Hope Speech Detection in Under-Resourced Kannada Language
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Signatory ID Name CIN Company Name 02700003 RAM TIKA
Signatory ID Name CIN Company Name 02700003 RAM TIKA U55101DL1998PTC094457 RVS HOTELS AND RESORTS 02700032 BANSAL SHYAM SUNDER U70102AP2005PTC047718 SHREEMUKH PROPERTIES PRIVATE 02700065 CHHIBA SAVITA U01100MH2004PTC150274 DEJA VU FARMS PRIVATE LIMITED 02700070 PARATE VIJAYKUMAR U45200MH1993PTC072352 PARATE DEVELOPERS P LTD 02700076 BHARATI GHOSH U85110WB2007PTC118976 ACCURATE MEDICARE & 02700087 JAIN MANISH RAJMAL U45202MH1950PTC008342 LEO ESTATES PRIVATE LIMITED 02700109 NATESAN RAMACHANDRAN U51505TN2002PTC049271 RESHMA ELECTRIC PRIVATE 02700110 JEGADEESAN MAHENDRAN U51505TN2002PTC049271 RESHMA ELECTRIC PRIVATE 02700126 GUPTA JAGDISH PRASAD U74210MP2003PTC015880 GOPAL SEVA PRIVATE LIMITED 02700155 KRISHNAKUMARAN NAIR U45201GJ1994PTC021976 SHARVIL HOUSING PVT LTD 02700157 DHIREN OZA VASANTLAL U45201GJ1994PTC021976 SHARVIL HOUSING PVT LTD 02700183 GUPTA KEDAR NATH U72200AP2004PTC044434 TRAVASH SOFTWARE SOLUTIONS 02700187 KUMARASWAMY KUNIGAL U93090KA2006PLC039899 EMERALD AIRLINES LIMITED 02700216 JAIN MANOJ U15400MP2007PTC020151 CHAMBAL VALLEY AGRO 02700222 BHAIYA SHARAD U45402TN1996PTC036292 NORTHERN TANCHEM PRIVATE 02700226 HENDIN URI ZIPORI U55101HP2008PTC030910 INNER WELLSPRING HOSPITALITY 02700266 KUMARI POLURU VIJAYA U60221PY2001PLC001594 REGENCY TRANSPORT CARRIERS 02700285 DEVADASON NALLATHAMPI U72200TN2006PTC059044 ZENTERE SOLUTIONS PRIVATE 02700322 GOPAL KAKA RAM U01400UP2007PTC033194 KESHRI AGRI GENETICS PRIVATE 02700342 ASHISH OBERAI U74120DL2008PTC184837 ASTHA LAND SCAPE PRIVATE 02700354 MADHUSUDHANA REDDY U70200KA2005PTC036400 -

Participatory Action Research on Gender-Based Hate Speech Online with a Karnataka-Based Youth Group
Acknowledgments Research team Bhavna Jha, Soujanya Sridharan, Aparna Kalley, Anusha Hegde, Karthik K, Shreyas Hiremath Research report Bhavna Jha, Soujanya Sridharan, Ankita Aggarwal, Tanvi Kanchan, Sneha Bhagwat, Aparna Kalley Session facilitators Soujanya Sridharan, Aparna Kalley, Karthik K, Anusha Hegde, Shreyas Hiremath, Kirana Kumari This report is part of IT for Change’s project, Recognize, Resist, Remedy: Addressing Gender-Based Hate Speech in the Online Public Sphere, supported by International Development Research Centre (IDRC), Canada. This Participatory Action Research project was co-facilitated by IT for Change and Samvada Baduku. To cite this report: IT for Change (2021). Participatory Action Research on Gender-Based Hate Speech Online with a Karnataka-Based Youth Group. Recognize, Resist, Remedy: Addressing Gender-Based Hate Speech in the Online Public Sphere. https://itforchange.net/sites/default/files/1738/PAR-on-gender-based-hate- speech-online-with-a-Karnataka-based-youth-group.pdf 2 Table of Contents Acknowledgments..............................................................................................................................................2 Executive summary.............................................................................................................................................5 1. Rationale and context...................................................................................................................................6 2. Objectives and research questions..............................................................................................................7 -

