Poinet: Protein Interactome with Sub-Network Analysis and Hub
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Age Dependence of Tumor Genetics in Unfavorable
Cetinkaya et al. BMC Cancer 2013, 13:231 http://www.biomedcentral.com/1471-2407/13/231 RESEARCH ARTICLE Open Access Age dependence of tumor genetics in unfavorable neuroblastoma: arrayCGH profiles of 34 consecutive cases, using a Swedish 25-year neuroblastoma cohort for validation Cihan Cetinkaya1,2, Tommy Martinsson3, Johanna Sandgren1,4, Catarina Träger5, Per Kogner5, Jan Dumanski1, Teresita Díaz de Ståhl1,4† and Fredrik Hedborg1,6*† Abstract Background: Aggressive neuroblastoma remains a significant cause of childhood cancer death despite current intensive multimodal treatment protocols. The purpose of the present work was to characterize the genetic and clinical diversity of such tumors by high resolution arrayCGH profiling. Methods: Based on a 32K BAC whole-genome tiling path array and using 50-250K Affymetrix SNP array platforms for verification, DNA copy number profiles were generated for 34 consecutive high-risk or lethal outcome neuroblastomas. In addition, age and MYCN amplification (MNA) status were retrieved for 112 unfavorable neuroblastomas of the Swedish Childhood Cancer Registry, representing a 25-year neuroblastoma cohort of Sweden, here used for validation of the findings. Statistical tests used were: Fisher’s exact test, Bayes moderated t-test, independent samples t-test, and correlation analysis. Results: MNA or segmental 11q loss (11q-) was found in 28/34 tumors. With two exceptions, these aberrations were mutually exclusive. Children with MNA tumors were diagnosed at significantly younger ages than those with 11q- tumors (mean: 27.4 vs. 69.5 months; p=0.008; n=14/12), and MNA tumors had significantly fewer segmental chromosomal aberrations (mean: 5.5 vs. 12.0; p<0.001). -

Environmental Influences on Endothelial Gene Expression
ENDOTHELIAL CELL GENE EXPRESSION John Matthew Jeff Herbert Supervisors: Prof. Roy Bicknell and Dr. Victoria Heath PhD thesis University of Birmingham August 2012 University of Birmingham Research Archive e-theses repository This unpublished thesis/dissertation is copyright of the author and/or third parties. The intellectual property rights of the author or third parties in respect of this work are as defined by The Copyright Designs and Patents Act 1988 or as modified by any successor legislation. Any use made of information contained in this thesis/dissertation must be in accordance with that legislation and must be properly acknowledged. Further distribution or reproduction in any format is prohibited without the permission of the copyright holder. ABSTRACT Tumour angiogenesis is a vital process in the pathology of tumour development and metastasis. Targeting markers of tumour endothelium provide a means of targeted destruction of a tumours oxygen and nutrient supply via destruction of tumour vasculature, which in turn ultimately leads to beneficial consequences to patients. Although current anti -angiogenic and vascular targeting strategies help patients, more potently in combination with chemo therapy, there is still a need for more tumour endothelial marker discoveries as current treatments have cardiovascular and other side effects. For the first time, the analyses of in-vivo biotinylation of an embryonic system is performed to obtain putative vascular targets. Also for the first time, deep sequencing is applied to freshly isolated tumour and normal endothelial cells from lung, colon and bladder tissues for the identification of pan-vascular-targets. Integration of the proteomic, deep sequencing, public cDNA libraries and microarrays, delivers 5,892 putative vascular targets to the science community. -

High-Resolution SNP Arrays in Mental Retardation Diagnostics: How Much Do We Gain?
