Stay Hungry, Stay Focused: Generating Informative and Specific
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

THE CAMPUS of Allegheny College
THE CAMPUS of Allegheny College Volume 108, Number 2 Meadville, Pa. Published Since 1876 October 3, 1984 Kerosene Heater Suspected Morning Blaze Takes Eight Lives Compiled by Meadville Tribune staff reports and Associated Press reports. Eight people, including seven children between the ages of 8 months and 9 years, died in a 4:45 a.m. fire Sunday at 1186 Cussewago Terrace. Sixty volunteer firefighters from Vernon Central, Vernon Township and West Mead 1 Volunteer Fire Departments re- sponded to the call, and took an hour to bring the fire under control. "It hits you hard, real hard, " said Vernon Township Fire Chief Bill Reichel. According to Crawford County Coroner Arden G. Hughes, dead from asphyxiation due to carbon monoxide poison- ing are Shirley A. Swartz, 46, and her grandchildren Winona D. Robey, 5, Adam J. Robey, 3, and Miranda E, Robey, 8 months. Also dead are: Jason P. Baily, 9, Michael Bailey, 8, Anthony E. Bailey, 6, and Melissa S. Onesky, 21 months. Hughes said autopsies were not performed, but cause of death was determined by labor- atory studies of blood samples taken from the deceased. Hughes said the Baileys and the Onesky child were being cared for overnight at the house. Unconfirmed reports from fire An abandoned hobby horse presents a stark image as firefighters tend to a victim of Sunday morning's fire. Tribune Photo by Ed Mailliard officials and neighbors indica- ted the four were grandchildren and were waiting to be rescued; and a foster grandchild, respec- the other five victims tively, of Mrs. Swartz. died on the second floor, Escaping the blaze without according to Tom Benak, Alcohol Board Selected injury were Mrs. -

Barbara Mandigo Kelly Peace Poetry Contest Winners
The Gathering by Ana Reisens Adult Category, First Place In the movie we sleep fearlessly on open planes because we cannot imagine any danger more tragic than those that have already passed. For weeks we have been arriving over the earth’s broken skin, over mountains and rivers, shaking the aching flagpoles from our shoulders. Now all the priests and imams and rabbis and shamans are gathered beside the others, teachers, brothers and kings and they’re sharing recipes and cooking sweet stories over fires. Suddenly we hear a voice calling from the sky or within – or is it a radio? – and it sings of quilts and white lilies as if wool and petals were engines. It’s a lullaby, a prayer we all understand, familiar like the scent of a lover’s skin. And as we listen we remember our grandmothers’ hands, the knitted strength of staying, how silence rises like warmth from a woven blanket. And slowly the lines begin to disappear from our skin and our memories spin until we’ve forgotten the I of our own histories and everyone is holy, everyone is laughing, weeping, singing, It’s over, come over, come in. And this is it, the story, an allegory, our movie – the ending and a beginning. The producer doesn’t want to take the risk. No one will watch it, he says, but we say, Just wait. All the while a familiar song plays on the radio and somewhere in a desert far away a soldier in a tank stops as if he’s forgotten the way. -

