Bridging Chasms in Hindustani Music Retrieval
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
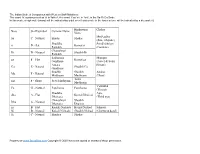
Note Staff Symbol Carnatic Name Hindustani Name Chakra Sa C
The Indian Scale & Comparison with Western Staff Notations: The vowel 'a' is pronounced as 'a' in 'father', the vowel 'i' as 'ee' in 'feet', in the Sa-Ri-Ga Scale In this scale, a high note (swara) will be indicated by a dot over it and a note in the lower octave will be indicated by a dot under it. Hindustani Chakra Note Staff Symbol Carnatic Name Name MulAadhar Sa C - Natural Shadaj Shadaj (Base of spine) Shuddha Swadhishthan ri D - flat Komal ri Rishabh (Genitals) Chatushruti Ri D - Natural Shudhh Ri Rishabh Sadharana Manipur ga E - Flat Komal ga Gandhara (Navel & Solar Antara Plexus) Ga E - Natural Shudhh Ga Gandhara Shudhh Shudhh Anahat Ma F - Natural Madhyam Madhyam (Heart) Tivra ma F - Sharp Prati Madhyam Madhyam Vishudhh Pa G - Natural Panchama Panchama (Throat) Shuddha Ajna dha A - Flat Komal Dhaivat Dhaivata (Third eye) Chatushruti Shudhh Dha A - Natural Dhaivata Dhaivat ni B - Flat Kaisiki Nishada Komal Nishad Sahsaar Ni B - Natural Kakali Nishada Shudhh Nishad (Crown of head) Så C - Natural Shadaja Shadaj Property of www.SarodSitar.com Copyright © 2010 Not to be copied or shared without permission. Short description of Few Popular Raags :: Sanskrut (Sanskrit) pronunciation is Raag and NOT Raga (Alphabetical) Aroha Timing Name of Raag (Karnataki Details Avroha Resemblance) Mood Vadi, Samvadi (Main Swaras) It is a old raag obtained by the combination of two raags, Ahiri Sa ri Ga Ma Pa Ga Ma Dha ni Så Ahir Bhairav Morning & Bhairav. It belongs to the Bhairav Thaat. Its first part (poorvang) has the Bhairav ang and the second part has kafi or Så ni Dha Pa Ma Ga ri Sa (Chakravaka) serious, devotional harpriya ang. -

Music & Dance Session 2020-21
1 FACULTY OF PERFORMING & VISUAL ARTS SYLLABUS Of MUSIC VOCAL For B.A. (Semester- I to VI ) (UnderContinuous Evaluation System) (12+3 System of Education) Session: 2020-21 The Heritage Institution KANYA MAHA VIDYALAYA JALANDHAR (Autonomous) B.A. (Semester- I) 1 2 Scheme of Studies and Examination Music Vocal SemesterI Course Marks Examinati Course Name Program Name Course Code Type Ext. on time Total CA L P (in Hours) Music Vocal B.A BARM-1366 E 100 40 40 20 3 B.A. Semester-I (Session 2020-21) Music Vocal Course Code: BARM-1366 Theory & Practical Course Outcome Upon successful completion of this course student will be able to know the basic concepts of music , which are - CO1 . Proficiency in playing Alankar , which are helpful in further learning of ragas. CO2. To know the lives of great musician who are torch bearers of Indian classical music. CO3. To Know about Tanpura, its structure , its sound Producing system and tuning of the instrument. B.A. Semester-I (Session 2020-21) Music Vocal Course Code: BARM-1366 2 3 Theory Total Marks-100 Time-3Hours Theory: 40 Pr: 40 CA: 20 Instructions given to the examiners are as follows: The paper setter will set Eight questions of equal marks . Two in each of the four Sections (A- D). Questions of Sections A-D should be set from Units I-IV of the syllabus respectively. Questions may be subdivided into parts (not exceeding four). Candidates are required to attempt five questions, selecting at least one question from each section. The fifth question may be attempted from any Section. -