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Archivio della ricerca- Università di Roma La Sapienza European Journal of Human Genetics (2010) 18, 178–185 & 2010 Macmillan Publishers Limited All rights reserved 1018-4813/10 $32.00 www.nature.com/ejhg ARTICLE High-resolution SNP arrays in mental retardation diagnostics: how much do we gain? Laura Bernardini1, Viola Alesi1,2, Sara Loddo1,2, Antonio Novelli1, Irene Bottillo1, Agatino Battaglia3, Maria Cristina Digilio4, Giuseppe Zampino5, Adam Ertel2, Paolo Fortina*,2,6, Saul Surrey7 and Bruno Dallapiccola1 We used Affymetrix 6.0 GeneChip SNP arrays to characterize copy number variations (CNVs) in a cohort of 70 patients previously characterized on lower-density oligonucleotide arrays affected by idiopathic mental retardation and dysmorphic features. The SNP array platform includes B900 000 SNP probes and 900 000 non-SNP oligonucleotide probes at an average distance of 0.7 Kb, which facilitates coverage of the whole genome, including coding and noncoding regions. The high density of probes is critical for detecting small CNVs, but it can lead to data interpretation problems. To reduce the number of false positives, parameters were set to consider only imbalances 475 Kb encompassing at least 80 probe sets. The higher resolution of the SNP array platform confirmed the increased ability to detect small CNVs, although more than 80% of these CNVs overlapped to copy number ‘neutral’ polymorphism regions and 4.4% of them did not contain known genes. In our cohort of 70 patients, of the 51 previously evaluated as ‘normal’ on the Agilent 44K array, the SNP array platform disclosed six additional CNV changes, including three in three patients, which may be pathogenic. -

Circular RNA Hsa Circ 0005114‑Mir‑142‑3P/Mir‑590‑5P‑ Adenomatous
ONCOLOGY LETTERS 21: 58, 2021 Circular RNA hsa_circ_0005114‑miR‑142‑3p/miR‑590‑5p‑ adenomatous polyposis coli protein axis as a potential target for treatment of glioma BO WEI1*, LE WANG2* and JINGWEI ZHAO1 1Department of Neurosurgery, China‑Japan Union Hospital of Jilin University, Changchun, Jilin 130033; 2Department of Ophthalmology, The First Hospital of Jilin University, Jilin University, Changchun, Jilin 130021, P.R. China Received September 12, 2019; Accepted October 22, 2020 DOI: 10.3892/ol.2020.12320 Abstract. Glioma is the most common type of brain tumor APC expression with a good overall survival rate. UALCAN and is associated with a high mortality rate. Despite recent analysis using TCGA data of glioblastoma multiforme and the advances in treatment options, the overall prognosis in patients GSE25632 and GSE103229 microarray datasets showed that with glioma remains poor. Studies have suggested that circular hsa‑miR‑142‑3p/hsa‑miR‑590‑5p was upregulated and APC (circ)RNAs serve important roles in the development and was downregulated. Thus, hsa‑miR‑142‑3p/hsa‑miR‑590‑5p‑ progression of glioma and may have potential as therapeutic APC‑related circ/ceRNA axes may be important in glioma, targets. However, the expression profiles of circRNAs and their and hsa_circ_0005114 interacted with both of these miRNAs. functions in glioma have rarely been studied. The present study Functional analysis showed that hsa_circ_0005114 was aimed to screen differentially expressed circRNAs (DECs) involved in insulin secretion, while APC was associated with between glioma and normal brain tissues using sequencing the Wnt signaling pathway. In conclusion, hsa_circ_0005114‑ data collected from the Gene Expression Omnibus database miR‑142‑3p/miR‑590‑5p‑APC ceRNA axes may be potential (GSE86202 and GSE92322 datasets) and explain their mecha‑ targets for the treatment of glioma. -

1 Supporting Information for a Microrna Network Regulates
