Intonation Analysis of Rāgas in Carnatic Music1
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Fusion Without Confusion Raga Basics Indian
Fusion Without Confusion Raga Basics Indian Rhythm Basics Solkattu, also known as konnakol is the art of performing percussion syllables vocally. It comes from the Carnatic music tradition of South India and is mostly used in conjunction with instrumental music and dance instruction, although it has been widely adopted throughout the world as a modern composition and performance tool. Similarly, the music of North India has its own system of rhythm vocalization that is based on Bols, which are the vocalization of specific sounds that correspond to specific sounds that are made on the drums of North India, most notably the Tabla drums. Like in the south, the bols are used in musical training, as well as composition and performance. In addition, solkattu sounds are often referred to as bols, and the practice of reciting bols in the north is sometimes referred to as solkattu, so the distinction between the two practices is blurred a bit. The exercises and compositions we will discuss contain bols that are found in both North and South India, however they come from the tradition of the North Indian tabla drums. Furthermore, the theoretical aspect of the compositions is distinctly from the Hindustani, (north Indian) tradition. Hence, for the purpose of this presentation, the use of the term Solkattu refers to the broader, more general practice of Indian rhythmic language. South Indian Percussion Mridangam Dolak Kanjira Gattam North Indian Percussion Tabla Baya (a.k.a. Tabla) Pakhawaj Indian Rhythm Terms Tal (also tala, taal, or taala) – The Indian system of rhythm. Tal literally means "clap". -
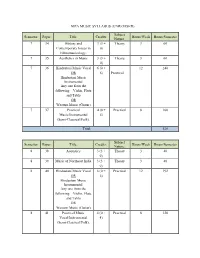
Mpa Music Syllabus (Unrevised)
MPA MUSIC SYLLABUS (UNREVISED) Subject Semester: Paper: Title: Credits: Hours/Week Hours/Semester Nature: 7 34 History and 3 (3 + Theory 3 60 Contemporary Issues in 0) Ethnomusicology. 7 35 Aesthetics in Music 3 (3 + Theory 3 60 0) 7 36 Hindustani Music Vocal 6 (0 + 12 240 OR 6) Practical Hindustani Music Instrumental Any one from the following – Violin, Flute and Tabla OR Western Music (Guitar) 7 37 Practical 4 (0 + Practical 8 160 Music/Instrumental 4) (Semi-Classical/Folk). Total: 520 Subject Semester: Paper: Title: Credits: Hours/Week Hours/Semester Nature: 8 38 Acoustics 3 (3 + Theory 3 48 0) 8 39 Music of Northeast India 3 (3 + Theory 3 48 0) 8 40 Hindustani Music Vocal 6 (0 + Practical 12 192 OR 6) Hindustani Music Instrumental Any one from the following – Violin, Flute and Tabla OR Western Music (Guitar) 8 41 Practical Music 4 (0 + Practical 8 128 Vocal/Instrumental 4) (Semi-Classical/Folk). Total 416 Subject Semester: Paper: Title: Credits: Hours/Week Hours/Semester Nature: 9 42 Music and Media 3 (3 + 0) Theory 3 60 9 43 Music in Dance and 3 (3 + 0) Theory 3 60 Theatre 9 44 Hindustani Music Vocal 6 (0 + 6) Practical 12 240 OR Hindustani Music Instrumental Any one from the following – Violin, Flute and Tabla OR Western Music (Guitar) 9 45 Practical Music 4 (0 + 4) Practical 8 160 Vocal/Instrumental (Semi-Classical/Folk) Total: 520 Subject Semester: Paper: Title: Credits: Hours/Week Hours/Semester Nature: 10 46 Music of Sikkim 3 (3 + 0) Theory 3 48 10 47 Fieldwork, Lab. -

Track Name Singers VOCALS 1 RAMKALI Pt. Bhimsen Joshi 2 ASAWARI TODI Pt
