THE MICROPROCESSOR Von Neumann's Architecture Model Input/Output Unit Provides Instructions and Data Memory Unit Stores Both I
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Computer Architectures
Computer Architectures Central Processing Unit (CPU) Pavel Píša, Michal Štepanovský, Miroslav Šnorek The lecture is based on A0B36APO lecture. Some parts are inspired by the book Paterson, D., Henessy, V.: Computer Organization and Design, The HW/SW Interface. Elsevier, ISBN: 978-0-12-370606-5 and it is used with authors' permission. Czech Technical University in Prague, Faculty of Electrical Engineering English version partially supported by: European Social Fund Prague & EU: We invests in your future. AE0B36APO Computer Architectures Ver.1.10 1 Computer based on von Neumann's concept ● Control unit Processor/microprocessor ● ALU von Neumann architecture uses common ● Memory memory, whereas Harvard architecture uses separate program and data memories ● Input ● Output Input/output subsystem The control unit is responsible for control of the operation processing and sequencing. It consists of: ● registers – they hold intermediate and programmer visible state ● control logic circuits which represents core of the control unit (CU) AE0B36APO Computer Architectures 2 The most important registers of the control unit ● PC (Program Counter) holds address of a recent or next instruction to be processed ● IR (Instruction Register) holds the machine instruction read from memory ● Another usually present registers ● General purpose registers (GPRs) may be divided to address and data or (partially) specialized registers ● SP (Stack Pointer) – points to the top of the stack; (The stack is usually used to store local variables and subroutine return addresses) ● PSW (Program Status Word) ● IM (Interrupt Mask) ● Optional Floating point (FPRs) and vector/multimedia regs. AE0B36APO Computer Architectures 3 The main instruction cycle of the CPU 1. Initial setup/reset – set initial PC value, PSW, etc. -

Microprocessor Architecture
EECE416 Microcomputer Fundamentals Microprocessor Architecture Dr. Charles Kim Howard University 1 Computer Architecture Computer System CPU (with PC, Register, SR) + Memory 2 Computer Architecture •ALU (Arithmetic Logic Unit) •Binary Full Adder 3 Microprocessor Bus 4 Architecture by CPU+MEM organization Princeton (or von Neumann) Architecture MEM contains both Instruction and Data Harvard Architecture Data MEM and Instruction MEM Higher Performance Better for DSP Higher MEM Bandwidth 5 Princeton Architecture 1.Step (A): The address for the instruction to be next executed is applied (Step (B): The controller "decodes" the instruction 3.Step (C): Following completion of the instruction, the controller provides the address, to the memory unit, at which the data result generated by the operation will be stored. 6 Harvard Architecture 7 Internal Memory (“register”) External memory access is Very slow For quicker retrieval and storage Internal registers 8 Architecture by Instructions and their Executions CISC (Complex Instruction Set Computer) Variety of instructions for complex tasks Instructions of varying length RISC (Reduced Instruction Set Computer) Fewer and simpler instructions High performance microprocessors Pipelined instruction execution (several instructions are executed in parallel) 9 CISC Architecture of prior to mid-1980’s IBM390, Motorola 680x0, Intel80x86 Basic Fetch-Execute sequence to support a large number of complex instructions Complex decoding procedures Complex control unit One instruction achieves a complex task 10 -

What Do We Mean by Architecture?
Embedded programming: Comparing the performance and development workflows for architectures Embedded programming week FABLAB BRIGHTON 2018 What do we mean by architecture? The architecture of microprocessors and microcontrollers are classified based on the way memory is allocated (memory architecture). There are two main ways of doing this: Von Neumann architecture (also known as Princeton) Von Neumann uses a single unified cache (i.e. the same memory) for both the code (instructions) and the data itself, Under pure von Neumann architecture the CPU can be either reading an instruction or reading/writing data from/to the memory. Both cannot occur at the same time since the instructions and data use the same bus system. Harvard architecture Harvard architecture uses different memory allocations for the code (instructions) and the data, allowing it to be able to read instructions and perform data memory access simultaneously. The best performance is achieved when both instructions and data are supplied by their own caches, with no need to access external memory at all. How does this relate to microcontrollers/microprocessors? We found this page to be a good introduction to the topic of microcontrollers and microprocessors, the architectures they use and the difference between some of the common types. First though, it’s worth looking at the difference between a microprocessor and a microcontroller. Microprocessors (e.g. ARM) generally consist of just the Central Processing Unit (CPU), which performs all the instructions in a computer program, including arithmetic, logic, control and input/output operations. Microcontrollers (e.g. AVR, PIC or 8051) contain one or more CPUs with RAM, ROM and programmable input/output peripherals. -