Navarathri Mandapam CHAPTER 4 Musical Aspect of Maharaja’S Compositions
Navarathri Mandapam CHAPTER 4 Musical Aspect of Maharaja’s Compositions 4.1. Introduction “Music begins where the possibilities of language end.” - Jean Sibelius Music is just not confined only to notes and its rendition, it is a unit of melody, its combinations and beautiful body movements. Therefore it is called Samageetam (g“rV_²) and Sharangdeva has given an apt definition to the term - JrV§ dmÚ§ VWm Z¥Ë`§, Ì`§ g“rV_wÀ`Vo& Maharaja’s compositions are models of all the three faculties of music. They are sung, played on various instruments and some compositions are exclusively composed for dance performances. To understand the nuance and technical aspects of music, it is very necessary to look back at the history of both the streams of Indian Music which are prevalent. As discussed in the earlier chapters, North Indian Music, popularly known as the Hindusthani Music had a lot of transitions since the Vedic era to the Mughal or the pre- indehendence era. After the decline of the Mughal Empire, the patronage of music continued in smaller princely kingdoms like Gwalior, Jaipur, Patiala giving rise to diversity of styles that is today known as Gharanas. Meanwhile the Bhakti and Sufi traditions -------------------------------- ( 100 ) ---------------------------------- continued to develop and interact with the different schools of music. Gharana system had a peculiar tradition of one-to-one teaching which was imparted through the Guru-Shishya tradition. To a large extent, it was limited to the palace and dance halls. It was shunned by the intellectuals, avoided by the educated middle class, and in general looked down upon as a frivolous practise. -

Fusion Without Confusion Raga Basics Indian
Fusion Without Confusion Raga Basics Indian Rhythm Basics Solkattu, also known as konnakol is the art of performing percussion syllables vocally. It comes from the Carnatic music tradition of South India and is mostly used in conjunction with instrumental music and dance instruction, although it has been widely adopted throughout the world as a modern composition and performance tool. Similarly, the music of North India has its own system of rhythm vocalization that is based on Bols, which are the vocalization of specific sounds that correspond to specific sounds that are made on the drums of North India, most notably the Tabla drums. Like in the south, the bols are used in musical training, as well as composition and performance. In addition, solkattu sounds are often referred to as bols, and the practice of reciting bols in the north is sometimes referred to as solkattu, so the distinction between the two practices is blurred a bit. The exercises and compositions we will discuss contain bols that are found in both North and South India, however they come from the tradition of the North Indian tabla drums. Furthermore, the theoretical aspect of the compositions is distinctly from the Hindustani, (north Indian) tradition. Hence, for the purpose of this presentation, the use of the term Solkattu refers to the broader, more general practice of Indian rhythmic language. South Indian Percussion Mridangam Dolak Kanjira Gattam North Indian Percussion Tabla Baya (a.k.a. Tabla) Pakhawaj Indian Rhythm Terms Tal (also tala, taal, or taala) – The Indian system of rhythm. Tal literally means "clap". -

M.A-Music-Vocal-Syllabus.Pdf
BANGALORE UNIVERSITY NAAC ACCREDITED WITH ‘A’ GRADE P.G. DEPARTMENT OF PERFORMING ARTS JNANABHARATHI, BANGALORE-560056 MUSIC SYLLABUS – M.A KARNATAKA MUSIC VOCAL AND INSTRUMENTAL (VEENA, VIOLIN AND FLUTE) CBCS SYSTEM- 2014 Dr. B.M. Jayashree. Professor of Music Chairperson, BOS (PG) M.A. KARNATAKA MUSIC VOCAL AND INSTRUMENTAL (VEENA, VIOLIN AND FLUTE) Semester scheme syllabus CBCS Scheme of Examination, continuous Evaluation and other Requirements: 1. ELIGIBILITY: A Degree with music vocal/instrumental as one of the optional subject with at least 50% in the concerned optional subject an merit internal among these applicant Of A Graduate with minimum of 50% marks secured in the senior grade examination in music (vocal/instrumental) conducted by secondary education board of Karnataka OR a graduate with a minimum of 50% marks secured in PG Diploma or 2 years diploma or 4 year certificate course in vocal/instrumental music conducted either by any recognized Universities of any state out side Karnataka or central institution/Universities Any degree with: a) Any certificate course in music b) All India Radio/Doordarshan gradation c) Any diploma in music or five years of learning certificate by any veteran musician d) Entrance test (practical) is compulsory for admission. 2. M.A. MUSIC course consists of four semesters. 3. First semester will have three theory paper (core), three practical papers (core) and one practical paper (soft core). 4. Second semester will have three theory papers (core), two practical papers (core), one is project work/Dissertation practical paper and one is practical paper (soft core) 5. Third semester will have two theory papers (core), three practical papers (core) and one is open Elective Practical paper 6. -

