(1997). “Laryngeal Complexity in Otomanguean Vowels,”
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Language EI Country Genetic Unit Speakers RI Acatepec Tlapanec 5
Language EI Country Genetic Unit Speakers RI Acatepec Tlapanec 5 Mexico Subtiapa-Tlapanec 33000 1 Alacatlatzala Mixtec 4.5 Mexico Mixtecan 23000 2 Alcozauca Mixtec 5 Mexico Mixtecan 10000 3 Aloápam Zapotec 4 Mexico Zapotecan 2100 4 Amatlán Zapotec 5 Mexico Zapotecan 6000 5 Amoltepec Mixtec 3 Mexico Mixtecan 6000 6 Ascunción Mixtepec Zapotec 1 Mexico Zapotecan 100 7 Atatláhuca Mixtec 5 Mexico Mixtecan 8300 8 Ayautla Mazatec 5 Mexico Popolocan 3500 9 Ayoquesco Zapotec 3 Mexico Zapotecan < 900 10 Ayutla Mixtec 5 Mexico Mixtecan 8500 11 Azoyú Tlapanec 1 Mexico Subtiapa-Tlapanec < 680 12 Aztingo Matlatzinca 1 Mexico Otopamean > < 100 13 Matlatzincan Cacaloxtepec Mixtec 2.5 Mexico Mixtecan < 850 14 Cajonos Zapotec 4 Mexico Zapotecan 5000 15 Central Hausteca Nahuatl 5 Mexico Uto-Aztecan 200000 16 Central Nahuatl 3 Mexico Uto-Aztecan 40000 17 Central Pame 4 Mexico Pamean 4350 18 Central Puebla Nahuatl 4.5 Mexico Uto-Aztecan 16000 19 Chaopan Zapotec 5 Mexico Zapotecan 24000 20 Chayuco Mixtec 5 Mexico Mixtecan 30000 21 Chazumba Mixtec 2 Mexico Mixtecan < 2,500 22 Chiapanec 1 Mexico Chiapanec-Mangue < 20 23 Chicahuaxtla Triqui 5 Mexico Mixtecan 6000 24 Chichicapan Zapotec 4 Mexico Zapotecan 4000 25 Chichimeca-Jonaz 3 Mexico Otopamean > < 200 26 Chichimec Chigmecatitlan Mixtec 3 Mexico Mixtecan 1600 27 Chiltepec Chinantec 3 Mexico Chinantecan < 1,000 28 Chimalapa Zoque 3.5 Mexico Zoque 4500 29 Chiquihuitlán Mazatec 3.5 Mexico Popolocan 2500 30 Chochotec 3 Mexico Popolocan 770 31 Coatecas Altas Zapotec 4 Mexico Zapotecan 5000 32 Coatepec Nahuatl 2.5 -

Presenta Eleuterio García Hernández
COMISIÓN NACIONAL PARA EL DESARROLLO DE LOS PUEBLOS INDÍGENAS MAESTRÍA EN LINGÜÍSTICA INDOAMERICANA NARRATIVA CONVERSACIONAL EN EL CHINANTECO DE TEMEXTITLÁN: UN ACERCAMIENTO A LAS NARRACIONES ORALES EN DOS GENERACIONES PRESENTA ELEUTERIO GARCÍA HERNÁNDEZ TESIS PARA OPTAR AL GRADO DE MAESTRO EN LINGÜÍSTICA INDOAMERICANA DIRECTORA: DRA. M. REGINA MARTÍNEZ CASAS México D. F. Enero de 2014 A mi madre, quien es mi verdadera maestra A mi padre (†) que, desde el cosmos donde está, es mi fuerza para hacer obras como esta A mis hermanos y a mi hermana, a quienes les debo mucho Ah, también para Miri 0 Agradecimientos Mis más profundos agradecimientos a las personas de la comunidad de Temextitlán por haberme dado todas las facilidades para grabarlas y «explotarlas». A los hombres, a las mujeres, a los niños y niñas que participaron de manera directa e indirecta y que me permitieron entender como funciona su desafiante comunidad lingüística. Agradezco a la Dra. María Regina Martínez Casas por la dirección de esta tesis. A la Dra. Rebeca Barriga Villanueva, al Dr. Mario Ernesto Chávez Peón y al Dr. Pedro Hernández López por haber leído mi borrador y por sus valiosas sugerencias. También al conjunto de mis profesores y mis compañeros en la Maestría. Mis reconocimientos a CIESAS, a CONACyT y a la CDI por hacer posible mi tránsito por esta maestría. El apoyo económico para mi manutención y para el trabajo de campo resultaron cruciales para la culminación de mi trabajo académico. 1 Tabla de contenido I. Introducción ........................................................................................................................ 6 Objetivos ............................................................................................................................................ 12 1.1 Estudios previos sobre el chinanteco y el tema de investigación ....................... -