The Von Neumann Computer Model 5/30/17, 10:03 PM
The von Neumann Computer Model 5/30/17, 10:03 PM CIS-77 Home http://www.c-jump.com/CIS77/CIS77syllabus.htm The von Neumann Computer Model 1. The von Neumann Computer Model 2. Components of the Von Neumann Model 3. Communication Between Memory and Processing Unit 4. CPU data-path 5. Memory Operations 6. Understanding the MAR and the MDR 7. Understanding the MAR and the MDR, Cont. 8. ALU, the Processing Unit 9. ALU and the Word Length 10. Control Unit 11. Control Unit, Cont. 12. Input/Output 13. Input/Output Ports 14. Input/Output Address Space 15. Console Input/Output in Protected Memory Mode 16. Instruction Processing 17. Instruction Components 18. Why Learn Intel x86 ISA ? 19. Design of the x86 CPU Instruction Set 20. CPU Instruction Set 21. History of IBM PC 22. Early x86 Processor Family 23. 8086 and 8088 CPU 24. 80186 CPU 25. 80286 CPU 26. 80386 CPU 27. 80386 CPU, Cont. 28. 80486 CPU 29. Pentium (Intel 80586) 30. Pentium Pro 31. Pentium II 32. Itanium processor 1. The von Neumann Computer Model Von Neumann computer systems contain three main building blocks: The following block diagram shows major relationship between CPU components: the central processing unit (CPU), memory, and input/output devices (I/O). These three components are connected together using the system bus. The most prominent items within the CPU are the registers: they can be manipulated directly by a computer program. http://www.c-jump.com/CIS77/CPU/VonNeumann/lecture.html Page 1 of 15 IPR2017-01532 FanDuel, et al. -

Towards Scalable Multiprocessor Virtual Machines
USENIX Association Proceedings of the Third Virtual Machine Research and Technology Symposium San Jose, CA, USA May 6–7, 2004 © 2004 by The USENIX Association All Rights Reserved For more information about the USENIX Association: Phone: 1 510 528 8649 FAX: 1 510 548 5738 Email: [email protected] WWW: http://www.usenix.org Rights to individual papers remain with the author or the author's employer. Permission is granted for noncommercial reproduction of the work for educational or research purposes. This copyright notice must be included in the reproduced paper. USENIX acknowledges all trademarks herein. Towards Scalable Multiprocessor Virtual Machines Volkmar Uhlig Joshua LeVasseur Espen Skoglund Uwe Dannowski System Architecture Group Universitat¨ Karlsruhe [email protected] Abstract of guests, such that they only ever access a fraction of the physical processors, or alternatively time-multiplex A multiprocessor virtual machine benefits its guest guests across a set of physical processors to, e.g., ac- operating system in supporting scalable job throughput commodate for spikes in guest OS workloads. It can and request latency—useful properties in server consol- also map guest operating systems to virtual processors idation where servers require several of the system pro- (which can exceed the number of physical processors), cessors for steady state or to handle load bursts. and migrate between physical processors without no- Typical operating systems, optimized for multipro- tifying the guest operating systems. This allows for, cessor systems in their use of spin-locks for critical sec- e.g., migration to other machine configurations or hot- tions, can defeat flexible virtual machine scheduling due swapping of CPUs without adequate support from the to lock-holder preemption and misbalanced load. -

