Basic Numerical Solution Methods for Differential Equations
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Introduction to Differential Equations
Introduction to Differential Equations Lecture notes for MATH 2351/2352 Jeffrey R. Chasnov k kK m m x1 x2 The Hong Kong University of Science and Technology The Hong Kong University of Science and Technology Department of Mathematics Clear Water Bay, Kowloon Hong Kong Copyright ○c 2009–2016 by Jeffrey Robert Chasnov This work is licensed under the Creative Commons Attribution 3.0 Hong Kong License. To view a copy of this license, visit http://creativecommons.org/licenses/by/3.0/hk/ or send a letter to Creative Commons, 171 Second Street, Suite 300, San Francisco, California, 94105, USA. Preface What follows are my lecture notes for a first course in differential equations, taught at the Hong Kong University of Science and Technology. Included in these notes are links to short tutorial videos posted on YouTube. Much of the material of Chapters 2-6 and 8 has been adapted from the widely used textbook “Elementary differential equations and boundary value problems” by Boyce & DiPrima (John Wiley & Sons, Inc., Seventh Edition, ○c 2001). Many of the examples presented in these notes may be found in this book. The material of Chapter 7 is adapted from the textbook “Nonlinear dynamics and chaos” by Steven H. Strogatz (Perseus Publishing, ○c 1994). All web surfers are welcome to download these notes, watch the YouTube videos, and to use the notes and videos freely for teaching and learning. An associated free review book with links to YouTube videos is also available from the ebook publisher bookboon.com. I welcome any comments, suggestions or corrections sent by email to [email protected]. -

On the Use of Discrete Fourier Transform for Solving Biperiodic Boundary Value Problem of Biharmonic Equation in the Unit Rectangle
On the Use of Discrete Fourier Transform for Solving Biperiodic Boundary Value Problem of Biharmonic Equation in the Unit Rectangle Agah D. Garnadi 31 December 2017 Department of Mathematics, Faculty of Mathematics and Natural Sciences, Bogor Agricultural University Jl. Meranti, Kampus IPB Darmaga, Bogor, 16680 Indonesia Abstract This note is addressed to solving biperiodic boundary value prob- lem of biharmonic equation in the unit rectangle. First, we describe the necessary tools, which is discrete Fourier transform for one di- mensional periodic sequence, and then extended the results to 2- dimensional biperiodic sequence. Next, we use the discrete Fourier transform 2-dimensional biperiodic sequence to solve discretization of the biperiodic boundary value problem of Biharmonic Equation. MSC: 15A09; 35K35; 41A15; 41A29; 94A12. Key words: Biharmonic equation, biperiodic boundary value problem, discrete Fourier transform, Partial differential equations, Interpola- tion. 1 Introduction This note is an extension of a work by Henrici [2] on fast solver for Poisson equation to biperiodic boundary value problem of biharmonic equation. This 1 note is organized as follows, in the first part we address the tools needed to solve the problem, i.e. introducing discrete Fourier transform (DFT) follows Henrici's work [2]. The second part, we apply the tools already described in the first part to solve discretization of biperiodic boundary value problem of biharmonic equation in the unit rectangle. The need to solve discretization of biharmonic equation is motivated by its occurence in some applications such as elasticity and fluid flows [1, 4], and recently in image inpainting [3]. Note that the work of Henrici [2] on fast solver for biperiodic Poisson equation can be seen as solving harmonic inpainting. -