Supporting Information for A microRNA Network Regulates Expression and Biosynthesis of CFTR and CFTR-ΔF508 Shyam Ramachandrana,b, Philip H. Karpc, Peng Jiangc, Lynda S. Ostedgaardc, Amy E. Walza, John T. Fishere, Shaf Keshavjeeh, Kim A. Lennoxi, Ashley M. Jacobii, Scott D. Rosei, Mark A. Behlkei, Michael J. Welshb,c,d,g, Yi Xingb,c,f, Paul B. McCray Jr.a,b,c Author Affiliations: Department of Pediatricsa, Interdisciplinary Program in Geneticsb, Departments of Internal Medicinec, Molecular Physiology and Biophysicsd, Anatomy and Cell Biologye, Biomedical Engineeringf, Howard Hughes Medical Instituteg, Carver College of Medicine, University of Iowa, Iowa City, IA-52242 Division of Thoracic Surgeryh, Toronto General Hospital, University Health Network, University of Toronto, Toronto, Canada-M5G 2C4 Integrated DNA Technologiesi, Coralville, IA-52241 To whom correspondence should be addressed: Email: [email protected] (M.J.W.); yi- [email protected] (Y.X.); Email: [email protected] (P.B.M.) This PDF file includes: Materials and Methods References Fig. S1. miR-138 regulates SIN3A in a dose-dependent and site-specific manner. Fig. S2. miR-138 regulates endogenous SIN3A protein expression. Fig. S3. miR-138 regulates endogenous CFTR protein expression in Calu-3 cells. Fig. S4. miR-138 regulates endogenous CFTR protein expression in primary human airway epithelia. Fig. S5. miR-138 regulates CFTR expression in HeLa cells. Fig. S6. miR-138 regulates CFTR expression in HEK293T cells. Fig. S7. HeLa cells exhibit CFTR channel activity. Fig. S8. miR-138 improves CFTR processing. Fig. S9. miR-138 improves CFTR-ΔF508 processing. Fig. S10. SIN3A inhibition yields partial rescue of Cl- transport in CF epithelia. -

Distinct Genetic Alterations in Colorectal Cancer
Distinct Genetic Alterations in Colorectal Cancer Hassan Ashktorab1*, Alejandro A. Scha¨ffer2, Mohammad Daremipouran3, Duane T. Smoot3, Edward Lee3, Hassan Brim3 1 Department of Medicine and Cancer Center, Howard University, College of Medicine, Washington, DC, United States of America, 2 National Center for Biotechnology Information, National Institutes of Health (NIH), Department of Health and Human Services (DHHS), Bethesda, Maryland, United States of America, 3 Department of Pathology, Howard University, College of Medicine, Washington, DC, United States of America Abstract Background: Colon cancer (CRC) development often includes chromosomal instability (CIN) leading to amplifications and deletions of large DNA segments. Epidemiological, clinical, and cytogenetic studies showed that there are considerable differences between CRC tumors from African Americans (AAs) and Caucasian patients. In this study, we determined genomic copy number aberrations in sporadic CRC tumors from AAs, in order to investigate possible explanations for the observed disparities. Methodology/Principal Findings: We applied genome-wide array comparative genome hybridization (aCGH) using a 105k chip to identify copy number aberrations in samples from 15 AAs. In addition, we did a population comparative analysis with aCGH data in Caucasians as well as with a widely publicized list of colon cancer genes (CAN genes). There was an average of 20 aberrations per patient with more amplifications than deletions. Analysis of DNA copy number of frequently altered chromosomes revealed that deletions occurred primarily in chromosomes 4, 8 and 18. Chromosomal duplications occurred in more than 50% of cases on chromosomes 7, 8, 13, 20 and X. The CIN profile showed some differences when compared to Caucasian alterations. Conclusions/Significance: Chromosome X amplification in male patients and chromosomes 4, 8 and 18 deletions were prominent aberrations in AAs. -

