Robust Fitting of Parametric Models Based on M-Estimation
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Robust Statistics Part 3: Regression Analysis
Robust Statistics Part 3: Regression analysis Peter Rousseeuw LARS-IASC School, May 2019 Peter Rousseeuw Robust Statistics, Part 3: Regression LARS-IASC School, May 2019 p. 1 Linear regression Linear regression: Outline 1 Classical regression estimators 2 Classical outlier diagnostics 3 Regression M-estimators 4 The LTS estimator 5 Outlier detection 6 Regression S-estimators and MM-estimators 7 Regression with categorical predictors 8 Software Peter Rousseeuw Robust Statistics, Part 3: Regression LARS-IASC School, May 2019 p. 2 Linear regression Classical estimators The linear regression model The linear regression model says: yi = β0 + β1xi1 + ... + βpxip + εi ′ = xiβ + εi 2 ′ ′ with i.i.d. errors εi ∼ N(0,σ ), xi = (1,xi1,...,xip) and β =(β0,β1,...,βp) . ′ Denote the n × (p + 1) matrix containing the predictors xi as X =(x1,..., xn) , ′ ′ the vector of responses y =(y1,...,yn) and the error vector ε =(ε1,...,εn) . Then: y = Xβ + ε Any regression estimate βˆ yields fitted values yˆ = Xβˆ and residuals ri = ri(βˆ)= yi − yˆi . Peter Rousseeuw Robust Statistics, Part 3: Regression LARS-IASC School, May 2019 p. 3 Linear regression Classical estimators The least squares estimator Least squares estimator n ˆ 2 βLS = argmin ri (β) β i=1 X If X has full rank, then the solution is unique and given by ˆ ′ −1 ′ βLS =(X X) X y The usual unbiased estimator of the error variance is n 1 σˆ2 = r2(βˆ ) LS n − p − 1 i LS i=1 X Peter Rousseeuw Robust Statistics, Part 3: Regression LARS-IASC School, May 2019 p. 4 Linear regression Classical estimators Outliers in regression Different types of outliers: vertical outlier good leverage point • • y • • • regular data • ••• • •• ••• • • • • • • • • • bad leverage point • • •• • x Peter Rousseeuw Robust Statistics, Part 3: Regression LARS-IASC School, May 2019 p. -

Fast Computation of the Deviance Information Criterion for Latent Variable Models
Crawford School of Public Policy CAMA Centre for Applied Macroeconomic Analysis Fast Computation of the Deviance Information Criterion for Latent Variable Models CAMA Working Paper 9/2014 January 2014 Joshua C.C. Chan Research School of Economics, ANU and Centre for Applied Macroeconomic Analysis Angelia L. Grant Centre for Applied Macroeconomic Analysis Abstract The deviance information criterion (DIC) has been widely used for Bayesian model comparison. However, recent studies have cautioned against the use of the DIC for comparing latent variable models. In particular, the DIC calculated using the conditional likelihood (obtained by conditioning on the latent variables) is found to be inappropriate, whereas the DIC computed using the integrated likelihood (obtained by integrating out the latent variables) seems to perform well. In view of this, we propose fast algorithms for computing the DIC based on the integrated likelihood for a variety of high- dimensional latent variable models. Through three empirical applications we show that the DICs based on the integrated likelihoods have much smaller numerical standard errors compared to the DICs based on the conditional likelihoods. THE AUSTRALIAN NATIONAL UNIVERSITY Keywords Bayesian model comparison, state space, factor model, vector autoregression, semiparametric JEL Classification C11, C15, C32, C52 Address for correspondence: (E) [email protected] The Centre for Applied Macroeconomic Analysis in the Crawford School of Public Policy has been established to build strong links between professional macroeconomists. It provides a forum for quality macroeconomic research and discussion of policy issues between academia, government and the private sector. The Crawford School of Public Policy is the Australian National University’s public policy school, serving and influencing Australia, Asia and the Pacific through advanced policy research, graduate and executive education, and policy impact. -

