1 Supplementary Text for Functional Gene Array-Based Ultra-Sensitive
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Classification of Esterases: an Important Gene Family Involved in Insecticide Resistance - a Review
Mem Inst Oswaldo Cruz, Rio de Janeiro, Vol. 107(4): 437-449, June 2012 437 The classification of esterases: an important gene family involved in insecticide resistance - A Review Isabela Reis Montella1,2, Renata Schama1,2,3/+, Denise Valle1,2,3 1Laboratório de Fisiologia e Controle de Artrópodes Vetores, Instituto Oswaldo Cruz-Fiocruz, Av. Brasil 4365, 21040-900 Rio de Janeiro, RJ, Brasil 2Instituto de Biologia do Exército, Rio de Janeiro, RJ, Brasil 3Instituto Nacional de Ciência e Tecnologia em Entomologia Molecular, Rio de Janeiro, RJ, Brasil The use of chemical insecticides continues to play a major role in the control of disease vector populations, which is leading to the global dissemination of insecticide resistance. A greater capacity to detoxify insecticides, due to an increase in the expression or activity of three major enzyme families, also known as metabolic resistance, is one major resistance mechanisms. The esterase family of enzymes hydrolyse ester bonds, which are present in a wide range of insecticides; therefore, these enzymes may be involved in resistance to the main chemicals employed in control programs. Historically, insecticide resistance has driven research on insect esterases and schemes for their classification. Currently, several different nomenclatures are used to describe the esterases of distinct species and a universal standard classification does not exist. The esterase gene family appears to be rapidly evolving and each insect species has a unique complement of detoxification genes with only a few orthologues across species. The examples listed in this review cover different aspects of their biochemical nature. However, they do not appear to contribute to reliably distinguish among the different resistance mechanisms. -

Supporting Information
Supporting Information Figure S1. The functionality of the tagged Arp6 and Swr1 was confirmed by monitoring cell growth and sensitivity to hydeoxyurea (HU). Five-fold serial dilutions of each strain were plated on YPD with or without 50 mM HU and incubated at 30°C or 37°C for 3 days. Figure S2. Localization of Arp6 and Swr1 on chromosome 3. The binding of Arp6-FLAG (top), Swr1-FLAG (middle), and Arp6-FLAG in swr1 cells (bottom) are compared. The position of Tel 3L, Tel 3R, CEN3, and the RP gene are shown under the panels. Figure S3. Localization of Arp6 and Swr1 on chromosome 4. The binding of Arp6-FLAG (top), Swr1-FLAG (middle), and Arp6-FLAG in swr1 cells (bottom) in the whole chromosome region are compared. The position of Tel 4L, Tel 4R, CEN4, SWR1, and RP genes are shown under the panels. Figure S4. Localization of Arp6 and Swr1 on the region including the SWR1 gene of chromosome 4. The binding of Arp6- FLAG (top), Swr1-FLAG (middle), and Arp6-FLAG in swr1 cells (bottom) are compared. The position and orientation of the SWR1 gene is shown. Figure S5. Localization of Arp6 and Swr1 on chromosome 5. The binding of Arp6-FLAG (top), Swr1-FLAG (middle), and Arp6-FLAG in swr1 cells (bottom) are compared. The position of Tel 5L, Tel 5R, CEN5, and the RP genes are shown under the panels. Figure S6. Preferential localization of Arp6 and Swr1 in the 5′ end of genes. Vertical bars represent the binding ratio of proteins in each locus. -