Proteomic Analysis of HIV-1 Nef Cellular Binding Partners Reveals a Role for Exocyst Complex Proteins in Mediating Enhancement of Intercellular Nanotube Formation
Proteomic analysis of HIV-1 Nef cellular binding partners reveals a role for exocyst complex proteins in mediating enhancement of intercellular nanotube formation The Harvard community has made this article openly available. Please share how this access benefits you. Your story matters Citation Mukerji, Joya, Kevin C Olivieri, Vikas Misra, Kristin A Agopian, and Dana Gabuzda. 2012. Proteomic analysis of hiv-1 nef cellular binding partners reveals a role for exocyst complex proteins in mediating enhancement of intercellular nanotube formation. Retrovirology 9: 33. Published Version doi:10.1186/1742-4690-9-33 Citable link http://nrs.harvard.edu/urn-3:HUL.InstRepos:10445557 Terms of Use This article was downloaded from Harvard University’s DASH repository, and is made available under the terms and conditions applicable to Other Posted Material, as set forth at http:// nrs.harvard.edu/urn-3:HUL.InstRepos:dash.current.terms-of- use#LAA Mukerji et al. Retrovirology 2012, 9:33 http://www.retrovirology.com/content/9/1/33 RESEARCH Open Access Proteomic analysis of HIV-1 Nef cellular binding partners reveals a role for exocyst complex proteins in mediating enhancement of intercellular nanotube formation Joya Mukerji1,2, Kevin C Olivieri1, Vikas Misra1, Kristin A Agopian1,2 and Dana Gabuzda1,2,3* Abstract Background: HIV-1 Nef protein contributes to pathogenesis via multiple functions that include enhancement of viral replication and infectivity, alteration of intracellular trafficking, and modulation of cellular signaling pathways. Nef stimulates formation of tunneling nanotubes and virological synapses, and is transferred to bystander cells via these intercellular contacts and secreted microvesicles. Nef associates with and activates Pak2, a kinase that regulates T-cell signaling and actin cytoskeleton dynamics, but how Nef promotes nanotube formation is unknown. -
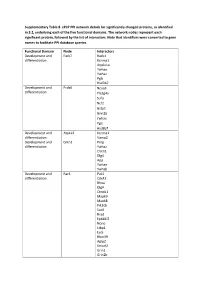
Supplementary Table 8. Cpcp PPI Network Details for Significantly Changed Proteins, As Identified in 3.2, Underlying Each of the Five Functional Domains
Supplementary Table 8. cPCP PPI network details for significantly changed proteins, as identified in 3.2, underlying each of the five functional domains. The network nodes represent each significant protein, followed by the list of interactors. Note that identifiers were converted to gene names to facilitate PPI database queries. Functional Domain Node Interactors Development and Park7 Rack1 differentiation Kcnma1 Atp6v1a Ywhae Ywhaz Pgls Hsd3b7 Development and Prdx6 Ncoa3 differentiation Pla2g4a Sufu Ncf2 Gstp1 Grin2b Ywhae Pgls Hsd3b7 Development and Atp1a2 Kcnma1 differentiation Vamp2 Development and Cntn1 Prnp differentiation Ywhaz Clstn1 Dlg4 App Ywhae Ywhab Development and Rac1 Pak1 differentiation Cdc42 Rhoa Dlg4 Ctnnb1 Mapk9 Mapk8 Pik3cb Sod1 Rrad Epb41l2 Nono Ltbp1 Evi5 Rbm39 Aplp2 Smurf2 Grin1 Grin2b Xiap Chn2 Cav1 Cybb Pgls Ywhae Development and Hbb-b1 Atp5b differentiation Hba Kcnma1 Got1 Aldoa Ywhaz Pgls Hsd3b4 Hsd3b7 Ywhae Development and Myh6 Mybpc3 differentiation Prkce Ywhae Development and Amph Capn2 differentiation Ap2a2 Dnm1 Dnm3 Dnm2 Atp6v1a Ywhab Development and Dnm3 Bin1 differentiation Amph Pacsin1 Grb2 Ywhae Bsn Development and Eef2 Ywhaz differentiation Rpgrip1l Atp6v1a Nphp1 Iqcb1 Ezh2 Ywhae Ywhab Pgls Hsd3b7 Hsd3b4 Development and Gnai1 Dlg4 differentiation Development and Gnao1 Dlg4 differentiation Vamp2 App Ywhae Ywhab Development and Psmd3 Rpgrip1l differentiation Psmd4 Hmga2 Development and Thy1 Syp differentiation Atp6v1a App Ywhae Ywhaz Ywhab Hsd3b7 Hsd3b4 Development and Tubb2a Ywhaz differentiation Nphp4 -