A Generalized Linear Model for Binomial Response Data
A Generalized Linear Model for Binomial Response Data Copyright c 2017 Dan Nettleton (Iowa State University) Statistics 510 1 / 46 Now suppose that instead of a Bernoulli response, we have a binomial response for each unit in an experiment or an observational study. As an example, consider the trout data set discussed on page 669 of The Statistical Sleuth, 3rd edition, by Ramsey and Schafer. Five doses of toxic substance were assigned to a total of 20 fish tanks using a completely randomized design with four tanks per dose. Copyright c 2017 Dan Nettleton (Iowa State University) Statistics 510 2 / 46 For each tank, the total number of fish and the number of fish that developed liver tumors were recorded. d=read.delim("http://dnett.github.io/S510/Trout.txt") d dose tumor total 1 0.010 9 87 2 0.010 5 86 3 0.010 2 89 4 0.010 9 85 5 0.025 30 86 6 0.025 41 86 7 0.025 27 86 8 0.025 34 88 9 0.050 54 89 10 0.050 53 86 11 0.050 64 90 12 0.050 55 88 13 0.100 71 88 14 0.100 73 89 15 0.100 65 88 16 0.100 72 90 17 0.250 66 86 18 0.250 75 82 19 0.250 72 81 20 0.250 73 89 Copyright c 2017 Dan Nettleton (Iowa State University) Statistics 510 3 / 46 One way to analyze this dataset would be to convert the binomial counts and totals into Bernoulli responses. -

Comparison of Some Chemometric Tools for Metabonomics Biomarker Identification ⁎ Réjane Rousseau A, , Bernadette Govaerts A, Michel Verleysen A,B, Bruno Boulanger C
Available online at www.sciencedirect.com Chemometrics and Intelligent Laboratory Systems 91 (2008) 54–66 www.elsevier.com/locate/chemolab Comparison of some chemometric tools for metabonomics biomarker identification ⁎ Réjane Rousseau a, , Bernadette Govaerts a, Michel Verleysen a,b, Bruno Boulanger c a Université Catholique de Louvain, Institut de Statistique, Voie du Roman Pays 20, B-1348 Louvain-la-Neuve, Belgium b Université Catholique de Louvain, Machine Learning Group - DICE, Belgium c Eli Lilly, European Early Phase Statistics, Belgium Received 29 December 2006; received in revised form 15 June 2007; accepted 22 June 2007 Available online 29 June 2007 Abstract NMR-based metabonomics discovery approaches require statistical methods to extract, from large and complex spectral databases, biomarkers or biologically significant variables that best represent defined biological conditions. This paper explores the respective effectiveness of six multivariate methods: multiple hypotheses testing, supervised extensions of principal (PCA) and independent components analysis (ICA), discriminant partial least squares, linear logistic regression and classification trees. Each method has been adapted in order to provide a biomarker score for each zone of the spectrum. These scores aim at giving to the biologist indications on which metabolites of the analyzed biofluid are potentially affected by a stressor factor of interest (e.g. toxicity of a drug, presence of a given disease or therapeutic effect of a drug). The applications of the six methods to samples of 60 and 200 spectra issued from a semi-artificial database allowed to evaluate their respective properties. In particular, their sensitivities and false discovery rates (FDR) are illustrated through receiver operating characteristics curves (ROC) and the resulting identifications are used to show their specificities and relative advantages.The paper recommends to discard two methods for biomarker identification: the PCA showing a general low efficiency and the CART which is very sensitive to noise. -