744 Hydrolysis of Chiral Organophosphorus Compounds By
[Frontiers in Bioscience, Landmark, 26, 744-770, Jan 1, 2021] Hydrolysis of chiral organophosphorus compounds by phosphotriesterases and mammalian paraoxonase-1 Antonio Monroy-Noyola1, Damianys Almenares-Lopez2, Eugenio Vilanova Gisbert3 1Laboratorio de Neuroproteccion, Facultad de Farmacia, Universidad Autonoma del Estado de Morelos, Morelos, Mexico, 2Division de Ciencias Basicas e Ingenierias, Universidad Popular de la Chontalpa, H. Cardenas, Tabasco, Mexico, 3Instituto de Bioingenieria, Universidad Miguel Hernandez, Elche, Alicante, Spain TABLE OF CONTENTS 1. Abstract 2. Introduction 2.1. Organophosphorus compounds (OPs) and their toxicity 2.2. Metabolism and treatment of OP intoxication 2.3. Chiral OPs 3. Stereoselective hydrolysis 3.1. Stereoselective hydrolysis determines the toxicity of chiral compounds 3.2. Hydrolysis of nerve agents by PTEs 3.2.1. Hydrolysis of V-type agents 3.3. PON1, a protein restricted in its ability to hydrolyze chiral OPs 3.4. Toxicity and stereoselective hydrolysis of OPs in animal tissues 3.4.1. The calcium-dependent stereoselective activity of OPs associated with PON1 3.4.2. Stereoselective hydrolysis commercial OPs pesticides by alloforms of PON1 Q192R 3.4.3. PON1, an enzyme that stereoselectively hydrolyzes OP nerve agents 3.4.4. PON1 recombinants and stereoselective hydrolysis of OP nerve agents 3.5. The activity of PTEs in birds 4. Conclusions 5. Acknowledgments 6. References 1. ABSTRACT Some organophosphorus compounds interaction of the racemic OPs with these B- (OPs), which are used in the manufacturing of esterases (AChE and NTE) and such interactions insecticides and nerve agents, are racemic mixtures have been studied in vivo, ex vivo and in vitro, using with at least one chiral center with a phosphorus stereoselective hydrolysis by A-esterases or atom. -

Enzymatic Degradation of Organophosphorus Pesticides and Nerve Agents by EC: 3.1.8.2
catalysts Review Enzymatic Degradation of Organophosphorus Pesticides and Nerve Agents by EC: 3.1.8.2 Marek Matula 1, Tomas Kucera 1 , Ondrej Soukup 1,2 and Jaroslav Pejchal 1,* 1 Department of Toxicology and Military Pharmacy, Faculty of Military Health Sciences, University of Defence, Trebesska 1575, 500 01 Hradec Kralove, Czech Republic; [email protected] (M.M.); [email protected] (T.K.); [email protected] (O.S.) 2 Biomedical Research Center, University Hospital Hradec Kralove, Sokolovska 581, 500 05 Hradec Kralove, Czech Republic * Correspondence: [email protected] Received: 26 October 2020; Accepted: 20 November 2020; Published: 24 November 2020 Abstract: The organophosphorus substances, including pesticides and nerve agents (NAs), represent highly toxic compounds. Standard decontamination procedures place a heavy burden on the environment. Given their continued utilization or existence, considerable efforts are being made to develop environmentally friendly methods of decontamination and medical countermeasures against their intoxication. Enzymes can offer both environmental and medical applications. One of the most promising enzymes cleaving organophosphorus compounds is the enzyme with enzyme commission number (EC): 3.1.8.2, called diisopropyl fluorophosphatase (DFPase) or organophosphorus acid anhydrolase from Loligo Vulgaris or Alteromonas sp. JD6.5, respectively. Structure, mechanisms of action and substrate profiles are described for both enzymes. Wild-type (WT) enzymes have a catalytic activity against organophosphorus compounds, including G-type nerve agents. Their stereochemical preference aims their activity towards less toxic enantiomers of the chiral phosphorus center found in most chemical warfare agents. Site-direct mutagenesis has systematically improved the active site of the enzyme. These efforts have resulted in the improvement of catalytic activity and have led to the identification of variants that are more effective at detoxifying both G-type and V-type nerve agents. -
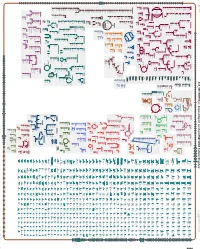
Generate Metabolic Map Poster
Authors: Pallavi Subhraveti Ron Caspi Quang Ong Peter D Karp An online version of this diagram is available at BioCyc.org. Biosynthetic pathways are positioned in the left of the cytoplasm, degradative pathways on the right, and reactions not assigned to any pathway are in the far right of the cytoplasm. Transporters and membrane proteins are shown on the membrane. Ingrid Keseler Periplasmic (where appropriate) and extracellular reactions and proteins may also be shown. Pathways are colored according to their cellular function. Gcf_900114035Cyc: Amycolatopsis sacchari DSM 44468 Cellular Overview Connections between pathways are omitted for legibility. -