Vijayawada Delhi Lucknow Bhopal Raipur Chandigarh Right to Education to Slow Down to 8.6% in ’22 for T20 Wc Bhubaneswar Ranchi Dehradun Hyderabad *Late City Vol
Follow us on: @TheDailyPioneer facebook.com/dailypioneer RNI No.APENG/2018/764698 Established 1864 ANALYSIS 7 MONEY 8 SPORTS 11 Published From ENFORCING THE INDIAN GOVT IT SPEND GROWTH AUSSIES’ BEST BACK VIJAYAWADA DELHI LUCKNOW BHOPAL RAIPUR CHANDIGARH RIGHT TO EDUCATION TO SLOW DOWN TO 8.6% IN ’22 FOR T20 WC BHUBANESWAR RANCHI DEHRADUN HYDERABAD *LATE CITY VOL. 3 ISSUE 276 VIJAYAWADA, FRIDAY, AUGUST 20, 2021; PAGES 12 `3 *Air Surcharge Extra if Applicable RAASHI KHANNA: PASSION FOR MY CRAFT KEEPS ME ON MY TOES { Page 12 } www.dailypioneer.com POWER MINISTRY ISSUES TIMELINES AIR INDIA DISINVESTMENT ON TRACK, ATHLETICS COACH O.M NAMBIAR, WHO BUILDERS ONLY UNDERSTAND COLOUR FOR INSTALLING SMART METERS STATES CIVIL AVIATION MINISTER GAVE INDIA PT USHA, PASSES AWAY OF MONEY OR JAIL TERM, SAYS SC he Ministry of Power on Thursday provided timelines for nion Civil Aviation Minister Jyotiraditya Scindia on enowned athletics coach O.M Nambiar, who nurtured one Builders only understand the colour of money or a jail replacing existing electricity meters with smart meters with Thursday said the disinvestment process of national of India's greatest track and field stars PT Usha, died here term,” said the Supreme Court on Thursday as it held a Tpre-payment feature in government offices, commercial Ucarrier Air India was on the "right track". “The Ron Thursday due to age-related illness. He was 89. “real estate firm guilty of contempt for wilfully not establishments and industrial units, among others According disinvestment process of Air India is on the right track. For Nambiar is survived by his wife Leela, three sons and a complying with its order and imposed a fine of Rs 15 lakh on to a notification, all consumers (other than agricultural users) this the financial bids should come in by September 15 and daughter. -

Utter Chaos in TS Over
Follow us on: RNI No. TELENG/2018/76469 @TheDailyPioneer facebook.com/dailypioneer Established 1864 Published From ANALYSIS 7 MONEY 8 SPORTS 12 HYDERABAD DELHI LUCKNOW NO COUNTRY SENSEX ENDS 153 PTS LOWER; INDIAN WOMEN BHOPAL RAIPUR CHANDIGARH FOR WOMEN NIFTY SLIPS BELOW 12,100 DOMINATE WITH 3 GOLD BHUBANESWAR RANCHI DEHRADUN VIJAYAWADA *LATE CITY VOL. 2 ISSUE 132 HYDERABAD, FRIDAY FEBRUARY 21, 2020; PAGES 12 `3 *Air Surcharge Extra if Applicable ANANYA JOINS VIJAY, PURI JAGANNADH ON SETS { Page 11 } www.dailypioneer.com TAJ MAHAL GETS A MAKEOVER AS NIRBHAYA CONVICT BANGS HEAD MARK ZUCKERBERG GETS STAFF AVOID ‘NATIONALISM’ WORD, IT AGRA PREPARES FOR TRUMP VISIT AGAINST WALL, HAS HEAD INJURY TO BLOW-DRY HIS ARMPITS IMPLIES NAZISM, SAYS RSS CHIEF head of US President Donald Trump's two-day India visit next week, ne of the four Nirbhaya case convicts to be hanged on March 3, ark Zuckerberg has his communications staff blow-dry his armpits SS chief Mohan Bhagwat on Thursday said use of the word Ahis few hours at Agra, the town of the Taj Mahal, has spurred a OVinay Sharma, was injured after he reportedly banged his head Mbefore big events and speeches, a new book on the Facebook R"nationalism" should be avoided as it reminds people of Adolf Hitler's makeover of sorts. Streets and wall are getting a fresh coat of painted against the wall of his cell at Tihar jail in Delhi. He has approached the founder and CEO claims. The 35-year-old had become famous for his Nazism. He made the remarks at an RSS event at the Mukherjee and water is being released into the Yamuna, one of country's major court for high level medical treatment for "grievous head perspiration during a 2010 televised interview when he University Morabadi in Ranchi. -