Helena Mace Song List 2010S Adam Lambert – Mad World Adele – Don't You Remember Adele – Hiding My Heart Away Adele
Helena Mace Song List 2010s Adam Lambert – Mad World Adele – Don’t You Remember Adele – Hiding My Heart Away Adele – One And Only Adele – Set Fire To The Rain Adele- Skyfall Adele – Someone Like You Birdy – Skinny Love Bradley Cooper and Lady Gaga - Shallow Bruno Mars – Marry You Bruno Mars – Just The Way You Are Caro Emerald – That Man Charlene Soraia – Wherever You Will Go Christina Perri – Jar Of Hearts David Guetta – Titanium - acoustic version The Chicks – Travelling Soldier Emeli Sande – Next To Me Emeli Sande – Read All About It Part 3 Ella Henderson – Ghost Ella Henderson - Yours Gabrielle Aplin – The Power Of Love Idina Menzel - Let It Go Imelda May – Big Bad Handsome Man Imelda May – Tainted Love James Blunt – Goodbye My Lover John Legend – All Of Me Katy Perry – Firework Lady Gaga – Born This Way – acoustic version Lady Gaga – Edge of Glory – acoustic version Lily Allen – Somewhere Only We Know Paloma Faith – Never Tear Us Apart Paloma Faith – Upside Down Pink - Try Rihanna – Only Girl In The World Sam Smith – Stay With Me Sia – California Dreamin’ (Mamas and Papas) 2000s Alicia Keys – Empire State Of Mind Alexandra Burke - Hallelujah Adele – Make You Feel My Love Amy Winehouse – Love Is A Losing Game Amy Winehouse – Valerie Amy Winehouse – Will You Love Me Tomorrow Amy Winehouse – Back To Black Amy Winehouse – You Know I’m No Good Coldplay – Fix You Coldplay - Yellow Daughtry/Gaga – Poker Face Diana Krall – Just The Way You Are Diana Krall – Fly Me To The Moon Diana Krall – Cry Me A River DJ Sammy – Heaven – slow version Duffy -

Artist Song Title N/A Swedish National Anthem 411 Dumb 702 I Still Love
Artist Song Title N/A Swedish National Anthem 411 Dumb 702 I Still Love You 911 A Little Bit More 911 All I Want Is You 911 How Do You Want Me To Love You 911 Party People (Friday Night) 911 Private Number 911 The Journey 911 More Than A Woman 1927 Compulsory Hero 1927 If I Could 1927 That's When I Think Of You Ariana Grande Dangerous Woman "Weird Al" Yankovic Ebay "Weird Al" Yankovic Men In Brown "Weird Al" Yankovic Eat It "Weird Al" Yankovic White & Nerdy *NSYNC Bye Bye Bye *NSYNC (God Must Have Spent) A Little More Time On You *NSYNC I'll Never Stop *NSYNC It's Gonna Be Me *NSYNC No Strings Attached *NSYNC Pop *NSYNC Tearin' Up My Heart *NSYNC That's When I'll Stop Loving You *NSYNC This I Promise You *NSYNC You Drive Me Crazy *NSYNC I Want You Back *NSYNC Feat. Nelly Girlfriend £1 Fish Man One Pound Fish 101 Dalmations Cruella DeVil 10cc Donna 10cc Dreadlock Holiday 10cc I'm Mandy 10cc I'm Not In Love 10cc Rubber Bullets 10cc The Things We Do For Love 10cc Wall Street Shuffle 10cc Don't Turn Me Away 10cc Feel The Love 10cc Food For Thought 10cc Good Morning Judge 10cc Life Is A Minestrone 10cc One Two Five 10cc People In Love 10cc Silly Love 10cc Woman In Love 1910 Fruitgum Co. Simon Says 1999 Man United Squad Lift It High (All About Belief) 2 Evisa Oh La La La 2 Pac Feat. Dr. Dre California Love 2 Unlimited No Limit 21st Century Girls 21st Century Girls 2nd Baptist Church (Lauren James Camey) Rise Up 2Pac Dear Mama 2Pac Changes 2Pac & Notorious B.I.G. -