Reconsideration of the Catalytic Center and Mechanism of Mammalian
Proc. Natl. Acad. Sci. USA Vol. 92, pp. 7187-7191, August 1995 Genetics Reconsideration of the catalytic center and mechanism of mammalian paraoxonase/arylesterase (organophosphatase/A-esterase/site-directed mutagenesis/high density lipoprotein/phosphotriesterase) ROBERT C. SORENSON*, SERGIO L. PRIMO-PARMOt, CHUNG-LIANG Kuot, STEVE ADKINS0§, OKSANA LOCKRIDGEI, AND BERT N. LA DU*tll *Department of Pharmacology, University of Michigan Medical School, Ann Arbor, MI 48109-0632; tDepartment of Anesthesiology, Research Division, 4038 Kresge Research II, University of Michigan Medical School, Ann Arbor, MI 48109-0572; tDepartment of Environmental and Industrial Health, School of Public Health, University of Michigan, Ann Arbor, MI 48109-2029; §Mental Health Research Institute and Department of Human Genetics, University of Michigan Medical School, Ann Arbor, MI 48109-0720; and lEppley Institute, University of Nebraska Medical Center, Omaha, NB 68198-6805 Communicated by James V Neel, University ofMichigan Medical School, Ann Arbor, MI, May 2, 1995 ABSTRACT For three decades, mammalian paraoxonase basis for the human polymorphism was the presence of argi- (A-esterase, aromatic esterase, arylesterase; PON, EC 3.1.8.1) nine (high PON activity, B-type allozyme) or glutamine (low has been thought to be a cysteine esterase demonstrating PON activity, A-type allozyme) at position 191 (11-13). structural and mechanistic homologies with the serine ester- Augustinsson (14, 15) suggested that PON, the carboxyes- ases (cholinesterases and carboxyesterases). Human, mouse, terases, and the cholinesterases were products of divergent and rabbit PONs each contain only three cysteine residues, evolution from an ancestral arylesterase but that PON utilized and their positions within PON have been conserved. -

Electronic Supplementary Material (ESI) for Analytical Methods. This Journal Is © the Royal Society of Chemistry 2014
Electronic Supplementary Material (ESI) for Analytical Methods. This journal is © The Royal Society of Chemistry 2014 Table S2. List of proteins detected in HCC serum. # # MW Accession Coverage Pepti calc. pI Score Description PSMs [kDa] des gi105990532 25.03 1012 66 515.2 7.05 1343.34 apolipoprotein B-100 precursor [Homo sapiens] gi225311 25.31 977 66 512.6 6.98 1324.72 lipoprotein B100 gi225310 24.57 972 65 515.2 7.06 1310.41 lipoprotein B100 gi119370332 52.25 1738 59 187.0 6.40 1995.72 Complement C3 gi122920512 76.07 4583 49 66.4 5.87 8935.61 Chain A, Human Serum Albumin Complexed With Myristate And Aspirin gi55669910 75.52 4500 46 65.2 5.80 8730.74 Chain A, Crystal Structure Of The Ga Module Complexed With Human Serum Albumin gi308153640 36.77 1109 35 163.2 6.46 1690.96 RecName: Full=Alpha-2-macroglobulin; Short=Alpha-2-M; AltName: Full=C3 and PZP- like alpha-2-macroglobulin domain-containing protein 5; Flags: Precursor gi66932947 36.77 1103 35 163.2 6.42 1690.30 alpha-2-macroglobulin precursor [Homo sapiens] gi118138017 49.95 975 30 103.9 5.29 1091.77 Chain B, Human Complement Component C3b gi110590600 52.22 903 29 74.8 7.12 1859.56 Chain B, Apo-Human Serum Transferrin (Glycosylated) gi317455058 64.17 761 29 71.0 7.30 891.66 Chain C, Crystal Structure Of Complement C3b In Complex With Factors B And D gi157831597 38.81 582 28 120.0 5.68 888.21 Chain A, X-Ray Crystal Structure Of Human Ceruloplasmin At 3.0 Angstroms gi81175167 27.58 334 26 192.7 7.15 517.84 Complement C4-B gi178557739 26.89 339 25 192.6 7.27 506.65 complement C4-B preproprotein -

