s web library wiki header education go internet b in advertise spam a nav mail users Images members topics disclaimer store clear feeds c awards 2002 Default general pics dir signup solutions map News public doc de weblog index2 shop contacts fr homepage travel button pixel list viewtopic documents overview tips adclick contact_us movies wp-content catalog us p staff hardware wireless global screenshots apps online version directory mobile other advertising tech welcome admin t policy faqs link 2001 training releases space member static join health -
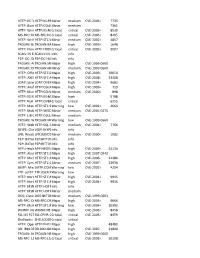
HTTP: IIS "Propfind" Rem HTTP:IIS:PROPFIND Minor Medium
HTTP: IIS "propfind"HTTP:IIS:PROPFIND RemoteMinor DoS medium CVE-2003-0226 7735 HTTP: IkonboardHTTP:CGI:IKONBOARD-BADCOOKIE IllegalMinor Cookie Languagemedium 7361 HTTP: WindowsHTTP:IIS:NSIISLOG-OF Media CriticalServices NSIISlog.DLLcritical BufferCVE-2003-0349 Overflow 8035 MS-RPC: DCOMMS-RPC:DCOM:EXPLOIT ExploitCritical critical CVE-2003-0352 8205 HTTP: WinHelp32.exeHTTP:STC:WINHELP32-OF2 RemoteMinor Buffermedium Overrun CVE-2002-0823(2) 4857 TROJAN: BackTROJAN:BACKORIFICE:BO2K-CONNECT Orifice 2000Major Client Connectionhigh CVE-1999-0660 1648 HTTP: FrontpageHTTP:FRONTPAGE:FP30REG.DLL-OF fp30reg.dllCritical Overflowcritical CVE-2003-0822 9007 SCAN: IIS EnumerationSCAN:II:IIS-ISAPI-ENUMInfo info P2P: DC: DirectP2P:DC:HUB-LOGIN ConnectInfo Plus Plus Clientinfo Hub Login TROJAN: AOLTROJAN:MISC:AOLADMIN-SRV-RESP Admin ServerMajor Responsehigh CVE-1999-0660 TROJAN: DigitalTROJAN:MISC:ROOTBEER-CLIENT RootbeerMinor Client Connectmedium CVE-1999-0660 HTTP: OfficeHTTP:STC:DL:OFFICEART-PROP Art PropertyMajor Table Bufferhigh OverflowCVE-2009-2528 36650 HTTP: AXIS CommunicationsHTTP:STC:ACTIVEX:AXIS-CAMERAMajor Camerahigh Control (AxisCamControl.ocx)CVE-2008-5260 33408 Unsafe ActiveX Control LDAP: IpswitchLDAP:OVERFLOW:IMAIL-ASN1 IMail LDAPMajor Daemonhigh Remote BufferCVE-2004-0297 Overflow 9682 HTTP: AnyformHTTP:CGI:ANYFORM-SEMICOLON SemicolonMajor high CVE-1999-0066 719 HTTP: Mini HTTP:CGI:W3-MSQL-FILE-DISCLSRSQL w3-msqlMinor File View mediumDisclosure CVE-2000-0012 898 HTTP: IIS MFCHTTP:IIS:MFC-EXT-OF ISAPI FrameworkMajor Overflowhigh (via -

Opensmtpd: Current State of Affairs
From: "Gilles Chehade" <[email protected]> To: "Ah, Jacques Cousteau" <[email protected]> Date: Sun, 24 Sep 2017 CET Subject: OpenSMTPD, current state of affairs The plan - Made tons of slides, I'll just skip over some if needed... - Sick AF, may need to run out during the talk… - Should this happen, stay calm and don’t panic, I’ll be back :-) $ whoami - Gilles Chehade <[email protected]> - I'm also @poolpOrg on twitter and github - I live in the beautiful city of Nantes, France (west coast riprizent !) - OpenBSD user since 2.6 (1999), OpenBSD developer since 4.2 (2007) - Also used NetBSD and FreeBSD a lot in the past, I enjoyed all BSD systems - Started working on smtpd in 2007 as personal project for my own needs - pyr@, reyk@ and henning@ tricked me into turning it into OpenSMTPD - "It will be fun", they said with a grin. $ whoami - Currently a Lead-Developer for the Vente-Privée Group - Platinum Sponsor of EuroBSDCon 2017 btw, woohoo ! - We are hiring. We are hiring. We are hiring. We are hiring. Mail me ;-) - I no longer do R&D work in the mail industry - Still do mail experiments in private though ;-) - My daily job has NOTHING to do with mails whatsoever, no conflicts of interest - Vente-Privée has a few OpenSMTPD instances as main MTA - I wasn't sure, I had to ask Miky Mike, the guy who knows this stuff - We also have a few OpenBSD installs, not sure I can say where and why, so… The OpenSMTPD crew - Eric Faurot <[email protected]> aka "The Doctor" - Sunil Nimmagadda <[email protected]> - Jung Joerg <[email protected]> - We tend to cc: our diffs to Todd Miller <[email protected]> - We receive a few contributions from the community - Mostly Linux people, just saying.. -

Linux Messaging for Large Scale Enterprise and Service Provider Environments
Linux Messaging for Large Scale Enterprise and Service Provider Environments Hosted by: Presented by: Invited speaker: Mihai ANGHEL Shari McMillan-Strack Sara Radicati VP Sales, Axigen VP Product Development, CEO, Radicati Group Inc. Gecad Technologies Schoolcenter 15 years of Multi-Platform expertise GECAD - a leading provider of security technology 1992 - 2003 GECAD developed advanced Security Technologies with native Multi-Platform design - specially focused on Linux / UNICES systems: PowerPC™ IBM s390® In 2003 Microsoft to Acquire Antivirus Technology From GeCAD Software “Gates noted that when the acquisition is closed, Microsoft intends to ship a Microsoft engine, based on the GeCAD technology acquired in 2003.” Source: www.microsoft.com Today Gecad’s security technology is part of: Gecad Technologies now provides: Gecad Technologies is part of a well established group of companies (Gecad Group) of 150 IT experts based in Bucharest , Romania, developing software solutions for the international market since 1992. A dedicated team with over 15 years of experience in Linux messaging, security and support services shifted focus towards developing innovative messaging solutions under the brand AXIGEN. Over 200 partners from 80 countries: Value Added Resellers, Service Providers, System Integrators, Appliance producers, Hardware Vendors Over 8.000.000 licensed mailboxes North America 29% APAC 12% EMEA 51% ROW 8% Technology Partnerships Linux – common misbeliefs “Linux is usually matched with Free Open Source components” This is believed