Track name Singers VOCALS 1 RAMKALI Pt. Bhimsen Joshi 2 ASAWARI TODI Pt. Bhimsen Joshi 3 HINDOLIKA Pt. Bhimsen Joshi 4 Thumri-Bhairavi Pt. Bhimsen Joshi 5 SHANKARA MANIK VERMA 6 NAT MALHAR MANIK VERMA 7 POORIYA MANIK VERMA 8 PILOO MANIK VERMA 9 BIHAGADA PANDIT JASRAJ 10 MULTANI PANDIT JASRAJ 11 NAYAKI KANADA PANDIT JASRAJ 12 DIN KI PURIYA PANDIT JASRAJ 13 BHOOPALI MALINI RAJURKAR 14 SHANKARA MALINI RAJURKAR 15 SOHONI MALINI RAJURKAR 16 CHHAYANAT MALINI RAJURKAR 17 HAMEER MALINI RAJURKAR 18 ADANA MALINI RAJURKAR 19 YAMAN MALINI RAJURKAR 20 DURGA MALINI RAJURKAR 21 KHAMAJ MALINI RAJURKAR 22 TILAK-KAMOD MALINI RAJURKAR 23 BHAIRAVI MALINI RAJURKAR 24 ANAND BHAIRAV PANDIT JITENDRA ABHISHEKI 25 RAAG MALA PANDIT JITENDRA ABHISHEKI 26 KABIR BHAJAN PANDIT JITENDRA ABHISHEKI 27 SHIVMAT BHAIRAV PANDIT JITENDRA ABHISHEKI 28 LALIT BEGUM PARVEEN SULTANA 29 JOG BEGUM PARVEEN SULTANA 30 GUJRI JODI BEGUM PARVEEN SULTANA 31 KOMAL BHAIRAV BEGUM PARVEEN SULTANA 32 MARUBIHAG PANDIT VASANTRAO DESHPANDE 33 THUMRI MISHRA KHAMAJ PANDIT VASANTRAO DESHPANDE 34 JEEVANPURI PANDIT KUMAR GANDHARVA 35 BAHAR PANDIT KUMAR GANDHARVA 36 DHANBASANTI PANDIT KUMAR GANDHARVA 37 DESHKAR PANDIT KUMAR GANDHARVA 38 GUNAKALI PANDIT KUMAR GANDHARVA 39 BILASKHANI-TODI PANDIT KUMAR GANDHARVA 40 KAMOD PANDIT KUMAR GANDHARVA 41 MIYA KI TODI USTAD RASHID KHAN 42 BHATIYAR USTAD RASHID KHAN 43 MIYA KI TODI USTAD RASHID KHAN 44 BHATIYAR USTAD RASHID KHAN 45 BIHAG ASHWINI BHIDE-DESHPANDE 46 BHINNA SHADAJ ASHWINI BHIDE-DESHPANDE 47 JHINJHOTI ASHWINI BHIDE-DESHPANDE 48 NAYAKI KANADA ASHWINI -

The Journal Ie Music Academy
THE JOURNAL OF IE MUSIC ACADEMY MADRAS A QUARTERLY OTED TO THE ADVANCEMENT OF THE SCIENCE AND ART OF MUSIC XIII 1962 Parts I-£V _ j 5tt i TOTftr 1 ®r?r <nr firerftr ii dwell not in Vaikuntha, nor in the hearts of Yogins, - the Sun; where my Bhaktas sing, there be I, ! ” EDITED BY V. RAGHAVAN, M.A., PH.D. 1 9 6 2 PUBLISHED BY HE MUSIC ACADEMY, MADRAS 115-E, M OW BRAY’S RO AD, M ADRAS-14. "iption—Inland Rs, 4. Foreign 8 sh. Post paid. i ADVERTISEMENT CHARGES I S COVER PAGES: if Back (outside) $ if Front (inside) i Back (D o.) if 0 if INSIDE PAGES: if 1st page (after cover) if if Ot^er pages (each) 1 £M E N i if k reference will be given to advertisers of if instruments and books and other artistic wares. if I Special position and special rate on application. Xif Xtx XK XK X&< i - XK... >&< >*< >*<. tG O^ & O +O +f >*< >•< >*« X NOTICE All correspondence should be addressed to Dr. V. R Editor, Journal of the Music Academy, Madras-14. Articles on subjects of music and dance are accep publication on the understanding that they are contribute) to the Journal of tlie Music Academy. All manuscripts should be legibly written or preferab written (double spaced—on one side of the paper only) and be signed by the writer (giving his address in full). The Editor of the Journal is not responsible for t1 expressed by individual contributors. All books, advertisement, moneys and cheque ♦ended for the Journal should be sent to D CONTENTS 'le X X X V th Madras Music Conference, 1961 : Official Report Alapa and Rasa-Bhava id wan C. -

Raga (Melodic Mode) Raga This Article Is About Melodic Modes in Indian Music