Yazoo Discography
Yazoo discography This discography was created on basis of web resources (special thanks to Eugenio Lopez at www.yazoo.org.uk and Matti Särngren at hem.spray.se/lillemej) and my own collection (marked *). Whenever there is doubt whether a certain release exists, this is indicated. The list is definitely not complete. Many more editions must exist in European countries. Also, there must be a myriad of promo’s out there. I have only included those and other variations (such as red vinyl releases) if I have at least one well documented source. Also, the list of covers is far from complete and I would really appreciate any input. There are four sections: 1. Albums, official releases 2. Singles, official releases 3. Live, bootlegs, mixes and samples 4. Covers (Christian Jongeneel 21-03-2016) 1 1 Albums Upstairs at Eric’s Yazoo 1982 (some 1983) A: Don’t go (3:06) B: Only you (3:12) Too pieces (3:12) Goodbye seventies (2:35) Bad connection (3:17) Tuesday (3:20) I before e except after c (4:38) Winter kills (4:02) Midnight (4:18) Bring your love down (didn’t I) (4:40) In my room (3:50) LP UK Mute STUMM 7 LP France Vogue 540037 * LP Germany Intercord INT 146.803 LP Spain RCA Victor SPL 1-7366 Lyrics on separate sheet ‘Arriba donde Eric’ * LP Spain RCA Victor SPL 1-7366 White label promo LP Spain Sanni Records STUMM 7 Reissue, 1990 * LP Sweden Mute STUMM 7 Marked NCB on label LP Greece Polygram/Mute 4502 Lyrics on separate sheet * LP Japan Sire P-11257 Lyrics on separate sheets (english & japanese) * LP Australia Mute POW 6044 Gatefold sleeve LP Yugoslavia RTL LL 0839 * Cass UK Mute C STUMM 7 * Cass Germany Intercord INT 446.803 Cass France Vogue 740037 Cass Spain RCA Victor SPK1 7366 Reissue, 1990 Cass Spain Sanni Records CSTUMM 7 Different case sleeve Cass India Mute C-STUMM 7 Cass Japan Sire PKF-5356 Cass Czech Rep. -

When God Whispers Your Name Your Special Gift
Also by Max Lucado INSPIRATIONAL Best of All 3:16 Coming Home A Gentle Thunder He Chose You A Love Worth Giving Hermie, a Common Caterpillar And the Angels Were Silent Hermie and Friends Bible Come Thirsty If Only I Had a Green Nose Cure for the Common Life Jacob’s Gift Every Day Deserves a Chance Just in Case You Ever Wonder Facing Your Giants Just Like Jesus (for teens) God Came Near Just the Way You Are He Chose the Nails Milo, the Mantis Who He Still Moves Stones Wouldn’t Pray In the Eye of the Storm Next Door Savior (for teens) In the Grip of Grace Punchinello and the Most It’s Not About Me Marvelous Gift Just Like Jesus Small Gifts in God’s Hands Next Door Savior Stanley the Stinkbug No Wonder They Call Him Tell Me the Secrets the Savior Tell Me the Story On the Anvil The Crippled Lamb Six Hours One Friday The Oak Inside the Acorn The Applause of Heaven The Way Home The Great House of God With You All the Way Traveling Light You Are Mine When Christ Comes You Are Special When God Whispers Your Name Your Special Gift CHILDREN’S BOOKS GIFT BOOKS All You Ever Need A Heart Like Jesus Because I Love You Everyday Blessings For These Tough Times The Greatest Moments God’s Mirror Traveling Light for Mothers God’s Promises for You Traveling Light Journal God Thinks You’re Wonderful Turn Grace for the Moment, Vol. I & II Walking with the Savior Grace for the Moment Journal You: God’s Brand-New Idea! In the Beginning Just for You FICTION Just Like Jesus Devotional An Angel’s Story Let the Journey Begin The Christmas Candle Max on Life Series The Christmas Child Mocha with Max BIBLES (GENERAL EDITOR) One Incredible Moment He Did This Just for You Safe in the Shepherd’s Arms (New Testament) Shaped by God The Devotional Bible The Cross Grace for the Moment Daily Bible The Gift for All People W HEN G OD W HISPERS Y OUR N AME This page intentionally left blank W HEN G OD W HISPERS Y OUR N AME MAX LUCADO © 1994, 1999 by Max Lucado All rights reserved. -