Sistema Tonal Del Chinanteco De San Juan Quiotepec, Oaxaca
CENTRO DE INVESTIGACIONES Y ESTUDIOS SUPERIORES EN ANTROPOLOGÍA SOCIAL COMISION NACIONAL PARA EL DESARROLLO DE LOS PUEBLOS INDIGENAS MAESTRIA EN LINGÜÍSTICA INDOAMERICANA SISTEMA TONAL DEL CHINANTECO DE SAN JUAN QUIOTEPEC, OAXACA PRESENTA RAFAEL CASTILLO MARTÍNEZ TESIS PARA OPTAR AL GRADO DE MAESTRO EN LINGÜÍSTICA INDOAMERICANA DIRECTOR DE TESIS: DR. FRANCISCO ARELLANES ARELLANES México, D.F. Enero de 2012 A mis padres, Pedro y Alicia, por su apoyo y preocupación. A mis hermanos, Verónica, Maritza, Lorenzo, Cesar y Juan. A mis sobrinos Esly, Cesar Antonio y Dante. ii Agradecimientos El presente trabajo fue producto de un gran esfuerzo, no individual sino colectivo, donde estuvieron involucradas muchas personas e instituciones. Quisiera iniciar agradeciendo al Dr, Francisco Arellanes Arellanes, quien compartió conmigo sus amplios conocimientos en cuanto a la fonología y el tiempo que dedicó a la dirección de la presente tesis. A la Dra. Esther Herrera Zendejas y al Dr. Mario Ernesto Chávez Peón, les agradezco sus sabios comentarios respecto a la investigación y análisis realizados, con lo que se enriqueció mucho este trabajo. A los investigadores del Instituto Lingüístico de Verano, James Rupp, Judi Lynn Anderson, Richard Gardner, Frank Robbins, Calvin Rensch y David Foris, quienes amablemente compartieron sus conocimientos respecto a las variantes del chinanteco que han investigado. También el agradecimiento a la Maestría en Lingüística Indoamericana del Centro de Investigaciones y Estudios Superiores en Antropología Social, a los investigadores que laboran ahí por su incidencia en mi formación de posgrado. Al Consejo Nacional de Ciencia y Tecnología, le agradezco el financiamiento económico. iii ÍNDICE GENERAL ÍNDICE DE MAPAS vii ÍNDICE DE CUADROS viii ÍNDICE DE ESPECTROGRAMAS ix ABREVIATURAS USADAS xiii 0. -

Inflectional Class Complexity in the Oto-Manguean Languages Matthew Baerman, Enrique Palancar, Timothy Feist
Inflectional class complexity in the Oto-Manguean languages Matthew Baerman, Enrique Palancar, Timothy Feist To cite this version: Matthew Baerman, Enrique Palancar, Timothy Feist. Inflectional class complexity in the Oto- Manguean languages. Amerindia, Association d’Ethno-linguistique Amérindienne, 2019, 41, pp.1 - 18. hal-02428337 HAL Id: hal-02428337 https://hal.archives-ouvertes.fr/hal-02428337 Submitted on 5 Jan 2020 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. AMERINDIA 41: 1-18, 2019 Inflectional class complexity in the Oto-Manguean languages Matthew BAERMAN Surrey Morphology Group, University of Surrey Enrique L. PALANCAR SeDyL, CNRS Timothy FEIST Surrey Morphology Group, University of Surrey Abstract: In this paper we introduce the object of study of this special issue of Amerindia, the inflectional classes of the Oto-Manguean languages of Mexico, together with their most relevant typological characteristics. These languages are rich both in the variety of their inflectional systems, and in the way these are split into inflection classes. In effect, the full typological range of possible inflection class systems can be found just in this one stock of languages. This is illustrated through a survey of the variety of morphological forms, assignment principles, and paradigm structure, as well as the effects of combining multiple inflection class systems across different exponents within a single word form. -