Hardware Architecture
Hardware Architecture Components Computing Infrastructure Components Servers Clients LAN & WLAN Internet Connectivity Computation Software Storage Backup Integration is the Key ! Security Data Network Management Computer Today’s Computer Computer Model: Von Neumann Architecture Computer Model Input: keyboard, mouse, scanner, punch cards Processing: CPU executes the computer program Output: monitor, printer, fax machine Storage: hard drive, optical media, diskettes, magnetic tape Von Neumann architecture - Wiki Article (15 min YouTube Video) Components Computer Components Components Computer Components CPU Memory Hard Disk Mother Board CD/DVD Drives Adaptors Power Supply Display Keyboard Mouse Network Interface I/O ports CPU CPU CPU – Central Processing Unit (Microprocessor) consists of three parts: Control Unit • Execute programs/instructions: the machine language • Move data from one memory location to another • Communicate between other parts of a PC Arithmetic Logic Unit • Arithmetic operations: add, subtract, multiply, divide • Logic operations: and, or, xor • Floating point operations: real number manipulation Registers CPU Processor Architecture See How the CPU Works In One Lesson (20 min YouTube Video) CPU CPU CPU speed is influenced by several factors: Chip Manufacturing Technology: nm (2002: 130 nm, 2004: 90nm, 2006: 65 nm, 2008: 45nm, 2010:32nm, Latest is 22nm) Clock speed: Gigahertz (Typical : 2 – 3 GHz, Maximum 5.5 GHz) Front Side Bus: MHz (Typical: 1333MHz , 1666MHz) Word size : 32-bit or 64-bit word sizes Cache: Level 1 (64 KB per core), Level 2 (256 KB per core) caches on die. Now Level 3 (2 MB to 8 MB shared) cache also on die Instruction set size: X86 (CISC), RISC Microarchitecture: CPU Internal Architecture (Ivy Bridge, Haswell) Single Core/Multi Core Multi Threading Hyper Threading vs. -
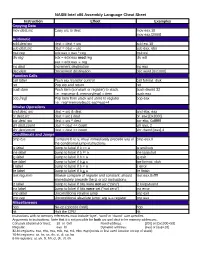
NASM Intel X86 Assembly Language Cheat Sheet
NASM Intel x86 Assembly Language Cheat Sheet Instruction Effect Examples Copying Data mov dest,src Copy src to dest mov eax,10 mov eax,[2000] Arithmetic add dest,src dest = dest + src add esi,10 sub dest,src dest = dest – src sub eax, ebx mul reg edx:eax = eax * reg mul esi div reg edx = edx:eax mod reg div edi eax = edx:eax reg inc dest Increment destination inc eax dec dest Decrement destination dec word [0x1000] Function Calls call label Push eip, transfer control call format_disk ret Pop eip and return ret push item Push item (constant or register) to stack. push dword 32 I.e.: esp=esp-4; memory[esp] = item push eax pop [reg] Pop item from stack and store to register pop eax I.e.: reg=memory[esp]; esp=esp+4 Bitwise Operations and dest, src dest = src & dest and ebx, eax or dest,src dest = src | dest or eax,[0x2000] xor dest, src dest = src ^ dest xor ebx, 0xfffffff shl dest,count dest = dest << count shl eax, 2 shr dest,count dest = dest >> count shr dword [eax],4 Conditionals and Jumps cmp b,a Compare b to a; must immediately precede any of cmp eax,0 the conditional jump instructions je label Jump to label if b == a je endloop jne label Jump to label if b != a jne loopstart jg label Jump to label if b > a jg exit jge label Jump to label if b > a jge format_disk jl label Jump to label if b < a jl error jle label Jump to label if b < a jle finish test reg,imm Bitwise compare of register and constant; should test eax,0xffff immediately precede the jz or jnz instructions jz label Jump to label if bits were not set (“zero”) jz looparound jnz label Jump to label if bits were set (“not zero”) jnz error jmp label Unconditional relative jump jmp exit jmp reg Unconditional absolute jump; arg is a register jmp eax Miscellaneous nop No-op (opcode 0x90) nop hlt Halt the CPU hlt Instructions with no memory references must include ‘byte’, ‘word’ or ‘dword’ size specifier. -