NOW WAP's WHAT I CALL MUSIC! Submitted By: Immediate Future Friday, 20 January 2006
NOW WAP'S WHAT I CALL MUSIC! Submitted by: Immediate Future Friday, 20 January 2006 EMI Music UK puts pop stars in your pocket with launch of mobile music store wap.the-raft.com bringing together music downloads, ringtones & videos from EMI Records, Virgin Records, Parlophone, Angel and Catalogue - http://wapinfo.the-raft.com Calling all music fans… Fancy going home with a Brit tonight? EMI Music UK extends ‘The Raft’ online music store from web to mobile with the launch of its mobile music site (http://wapinfo.the-raft.com). By texting ‘GO RAFT’ to 85080 (free text from all networks), music lovers will be able to access official artist news, breaking tour dates, music downloads and video, competitions and artist approved ringtones and realtones. And if you’ve got a bit of a creative urge yourself, you’ll be able to customise your own tracks by adding beats or special features to turn them into personalised ringtones (http://wapinfo.the-raft.com). Be the envy of all your friends with your totally exclusive ringtones! You’ll be kept up to date with the latest news and featured artist areas which include Artist A-Zs and weekly competitions in anyone of the following categories; pop, urban, dance, jazz and rock. Wap.the-raft.com (http://wapinfo.the-raft.com) will also host the UK top 10 ringtones plus specialist charts like alternative and Bollywood. Competitions include money-can’t-buy exclusive artist merchandise plus album collections—such as the Brits collection; a bumper hamper of Brits-nominated albums Wap.the-raft.com provides something for every music fan—in an easy-to-find mobile music format. -

A Thousand Years Christina Perri Old Devil Called Love Alison
Mob 07973 146244 www.katiehalliday.co.uk A Thousand Years Christina Perri Old Devil Called Love Alison Moyet Amazed Lonestar One Night Only Jennifer Hudson Angels Robbie Williams Only Girl In The World Ellie Goulding Harp Arr Are You Ready For Love Elton John Ordinary People John Legend As If We Never Said Goodbye Barbara Streisand Other Side Of The World KT Tunstall At Last Etta James Over The Rainbow Eva Cassidy Beautiful Christina Aguilera Patience Take That Better The Devil You Know Kylie (swing arrangement) Promise This Cheryl Cole Bleeding Love Leona Lewis Purple Rain Prince Can’t Stop The Feeling Justin Timberlake Runaway The Corrs Chasing Cars Snow Patrol Say What You Want Texas Closest Thing To Crazy Katie Melua Search For A Hero M People Come Away With Me Norah Jones Sex On Fire (acoustic) Kings Of Leon Dance With My Father Celine Dion version Show Me Heaven Maria McKee Days Of Our Lives Queen Skyfall Adele Diamonds Are A Girls' Best Friend Moulin Rouge Someone Like You Adele Don't Know Why Norah Jones Songbird Eva Cassidy Downtown Petula Clarke Slow Rumer Evergreen Will Young Stop Crying Your Heart Out Oasis Everything I Do I Do It For You Bryan Adams Super Dooper Love Joss Stone Falling Alicia Keys Sway Micheal Buble Falling Into You Celine Dion Sweet About Me Gabrella Cilmi Father Figure/Faith Medley George Michael Sweetest Feeling Jackie Wilson Feeling Good Nina Simone Tell Me I'm Not Dreaming Katherine Jenkins First Time Ever I Saw Your Face Roberta Flack Thankyou Dido From This Moment Shania Twain The One Kodaline Get -

Songs by Title
Karaoke Box London www.karaokebox.co.uk 020 7329 9991 Song Title Artist 22 Taylor Swift 1234 Feist 1901 Birdy 1959 Lee Kernaghan 1973 James Blunt 1973 James Blunt 1983 Neon Trees 1985 Bowling For Soup 1999 Prince If U Got It Chris Malinchak Strong One Direction XO Beyonce (Baby Ive Got You) On My Mind Powderfinger (Barry) Islands In The Stream Comic Relief (Call Me) Number One The Tremeloes (Cant Start) Giving You Up Kylie Minogue (Doo Wop) That Thing Lauren Hill (Everybody's Gotta Learn Sometime) I Need Your Loving Baby D (Everything I Do) I Do It For You Bryan Adams (Hey Wont You Play) Another Somebody… B. J. Thomas (How Does It Feel To Be) On Top Of The World England United (I Am Not A) Robot Marina And The Diamonds (I Love You) For Sentinmental Reasons Nat King Cole (If Paradise Is) Half As Nice Amen Corner (Ill Never Be) Maria Magdalena Sandra (I've Had) The Time Of My Life Bill Medley and Jennifer Warnes (Just Like) Romeo And Juliet The Reflections (Just Like) Starting Over John Lennon (Keep Feeling) Fascination The Human League (Maries The Name) Of His Latest Flame Elvis Presley (Meet) The Flintstones B-52S (Mucho Mambo) Sway Shaft (Now and Then) There's A Fool Such As I Elvis Presley (Sittin On) The Dock Of The Bay Otis Redding (The Man Who Shot) Liberty Valance Gene Pitney (They Long To Be) Close To You Carpenters (We Want) The Same Thing Belinda Carlisle (Where Do I Begin) Love Story Andy Williams (You Drive Me) Crazy Britney Spears 1 2 3 4 (Sumpin New) Coolio 1 Thing Amerie 1+1 (One Plus One) Beyonce 1000 Miles Away Hoodoo Gurus -

