Memory Hierarchy and Cache Design
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

File Systems and Disk Layout I/O: the Big Picture
File Systems and Disk Layout I/O: The Big Picture Processor interrupts Cache Memory Bus I/O Bridge Main I/O Bus Memory Disk Graphics Network Controller Controller Interface Disk Disk Graphics Network 1 Rotational Media Track Sector Arm Cylinder Platter Head Access time = seek time + rotational delay + transfer time seek time = 5-15 milliseconds to move the disk arm and settle on a cylinder rotational delay = 8 milliseconds for full rotation at 7200 RPM: average delay = 4 ms transfer time = 1 millisecond for an 8KB block at 8 MB/s Bandwidth utilization is less than 50% for any noncontiguous access at a block grain. Disks and Drivers Disk hardware and driver software provide basic facilities for nonvolatile secondary storage (block devices). 1. OS views the block devices as a collection of volumes. A logical volume may be a partition ofasinglediskora concatenation of multiple physical disks (e.g., RAID). 2. OS accesses each volume as an array of fixed-size sectors. Identify sector (or block) by unique (volumeID, sector ID). Read/write operations DMA data to/from physical memory. 3. Device interrupts OS on I/O completion. ISR wakes up process, updates internal records, etc. 2 Using Disk Storage Typical operating systems use disks in three different ways: 1. System calls allow user programs to access a “raw” disk. Unix: special device file identifies volume directly. Any process that can open thedevicefilecanreadorwriteany specific sector in the disk volume. 2. OS uses disk as backing storage for virtual memory. OS manages volume transparently as an “overflow area” for VM contents that do not “fit” in physical memory. -

Semiconductor Memories
Semiconductor Memories Prof. MacDonald Types of Memories! l" Volatile Memories –" require power supply to retain information –" dynamic memories l" use charge to store information and require refreshing –" static memories l" use feedback (latch) to store information – no refresh required l" Non-Volatile Memories –" ROM (Mask) –" EEPROM –" FLASH – NAND or NOR –" MRAM Memory Hierarchy! 100pS RF 100’s of bytes L1 1nS SRAM 10’s of Kbytes 10nS L2 100’s of Kbytes SRAM L3 100’s of 100nS DRAM Mbytes 1us Disks / Flash Gbytes Memory Hierarchy! l" Large memories are slow l" Fast memories are small l" Memory hierarchy gives us illusion of large memory space with speed of small memory. –" temporal locality –" spatial locality Register Files ! l" Fastest and most robust memory array l" Largest bit cell size l" Basically an array of large latches l" No sense amps – bits provide full rail data out l" Often multi-ported (i.e. 8 read ports, 2 write ports) l" Often used with ALUs in the CPU as source/destination l" Typically less than 10,000 bits –" 32 32-bit fixed point registers –" 32 60-bit floating point registers SRAM! l" Same process as logic so often combined on one die l" Smaller bit cell than register file – more dense but slower l" Uses sense amp to detect small bit cell output l" Fastest for reads and writes after register file l" Large per bit area costs –" six transistors (single port), eight transistors (dual port) l" L1 and L2 Cache on CPU is always SRAM l" On-chip Buffers – (Ethernet buffer, LCD buffer) l" Typical sizes 16k by 32 Static Memory -

EEPROM Emulation
...the world's most energy friendly microcontrollers EEPROM Emulation AN0019 - Application Note Introduction This application note demonstrates a way to use the flash memory of the EFM32 to emulate single variable rewritable EEPROM memory through software. The example API provided enables reading and writing of single variables to non-volatile flash memory. The erase-rewrite algorithm distributes page erases and thereby doing wear leveling. This application note includes: • This PDF document • Source files (zip) • Example C-code • Multiple IDE projects 2013-09-16 - an0019_Rev1.09 1 www.silabs.com ...the world's most energy friendly microcontrollers 1 General Theory 1.1 EEPROM and Flash Based Memory EEPROM stands for Electrically Erasable Programmable Read-Only Memory and is a type of non- volatile memory that is byte erasable and therefore often used to store small amounts of data that must be saved when power is removed. The EFM32 microcontrollers do not include an embedded EEPROM module for byte erasable non-volatile storage, but all EFM32s do provide flash memory for non-volatile data storage. The main difference between flash memory and EEPROM is the erasable unit size. Flash memory is block-erasable which means that bytes cannot be erased individually, instead a block consisting of several bytes need to be erased at the same time. Through software however, it is possible to emulate individually erasable rewritable byte memory using block-erasable flash memory. To provide EEPROM functionality for the EFM32s in an application, there are at least two options available. The first one is to include an external EEPROM module when designing the hardware layout of the application. -