MHA Asks NIA to Probe Case of Arrested JK
Follow us on: RNI No. TELENG/2018/76469 @TheDailyPioneer facebook.com/dailypioneer Established 1864 Published From OPINION 6 MONEY 8 SPORTS 12 HYDERABAD DELHI LUCKNOW A NEW AIR BNP PARIBAS SEES 9PC KOHLI TO BE BHOPAL RAIPUR CHANDIGARH QUALITY AGENDA GROWTH FOR SENSEX IN ’20 BACK AT NO 3 BHUBANESWAR RANCHI DEHRADUN VIJAYAWADA *LATE CITY VOL. 2 ISSUE 97 HYDERABAD, FRIDAY JANUARY 17, 2020; PAGES 12 `3 *Air Surcharge Extra if Applicable BUNNY EYES BOLLYWOOD FOR PAN-INDIA APPEAL { Page 11 } www.dailypioneer.com KTR 2.0 WILL BE STRICTER MHA asks NIA to probe AFTER POLLS case of arrested JK DSP Implementing Municipal PNS n NEW DELHI The NIA has been Major terror The Union home ministry has credited with breaking Act a challenge asked the NIA to initiate the the nexus between process of probing the case of stone pelters and attack averted Will sack lax civic officials suspended Jammu and separatists in Jammu PNS n NEW DELHI Kashmir Police deputy super- NAVEENA GHANATE CONFIDENT OF intendent Davinder Singh, who and Kashmir A major attack by the Jaish-e- n HYDERABAD WINNING GHMC ELECTIONS was caught in south Kashmir Mohammed terror group has while ferrying two militants to been averted in Srinagar ahead Telangana Minister K T Rama "Next 4 years there are no BJP should focus more on economy and Jammu last weekend, officials Jammu and Kashmir, were of Republic Day, Srinagar Rao has declared that people elections. I will be focusing on less on other parties, religion and issues said on Thursday. present during the prelimi- police said on Thursday. -
Editorial Board
ISSN 2582-4287 Journal of Health and Allied Sciences NU Formerly Nitte University Journal Of Health Science An official publication of Nitte (Deemed to be University) Editor-in-Chief Rathika Shenoy Hugo de Bruyn Department of Pediatrics, K.S. Hegde School of Dentistry Iddya Karunasagar Medical Academy Radboud University Nitte (Deemed to be University) Nitte (Deemed to be University) Nijmegen, The Netherlands University Enclave Deralakatte University Enclave Deralakatte Raghavendra Rao Mangalore, Karnataka, India Mangalore, Karnataka, India Center for Neurobehavioural Anirban Chakraborty Development, Minnesota University Managing Editor Nitte University Center for Science Minneapolis, MN, United States Education and Research Azeem Mohiyuddin Indrani Karunasagar Nitte (Deemed to be University) Sri Devaraj Urs Academy of Higher Nitte (Deemed to be University) University Enclave Deralakatte Education and Research, Tamaka University Enclave Deralakatte Mangalore, Karnataka, India Kolar, Karnataka, India Mangalore, Karnataka, India Bert Callenwaert Harsha Halahalli Faculty of Medicine and Health K.S. Hegde Medical Academy Editorial Board Sciences, Ghent University Hospital Nitte (Deemed to be University) Ghent, Belgium, India University Enclave Deralakatte Ananthram Shetty Vinod Scaria Mangalore, Karnataka, India Institute of Medical Sciences Institute of Genomics and Integrative Avinash Shetty Canterbury Christ Church University Biology, New Delhi, India Pediatric Infectious Diseases Chatham Maritime, Kent M.S. Ravi Wake Forest School of Medicine United Kingdom Department of Orthodontics and Ardmore Tower, Medical Center Shubada Chiplunkar Dento-Facial Orthopedics Boulevard, Winston-Salem Advanced Center for Treatment AB Shetty Memorial Institute of North Carolina, United States Research and Education in Cancer Dental Sciences, Deralakatte, Pierre Emmanuel Gleizes (ACTREC), Kharghar, Navi Mumbai Mangalore, Karnataka, India Molecular Biology Laboratory Maharashtra, India Veena Shetty University Paul Sabatier, Toulouse Georgi Abraham K.S. -