FREE SAMPLES FREE VST RESOURCES EFFECTS BLOG VIRTUAL INSTRUMENTS Raga (Melodic Mode) Raga This article is about melodic modes in Indian music. For subgenre of reggae music, see Ragga. For similar terms, see Ragini (actress), Raga (disambiguation), and Ragam (disambiguation). A Raga performance at Collège des Bernardins, France Indian classical music Carnatic music · Hindustani music · Concepts Shruti · Svara · Alankara · Raga · Rasa · Tala · A Raga (IAST: rāga), Raag or Ragam, literally means "coloring, tingeing, dyeing".[1][2] The term also refers to a concept close to melodic mode in Indian classical music.[3] Raga is a remarkable and central feature of classical Indian music tradition, but has no direct translation to concepts in the classical European music tradition.[4][5] Each raga is an array of melodic structures with musical motifs, considered in the Indian tradition to have the ability to "color the mind" and affect the emotions of the audience.[1][2][5] A raga consists of at least five notes, and each raga provides the musician with a musical framework.[3][6][7] The specific notes within a raga can be reordered and improvised by the musician, but a specific raga is either ascending or descending. Each raga has an emotional significance and symbolic associations such as with season, time and mood.[3] The raga is considered a means in Indian musical tradition to evoke certain feelings in an audience. Hundreds of raga are recognized in the classical Indian tradition, of which about 30 are common.[3][7] Each raga, state Dorothea -

Online Class Plan from 30.3.2020 to 4.4.2020 Click to Download
Department of Music Online Class Plan from 30.3.2020 to 4.4.2020 Dr.Gurinder H.Singh Name of the course: (CBCS) BA Prog. Part 1, Sem 2, Hindustani Music Name of paper: Basics of Indian Musicology. (62444201) Name of unit: 1 and 2 Primary study material: Practical -Raga Jaunpuri - Reference Book, Pt. Bhatkhande, Kramik Pustak Mallika, Vol-4, Pg. 604 a) Parichey b) Aroha, Avaroha, Pakad. Ability to sing and play on the Harmonium. b)Writing of the Notation in the Bandish in chota khayal (Theory) c) Learning to sing the Sthai d) Learning to sing the Antara. e) learning to sing 2 alaaps i ) Mandra to Madhya Saptak ii) Madhya Saptak to Taar Saptak. iii) learning to sing 3 Taans in 8 beats iv) learning to sing one Taan in 12 beats v) learning to sing one Taan in 16 beats. Raag Jaunpuri You Tube Links:- https://youtu.be/9FNv8CZAuA4 https://youtu.be/Ruqu6DPL6PI https://youtu.be/RPPMHvXciNA Dr.Prerna Arora Name of the course: (CBCS) BA Prog. Part 1, Sem 2, Hindustani Music Name of paper: Basics of Indian Musicology. (62444201) Name of unit: 1 and 2 Primary study material: Practical Raga Yaman Pt. Tejpal Singh, Vidhivat Sangeet Sikshan Pg. 111 a) Parichey b) Aroha, Avaroha, Pakad. Ability to sing and play on the Harmonium. b)Writing of the Notation in the Bandish in chota khayal (Theory) c) Learning to sing the Sthai d) Learning to sing the Antara. e) learning to sing 2 alaaps i ) Mandra to Madhya Saptak ii) Madhya Saptak to Taar Saptak. -

MKG-Xxviliitechmt/1 T/01 Tl W-N ~ ~ ---~---~~