Complete Genome of the Cellulolytic Thermophile Acidothermus Cellulolyticus 11B Provides Insights Into Its Ecophysiological and Evolutionary Adaptations
Downloaded from genome.cshlp.org on October 2, 2021 - Published by Cold Spring Harbor Laboratory Press Letter Complete genome of the cellulolytic thermophile Acidothermus cellulolyticus 11B provides insights into its ecophysiological and evolutionary adaptations Ravi D. Barabote,1,9 Gary Xie,1 David H. Leu,2 Philippe Normand,3 Anamaria Necsulea,4 Vincent Daubin,4 Claudine Me´digue,5 William S. Adney,6 Xin Clare Xu,2 Alla Lapidus,7 Rebecca E. Parales,8 Chris Detter,1 Petar Pujic,3 David Bruce,1 Celine Lavire,3 Jean F. Challacombe,1 Thomas S. Brettin,1 and Alison M. Berry2,10 1DOE Joint Genome Institute, Bioscience Division, Los Alamos National Laboratory, Los Alamos, New Mexico 87545, USA; 2Department of Plant Sciences, University of California, Davis, California 95616, USA; 3Centre National de la Recherche Scientifique (CNRS), UMR5557, E´cologie Microbienne, Universite´ Lyon I, Villeurbanne F-69622, France; 4Centre National de la Recherche Scientifique (CNRS), UMR5558, Laboratoire de Biome´trie et Biologie E´volutive, Universite´ Lyon I, Villeurbanne F-69622, France; 5Centre National de la Recherche Scientifique (CNRS), UMR8030 and CEA/DSV/IG/Genoscope, Laboratoire de Ge´nomique Comparative, 91057 Evry Cedex, France; 6National Renewable Energy Laboratory, Golden, Colorado 80401, USA; 7DOE Joint Genome Institute, Walnut Creek, California 94598, USA; 8Department of Microbiology, University of California, Davis, California 95616, USA We present here the complete 2.4-Mb genome of the cellulolytic actinobacterial thermophile Acidothermus cellulolyticus 11B. New secreted glycoside hydrolases and carbohydrate esterases were identified in the genome, revealing a diverse biomass- degrading enzyme repertoire far greater than previously characterized and elevating the industrial value of this organism. -

Literature Mining Methods for Toxicology and Construction of Adverse Outcome Pathways
Literature Mining Methods for Toxicology and Construction of Adverse Outcome Pathways Nancy C. Baker, PhD –Lockheed Martin (contractor) Thomas B. Knudsen, PhD -National Center for Computational Toxicology US EPA, Research Triangle Park, NC 27711 [email protected] [email protected] 1st Workshop/Scientific Expert Group meeting on the OECD Retinoid Project April 26, 2016 –Brussels The views expressed in this presentation are those of the presenter(s) and do not necessarily reflect the views or policies of the U.S. Environmental Protection Agency. 4/27/2016 Text mining – why do it? Unstructured Structured Text data Chemical Gene Amount Corticosterone NR3C1 416 Tretinoin RARA 397 Mifepristone NR3C1 260 Fenofibrate PPARA 189 Estradiol EGFR 119 Tretinoin RARG 111 Tamoxifen EGFR 96 Tretinoin EGFR 86 Triamcinolone NR3C1 83 Lovastatin LDLR 65 Estradiol NR3C1 60 Estradiol MMP9 54 Genistein EGFR 50 Phenobarbital NR1I3 48 • Integrate • Analyze • Cluster • Model • Infer • Visualize • Discover • Deal with Error / noise / bias Anatomy of a PubMed record MeSH Indexing annotations MeSH • Medical Subject Headings • Not designed to be used as data … but that’s what many people do. • But like data they are a controlled vocabulary Format: Heading / subheading Chemical Disease or condition caused by chemical Effect from chemical https://www.nlm.nih.gov/mesh/MBrowser.html Indexing terms data PubMed ID MeSH heading Qualifier / subheading Majr 15907662 Chlorpyrifos Administration & dosage N 15907662 Chlorpyrifos Toxicity Y 15907662 Cleft Palate Chemically -