Sl. No. Roll No Name Mobile Category VH PH Subject` REF 1 15020128 JAGADESHA D 9739499799 CAT-IIIB NO NO KANNADA DU79675533 2 15
Sl. No. Roll No Name Mobile Category VH PH Subject` REF 1 15020128 JAGADESHA D 9739499799 CAT-IIIB NO NO KANNADA DU79675533 2 15030001 LAMBODAR CHANDRAKANT GAONKAR 7259980627 CAT-IIA NO NO ECONOMICS DU79186494 3 15010138 ANAND BASARAGI 8147087505 CAT-IIA NO NO COMMERCE DU79552467 4 15060002 NAGRAJ SAHDEV BELGAONKAR 9742436236 CAT-IIIB NO NO HISTORY DU79136956 5 15030007 CHEERANJEEVI KANNER 9916972682 ST NO NO ECONOMICS DU79077380 6 15020005 RAVI DEEVIGIHALLI 9845383596 ST NO NO KANNADA DU79078684 7 15090116 SOMANAT PUJAR 7829613973 SC NO NO HINDI DU79654339 8 15070031 SANTOSH KARAMALLAVAR 9916658271 CAT-IIIB NO YES SOCIOLOGY DU79526118 9 15040188 BASAVARAJ NAGALINGAPPA MALAGIHAL 9148928679 CAT-IIIB NO NO ENGLISH DU79759293 10 15250009 RAGHAVENDRA K SALI 9480774670 ST NO NO PHYSICAL SCIENCE DU79005835 11 15200122 DEMAPPA GOUDARA 7353466364 CAT-I NO NO PHYSICAL EDUCATION DU79802106 12 15380002 KOLI SHIVANAND HIRAGAPPA 9448627782 CAT-I NO NO Linguistics DU79208258 13 15040004 PARINITHA P 8277902771 CAT-IIIA NO NO English DU79052965 14 15010029 NAVEEN 9886881188 CAT-IIIA NO NO ACCOUNTING & TAXATION COMMERCE DU79082737 15 15050094 NAVEEN MARIGOUDAR 7259231516 CAT-IIIB NO NO POLITICAL SCIENCE DU79051286 16 15040632 PRAVEEN KURABAR S 8095102476 CAT-IIA NO NO ENGLISH DU80174218 17 15050002 ASHOK MADABHAVI 8105859120 CAT-IIA NO NO POLITICAL SCIENCE DU79074451 18 15280015 HATPAKKI APARNA JAYARAJ 9886907470 CAT-IIA NO NO BIOCHEMISTRY DU79006523 19 15270012 NIRANJANSWAMI SANGAYYA HIREMATH 8095703203 GEN NO NO CHEMISTRY DU79139002 20 15240006 SHRIDHAR -

Rashmika Mandanna Just Can't Get Enough of the New Mcspicy
Rashmika Mandanna Just Can’t Get Enough of the new McSpicy Fried Chicken in the latest campaign launched by McDonald’s ~The brand has launched two TVCs as part of a 360-degree campaign, that will be aired in Karnataka, Tamil Nadu, Andh5.06 <030 0.ph5.06 <03ned a(, An)4()3(, )] TJ ET BT 1 0 053 395.69 610.54 Tm ela(,6(gil N)3()-2(n)5( )] TJ ET BT 1 0 00 1 03.69 610.54 Tmn)5( )] TJ ET BT 1 0 002.913.69 610.54 Tm [(~)] TJ ET /F5 /F4 11.04 Tf 1 0 4 1 433.69 610.54 Tmn The second TVC shows Rashmika and her friends digging into the scrumptious McSpicy Fried Chicken at home together. When one of her friends suggests trying something other than the McSpicy Fried Chicken next time after having the same product every single day for the last one year, Rashmika simply chooses to change her friend but not her favourite fried chicken. Click here to watch the TVC Rashmika was recently appointed by McDonald’s as its brand ambassador to further strengthen its connect with millennials in its key markets of Karnataka, Tamil Nadu, Andhra Pradesh and Telangana. The TVCs will be aired exclusively in the South markets in Kannada, Tamil and Telugu and will be adapted for the digital platforms as well. The campaign has been conceptualised by DDB Mudra. Through this new campaign, the brand aims to create a strong mark in the Indian fried chicken market. The new integrated campaign will have a multi-pronged approach with media mix of TV, digital and social platforms along with strong in-store visibility, on-ground and OOH activations. -