A Hybrid Swapping Scheme Based on Per-Process Reclaim for Performance Improvement of Android Smartphones (August 2018)
Received August 19, 2018, accepted September 14, 2018, date of publication October 1, 2018, date of current version October 25, 2018. Digital Object Identifier 10.1109/ACCESS.2018.2872794 A Hybrid Swapping Scheme Based On Per-Process Reclaim for Performance Improvement of Android Smartphones (August 2018) JUNYEONG HAN 1, SUNGEUN KIM1, SUNGYOUNG LEE1, JAEHWAN LEE2, AND SUNG JO KIM2 1LG Electronics, Seoul 07336, South Korea 2School of Software, Chung-Ang University, Seoul 06974, South Korea Corresponding author: Sung Jo Kim ([email protected]) This work was supported in part by the Basic Science Research Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Education under Grant 2016R1D1A1B03931004 and in part by the Chung-Ang University Research Scholarship Grants in 2015. ABSTRACT As a way to increase the actual main memory capacity of Android smartphones, most of them make use of zRAM swapping, but it has limitation in increasing its capacity since it utilizes main memory. Unfortunately, they cannot use secondary storage as a swap space due to the long response time and wear-out problem. In this paper, we propose a hybrid swapping scheme based on per-process reclaim that supports both secondary-storage swapping and zRAM swapping. It attempts to swap out all the pages in the working set of a process to a zRAM swap space rather than killing the process selected by a low-memory killer, and to swap out the least recently used pages into a secondary storage swap space. The main reason being is that frequently swap- in/out pages use the zRAM swap space while less frequently swap-in/out pages use the secondary storage swap space, in order to reduce the page operation cost. -

AN-1471 Application Note
AN-1471 APPLICATION NOTE One Technology Way • P. O. Box 9106 • Norwood, MA 02062-9106, U.S.A. • Tel: 781.329.4700 • Fax: 781.461.3113 • www.analog.com ADuCM4050 Flash EEPROM Emulation by Pranit Jadhav and Rafael Lajara INTRODUCTION provides assurance that the flash initialization function works as Nonvolatile data storage is a necessity in many embedded expected. An ECC check is enabled for the entire user space in systems. Data, such as boot up configuration, calibration constants, the flash memory of the ADuCM4050. If ECC errors are reported and network related information, is normally stored on an during any read operation, the ECC engine automatically corrects electronically erasable programmable read only memory 1-bit errors and only reports on detection of 2-bit errors. When a (EEPROM) device. The advantage of using the EEPROM to store read occurs on the flash, appropriate flags are set in the status this data is that a single byte on an EEPROM device can be register of the ADuCM4050. If interrupts are generated, the source rewritten or updated without affecting the contents in the other address of the ECC error causing an interrupt is available in the locations. FLCC0_ECC_ADDR register for the interrupt service routine (ISR) to read. The ADuCM4050 is an ultra low power microcontroller unit (MCU) with integrated flash memory. The ADuCM4050 includes Emulation of the EEPROM on the integrated flash memory 512 kB of embedded flash memory with a 72-bit wide data bus reduces the bill of material (BOM) cost by omitting the EEPROM that provides two 32-bits words of data and one corresponding in the design. -

File System Layout
File Systems Main Points • File layout • Directory layout • Reliability/durability Named Data in a File System index !le name directory !le number structure storage o"set o"set block Last Time: File System Design Constraints • For small files: – Small blocks for storage efficiency – Files used together should be stored together • For large files: – ConCguous allocaon for sequenCal access – Efficient lookup for random access • May not know at file creaon – Whether file will become small or large File System Design Opons FAT FFS NTFS Index Linked list Tree Tree structure (fixed, asym) (dynamic) granularity block block extent free space FAT array Bitmap Bitmap allocaon (fixed (file) locaon) Locality defragmentaon Block groups Extents + reserve Best fit space defrag MicrosoS File Allocaon Table (FAT) • Linked list index structure – Simple, easy to implement – SCll widely used (e.g., thumb drives) • File table: – Linear map of all blocks on disk – Each file a linked list of blocks FAT MFT Data Blocks 0 1 2 3 !le 9 block 3 4 5 6 7 8 9 !le 9 block 0 10 !le 9 block 1 11 !le 9 block 2 12 !le 12 block 0 13 14 15 16 !le 12 block 1 17 18 !le 9 block 4 19 20 FAT • Pros: – Easy to find free block – Easy to append to a file – Easy to delete a file • Cons: – Small file access is slow – Random access is very slow – Fragmentaon • File blocks for a given file may be scaered • Files in the same directory may be scaered • Problem becomes worse as disk fills Berkeley UNIX FFS (Fast File System) • inode table – Analogous to FAT table • inode – Metadata • File owner, access permissions, -