3 Runge-Kutta Methods
3 Runge-Kutta Methods In contrast to the multistep methods of the previous section, Runge-Kutta methods are single-step methods — however, with multiple stages per step. They are motivated by the dependence of the Taylor methods on the specific IVP. These new methods do not require derivatives of the right-hand side function f in the code, and are therefore general-purpose initial value problem solvers. Runge-Kutta methods are among the most popular ODE solvers. They were first studied by Carle Runge and Martin Kutta around 1900. Modern developments are mostly due to John Butcher in the 1960s. 3.1 Second-Order Runge-Kutta Methods As always we consider the general first-order ODE system y0(t) = f(t, y(t)). (42) Since we want to construct a second-order method, we start with the Taylor expansion h2 y(t + h) = y(t) + hy0(t) + y00(t) + O(h3). 2 The first derivative can be replaced by the right-hand side of the differential equation (42), and the second derivative is obtained by differentiating (42), i.e., 00 0 y (t) = f t(t, y) + f y(t, y)y (t) = f t(t, y) + f y(t, y)f(t, y), with Jacobian f y. We will from now on neglect the dependence of y on t when it appears as an argument to f. Therefore, the Taylor expansion becomes h2 y(t + h) = y(t) + hf(t, y) + [f (t, y) + f (t, y)f(t, y)] + O(h3) 2 t y h h = y(t) + f(t, y) + [f(t, y) + hf (t, y) + hf (t, y)f(t, y)] + O(h3(43)). -

Runge-Kutta Scheme Takes the Form K1 = Hf (Tn, Yn); K2 = Hf (Tn + Αh, Yn + Βk1); (5.11) Yn+1 = Yn + A1k1 + A2k2
Approximate integral using the trapezium rule: h Y (t ) ≈ Y (t ) + [f (t ; Y (t )) + f (t ; Y (t ))] ; t = t + h: n+1 n 2 n n n+1 n+1 n+1 n Use Euler's method to approximate Y (tn+1) ≈ Y (tn) + hf (tn; Y (tn)) in trapezium rule: h Y (t ) ≈ Y (t ) + [f (t ; Y (t )) + f (t ; Y (t ) + hf (t ; Y (t )))] : n+1 n 2 n n n+1 n n n Hence the modified Euler's scheme 8 K1 = hf (tn; yn) > h <> y = y + [f (t ; y ) + f (t ; y + hf (t ; y ))] , K2 = hf (tn+1; yn + K1) n+1 n 2 n n n+1 n n n > K1 + K2 :> y = y + n+1 n 2 5.3.1 Modified Euler Method Numerical solution of Initial Value Problem: dY Z tn+1 = f (t; Y ) , Y (tn+1) = Y (tn) + f (t; Y (t)) dt: dt tn Use Euler's method to approximate Y (tn+1) ≈ Y (tn) + hf (tn; Y (tn)) in trapezium rule: h Y (t ) ≈ Y (t ) + [f (t ; Y (t )) + f (t ; Y (t ) + hf (t ; Y (t )))] : n+1 n 2 n n n+1 n n n Hence the modified Euler's scheme 8 K1 = hf (tn; yn) > h <> y = y + [f (t ; y ) + f (t ; y + hf (t ; y ))] , K2 = hf (tn+1; yn + K1) n+1 n 2 n n n+1 n n n > K1 + K2 :> y = y + n+1 n 2 5.3.1 Modified Euler Method Numerical solution of Initial Value Problem: dY Z tn+1 = f (t; Y ) , Y (tn+1) = Y (tn) + f (t; Y (t)) dt: dt tn Approximate integral using the trapezium rule: h Y (t ) ≈ Y (t ) + [f (t ; Y (t )) + f (t ; Y (t ))] ; t = t + h: n+1 n 2 n n n+1 n+1 n+1 n Hence the modified Euler's scheme 8 K1 = hf (tn; yn) > h <> y = y + [f (t ; y ) + f (t ; y + hf (t ; y ))] , K2 = hf (tn+1; yn + K1) n+1 n 2 n n n+1 n n n > K1 + K2 :> y = y + n+1 n 2 5.3.1 Modified Euler Method Numerical solution of Initial Value Problem: dY Z tn+1 = -
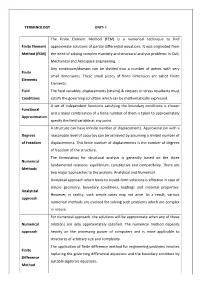
TERMINOLOGY UNIT- I Finite Element Method (FEM)
TERMINOLOGY UNIT- I The Finite Element Method (FEM) is a numerical technique to find Finite Element approximate solutions of partial differential equations. It was originated from Method (FEM) the need of solving complex elasticity and structural analysis problems in Civil, Mechanical and Aerospace engineering. Any continuum/domain can be divided into a number of pieces with very Finite small dimensions. These small pieces of finite dimension are called Finite Elements Elements. Field The field variables, displacements (strains) & stresses or stress resultants must Conditions satisfy the governing condition which can be mathematically expressed. A set of independent functions satisfying the boundary conditions is chosen Functional and a linear combination of a finite number of them is taken to approximately Approximation specify the field variable at any point. A structure can have infinite number of displacements. Approximation with a Degrees reasonable level of accuracy can be achieved by assuming a limited number of of Freedom displacements. This finite number of displacements is the number of degrees of freedom of the structure. The formulation for structural analysis is generally based on the three Numerical fundamental relations: equilibrium, constitutive and compatibility. There are Methods two major approaches to the analysis: Analytical and Numerical. Analytical approach which leads to closed-form solutions is effective in case of simple geometry, boundary conditions, loadings and material properties. Analytical However, in reality, such simple cases may not arise. As a result, various approach numerical methods are evolved for solving such problems which are complex in nature. For numerical approach, the solutions will be approximate when any of these Numerical relations are only approximately satisfied. -