Zamindari System in Telugu Pdf
Zamindari system in telugu pdf Continue Indian hereditary aristocrat For other uses, see zamindar (disambigation). Sir Nawab Hwaja Salimullah was a zamindar with the title of Nawab. His family's land in Bengal was one of the largest and richest in British India. In the Indian subcontinent, the Indian subcontinent was an autonomous or semi-autonomous ruler of the state who accepted the suzerainism of the Emperor of Hindustan. The term means the owner of the land in Persian. As a rule, hereditary, zamindars held huge tracts of land and control over their peasants, from which they reserved the right to collect taxes on behalf of imperial courts or for military purposes. In the 19th and 20th centuries, with the advent of British imperialism, many rich and influential zamindars were awarded princely and royal titles such as Maharaja (Great King), Raja/Paradise (King) and Navab. In the days of the Mughal Empire, the zamindars belonged to the nobility and formed the ruling class. Under British colonial rule in India, the permanent settlement consolidated such a well-known system of zamindari. The British awarded the supporting zamindars, recognizing them as princes. Many of the princely state of the region were pre-colonial zamindars, erected in more protocol. However, the British also reduced the land holdings of many pre-colonial princely states and chiefs, lowered their status to the zamindar from the formerly higher ranks of the nobility. The system was abolished during land reforms in East Pakistan (Bangladesh) in 1950, India in 1951 and West Pakistan in 1959. The zamindars often played an important role in the regional history of the subcontinent. -

University of Mauritius Mahatma Gandhi Institute
University of Mauritius Mahatma Gandhi Institute Regulations And Programme of Studies B. A (Hons) Performing Arts (Vocal Hindustani) (Review) - 1 - UNIVERSITY OF MAURITIUS MAHATMA GANDHI INSTITUTE PART I General Regulations for B.A (Hons) Performing Arts (Vocal Hindustani) 1. Programme title: B.A (Hons) Performing Arts (Vocal Hindustani) 2. Objectives To equip the student with further knowledge and skills in Vocal Hindustani Music and proficiency in the teaching of the subject. 3. General Entry Requirements In accordance with the University General Entry Requirements for admission to undergraduate degree programmes. 4. Programme Requirement A post A-Level MGI Diploma in Performing Arts (Vocal Hindustani) or an alternative qualification acceptable to the University of Mauritius. 5. Programme Duration Normal Maximum Degree (P/T): 2 years 4 years (4 semesters) (8 semesters) 6. Credit System 6.1 Introduction 6.1.1 The B.A (Hons) Performing Arts (Vocal Hindustani) programme is built up on a 3- year part time Diploma, which accounts for 60 credits. 6.1.2 The Programme is structured on the credit system and is run on a semester basis. 6.1.3 A semester is of a duration of 15 weeks (excluding examination period). - 2 - 6.1.4 A credit is a unit of measure, and the Programme is based on the following guidelines: 15 hours of lectures and / or tutorials: 1 credit 6.2 Programme Structure The B.A Programme is made up of a number of modules carrying 3 credits each, except the Dissertation which carries 9 credits. 6.3 Minimum Credits Required for the Award of the Degree: 6.3.1 The MGI Diploma already accounts for 60 credits. -