The Mesoamerican Indian Languages Cambridge Language Surveys
THE MESOAMERICAN INDIAN LANGUAGES CAMBRIDGE LANGUAGE SURVEYS General Editors: W. Sidney Allen, B. Comrie, C. J. Fillmore, E. J. A. Henderson, F. W. Householder, R. Lass, J. Lyons, R. B. Le Page, P. H. Matthews, F. R. Palmer, R. Posner, J. L. M. Trim This series offers general accounts of all the major language families of the world. Some volumes are organized on a purely genetic basis, others on a geographical basis, whichever yields the most convenient and intelligible grouping in each case. Sometimes, as with the Australian volume, the two in any case coincide. Each volume compares and contrasts the typological features of the languages it deals with. It also treats the relevant genetic relationships, historical development, and sociolinguistic issues arising from their role and use in the world today. The intended readership is the student of linguistics or general linguist, but no special knowledge of the languages under consideration is assumed. Some volumes also have a wider appeal, like those on Australia and North America, where the future of the languages and their speakers raises important social and political issues. Already published: The languages of Australia R. M. W. Dixon The languages of the Soviet Union Bernard Comrie Forthcoming titles include: Japanese/Korean M. Shibatani and Ho-min Sohn Chinese J. Norman and Mei Tsu-lin S. E. Asia J. A. Matisoff Dravidian R. E. Asher Austronesian R. Blust Afro-Asiatic R. Hetzron North American Indian W. Chafe Slavonic R. Sussex Germanic R. Lass Celtic D. MacAulay et al. Indo-Aryan C. P. Masica Balkans 7. Ellis Creole languages J. -

Guia De Fontes E Bibliografia Sobre Línguas Indígenas E Produção Associada: Documentos Do CELIN 1
Guia de Fontes e Bibliografia sobre Línguas Indígenas e Produção Associada: Documentos do CELIN 1 Referências Completas Código da Base Autor/Organizador Título e outras informações SÉRIE LIVROS DIGITAL 1 Guia de Fontes e Bibliografia sobre Línguas Indígenas e Produção Associada Documentos do CELIN Organizadora Marília Facó Soares Colaboradores Lourdes Cristina Araújo Coimbra Thays Lacerda Adilson Moreira Fontenele Museu Nacional/ UFRJ Rio de Janeiro 2013 Editores Universidade Federal Miguel Angel Monné Barrios e Ulisses Caramaschi do Rio de Janeiro Normalização Edson Vargas da Silva e Leandra de Oliveira Reitor Diagramação e Arte-final Carlos Antônio Levi Lia Ribeiro Capa Museu Nacional Edney Souza Editoração Eletrônica Diretora William de Lima Claudia Rodrigues Ferreira de Carvalho Antonio Clovis Britto de Araujo Guilherme de Oliveira Lima Serviços de Secretaria Thiago Macedo dos Santos Editores de Área Adriano Brilhante Kury, Ficha Catalográfica Ciro Alexandre Ávila Claudia Petean Bove G943 Guia de fontes e bibliografia sobre línguas indígenas e produção Débora de Oliveira Pires associada: documentos do CELIN / organizadora, Marília Facó Guilherme Ramos da Silva Muricy Soares; colaboradores, Lo urdes Cristina Araújo Coimbra ... [et ai.]. - Rio de Janeiro: Museu Nacional, 2013. lzabel Cristina Alves Dias 3.581 Kb; PDF João Alves de Oliveira João Wagner de Alencar Castro Com a colaboração de: Thays Lacerda, Adilson Moreira Fontenele. Marcela Laura Monné Freire ISBN 978-85-7427-047-0 Marcelo de Araújo Carvalho 1. Línguas indígenas - Bibliografias. 1. Soares, Marília Facó. 11. Marcos Raposo Coimbra, Lourdes Cristina Araújo. Ili. Lacerda, Thays. IV. Fontenele, Maria Dulce Barcellos Gaspar de Oliveira Adilson Moreira. V. Museu Nacional (Brasil). VI. Série. -

Bayesian Models for Multilingual Word Alignment