After the Melee, Calm Returns to Hyderabad's Wine Shops 15 Migrant
INDIAN09 May, 2020 | Saturday | Volume No: 8| Issue No: 69 Pages: 8 CHRONICLE www.indianchronicle.com Published from : Ranga Reddy (Telangana State) 3 3 students injured as a dispute during cricket match turn into battle in Warangal Depressed over delay in wedding, couple ends life in Adilabad A dispute that erupted while playing cricket match led to the students thrashing each other with the bats, Depressed over delay in their wedding due to the coronavirus induced lockdown, a couple committed suicide in wickets and sticks. Three students have been injured in the incident and were shi?ed to a hospital for treatment. Kampur village of Narnur mandal of Adilabad district. Locals informed the police who reached the spot and took up Getting into the details, the students of Kazipet high school were playing a cricket match to kill the time during the an investigation. The police said that the couple who got engaged were depressed over the lockdown that was lockdown. However, a dispute arose between them and the students started attacking each other with the cricket imposed to prevent the spread of the virus. With no hope of being together, the couple consumed poison and equipment. The Kazipet policeIt is learned that the two teams involved in the match had an argument over batting committed suicide, the police said.The victims were identified as Ganesh and Seetha Bhai. The victims were which eventually led to the attack. The cricket dispute caught the attention of the public who vented out anger at identified as Ganesh and Seetha Bhai. With the death of the couple, a pall of gloom descended in the village. -
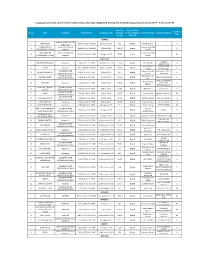
Language Wise List of the Feature Films Indian/Foreign (Digital & Video)
Language wise List of the feature films Indian/Foreign (Digital & Video) Certified during period (01/01/2019 - 01/12/2019) Certified Type Of Film Certificate Sr. No Title Language Certificate No. Certificate Date Duration/ (Video/Digital/C Producer Name Production House Type Length elluloid) ARABIC ARABIC WITH ENGLISH 1 YOMEDDINE DFL/1/16/2019-MUM 26 March 2019 99.2 Digital WILD BUNCH - U SUBTITLES CAPHARNAUM ( Arabic With English Capharnaum Film 2 DFL/3/25/2019-MUM 02 May 2019 128.08 Digital - A CHILDREN OF CHAOS) Subtitles Ltd BVI CAPHARNAUM Arabic with English Capharnaum Film 3 VFL/2/448/2019-MUM 13 August 2019 127.54 Video - UA (CHILDREN OF CHAOS) Subtitles Ltd BVI ASSAMESE DREAM 1 KOKAIDEU BINDAAS Assamese DIL/1/1/2019-GUW 14 February 2019 120.4 Digital Rahul Modi U PRODUCTION Ajay Vishnu Children's Film 2 GATTU Assamese DIL/1/59/2019-MUM 22 March 2019 74.41 Digital U Chavan Society, India ASSAMESE WITH Anupam Kaushik Bhaworiya - The T- 3 BORNODI BHOTIAI DIL/1/5/2019-GUW 18 April 2019 120 Digital U ENGLISH SUBTITLES Borah Posaitives ASSAMESE WITH Kunjalata Gogoi 4 JANAKNANDINI DIL/1/8/2019-GUW 25 June 2019 166.23 Digital NIZI PRODUCTION U ENGLISH SUBTITLES Das SKYPLEX MOTION Nazim Uddin 5 ASTITTWA Assamese DIL/1/9/2019-GUW 04 July 2019 145.03 Digital PICTURES U Ahmed INTERNATIONAL FIREFLIES... JONAKI ASSAMESE WITH 6 DIL/3/2/2019-GUW 04 July 2019 93.06 Digital Milin Dutta vortex films A PORUA ENGLISH SUBTITLES ASSAMESE WITH 7 AAMIS DIL/2/4/2019-GUW 10 July 2019 109.07 Digital Poonam Deol Signum Productions UA ENGLISH SUBTITLES ASSAMESE WITH 8 JI GOLPOR SES NAI DIL/3/3/2019-GUW 26 July 2019 94.55 Digital Krishna Kalita M/S. -