The Spread of Sanskrit* (Published In: from Turfan to Ajanta
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Serveur académique lausannois Spread of Sanskrit 1 Johannes Bronkhorst Section de langues et civilisations orientales Université de Lausanne Anthropole CH-1009 Lausanne The spread of Sanskrit* (published in: From Turfan to Ajanta. Festschrift for Dieter Schlingloff on the Occasion of his Eightieth Birthday. Ed. Eli Franco and Monika Zin. Lumbini International Research Institute. 2010. Vol. 1. Pp. 117-139.) A recent publication — Nicholas Ostler’s Empires of the Word (2005) — presents itself in its subtitle as A Language History of the World. Understandably, it deals extensively with what it calls “world languages”, languages which play or have played important roles in world history. An introductory chapter addresses, already in its title, the question “what it takes to be a world language”. The title also provides a provisional answer, viz. “you never can tell”, but the discussion goes beyond mere despair. It opposes the “pernicious belief” which finds expression in a quote from J. R. Firth, a leading British linguist of the mid-twentieth century (p. 20): “World powers make world languages [...] Men who have strong feelings directed towards the world and its affairs have done most. What the humble prophets of linguistic unity would have done without Hebrew, Arabic, Latin, Sanskrit and English, it it difficult to imagine. Statesmen, soldiers, sailors, and missionaries, men of action, men of strong feelings have made world languages. They are built on blood, money, sinews, and suffering in the pursuit of power.” Ostler is of the opinion that this belief does not stand up to criticism: “As soon as the careers of languages are seriously studied — even the ‘Hebrew, Arabic, Latin, Sanskrit and English’ that Firth explicitly mentions as examples — it becomes clear that this self-indulgently tough-minded view is no guide at all to what really makes a language capable of spreading.” He continues on the following page (p. -

Functional Translation
Certificate in Translation (CIT) CIT-02 Functional Translation Block 2 Functional Translation in Practice Unit-08: Using Dictionary and Thesaurus in Translation Unit-09: Translation of Registers and Technical Terms EXPERT COMMITTEE Chairman Members Prof. Jatin Nayak Dr. Abhilash Nayak Shri Bimal Prasad Professor in English Regional Director Research and Support Services Utkal University IGNOU Regional Centre Eastern Media Bhubaneswar, Odisha Bhubaneswar Bhubaneswar, Odisha Convener Dr. Sambhu Dayal Agrawal Shri Das Benhur Dr. Sangram Jena Consultant (Academic) in CIT Retired Principal Dy. Director Odisha State Open University SCS College, Puri Department of Revenue Sambalpur, Odisha Government of Odisha CERTIFICATE IN TRANSLATION Course Writer Dr. Sambhu Dayal Agrawal Welcome Note Dear Student, Hope you are comfortable learning translation from English to Odia. We are trying to guide you through such information and practice that will enable you provide good translation . I am very happy to offer you this new boo k that contains two very interesting units . Have you seen small children playing word game using dictionaries? This increases their vocabulary while enjoying using it. However, Unit-08 will educate you about the various features of Dictionaries and Thesauri. If you try to go deep into using these two most reliable resources, your job of translation will become easy. Unit-09 deals with a very interesting aspect of any language that we are well -versed already, but we never take cognizance of its technicality or inner beauty. We speak differently with d ifferent people at different places and occasions. These various types of our speech are technically known as ‘Register’ in linguistics. -