Bayesian Models for Multilingual Word Alignment Robert Östling Academic dissertation for the Degree of Doctor of Philosophy in Linguistics at Stockholm University to be publicly defended on Friday 22 May 2015 at 13.00 in hörsal 5, hus B, Universitetsvägen 10 B. Abstract In this thesis I explore Bayesian models for word alignment, how they can be improved through joint annotation transfer, and how they can be extended to parallel texts in more than two languages. In addition to these general methodological developments, I apply the algorithms to problems from sign language research and linguistic typology. In the first part of the thesis, I show how Bayesian alignment models estimated with Gibbs sampling are more accurate than previous methods for a range of different languages, particularly for languages with few digital resources available —which is unfortunately the state of the vast majority of languages today. Furthermore, I explore how different variations to the models and learning algorithms affect alignment accuracy. Then, I show how part-of-speech annotation transfer can be performed jointly with word alignment to improve word alignment accuracy. I apply these models to help annotate the Swedish Sign Language Corpus (SSLC) with part-of-speech tags, and to investigate patterns of polysemy across the languages of the world. Finally, I present a model for multilingual word alignment which learns an intermediate representation of the text. This model is then used with a massively parallel corpus containing translations of the New Testament, to explore word order features in 1001 languages. Keywords: word alignment, parallel text, Bayesian models, MCMC, linguistic typology, sign language, annotation transfer, transfer learning. -

Code Alpha-3 Pour Un Traitement Exhaustif Des Langues
PROJET DE NORME INTERNATIONALE ISO/DIS 639-3 ISO/TC 37/SC 2 Secrétariat: SCC Début de vote: Vote clos le: 2005-02-04 2005-07-04 INTERNATIONAL ORGANIZATION FOR STANDARDIZATION • МЕЖДУНАРОДНАЯ ОРГАНИЗАЦИЯ ПО СТАНДАРТИЗАЦИИ • ORGANISATION INTERNATIONALE DE NORMALISATION Codes pour la représentation des noms de langues — Partie 3: Code alpha-3 pour un traitement exhaustif des langues Codes for the representation of names of languages — Part 3: Alpha-3 code for comprehensive coverage of languages ICS 01.140.20 Pour accélérer la distribution, le présent document est distribué tel qu'il est parvenu du secrétariat du comité. Le travail de rédaction et de composition de texte sera effectué au Secrétariat central de l'ISO au stade de publication. To expedite distribution, this document is circulated as received from the committee secretariat. ISO Central Secretariat work of editing and text composition will be undertaken at publication stage. CE DOCUMENT EST UN PROJET DIFFUSÉ POUR OBSERVATIONS ET APPROBATION. IL EST DONC SUSCEPTIBLE DE MODIFICATION ET NE PEUT ÊTRE CITÉ COMME NORME INTERNATIONALE AVANT SA PUBLICATION EN TANT QUE TELLE. OUTRE LE FAIT D'ÊTRE EXAMINÉS POUR ÉTABLIR S'ILS SONT ACCEPTABLES À DES FINS INDUSTRIELLES, TECHNOLOGIQUES ET COMMERCIALES, AINSI QUE DU POINT DE VUE DES UTILISATEURS, LES PROJETS DE NORMES INTERNATIONALES DOIVENT PARFOIS ÊTRE CONSIDÉRÉS DU POINT DE VUE DE LEUR POSSIBILITÉ DE DEVENIR DES NORMES POUVANT SERVIR DE RÉFÉRENCE DANS LA RÉGLEMENTATION NATIONALE. © Organisation internationale de normalisation, 2005 ISO/DIS 639-3 PDF — Exonération de responsabilité Le présent fichier PDF peut contenir des polices de caractères intégrées. Conformément aux conditions de licence d'Adobe, ce fichier peut être imprimé ou visualisé, mais ne doit pas être modifié à moins que l'ordinateur employé à cet effet ne bénéficie d'une licence autorisant l'utilisation de ces polices et que celles-ci y soient installées. -