1111111111111I1111111111111111111111111111111111111I111111111111111111111111111111111111111I1111111111111 MKG-XXVIlIITECHMT/1 T/01 POST CODE i~ ern; : Write here Roll Number and Answer Sheet No. ~~~~~~~ Roll No. I 3ijsfAi€fi Answer Sheet No./~~~ Time Allowed: 2 hours Maximum Marks: 200 Bmft1 ~ : 2 t:R .~~ : 200 1. If the Roll No. is a 8 digit No., the candidate needs to circle as 1. ~~8~~tm~~~~2 "00" as the first 2 digits in the first 2 columns of the Roll No. ~ ~ 1:!@ 2 3icf; ~~ if "oo..~ ~it I 2. OMR Answer Sheet is enclosed in this Booklet. You must 2. ~ T\R ~ if 3ir.~.:mc T\R ~ ~ tl w-n ~ ~ complete the details of Roll Number, Question Booklet No., qjffiq if~ ~ il ~ :mq ~ ~ if 3ltR1 itR~, etc., on the Answer Sheet and Answer Sheet No. on the space ~~mr,~(lm~~~ii~~~ ~~~~cj;'r~~1 ~~T\R~Cf?r provided above in this Question Booklet, before you actually ~~~:Jftt~~~~1 r--------- start answering the questions, failing which your Answer Sheet 3. 3ir.~.3m:. ~ ~ will not be evaluated and you will b~ awarded 'ZERO' mark. if trft m <f?: I 3. A machine will read the coded information in the OMR Answer ~~~~~~~~~ I • I I I ~ Sheet. In case non/wrong bubbling of Roll Number etc., the ~~~. 3iI.ltlf.3m:. "3ffi~<it I machine shall reject such OMR answer sheet and hence ~~~ 3fIi~ 3U.~.3ffi."3ffi I such OMR answer sheet shall not be evaluated. ~q;y~~~1 I 4. ~ ~~"@ft ms;:UCliT'~ ~ 4. Please check all the pages of the Booklet carefully. In case of '" ....Po~..;..,.~c:::"~-=.'.,...,~ 'I any defect, please ask the Invigilator for replacement of the ~ I "<''< 'I">'!/ '<'''I ~, (I] ''''.IGl'l"> <fit .j~ ~ Booklet. -

2 M Music Hcm.Pdf
Visva-Bharati, Sangit-Bhavana DEPARTMENT OF HINDUSTHANI CLASSICAL MUSIC CURRICULUM FOR POSTGRADUATE COURSE M.MUS IN HINDUSTHANI CLASSICAL MUSIC Sl.No Course Semester Credit Marks Full . Marks 1. 16 Courses I-IV 16X4=64 16X50 800 10 Courses Practical 06 Courses Theoretical Total Courses 16 Semester IV Credits 64 Marks 800 M.MUS IN HINDUSTHANI CLASSICAL MUSIC OUTLINE OF THE COURSE STRUCTURE 1st Semester 200 Marks Course Marks Credits Course-I (Practical) 40+10=50 4 Course-II (Practical) 40+10=50 4 Course-III (Practical) 40+10=50 4 Course-IV (Theoretical) 40+10=50 4 2nd Semester 200 Marks Course Marks Credits Course-V (Practical) 40+10=50 4 Course-VI (Practical) 40+10=50 4 Course-VII (Theoretical) 40+10=50 4 Course-VIII (Theoretical) 40+10=50 4 3rd Semester 200 Marks Course Marks Credits Course-IX (Practical) 40+10=50 4 Course-X (Practical) 40+10=50 4 Course-XI (Practical) 40+10=50 4 Course-XII (Theoretical) 40+10=50 4 4th Semester 200 Marks Course Marks Credits Course-XIII (Practical) 40+10=50 4 Course-XIV (Practical) 40+10=50 4 Course-XV (Theoretical) 40+10=50 4 Course-XVI (Theoretical) 40+10=50 4 1 Sangit-Bhavana, Visva Bharati Department of Hindusthani Classical Music CURRICULUM FOR POST GRADUATE COURSE M.MUS IN HINDUSTHANI CLASSICAL MUSIC TABLE OF CONTENTS HINDUSTHANI CLASSICAL MUSIC (VOCAL)………………………………………………3 HINDUSTHANI CLASSICAL MUSIC INSTRUMENTAL (SITAR)…………………………14 HINDUSTHANI CLASSICAL MUSIC INSTRUMENTAL (ESRAJ)…………………………23 HINDUSTHANI CLASSICAL MUSIC INSTRUMENTAL (TABLA)………………………..32 HINDUSTHANI CLASSICAL MUSIC INSTRUMENTAL (PAKHAWAJ)………………….42 2 CURRICULUM FOR POSTGRADUATE COURSE DEPARTMENT OF HINDUSTHANI CLASSICAL MUSIC SUBJECT- HINDUSTHANI CLASSICAL MUSIC (VOCAL) Course Objectives: This is a Master’s degree course in Hindustani Classical vocal music with emphasis on teaching a nuanced interpretation of different ragas. -

Classical Music (Vocal) (Honours)