In This Table Protein Name, Uniprot Code, Gene Name P-Value
Supplementary Table S1: In this table protein name, uniprot code, gene name p-value and Fold change (FC) for each comparison are shown, for 299 of the 301 significantly regulated proteins found in both comparisons (p-value<0.01, fold change (FC) >+/-0.37) ALS versus control and FTLD-U versus control. Two uncharacterized proteins have been excluded from this list Protein name Uniprot Gene name p value FC FTLD-U p value FC ALS FTLD-U ALS Cytochrome b-c1 complex P14927 UQCRB 1.534E-03 -1.591E+00 6.005E-04 -1.639E+00 subunit 7 NADH dehydrogenase O95182 NDUFA7 4.127E-04 -9.471E-01 3.467E-05 -1.643E+00 [ubiquinone] 1 alpha subcomplex subunit 7 NADH dehydrogenase O43678 NDUFA2 3.230E-04 -9.145E-01 2.113E-04 -1.450E+00 [ubiquinone] 1 alpha subcomplex subunit 2 NADH dehydrogenase O43920 NDUFS5 1.769E-04 -8.829E-01 3.235E-05 -1.007E+00 [ubiquinone] iron-sulfur protein 5 ARF GTPase-activating A0A0C4DGN6 GIT1 1.306E-03 -8.810E-01 1.115E-03 -7.228E-01 protein GIT1 Methylglutaconyl-CoA Q13825 AUH 6.097E-04 -7.666E-01 5.619E-06 -1.178E+00 hydratase, mitochondrial ADP/ATP translocase 1 P12235 SLC25A4 6.068E-03 -6.095E-01 3.595E-04 -1.011E+00 MIC J3QTA6 CHCHD6 1.090E-04 -5.913E-01 2.124E-03 -5.948E-01 MIC J3QTA6 CHCHD6 1.090E-04 -5.913E-01 2.124E-03 -5.948E-01 Protein kinase C and casein Q9BY11 PACSIN1 3.837E-03 -5.863E-01 3.680E-06 -1.824E+00 kinase substrate in neurons protein 1 Tubulin polymerization- O94811 TPPP 6.466E-03 -5.755E-01 6.943E-06 -1.169E+00 promoting protein MIC C9JRZ6 CHCHD3 2.912E-02 -6.187E-01 2.195E-03 -9.781E-01 Mitochondrial 2- -

Centre for Arab Genomic Studies a Division of Sheikh Hamdan Award for Medical Sciences
Centre for Arab Genomic Studies A Division of Sheikh Hamdan Award for Medical Sciences The atalogue for ransmission enetics in rabs C T G A CTGA Database Exocyst Complex Component 4 Alternative Names defects. Individuals were diagnosed with MKS EXOC4 based on the presence of occipital encephalocele as SEC8, S. Cerevisiae, Homolog of well as any combination of liver fibrosis, cleft SEC8 palate, dysplastic kidneys, polydactyly and early KIAA1699 lethality. DNA from both affected and healthy members was obtained and an autozygome guided Record Category mutation analysis of known MKS genes was carried Gene locus out. However, some families did not have mutations in any of the known MKS genes. In such WHO-ICD cases, an exome sequencing was performed. N/A to gene loci Exomes were then searched for compound heterozygous mutations in known MKS genes. Incidence per 100,000 Live Births Failing that, all detected variants were filtered for N/A to gene loci homozygous novel changes within the autozygome. This resulted in the detection of a novel OMIM Number homozygous mutation c.1733A>G (p.Gln578Arg) 608185 in the EXOC4 gene in one of the affected families. This mutation was not found in dbSNP, 1000 Mode of Inheritance genomes or 200 Saudi controls. In-silico analysis N/A to gene loci by PolyPhen predicted this variant to be ‘probably damaging’ while SIFT predicted it to be Gene Map Locus deleterious. The authors noted that EXOC4 had not 7q33 previously been linked to MKS syndrome and that more studies were needed to confirm this Description association. The EXOC4 gene encodes a protein that forms the exocyst complex along with seven other EXOC References proteins. -

Exocyst Components Promote an Incompatible Interaction Between Glycine Max (Soybean) and Heterodera Glycines (The Soybean Cyst Nematode) Keshav Sharma1,7, Prakash M