6. the Languages of Middle America Harry Van Der Hulst, Keren Rice
1 6. The Languages of Middle America 2 3 4 5 Harry van der Hulst, Keren Rice, and Leo Wetzels 6 7 1. Introduction1 8 9 10 In this chapter, we present a survey of word prosodic systems in the lan- guages of Middle America (Campbell 1997: Chapter 5). Middle America 11 includes Central America and Mexico. The term ‘Middle America’, refer- 12 13 ring to a geographical unit, is not synonymous to ‘Mesoamerica,’ which refers to a culture area ‘‘defined on the basis of common characteristics 14 that were present during the conquest times’’ (Sua´rez 1983: 11). Bearing 15 16 this di¤erence in mind, we here o¤er a survey of the families and isolate ´ 17 languages that Suarez groups within the Mesoamerican group and that Campbell (1997) considers in his chapter on ‘Middle American’ languages; 18 19 this does not include the ‘West Indies’ (Antilles, Bahamas, Turks and 20 Caico islands) or Cuba. 21 22 23 2. The language families 24 25 Some language families fall almost completely within the Middle American 26 region, while others only have a few representatives. To the former group belong: 27 28 29 (1) – Oto-Manguean (section 5.1.) 30 – Mixe-Zoquean (section 5.2.) 31 – Totonacan (section 5.3.) 32 – Tequistlatecan (section 5.4.) 33 34 – Mayan (section 5.5.) 35 – Misumalpan (section 5.6.) 36 37 38 1. During the writing of this chapter we have received useful input from various 39 people, including Lyle Campbell, Esther Herrera, Diane Hintz, Jean-Le´o 40 Le´onard, Inga McKendry, Irina Monich, Keith Snider, and Rebecca Yarrish. -

Protestant Education Among Indigenous Mexicans: the Social Impact of the Summer Institute of Linguistics (SIL), 1935-1970
Munich Personal RePEc Archive Protestant Education among Indigenous Mexicans: The Social Impact of the Summer Institute of Linguistics (SIL), 1935-1970 Paxman, Andrew Centro de Investigación y Docencia Económicas (CIDE) 12 August 2021 Online at https://mpra.ub.uni-muenchen.de/109187/ MPRA Paper No. 109187, posted 21 Aug 2021 13:50 UTC 1 Protestant Education among Indigenous Mexicans: The Social Impact of the Summer Institute of Linguistics (SIL), 1935-1970 Andrew Paxman CIDE, Mexico/Latin American Centre, University of Oxford, UK1 31 July 2021 [amended 12 Aug.] 1. Introduction In 1935, two U.S. Protestant missionaries took up residence in distinct indigenous Mexican towns, Tetelcingo, Morelos and San Miguel el Grande, Oaxaca, and began learning the vernacular languages, Nahuatl and Mixtec. These men were William Cameron Townsend, founder of newly-minted organisation the Summer Institute of Linguistics (SIL) and a veteran of the Guatemalan mission field, and Kenneth Pike, a recent college graduate with an unusual gift for languages. Their aim was to become sufficiently proficient in the local dialects to be able to translate into them the New Testament, for they believed that only through direct access to God’s word – rather than through the customary mediation of Catholic priests, who were almost uniformly monolingual Spanish-speakers – could indigenous souls be saved. Their endeavours were unusual for three reasons. Prior to Townsend, although there had been occasional translations of scripture into indigenous languages, few if any Protestant missionaries in the Americas had combined long-term residence in the field with a commitment to rendering the gospel into a local tongue. -