Vocal Grade 4
VOCAL GRADE 4 Introduction Welcome to Grade 4 You are about to start the wonderful journey of learning to sing, a journey that is challenging, but rewarding and enjoyable! Whether you want to jam with a band or enjoy singing solo, this series of lessons will get you ready to perform with skill & confidence. What will you learn? Grade 4 covers the following topics : 1) Guruvandana and Saraswati vandana 2) Gharanas in Indian Classical Music 3) Pandit Vishnu Narayan Bhatkhande 4) Tanpura 5) Lakshan Geet 6) Music & Psychology 7) Raag Bhairav 8) Chartaal 9) Raag Bihag 10) Raag and Time Theory 11) Raag Kafi 12) Taal Ektaal 13) Bada Khyal 14) Guessing a Raag 15) Alankar 1 What You Need Harmonium /Synthesizer Electronic Tabla / TablaApp You can learn to sing without any of the above instruments also and by tapping your feet, however you will get a lot more out of this series if you have a basic harmonium and a digital Tabla to practice. How to Practice At Home Apart from this booklet for level 1, there will be video clippings shown to you for each topic in all the lessons. During practice at home, please follow the method shown in the clippings. Practice each lesson several times before meeting for the next lesson. A daily practice regime of a minimum of 15 minutes will suffice to start with. Practicing with the harmonium and the digital Tabla will certainly have an added advantage. DigitalTablamachinesorTablasoftware’sareeasilyavailableandideallyshould beusedfor daily practice. 2 Lesson 1 GURUVANDANA SARASWATI VANDANA & Guruvandana Importance of Guruvandana : The concept of Guru is as old as humanity itself. -

On Identifying a Common Goal Between Musicians and Scientists
ON IDENTIFYING A COMMON GOAL BETWEEN MUSICIANS AND SCIENTISTS Soubhik Chakraborty Department of Applied Mathematics Birla Institute of Technology Mesra, Ranchi-835215, India Email: [email protected] Abstract The aim of this article is to identify a common goal between musicians and scientists. Our analysis ends on a positive note suggesting that the “gap” between the two, so to say, exists only in the nature of the paths undertaken. There is hardly any gap so far as the goal is concerned. This realization, which I believe will be helpful in bringing scientists and musicians together thereby raising the standard of music appreciation, music therapy and music-learning, bears a sure relevance in the context of those developing countries such as India to which this author belongs where music therapy is not yet an established profession, nor is scientific research in music as popular as in the west. Key words Music appreciation; music therapy; music learning 1. Introduction Discovering similarities between the pursuits of scientific research and musical arts is a compelling and perennially interesting topic that has been discussed for around a century. This article gives my subjective personal opinion on the topic and bears a sure relevance in the Indian context where music therapy is not yet an established profession, nor is scientific research in music as popular as in the west. For further literature, however, the reader is referred to Parncutt and McPherson (2002), Hallam, Cross and Thaut (2009). See also Levinson (2003). 1.1 Discovering science in art Morgan and King (1986) have distinguished art from science as follows:- Science is a body of systematized knowledge. -

Unni Menon…. Is Basically a Malayalam Film Playback Singer
“FIRST ICSI-SIRC CSBF MUSICAL NITE” 11.11.2012 Sunday 6.05 p.m Kamarajar Arangam A/C Chennai In Association With Celebrity Singers . UNNI MENON . SRINIVAS . ANOORADA SRIRAM . MALATHY LAKSHMAN . MICHAEL AUGUSTINE Orchestra by THE VISION AND MISSION OF ICSI Vision : "To be a global leader in promoting Good Corporate Governance” Mission : "To develop high calibre professionals facilitating good Corporate Governance" The Institute The Institute of Company Secretaries of India(ICSI) is constituted under an Act of Parliament i.e. the Company Secretaries Act, 1980 (Act No. 56 of 1980). ICSI is the only recognized professional body in India to develop and regulate the profession of Company Secretaries in India. The Institute of Company Secretaries of India(ICSI) has on its rolls 25,132 members including 4,434 members holding certificate of the practice. The number of current students is over 2,30,000. The Institute of company Secretaries of India (ICSI) has its headquarters at New Delhi and four regional offices at New Delhi, Chennai, Kolkata and Mumbai and 68 Chapters in India. The ICSI has emerged as a premier professional body developing professionals specializing in Corporate Governance. Members of the Institute are rendering valuable services to the Government, Regulatory `bodies, Trade, Commerce, Industry and society at large. Objective of the Fund Financial Assistance in the event of Death of a member of CBSF Upto the age of 60 years • Upto Rs.3,00,000 in deserving cases on receipt of request subject to the Guidelines approved by the Managing