Proposed Syllabus For Bachelor of Performing Arts (BPA) IN Hindustani Classical Music (Vocal) (Honours) Choice Based Credit System 2018 Department of Performing Arts Assam University, Silchar, Assam-7800 1 Details Course Structure Bachelor of Performing Arts (B.P.A) IN Hindustani Classical Music (Vocal) (Honours) Semester Core course Ability Skill Discipline Generic (14) Enhancement Enhancement Specific Elective Compulsory Course (SEC) Elective (DSE) (GE) (4) Course (AECC) (2) (4) (2) BPA-102, CC (Theory) BPA-101 BPA-104 SEM-I AECC-I GE-I BPA-103, CC (Practical) General (Practical) English/Mil BPA-202, CC (Theory) BPA-201 BPA-204 AE GE-II (Practical) SEM-II BPA-203, CC (Practical) CC-II Environmental Studies BPA-301, CC (Theory) BPA-305 BPA-304 SEM SEC-I GE-III III BPA-302, CC (Practical) (Practical) (Practical) BPA-303, CC (Theory) SEM BPA-401, CC (Theory) BPA-405 BPA-404 IV SEC-II GE-IV BPA-402, CC (Practical) (Practical) (Practical) BPA-403, CC (Theory) SEM BPA-501, CC (Theory) BPA-503 V DSE-I (Theory) BPA-502, CC (Practical) BPA-504 DSE-II (Practical) SEM BPA-601,CC (Theory) BPA-603 VI DSE-III (Theory) BPA-602,CC (Practical) BPA-604 DSE-IV (Practical) 2 Course Structure Semester Course Code Course Type Total External Internal Total Credit Marks Marks Marks I BPA-101,AECC-I English/MIL 2 70 30 100 BPA-102,CC Theory 6 70 30 100 BPA-103,CC Practical 6 70 30 100 BPA-104, GE-I Practical 6 70 30 100 II BPA-201,AECC-II Environmental Science 2 70 30 100 BPA-202, CC Theory 6 70 30 100 BPA-203, CC Practical 6 70 30 100 BPA-204, GE-II Theory -

40 an Effect of Raga Therapy on Our Human Body
International Journal of Humanities and Social Science Research ISSN: 2455-2070 www.socialresearchjournals.com Volume 1; Issue 1; November 2015; Page No. 40-43 An effect of Raga Therapy on our human body 1 Joyanta Sarkar, 2 Utpal Biswas 1 Department of Instrumental Music, RabindraBharati University 2 Assistant Professor, Department of Music, Tripura University Abstract Now a days, music assumes a vital part in each human life. Because of overwhelming work weight, people listen music to relax. Music increases the metabolic activities within the human body. It accelerates the respiration, influences the internal secretion, improves the muscular activities and as such affects the "Central Nervous System” and Circulatory System of the listener and the performer. A Raga is the sequence of selected notes (swaras) that lend appropriate ‘mood’ or emotion in a selective combination. It’s a yoga system through the medium of sonorous sounds. Depending on its nature, a raga could induce or intensify joy or sorrow, violence or peace, and it is this quality which forms the basis for musical application. Keywords: Raga Therapy, human body Introduction Music therapy as a means to identify with cultural and spiritual identity Music therapy to assist memory and imagination. Etc The goals of Raga therapy are dependent upon the purpose of music therapy for each individual case. Drug and alcohol centers and schools may use music therapy and behavior changing may be an important goal (Sairam, 2004a) [3]. Whereas, nursing homes may use music therapy in more of a support role or to relieve pain. Autism, a neurological disorder that affects normal brain functioning is usually noticed within 30 months of age. -

MUSIC N114T – Indian Classical Music (Instrumental)