George Michael Was Britain's Biggest Pop Star of the 1980S, First with The
George Michael was Britain’s biggest pop star of the 1980s, first with the duo Wham! and then as a solo artist. The Three Crowns played a small but significant part in his story. After Wham! made their initial chart breakthrough with the single Young Guns (Go for It) in 1982, George’s songwriting gift brought them giant hits including Wake Me Up Before You Go-Go and Freedom, and they became leading lights of the 80s boom in British pop music, alongside Duran Duran, Culture Club and Spandau Ballet, even exporting it behind the Iron Curtain. His first solo album Faith, released in 1987, sold 25 million copies, and George sold more than 100 million albums worldwide with Wham! and under his own name. George was born Georgios Kyriacos Panayiotou in Finchley, north London. His father, Kyriacos Panayiotou, was a Greek Cypriot restaurateur, and his mother an English dancer, Lesley Angold. In the late 1960s the family moved to Edgware, where George attended Kingsbury School, before they moved to the affluent Hertfordshire town of Radlett in the mid-1970s. Bushey Meads Comprehensive 1974 - 1981 George – a wimp Andy - cocksure In September 1975 a twelve year old George showed up at Bushey Meads School keen to impress as the new boy and was introduced to Andy Ridgeley who had already been impressing for a full year. Andy recalled their meeting as follows; “I remember at the time we were playing King of the Wall. As he was the new boy we goaded him into it. I was up there and he threw me off. -
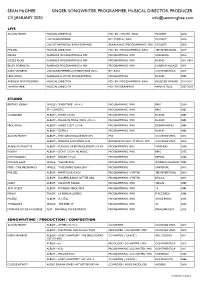
CV JANUARY 2020 [email protected]
SEAN McGHEE SINGER, SONGWRITER, PROGRAMMER, MUSICAL DIRECTOR, PRODUCER. CV JANUARY 2020 [email protected] LIVE ALISON MOYET MUSICAL DIRECTOR MD / BV / SYNTHS / BASS MODEST! 2018- LIVE BAND MEMBER BV / SYNTHS / BASS MODEST! 2013- LIVE SET ARRANGER & PROGRAMMER ARRANGING / PROGRAMMING / MIX MODEST! 2013- PHILDEL MUSICAL DIRECTOR MD / BV / PROGRAMMING / BASS YEE INVENTIONS 2019 KIESZA PLAYBACK PROGRAMMING & MIX PROGRAMMING / MIX UNIVERSAL 2014 RIZZLE KICKS PLAYBACK PROGRAMMING & MIX PROGRAMMING / MIX ISLAND 2011-2014 BLUEY ROBINSON PLAYBACK PROGRAMMING & MIX PROGRAMMING / MIX LONDON VILLAGE 2013 KATE HAVNEVIK LIVE BAND MEMBER (CHINESE TOUR 2015) BV / BASS CONTINENTICA 2015 FROU FROU PLAYBACK & SYNTH PROGRAMMING PROGRAMMING ISLAND 2003 ANDREW MONTGOMERY MUSICAL DIRECTOR MD / BV / PROGRAMMING / BASS RULED BY DREAMS 2014-2015 TEMPOSHARK MUSICAL DIRECTOR MD / PROGRAMMING PAPER & GLUE 2007-2010 STUDIO BRITNEY SPEARS SINGLE – “EVERYTIME” (UK #1) PROGRAMMING / MIX BMG 2004 EP – CHAOTIC PROGRAMMING / MIX BMG 2005 SUGABABES ALBUM – THREE (UK #3) PROGRAMMING / MIX ISLAND 2003 ALBUM – TALLER IN MORE WAYS (UK #1) PROGRAMMING / MIX ISLAND 2005 FROU FROU ALBUM – SHREK 2 OST (US #8) PROGRAMMING / MIX DREAMWORKS 2004 ALBUM – DETAILS PROGRAMMING / MIX ISLAND 2002 ALISON MOYET ALBUM – THE TURN: DELUXE EDITION MIX COOKING VINYL 2015 ALBUM – MINUTES & SECONDS LIVE BACKING VOCALS / SYNTHS / MIX COOKING VINYL 2014 ALANIS MORISSETTE ALBUM – FLAVORS OF ENTANGLEMENT (US #8) PROGRAMMING / BVs WARNERS 2008 ROBYN ALBUM – DON’T STOP THE MUSIC PROGRAMMING / MIX BMG -