Optimizing HLT Code for Run-Time Efficiency
Optimizing HLT code for run-time efficiency Public Note Issue: 1 Revision: 0 Reference: LHCb-PUB-2010-017 Created: September 6, 2010 Last modified: November 4, 2010 LHCb-PUB-2010-017 04/11/2010 Prepared by: Axel Thuressona, Niko Neufeldb aLund,Sweden bCERN, PH Optimizing HLT code for run-time efficiency Ref: LHCb-PUB-2010-017 Public Note Issue: 1 Date: November 4, 2010 Abstract An upgrade of the High level trigger (HLT) farm at LHCb will be inevitable due to the increase in luminosity at the LHC. The upgrade will be done in two main ways. The first way is to make the software more efficient and faster. The second way is to increase the number of servers in the farm. This paper will concern both of these two ways divided into three parts. The first part is about NUMA, modern servers are all built with NUMA so an upgrade of the HLT farm will consist of this new architecture. The present HLT farm servers consists of the architecture UMA. After several tests it turned out that the Intel-servers that was used for testing (having 2 nodes) had very little penalty when comparing the worst-case the optimal-case. The conclusions for Intel-servers are that the NUMA architecture doesn’t affect the existing software negative. Several tests was done on an AMD-server having 8 nodes, and hence a more complicated structure. Non-optimal effects could be observed for this server and when comparing the worst-case with the optimal-case a big difference was found. So for the AMD-server the NUMA architecture can affect the existing software negative under certain circumstances. -

The Von Neumann Architecture of Computer Systems
The von Neumann Architecture of Computer Systems http://www.csupomona.edu/~hnriley/www/VonN.html The von Neumann Architecture of Computer Systems H. Norton Riley Computer Science Department California State Polytechnic University Pomona, California September, 1987 Any discussion of computer architectures, of how computers and computer systems are organized, designed, and implemented, inevitably makes reference to the "von Neumann architecture" as a basis for comparison. And of course this is so, since virtually every electronic computer ever built has been rooted in this architecture. The name applied to it comes from John von Neumann, who as author of two papers in 1945 [Goldstine and von Neumann 1963, von Neumann 1981] and coauthor of a third paper in 1946 [Burks, et al. 1963] was the first to spell out the requirements for a general purpose electronic computer. The 1946 paper, written with Arthur W. Burks and Hermann H. Goldstine, was titled "Preliminary Discussion of the Logical Design of an Electronic Computing Instrument," and the ideas in it were to have a profound impact on the subsequent development of such machines. Von Neumann's design led eventually to the construction of the EDVAC computer in 1952. However, the first computer of this type to be actually constructed and operated was the Manchester Mark I, designed and built at Manchester University in England [Siewiorek, et al. 1982]. It ran its first program in 1948, executing it out of its 96 word memory. It executed an instruction in 1.2 milliseconds, which must have seemed phenomenal at the time. Using today's popular "MIPS" terminology (millions of instructions per second), it would be rated at .00083 MIPS. -

An Overview of Parallel Computing
An Overview of Parallel Computing Marc Moreno Maza University of Western Ontario, London, Ontario (Canada) Chengdu HPC Summer School 20-24 July 2015 Plan 1 Hardware 2 Types of Parallelism 3 Concurrency Platforms: Three Examples Cilk CUDA MPI Hardware Plan 1 Hardware 2 Types of Parallelism 3 Concurrency Platforms: Three Examples Cilk CUDA MPI Hardware von Neumann Architecture In 1945, the Hungarian mathematician John von Neumann proposed the above organization for hardware computers. The Control Unit fetches instructions/data from memory, decodes the instructions and then sequentially coordinates operations to accomplish the programmed task. The Arithmetic Unit performs basic arithmetic operation, while Input/Output is the interface to the human operator. Hardware von Neumann Architecture The Pentium Family. Hardware Parallel computer hardware Most computers today (including tablets, smartphones, etc.) are equipped with several processing units (control+arithmetic units). Various characteristics determine the types of computations: shared memory vs distributed memory, single-core processors vs multicore processors, data-centric parallelism vs task-centric parallelism. Historically, shared memory machines have been classified as UMA and NUMA, based upon memory access times. Hardware Uniform memory access (UMA) Identical processors, equal access and access times to memory. In the presence of cache memories, cache coherency is accomplished at the hardware level: if one processor updates a location in shared memory, then all the other processors know about the update. UMA architectures were first represented by Symmetric Multiprocessor (SMP) machines. Multicore processors follow the same architecture and, in addition, integrate the cores onto a single circuit die. Hardware Non-uniform memory access (NUMA) Often made by physically linking two or more SMPs (or multicore processors). -