BIRLA INSTITUTE OF TECHNOLOGY AND SCIENCE, PILANI INSTRUCTION DIVISION SECOND SEMESTER - 2017-2018 Course Handout (Part - II) Date :06/01/2018 In addition to part-I (General Handout for all courses appended to the time table) this portion gives further specific details regarding the course. Course No. : MUSIC N114T Course Title : Indian Classical Music (Instrumental) II Instructor-in-charge : ANlL RAI 1. Scope and Objective of the Course :- Performing Raags prescribed for the course with Sthai Antra and five fast improvisations in each Raag. Knowledge of Taals and simple Lavekaries. 2. Scope and Objectives- * To develop the performing skills of the Raags and Taals, prescribed for the course, in the students * Awareness and rendering all the parts of the Raga, with its ingredients * Understanding and performing the slow and the fast tempo compositions of the Ragas * Performing and plying Taals on the purcissions * Applying the Taals intricacies in the performances 3. Prescribed Text Books- Being a practical learning course, no book is prescribed. Only classroom teaching is required 4. Course Plan : Module Number Lecture session Learning Outcome 1. Notation system for L-1.1- Lecture for Bhatakhande Understanding of the notation writing compostions, notation system systems, popular in the Sargamgeets, alankars etc Hindustani Sangeet and Cernatic L-1.2- Lecture for Paluskar notation music System L-1.3- Lecture for Ceratic notation system 2. Use of Vadi-Samvadi in L-2.1- Lecture for the important notes Getting acquainted with the the Raag Mukhyachalan, of the Raga and their practical dominant, Sub-domonant and Raagvistar& their written application other important notes of the descriptions Raga, their use and application L-2.2- Common descriptions of Ragas L-2.3- Raag Progression 3. -

Hindustani Music (Vocal/Instrumental)
Choice Based Credit System (CBCS) UNIVERSITY OF DELHI DEPARTMENT OF MUSIC UNDERGRADUATE PROGRAMME (Courses effective from Academic Year 2015-16) SYLLABUS OF COURSES TO BE OFFERED Core Courses, Elective Courses & Ability Enhancement Courses Disclaimer: The CBCS syllabus is uploaded as given by the Faculty concerned to the Academic Council. The same has been approved as it is by the Academic Council on 13.7.2015 and Executive Council on 14.7.2015. Any query may kindly be addressed to the concerned Faculty. Undergraduate Programme Secretariat Preamble The University Grants Commission (UGC) has initiated several measures to bring equity, efficiency and excellence in the Higher Education System of country. The important measures taken to enhance academic standards and quality in higher education include innovation and improvements in curriculum, teaching-learning process, examination and evaluation systems, besides governance and other matters. The UGC has formulated various regulations and guidelines from time to time to improve the higher education system and maintain minimum standards and quality across the Higher Educational Institutions (HEIs) in India. The academic reforms recommended by the UGC in the recent past have led to overall improvement in the higher education system. However, due to lot of diversity in the system of higher education, there are multiple approaches followed by universities towards examination, evaluation and grading system. While the HEIs must have the flexibility and freedom in designing the examination and evaluation methods that best fits the curriculum, syllabi and teaching–learning methods, there is a need to devise a sensible system for awarding the grades based on the performance of students.