The Original Euler's Calculus-Of-Variations Method: Key
Submitted to EJP 1 Jozef Hanc, [email protected] The original Euler’s calculus-of-variations method: Key to Lagrangian mechanics for beginners Jozef Hanca) Technical University, Vysokoskolska 4, 042 00 Kosice, Slovakia Leonhard Euler's original version of the calculus of variations (1744) used elementary mathematics and was intuitive, geometric, and easily visualized. In 1755 Euler (1707-1783) abandoned his version and adopted instead the more rigorous and formal algebraic method of Lagrange. Lagrange’s elegant technique of variations not only bypassed the need for Euler’s intuitive use of a limit-taking process leading to the Euler-Lagrange equation but also eliminated Euler’s geometrical insight. More recently Euler's method has been resurrected, shown to be rigorous, and applied as one of the direct variational methods important in analysis and in computer solutions of physical processes. In our classrooms, however, the study of advanced mechanics is still dominated by Lagrange's analytic method, which students often apply uncritically using "variational recipes" because they have difficulty understanding it intuitively. The present paper describes an adaptation of Euler's method that restores intuition and geometric visualization. This adaptation can be used as an introductory variational treatment in almost all of undergraduate physics and is especially powerful in modern physics. Finally, we present Euler's method as a natural introduction to computer-executed numerical analysis of boundary value problems and the finite element method. I. INTRODUCTION In his pioneering 1744 work The method of finding plane curves that show some property of maximum and minimum,1 Leonhard Euler introduced a general mathematical procedure or method for the systematic investigation of variational problems. -

Numerical Stability; Implicit Methods
NUMERICAL STABILITY; IMPLICIT METHODS When solving the initial value problem 0 Y (x) = f (x; Y (x)); x0 ≤ x ≤ b Y (x0) = Y0 we know that small changes in the initial data Y0 will result in small changes in the solution of the differential equation. More precisely, consider the perturbed problem 0 Y"(x) = f (x; Y"(x)); x0 ≤ x ≤ b Y"(x0) = Y0 + " Then assuming f (x; z) and @f (x; z)=@z are continuous for x0 ≤ x ≤ b; −∞ < z < 1, we have max jY"(x) − Y (x)j ≤ c j"j x0≤x≤b for some constant c > 0. We would like our numerical methods to have a similar property. Consider the Euler method yn+1 = yn + hf (xn; yn) ; n = 0; 1;::: y0 = Y0 and then consider the perturbed problem " " " yn+1 = yn + hf (xn; yn ) ; n = 0; 1;::: " y0 = Y0 + " We can show the following: " max jyn − ynj ≤ cbj"j x0≤xn≤b for some constant cb > 0 and for all sufficiently small values of the stepsize h. This implies that Euler's method is stable, and in the same manner as was true for the original differential equation problem. The general idea of stability for a numerical method is essentially that given above for Eulers's method. There is a general theory for numerical methods for solving the initial value problem 0 Y (x) = f (x; Y (x)); x0 ≤ x ≤ b Y (x0) = Y0 If the truncation error in a numerical method has order 2 or greater, then the numerical method is stable if and only if it is a convergent numerical method. -