Quantile Regression for Overdispersed Count Data: a Hierarchical Method Peter Congdon
Congdon Journal of Statistical Distributions and Applications (2017) 4:18 DOI 10.1186/s40488-017-0073-4 RESEARCH Open Access Quantile regression for overdispersed count data: a hierarchical method Peter Congdon Correspondence: [email protected] Abstract Queen Mary University of London, London, UK Generalized Poisson regression is commonly applied to overdispersed count data, and focused on modelling the conditional mean of the response. However, conditional mean regression models may be sensitive to response outliers and provide no information on other conditional distribution features of the response. We consider instead a hierarchical approach to quantile regression of overdispersed count data. This approach has the benefits of effective outlier detection and robust estimation in the presence of outliers, and in health applications, that quantile estimates can reflect risk factors. The technique is first illustrated with simulated overdispersed counts subject to contamination, such that estimates from conditional mean regression are adversely affected. A real application involves ambulatory care sensitive emergency admissions across 7518 English patient general practitioner (GP) practices. Predictors are GP practice deprivation, patient satisfaction with care and opening hours, and region. Impacts of deprivation are particularly important in policy terms as indicating effectiveness of efforts to reduce inequalities in care sensitive admissions. Hierarchical quantile count regression is used to develop profiles of central and extreme quantiles according to specified predictor combinations. Keywords: Quantile regression, Overdispersion, Poisson, Count data, Ambulatory sensitive, Median regression, Deprivation, Outliers 1. Background Extensions of Poisson regression are commonly applied to overdispersed count data, focused on modelling the conditional mean of the response. However, conditional mean regression models may be sensitive to response outliers. -
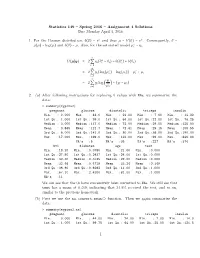
Statistics 149 – Spring 2016 – Assignment 4 Solutions Due Monday April 4, 2016 1. for the Poisson Distribution, B(Θ) =
Statistics 149 { Spring 2016 { Assignment 4 Solutions Due Monday April 4, 2016 1. For the Poisson distribution, b(θ) = eθ and thus µ = b′(θ) = eθ. Consequently, θ = ∗ g(µ) = log(µ) and b(θ) = µ. Also, for the saturated model µi = yi. n ∗ ∗ D(µSy) = 2 Q yi(θi − θi) − b(θi ) + b(θi) i=1 n ∗ ∗ = 2 Q yi(log(µi ) − log(µi)) − µi + µi i=1 n yi = 2 Q yi log − (yi − µi) i=1 µi 2. (a) After following instructions for replacing 0 values with NAs, we summarize the data: > summary(mypima2) pregnant glucose diastolic triceps insulin Min. : 0.000 Min. : 44.0 Min. : 24.00 Min. : 7.00 Min. : 14.00 1st Qu.: 1.000 1st Qu.: 99.0 1st Qu.: 64.00 1st Qu.:22.00 1st Qu.: 76.25 Median : 3.000 Median :117.0 Median : 72.00 Median :29.00 Median :125.00 Mean : 3.845 Mean :121.7 Mean : 72.41 Mean :29.15 Mean :155.55 3rd Qu.: 6.000 3rd Qu.:141.0 3rd Qu.: 80.00 3rd Qu.:36.00 3rd Qu.:190.00 Max. :17.000 Max. :199.0 Max. :122.00 Max. :99.00 Max. :846.00 NA's :5 NA's :35 NA's :227 NA's :374 bmi diabetes age test Min. :18.20 Min. :0.0780 Min. :21.00 Min. :0.000 1st Qu.:27.50 1st Qu.:0.2437 1st Qu.:24.00 1st Qu.:0.000 Median :32.30 Median :0.3725 Median :29.00 Median :0.000 Mean :32.46 Mean :0.4719 Mean :33.24 Mean :0.349 3rd Qu.:36.60 3rd Qu.:0.6262 3rd Qu.:41.00 3rd Qu.:1.000 Max. -

Bayesian Methods: Review of Generalized Linear Models
Bayesian Methods: Review of Generalized Linear Models RYAN BAKKER University of Georgia ICPSR Day 2 Bayesian Methods: GLM [1] Likelihood and Maximum Likelihood Principles Likelihood theory is an important part of Bayesian inference: it is how the data enter the model. • The basis is Fisher’s principle: what value of the unknown parameter is “most likely” to have • generated the observed data. Example: flip a coin 10 times, get 5 heads. MLE for p is 0.5. • This is easily the most common and well-understood general estimation process. • Bayesian Methods: GLM [2] Starting details: • – Y is a n k design or observation matrix, θ is a k 1 unknown coefficient vector to be esti- × × mated, we want p(θ Y) (joint sampling distribution or posterior) from p(Y θ) (joint probabil- | | ity function). – Define the likelihood function: n L(θ Y) = p(Y θ) | i| i=1 Y which is no longer on the probability metric. – Our goal is the maximum likelihood value of θ: θˆ : L(θˆ Y) L(θ Y) θ Θ | ≥ | ∀ ∈ where Θ is the class of admissable values for θ. Bayesian Methods: GLM [3] Likelihood and Maximum Likelihood Principles (cont.) Its actually easier to work with the natural log of the likelihood function: • `(θ Y) = log L(θ Y) | | We also find it useful to work with the score function, the first derivative of the log likelihood func- • tion with respect to the parameters of interest: ∂ `˙(θ Y) = `(θ Y) | ∂θ | Setting `˙(θ Y) equal to zero and solving gives the MLE: θˆ, the “most likely” value of θ from the • | parameter space Θ treating the observed data as given. -