Effect of Pandemic on Indian Cinema
"WE MAKE YOU MORE VALUABLE" CONTENT Interview with Pritam Roy 6 Indian Cinema 1 7 Interesting Fact OTT 2 Profit @ OTT 8 3 Effect @ Indian Cinema 9 How OTT Earn Effect @ Multiplexes 4 Movie Review 10 Effect @ Film Worker 5 11 Movie Trivia FROM THE PRESIDENT'S DESK Dr. S.R SRIDHARAMURTHY PRESIDENT, NSB ACADEMY It is very heartening to know that NSB Movie Club I can’t imagine how dull and boring the world “Drishyam” is coming out with a unique magazine would have been without movies. Needless to say, to discuss happenings and to unearth its impact how they all connect us to our friends and shape on people and society. our lives. There are abundant number of movies that are based on wide variety of business We all have grown up watching movies and I must management concepts that serve as an impressive confess that movies have been a great source of source of learning. inspiration to me. Movies, to me, are not just of a source of entertainment but also are the master I hope that “Drishyam” will bring the classic pieces of art, wisdom and heroics. Movies have movies that will inspire all of us for life. helped me understand our past, see the places that I could not go, helped me get in touch with We can do more with movies! my own emotions and above all to find expression to the inexplicable inner feelings. Movies have immense value in shaping our lives and society and getting the attention of society to the pertinent issues. -
Unwind Mauritius Times Friday, April 2 , 2021 13 They Are Driving Us Mad with Corona
66th Year -- No. 3665 Friday, April 2, 2021 www.mauritiustimes.com facebook.com/mauritius.times 18 Pages - ePaper MAURITIUS TIMES l “I'm coronavirus brave. I stand tall and proud. With my mask on my face, Staying away from the crowd.” -- Ari Gunzburg, Coronavirus Brave Interview : Xavier-Luc Duval, Leader de l'Opposition “ Le Gouvernement doit se ressaisir car on va droit dans le mur ” 'Il est impossible d'envisager une ouverture des frontières alors que la grande majorité des Mauriciens n'est pas vaccinée' + See Page 8-9 Corona doesn't play April fool This is the world's most difficult battle. We can only win it by fighting it together By Mrinal Roy + See Page 4 Safe City Project, Audit Report & ICAC ‘Can an ICAC investigation override the constitutional powers of the Director of Audit? Surely the better opinion would be that the supremacy of the Constitution should prevail' Dr R Neerunjun Gopee + See Page 3 By Lex + See Page 5 Mauritius Times Friday, April 2, 2021 www.mauritiustimes.com Edit Page facebook.com/mauritius.times 2 Constitutionalism to Support The Conversation Constitutional Functions Covid-19 vaccines are a victory for public research, not ‘greed’… ur Constitution makes provision for a assessment was made to ascertain the fair- number of what are called Constitu- ness of the lease payments made by the The development of the Covid-19 vaccines is part of a vast system of tional Posts, which guarantee to the Police Service under the contract, and thus O public subsidies and universities, not corporate ambition occupiers of these posts constitutional protec- that the procurement was undertaken in the tion in the sense that they benefit from some most economical manner.’ Furthermore, the form of constitutional protection.