Leonhard Euler: His Life, the Man, and His Works∗
SIAM REVIEW c 2008 Walter Gautschi Vol. 50, No. 1, pp. 3–33 Leonhard Euler: His Life, the Man, and His Works∗ Walter Gautschi† Abstract. On the occasion of the 300th anniversary (on April 15, 2007) of Euler’s birth, an attempt is made to bring Euler’s genius to the attention of a broad segment of the educated public. The three stations of his life—Basel, St. Petersburg, andBerlin—are sketchedandthe principal works identified in more or less chronological order. To convey a flavor of his work andits impact on modernscience, a few of Euler’s memorable contributions are selected anddiscussedinmore detail. Remarks on Euler’s personality, intellect, andcraftsmanship roundout the presentation. Key words. LeonhardEuler, sketch of Euler’s life, works, andpersonality AMS subject classification. 01A50 DOI. 10.1137/070702710 Seh ich die Werke der Meister an, So sehe ich, was sie getan; Betracht ich meine Siebensachen, Seh ich, was ich h¨att sollen machen. –Goethe, Weimar 1814/1815 1. Introduction. It is a virtually impossible task to do justice, in a short span of time and space, to the great genius of Leonhard Euler. All we can do, in this lecture, is to bring across some glimpses of Euler’s incredibly voluminous and diverse work, which today fills 74 massive volumes of the Opera omnia (with two more to come). Nine additional volumes of correspondence are planned and have already appeared in part, and about seven volumes of notebooks and diaries still await editing! We begin in section 2 with a brief outline of Euler’s life, going through the three stations of his life: Basel, St. -

Lecture 7: the Complex Fourier Transform and the Discrete Fourier Transform (DFT)
Lecture 7: The Complex Fourier Transform and the Discrete Fourier Transform (DFT) c Christopher S. Bretherton Winter 2014 7.1 Fourier analysis and filtering Many data analysis problems involve characterizing data sampled on a regular grid of points, e. g. a time series sampled at some rate, a 2D image made of regularly spaced pixels, or a 3D velocity field from a numerical simulation of fluid turbulence on a regular grid. Often, such problems involve characterizing, detecting, separating or ma- nipulating variability on different scales, e. g. finding a weak systematic signal amidst noise in a time series, edge sharpening in an image, or quantifying the energy of motion across the different sizes of turbulent eddies. Fourier analysis using the Discrete Fourier Transform (DFT) is a fun- damental tool for such problems. It transforms the gridded data into a linear combination of oscillations of different wavelengths. This partitions it into scales which can be separately analyzed and manipulated. The computational utility of Fourier methods rests on the Fast Fourier Transform (FFT) algorithm, developed in the 1960s by Cooley and Tukey, which allows efficient calculation of discrete Fourier coefficients of a periodic function sampled on a regular grid of 2p points (or 2p3q5r with slightly reduced efficiency). 7.2 Example of the FFT Using Matlab, take the FFT of the HW1 wave height time series (length 24 × 60=25325) and plot the result (Fig. 1): load hw1 dat; zhat = fft(z); plot(abs(zhat),’x’) A few elements (the second and last, and to a lesser extent the third and the second from last) have magnitudes that stand above the noise. -