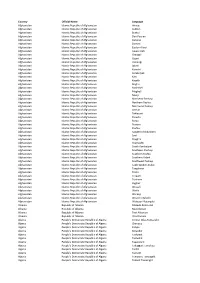
Missing Languages
Country Official Name Language Afghanistan Islamic Republic of Afghanistan Aimaq Afghanistan Islamic Republic of Afghanistan Ashkun Afghanistan Islamic Republic of Afghanistan Brahui Afghanistan Islamic Republic of Afghanistan Dari Persian Afghanistan Islamic Republic of Afghanistan Darwazi Afghanistan Islamic Republic of Afghanistan Domari Afghanistan Islamic Republic of Afghanistan Eastern Farsi Afghanistan Islamic Republic of Afghanistan Gawar-Bati Afghanistan Islamic Republic of Afghanistan Grangali Afghanistan Islamic Republic of Afghanistan Gujari Afghanistan Islamic Republic of Afghanistan Hazaragi Afghanistan Islamic Republic of Afghanistan Jakati Afghanistan Islamic Republic of Afghanistan Kamviri Afghanistan Islamic Republic of Afghanistan Karakalpak Afghanistan Islamic Republic of Afghanistan Kati Afghanistan Islamic Republic of Afghanistan Kazakh Afghanistan Islamic Republic of Afghanistan Kirghiz Afghanistan Islamic Republic of Afghanistan Malakhel Afghanistan Islamic Republic of Afghanistan Mogholi Afghanistan Islamic Republic of Afghanistan Munji Afghanistan Islamic Republic of Afghanistan Northeast Pashayi Afghanistan Islamic Republic of Afghanistan Northern Pashto Afghanistan Islamic Republic of Afghanistan Northwest Pashayi Afghanistan Islamic Republic of Afghanistan Ormuri Afghanistan Islamic Republic of Afghanistan Pahlavani Afghanistan Islamic Republic of Afghanistan Parachi Afghanistan Islamic Republic of Afghanistan Parya Afghanistan Islamic Republic of Afghanistan Prasuni Afghanistan Islamic Republic of Afghanistan -

Some Principles on the Use of Macro-Areas in Typological Comparison
Language Dynamics and Change 4 (2014) 167–187 brill.com/ldc Some Principles on the Use of Macro-Areas in Typological Comparison Harald Hammarström Max Planck Institute for Psycholinguistics & Centre for Language Studies, Radboud Universiteit Nijmegen, The Netherlands [email protected] Mark Donohue Department of Linguistics, Australian National University, Australia [email protected] Abstract While the notion of the ‘area’ or ‘Sprachbund’ has a long history in linguistics, with geographically-defined regions frequently cited as a useful means to explain typolog- ical distributions, the problem of delimiting areas has not been well addressed. Lists of general-purpose, largely independent ‘macro-areas’ (typically continent size) have been proposed as a step to rule out contact as an explanation for various large-scale linguistic phenomena. This squib points out some problems in some of the currently widely-used predetermined areas, those found in the World Atlas of Language Struc- tures (Haspelmath et al., 2005). Instead, we propose a principled division of the world’s landmasses into six macro-areas that arguably have better geographical independence properties. Keywords areality – macro-areas – typology – linguistic area 1 Areas and Areality The investigation of language according to area has a long tradition (dating to at least as early as Hervás y Panduro, 1971 [1799], who draws few historical © koninklijke brill nv, leiden, 2014 | doi: 10.1163/22105832-00401001 168 hammarström and donohue conclusions, or Kopitar, 1829, who is more interested in historical inference), and is increasingly seen as just as relevant for understanding a language’s history as the investigation of its line of descent, as revealed through the application of the comparative method.