12) United States Patent (10
US007635572B2 (12) UnitedO States Patent (10) Patent No.: US 7,635,572 B2 Zhou et al. (45) Date of Patent: Dec. 22, 2009 (54) METHODS FOR CONDUCTING ASSAYS FOR 5,506,121 A 4/1996 Skerra et al. ENZYME ACTIVITY ON PROTEIN 5,510,270 A 4/1996 Fodor et al. MICROARRAYS 5,512,492 A 4/1996 Herron et al. 5,516,635 A 5/1996 Ekins et al. (75) Inventors: Fang X. Zhou, New Haven, CT (US); 5,532,128 A 7/1996 Eggers Barry Schweitzer, Cheshire, CT (US) 5,538,897 A 7/1996 Yates, III et al. s s 5,541,070 A 7/1996 Kauvar (73) Assignee: Life Technologies Corporation, .. S.E. al Carlsbad, CA (US) 5,585,069 A 12/1996 Zanzucchi et al. 5,585,639 A 12/1996 Dorsel et al. (*) Notice: Subject to any disclaimer, the term of this 5,593,838 A 1/1997 Zanzucchi et al. patent is extended or adjusted under 35 5,605,662 A 2f1997 Heller et al. U.S.C. 154(b) by 0 days. 5,620,850 A 4/1997 Bamdad et al. 5,624,711 A 4/1997 Sundberg et al. (21) Appl. No.: 10/865,431 5,627,369 A 5/1997 Vestal et al. 5,629,213 A 5/1997 Kornguth et al. (22) Filed: Jun. 9, 2004 (Continued) (65) Prior Publication Data FOREIGN PATENT DOCUMENTS US 2005/O118665 A1 Jun. 2, 2005 EP 596421 10, 1993 EP 0619321 12/1994 (51) Int. Cl. EP O664452 7, 1995 CI2O 1/50 (2006.01) EP O818467 1, 1998 (52) U.S. -

Anti-PON1 Monoclonal Antibody, Clone FQS3903 (CABT-36017RH) This Product Is for Research Use Only and Is Not Intended for Diagnostic Use
Anti-PON1 monoclonal antibody, clone FQS3903 (CABT-36017RH) This product is for research use only and is not intended for diagnostic use. PRODUCT INFORMATION Product Overview Rabbit monoclonal antibody to Human PON1. Antigen Description The protein encoded by this gene is an unusual orphan receptor that contains a putative ligand- binding domain but lacks a conventional DNA-binding domain. The gene product is a member of the nuclear hormone receptor family, a group of transcription factors regulated by small hydrophobic hormones, a subset of which do not have known ligands and are referred to as orphan nuclear receptors. The protein has been shown to interact with retinoid and thyroid hormone receptors, inhibiting their ligand-dependent transcriptional activation. In addition, interaction with estrogen receptors has been demonstrated, leading to inhibition of function. Studies suggest that the protein represses nuclear hormone receptor-mediated transactivation via two separate steps: competition with coactivators and the direct effects of its transcriptional repressor function. Immunogen Synthetic peptide corresponding to residues near the N terminus of Human PON1. Isotype IgG Source/Host Rabbit Species Reactivity Human Clone FQS3903 Purification Tissue culture supernatant Conjugate Unconjugated Applications IHC-P, IP, WB Sequence Similarities Belongs to the paraoxonase family. Format Liquid Size 100 μl Buffer Preservative: 0.01% Sodium AzideConstituents: 40% Glycerol, 0.05% BSA, Tissue culture supernatant, 0.15M Sodium chloride, 50mM Tris glycine, pH 7.4 Preservative 0.01% Sodium Azide 45-1 Ramsey Road, Shirley, NY 11967, USA Email: [email protected] Tel: 1-631-624-4882 Fax: 1-631-938-8221 1 © Creative Diagnostics All Rights Reserved Storage Store at -20°C. -

Gfapind Nestin G FA P DA PI
Figure S1 GFAPInd NB +bFGF/+EGF NB -bFGF/-EGF nestin GFAP DAPI (a) Figure S1 GFAPConst NB +bFGF+/+EGF NB -bFGF/-EGF nestin GFAP DAPI (b) Figure S2 +bFGF/+EGF (a) Figure S2 -bFGF/-EGF (b) Figure S3 #10 #1095 #1051 #1063 #1043 #1083 ~20 weeks GSCs GSC_IRs compare tumor-propagating capacity proliferation gene expression Supplemental Table S1. Expression patterns of nestin and GFAP in GSCs self-renewing in vitro. GSC line nestin (%) GFAP (%) #10 90 ± 1,9 26 ± 5,8 #1095 92 ± 5,4 1,45 ± 0,1 #1063 74,4 ± 27,9 3,14 ± 1,8 #1051 92 ± 1,3 < 1 #1043 96,7 ± 1,4 96,7 ± 1,4 #1080 99 ± 0,6 99 ± 0,6 #1083 64,5 ± 14,1 64,5 ± 14,1 G112-NB 99 ± 1,6 99 ± 1,6 Immunofluorescence staining of GSCs cultured under self-renewal promoting condition Supplemental Table S2. Gene expression analysis by Gene Ontology terms.