Discretization of Integro-Differential Equations
Discretization of Integro-Differential Equations Modeling Dynamic Fractional Order Viscoelasticity K. Adolfsson1, M. Enelund1,S.Larsson2,andM.Racheva3 1 Dept. of Appl. Mech., Chalmers Univ. of Technology, SE–412 96 G¨oteborg, Sweden 2 Dept. of Mathematics, Chalmers Univ. of Technology, SE–412 96 G¨oteborg, Sweden 3 Dept. of Mathematics, Technical University of Gabrovo, 5300 Gabrovo, Bulgaria Abstract. We study a dynamic model for viscoelastic materials based on a constitutive equation of fractional order. This results in an integro- differential equation with a weakly singular convolution kernel. We dis- cretize in the spatial variable by a standard Galerkin finite element method. We prove stability and regularity estimates which show how the convolution term introduces dissipation into the equation of motion. These are then used to prove a priori error estimates. A numerical ex- periment is included. 1 Introduction Fractional order operators (integrals and derivatives) have proved to be very suit- able for modeling memory effects of various materials and systems of technical interest. In particular, they are very useful when modeling viscoelastic materials, see, e.g., [3]. Numerical methods for quasistatic viscoelasticity problems have been studied, e.g., in [2] and [8]. The drawback of the fractional order viscoelastic models is that the whole strain history must be saved and included in each time step. The most commonly used algorithms for this integration are based on the Lubich convolution quadrature [5] for fractional order operators. In [1, 2], we develop an efficient numerical algorithm based on sparse numerical quadrature earlier studied in [6]. While our earlier work focused on discretization in time for the quasistatic case, we now study space discretization for the fully dynamic equations of mo- tion, which take the form of an integro-differential equation with a weakly singu- lar convolution kernel. -

A Brief Introduction to Numerical Methods for Differential Equations
A Brief Introduction to Numerical Methods for Differential Equations January 10, 2011 This tutorial introduces some basic numerical computation techniques that are useful for the simulation and analysis of complex systems modelled by differential equations. Such differential models, especially those partial differential ones, have been extensively used in various areas from astronomy to biology, from meteorology to finance. However, if we ignore the differences caused by applications and focus on the mathematical equations only, a fundamental question will arise: Can we predict the future state of a system from a known initial state and the rules describing how it changes? If we can, how to make the prediction? This problem, known as Initial Value Problem(IVP), is one of those problems that we are most concerned about in numerical analysis for differential equations. In this tutorial, Euler method is used to solve this problem and a concrete example of differential equations, the heat diffusion equation, is given to demonstrate the techniques talked about. But before introducing Euler method, numerical differentiation is discussed as a prelude to make you more comfortable with numerical methods. 1 Numerical Differentiation 1.1 Basic: Forward Difference Derivatives of some simple functions can be easily computed. However, if the function is too compli- cated, or we only know the values of the function at several discrete points, numerical differentiation is a tool we can rely on. Numerical differentiation follows an intuitive procedure. Recall what we know about the defini- tion of differentiation: df f(x + h) − f(x) = f 0(x) = lim dx h!0 h which means that the derivative of function f(x) at point x is the difference between f(x + h) and f(x) divided by an infinitesimal h. -

Oscillation-Free Method for Semilinear Diffusion Equations Under
Oscillation-free method for semilinear diffusion equations under noisy initial conditions R. C. Harwooda,∗, Likun Zhangb, V. S. Manoranjanc aDepartment of Mathematics, George Fox University, Newberg, OR 97132, USA bDepartment of Physics and Center for Nonlinear Dynamics, University of Texas at Austin, Austin, TX 78712, USA cDepartment of Mathematics, Washington State University, Pullman, WA 99164, USA Abstract Noise in initial conditions from measurement errors can create unwanted oscillations which propagate in numerical solutions. We present a technique of prohibiting such oscillation errors when solving initial-boundary-value problems of semilinear diffusion equations. Symmetric Strang splitting is applied to the equation for solving the linear diffusion and nonlinear remainder separately. An oscillation-free scheme is developed for overcoming any oscillatory behavior when numerically solving the linear diffusion portion. To demonstrate the ills of stable oscillations, we compare our method using a weighted implicit Euler scheme to the Crank-Nicolson method. The oscillation-free feature and stability of our method are analyzed through a local linearization. The accuracy of our oscillation-free method is proved and its usefulness is further verified through solving a Fisher-type equation where oscillation-free solutions are successfully produced in spite of random errors in the initial conditions. Keywords: numerical oscillations, splitting methods, finite difference, Euler method, reaction-diffusion, semilinear parabolic partial differential equation arXiv:1607.07433v1 [math.NA] 23 Jul 2016 1. Introduction Before analyzing numerical methods for stability it is necessary that the equations they solve be well-posed and stable themselves. In this paper, we consider the ∗Corresponding author Email addresses: [email protected] (R.