KARAOKE Buch 2019 Vers 2
Wenn ihr euer gesuchtes Lied nicht im Buch findet - bitte DJ fragen Weitere 10.000 Songs in Englisch und Deutsch auf Anfrage If you can’t find your favourite song in the book – please ask the DJ More then 10.000 Songs in English and German toon request 10cc Dreadlock Holiday 3 Doors Down Here Without You 3 Doors Down Kryptonite 4 Non Blondes What's Up 50 Cent Candy Shop 50 Cent In Da Club 5th Dimension Aquarius & Let The Sunshine A Ha Take On Me Abba Dancing Queen Abba Gimme Gimme Gimme Abba Knowing Me, Knowing You Abba Mama Mia Abba Waterloo ACDC Highway To Hell ACDC T.N.T ACDC Thunderstruck ACDC You Shook Me All Night Long Ace Of Base All That She Wants Adele Chasing Pavements Adele Hello Adele Make You Feel My Love Adele Rolling In The Deep Adele Skyfall Adele Someone Like You Adrian (Bombay) Ring Of Fire Adrian Dirty Angels Adrian My Big Boner Aerosmith Dream On Aerosmith I Don’t Want To Miss A Thing Afroman Because I Got High Air Supply All Out Of Love Al Wilson The Snake Alanis Morissette Ironic Alanis Morissette You Oughta Know Alannah Miles Black Velvet Alcazar Crying at The Discotheque Alex Clare Too Close Alexandra Burke Hallelujah Alice Cooper Poison Alice Cooper School’s Out Alicia Keys Empire State Of Mind (Part 2) Alicia Keys Fallin’ Alicia Keys If I Ain’t Got You Alien Ant Farm Smooth Criminal Alison Moyet That Old Devil Called Love Aloe Blacc I Need A Dollar Alphaville Big In Japan Ami Stewart Knock On Wood Amy MacDonald This Is The Life Amy Winehouse Back To Black Amy Winehouse Rehab Amy Winehouse Valerie Anastacia I’m Outta Love Anastasia Sick & Tired Andy Williams Can’t Take My Eyes Off Of You Animals, The The House Of The Rising Sun Aqua Barbie Girl Archies, The Sugar, Sugar Arctic Monkeys I Bet You Look Good On The Dance Floor Aretha Franklin Respect Arrows, The Hot Hot Hot Atomic Kitten Eternal Flame Atomic Kitten Whole Again Avicii & Aloe Blacc Wake Me Up Avril Lavigne Complicated Avril Lavigne Sk8er Boi Aztec Camera Somewhere In My Heart Gesuchtes Lied nicht im Buch - bitte DJ fragen B.J.