www.nature.com/scientificreports OPEN Exocyst components promote an incompatible interaction between Glycine max (soybean) and Heterodera glycines (the soybean cyst nematode) Keshav Sharma1,7, Prakash M. Niraula1,8, Hallie A. Troell1, Mandeep Adhikari1, Hamdan Ali Alshehri2, Nadim W. Alkharouf3, Kathy S. Lawrence4 & Vincent P. Klink1,5,6* Vesicle and target membrane fusion involves tethering, docking and fusion. The GTPase SECRETORY4 (SEC4) positions the exocyst complex during vesicle membrane tethering, facilitating docking and fusion. Glycine max (soybean) Sec4 functions in the root during its defense against the parasitic nematode Heterodera glycines as it attempts to develop a multinucleate nurse cell (syncytium) serving to nourish the nematode over its 30-day life cycle. Results indicate that other tethering proteins are also important for defense. The G. max exocyst is encoded by 61 genes: 5 EXOC1 (Sec3), 2 EXOC2 (Sec5), 5 EXOC3 (Sec6), 2 EXOC4 (Sec8), 2 EXOC5 (Sec10) 6 EXOC6 (Sec15), 31 EXOC7 (Exo70) and 8 EXOC8 (Exo84) genes. At least one member of each gene family is expressed within the syncytium during the defense response. Syncytium-expressed exocyst genes function in defense while some are under transcriptional regulation by mitogen-activated protein kinases (MAPKs). The exocyst component EXOC7-H4-1 is not expressed within the syncytium but functions in defense and is under MAPK regulation. The tethering stage of vesicle transport has been demonstrated to play an important role in defense in the G. max-H. glycines pathosystem, with some of the spatially and temporally regulated exocyst components under transcriptional control by MAPKs. Abbreviations DCM Detection call methodology wr Whole root system pg Per gram SAR Systemic acquired resistance During their defense against pathogen infection, plants employ cellular processes to detect and amplify signals derived from the activities of those pathogens. -

Mirna Regulons Associated with Synaptic Function
miRNA Regulons Associated with Synaptic Function Maria Paschou1, Maria D. Paraskevopoulou2, Ioannis S. Vlachos2, Pelagia Koukouraki1, Artemis G. Hatzigeorgiou2,3, Epaminondas Doxakis1* 1 Basic Neurosciences Division, Biomedical Research Foundation of the Academy of Athens, Athens, Greece, 2 Institute of Molecular Oncology, Biomedical Sciences Research Center ‘‘Alexander Fleming’’ Vari, Greece, 3 Department of Computer and Communication Engineering, University of Thessaly, Volos, Greece Abstract Differential RNA localization and local protein synthesis regulate synapse function and plasticity in neurons. MicroRNAs are a conserved class of regulatory RNAs that control mRNA stability and translation in tissues. They are abundant in the brain but the extent into which they are involved in synaptic mRNA regulation is poorly known. Herein, a computational analysis of the coding and 39UTR regions of 242 presynaptic and 304 postsynaptic proteins revealed that 91% of them are predicted to be microRNA targets. Analysis of the longest 39UTR isoform of synaptic transcripts showed that presynaptic mRNAs have significantly longer 39UTR than control and postsynaptic mRNAs. In contrast, the shortest 39UTR isoform of postsynaptic mRNAs is significantly shorter than control and presynaptic mRNAs, indicating they avert microRNA regulation under specific conditions. Examination of microRNA binding site density of synaptic 39UTRs revealed that they are twice as dense as the rest of protein-coding transcripts and that approximately 50% of synaptic transcripts are predicted to have more than five different microRNA sites. An interaction map exploring the association of microRNAs and their targets revealed that a small set of ten microRNAs is predicted to regulate 77% and 80% of presynaptic and postsynaptic transcripts, respectively.