Robust Linear Regression: a Review and Comparison Arxiv:1404.6274
Robust Linear Regression: A Review and Comparison Chun Yu1, Weixin Yao1, and Xue Bai1 1Department of Statistics, Kansas State University, Manhattan, Kansas, USA 66506-0802. Abstract Ordinary least-squares (OLS) estimators for a linear model are very sensitive to unusual values in the design space or outliers among y values. Even one single atypical value may have a large effect on the parameter estimates. This article aims to review and describe some available and popular robust techniques, including some recent developed ones, and compare them in terms of breakdown point and efficiency. In addition, we also use a simulation study and a real data application to compare the performance of existing robust methods under different scenarios. arXiv:1404.6274v1 [stat.ME] 24 Apr 2014 Key words: Breakdown point; Robust estimate; Linear Regression. 1 Introduction Linear regression has been one of the most important statistical data analysis tools. Given the independent and identically distributed (iid) observations (xi; yi), i = 1; : : : ; n, 1 in order to understand how the response yis are related to the covariates xis, we tradi- tionally assume the following linear regression model T yi = xi β + "i; (1.1) where β is an unknown p × 1 vector, and the "is are i.i.d. and independent of xi with E("i j xi) = 0. The most commonly used estimate for β is the ordinary least square (OLS) estimate which minimizes the sum of squared residuals n X T 2 (yi − xi β) : (1.2) i=1 However, it is well known that the OLS estimate is extremely sensitive to the outliers. -

A Guide to Robust Statistical Methods in Neuroscience
A GUIDE TO ROBUST STATISTICAL METHODS IN NEUROSCIENCE Authors: Rand R. Wilcox1∗, Guillaume A. Rousselet2 1. Dept. of Psychology, University of Southern California, Los Angeles, CA 90089-1061, USA 2. Institute of Neuroscience and Psychology, College of Medical, Veterinary and Life Sciences, University of Glasgow, 58 Hillhead Street, G12 8QB, Glasgow, UK ∗ Corresponding author: [email protected] ABSTRACT There is a vast array of new and improved methods for comparing groups and studying associations that offer the potential for substantially increasing power, providing improved control over the probability of a Type I error, and yielding a deeper and more nuanced understanding of data. These new techniques effectively deal with four insights into when and why conventional methods can be unsatisfactory. But for the non-statistician, the vast array of new and improved techniques for comparing groups and studying associations can seem daunting, simply because there are so many new methods that are now available. The paper briefly reviews when and why conventional methods can have relatively low power and yield misleading results. The main goal is to suggest some general guidelines regarding when, how and why certain modern techniques might be used. Keywords: Non-normality, heteroscedasticity, skewed distributions, outliers, curvature. 1 1 Introduction The typical introductory statistics course covers classic methods for comparing groups (e.g., Student's t-test, the ANOVA F test and the Wilcoxon{Mann{Whitney test) and studying associations (e.g., Pearson's correlation and least squares regression). The two-sample Stu- dent's t-test and the ANOVA F test assume that sampling is from normal distributions and that the population variances are identical, which is generally known as the homoscedastic- ity assumption. -