Introduction to Graphics Hardware and GPU's
Blockseminar: Verteiltes Rechnen und Parallelprogrammierung Tim Conrad GPU Computer: CHINA.imp.fu-berlin.de GPU Intro Today • Introduction to GPGPUs • “Hands on” to get you started • Assignment 3 • Projects GPU Intro Traditional Computing Von Neumann architecture: instructions are sent from memory to the CPU Serial execution: Instructions are executed one after another on a single Central Processing Unit (CPU) Problems: • More expensive to produce • More expensive to run • Bus speed limitation GPU Intro Parallel Computing Official-sounding definition: The simultaneous use of multiple compute resources to solve a computational problem. Benefits: • Economical – requires less power and cheaper to produce • Better performance – bus/bottleneck issue Limitations: • New architecture – Von Neumann is all we know! • New debugging difficulties – cache consistency issue GPU Intro Flynn’s Taxonomy Classification of computer architectures, proposed by Michael J. Flynn • SISD – traditional serial architecture in computers. • SIMD – parallel computer. One instruction is executed many times with different data (think of a for loop indexing through an array) • MISD - Each processing unit operates on the data independently via independent instruction streams. Not really used in parallel • MIMD – Fully parallel and the most common form of parallel computing. GPU Intro Enter CUDA CUDA is NVIDIA’s general purpose parallel computing architecture • Designed for calculation-intensive computation on GPU hardware • CUDA is not a language, it is an API • We will -

Computer Architecture
Computer architecture Compendium for INF2270 Philipp Häfliger, Dag Langmyhr and Omid Mirmotahari Spring 2013 Contents Contents iii List of Figures vii List of Tables ix 1 Introduction1 I Basics of computer architecture3 2 Introduction to Digital Electronics5 3 Binary Numbers7 3.1 Unsigned Binary Numbers.........................7 3.2 Signed Binary Numbers..........................7 3.2.1 Sign and Magnitude........................7 3.2.2 Two’s Complement........................8 3.3 Addition and Subtraction.........................8 3.4 Multiplication and Division......................... 10 3.5 Extending an n-bit binary to n+k bits................... 11 4 Boolean Algebra 13 4.1 Karnaugh maps............................... 16 4.1.1 Karnaugh maps with 5 and 6 bit variables........... 18 4.1.2 Karnaugh map simplification with ‘X’s.............. 19 4.1.3 Karnaugh map simplification based on zeros.......... 19 5 Combinational Logic Circuits 21 5.1 Standard Combinational Circuit Blocks................. 22 5.1.1 Encoder............................... 23 5.1.2 Decoder.............................. 24 5.1.3 Multiplexer............................. 25 5.1.4 Demultiplexer........................... 26 5.1.5 Adders............................... 26 6 Sequential Logic Circuits 31 6.1 Flip-Flops.................................. 31 6.1.1 Asynchronous Latches...................... 31 6.1.2 Synchronous Flip-Flops...................... 34 6.2 Finite State Machines............................ 37 6.2.1 State Transition Graphs...................... 37 6.3 Registers................................... 39 6.4 Standard Sequential Logic Circuits.................... 40 6.4.1 Counters.............................. 40 6.4.2 Shift Registers........................... 42 Page iii CONTENTS 7 Von Neumann Architecture 45 7.1 Data Path and Memory Bus........................ 47 7.2 Arithmetic and Logic Unit (ALU)..................... 47 7.3 Memory................................... 48 7.3.1 Static Random Access Memory (SRAM)...........