What I Should Have Described in Class Today
Statistics 849 Clarification 2010-11-03 (p. 1) What I should have described in class today Sorry for botching the description of the deviance calculation in a generalized linear model and how it relates to the function dev.resids in a glm family object in R. Once again Chen Zuo pointed out the part that I had missed. We need to use positive contributions to the deviance for each observation if we are later to take the square roots of these quantities. To ensure that these are all positive we establish a baseline level for the deviance, which is the lowest possible value of the deviance, corresponding to a saturated model in which each observation has one parameter associated with it. Another value quoted in the summary output is the null deviance, which is the deviance for the simplest possible model (the \null model") corresponding to a formula like > data(Contraception, package = "mlmRev") > summary(cm0 <- glm(use ~ 1, binomial, Contraception)) Call: glm(formula = use ~ 1, family = binomial, data = Contraception) Deviance Residuals: Min 1Q Median 3Q Max -0.9983 -0.9983 -0.9983 1.3677 1.3677 Coefficients: Estimate Std. Error z value Pr(>|z|) (Intercept) -0.43702 0.04657 -9.385 <2e-16 (Dispersion parameter for binomial family taken to be 1) Null deviance: 2590.9 on 1933 degrees of freedom Residual deviance: 2590.9 on 1933 degrees of freedom AIC: 2592.9 Number of Fisher Scoring iterations: 4 Notice that the coefficient estimate, -0.437022, is the logit transformation of the proportion of positive responses > str(y <- as.integer(Contraception[["use"]]) - 1L) int [1:1934] 0 0 0 0 0 0 0 0 0 0 .. -

Robust Bayesian General Linear Models ⁎ W.D
www.elsevier.com/locate/ynimg NeuroImage 36 (2007) 661–671 Robust Bayesian general linear models ⁎ W.D. Penny, J. Kilner, and F. Blankenburg Wellcome Department of Imaging Neuroscience, University College London, 12 Queen Square, London WC1N 3BG, UK Received 22 September 2006; revised 20 November 2006; accepted 25 January 2007 Available online 7 May 2007 We describe a Bayesian learning algorithm for Robust General Linear them from the data (Jung et al., 1999). This is, however, a non- Models (RGLMs). The noise is modeled as a Mixture of Gaussians automatic process and will typically require user intervention to rather than the usual single Gaussian. This allows different data points disambiguate the discovered components. In fMRI, autoregressive to be associated with different noise levels and effectively provides a (AR) modeling can be used to downweight the impact of periodic robust estimation of regression coefficients. A variational inference respiratory or cardiac noise sources (Penny et al., 2003). More framework is used to prevent overfitting and provides a model order recently, a number of approaches based on robust regression have selection criterion for noise model order. This allows the RGLM to default to the usual GLM when robustness is not required. The method been applied to imaging data (Wager et al., 2005; Diedrichsen and is compared to other robust regression methods and applied to Shadmehr, 2005). These approaches relax the assumption under- synthetic data and fMRI. lying ordinary regression that the errors be normally (Wager et al., © 2007 Elsevier Inc. All rights reserved. 2005) or identically (Diedrichsen and Shadmehr, 2005) distributed. In Wager et al. -

Sketching for M-Estimators: a Unified Approach to Robust Regression
Sketching for M-Estimators: A Unified Approach to Robust Regression Kenneth L. Clarkson∗ David P. Woodruffy Abstract ing algorithm often results, since a single pass over A We give algorithms for the M-estimators minx kAx − bkG, suffices to compute SA. n×d n n where A 2 R and b 2 R , and kykG for y 2 R is specified An important property of many of these sketching ≥0 P by a cost function G : R 7! R , with kykG ≡ i G(yi). constructions is that S is a subspace embedding, meaning d The M-estimators generalize `p regression, for which G(x) = that for all x 2 R , kSAxk ≈ kAxk. (Here the vector jxjp. We first show that the Huber measure can be computed norm is generally `p for some p.) For the regression up to relative error in O(nnz(A) log n + poly(d(log n)=")) d time, where nnz(A) denotes the number of non-zero entries problem of minimizing kAx − bk with respect to x 2 R , of the matrix A. Huber is arguably the most widely used for inputs A 2 Rn×d and b 2 Rn, a minor extension of M-estimator, enjoying the robustness properties of `1 as well the embedding condition implies S preserves the norm as the smoothness properties of ` . 2 of the residual vector Ax − b, that is kS(Ax − b)k ≈ We next develop algorithms for general M-estimators. kAx − bk, so that a vector x that makes kS(Ax − b)k We analyze the M-sketch, which is a variation of a sketch small will also make kAx − bk small.