ZFS On-Disk Specification Draft
ZFS On-Disk Specification Draft Sun Microsystems, Inc. 4150 Network Circle Santa Clara, CA 95054 U.S.A 1 ©2006 Sun Microsystems, Inc. 4150 Network Circle Santa Clara, CA 95054 U.S.A. This product or document is protected by copyright and distributed under licenses restricting its use, copying, distribution, and decompilation. No part of this product or document may be reproduced in any form by any means without prior written authorization of Sun and its licensors, if any. Third-party software, including font technology, is copyrighted and licensed from Sun suppliers. Parts of the product may be derived from Berkeley BSD systems, licensed from the University of California. Sun, Sun Microsystems, the Sun logo, Java, JavaServer Pages, Solaris, and StorEdge are trademarks or registered trademarks of Sun Microsystems, Inc. in the U.S. and other countries. U.S. Government Rights Commercial software. Government users are subject to the Sun Microsystems, Inc. standard license agreement and applicable provisions of the FAR and its supplements. DOCUMENTATION IS PROVIDED AS IS AND ALL EXPRESS OR IMPLIED CONDITIONS, REPRESENTATIONS AND WARRANTIES, INCLUDING ANY IMPLIED WARRANTY OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE OR NON-INFRINGEMENT, ARE DISCLAIMED, EXCEPT TO THE EXTENT THAT SUCH DISCLAIMERS ARE HELD TO BE LEGALLY INVALID. Unless otherwise licensed, use of this software is authorized pursuant to the terms of the license found at: http://developers.sun.com/berkeley_license.html Ce produit ou document est protégé par un copyright et distribué avec des licences qui en restreignent l'utilisation, la copie, la distribution, et la décompilation. Aucune partie de ce produit ou document ne peut être reproduite sous aucune forme, par quelque moyen que ce soit, sans l'autorisation préalable et écrite de Sun et de ses bailleurs de licence, s'il y en a. -
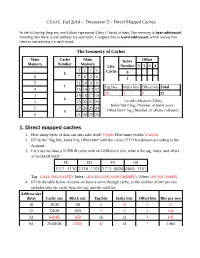
1. Direct Mapped Caches 1
CS 61C SpringFall 2014 2014 – Discussion 5 – Direct Mapped Caches In the following diagram, each block represents 8 bits (1 byte) of data. Our memory is byte-addressed, meaning that there is one address for each byte. Compare this to word-addressed, which means that there is one address for each word. The Geometry of Caches Main Cache Main Index Offset Memory Number Memory CPU Number 3 2 1 0 ... 3 2 1 0 Cache 0 0 6 7 6 5 4 1 5 11 10 9 8 1 Tag bits Index bits Offset bits Total 4 15 14 13 12 29 1 2 32 3 19 18 17 16 2 2 23 22 21 20 1word=4 bytes=32bits Index bits=log (Number of index rows) 1 27 26 25 24 2 3 Offset bits=log2(Number of offsets columns) 0 31 30 29 28 1. Direct mapped caches 1. How many bytes of data can our cache hold? 8 bytes How many words? 2 words 2. Fill in the “Tag bits, Index bits, Offset bits” with the correct T:I:O breakdown according to the diagram. 3. Let’s say we have a 8192KiB cache with an 128B block siZe, what is the tag, index, and offset of 0xFEEDF00D? FE ED F0 0D 1111 1110 1110 1101 1111 0000 0000 1101 Tag: 1 1111 1101 (0x1FD) Index: 1101 1011 1110 0000 (0xDBE0) Offset: 000 1101 (0x0D) 4. Fill in the table below. Assume we have a write-through cache, so the number of bits per row includes only the cache data, the tag, and the valid bit. -

VLSI Memory Lecture-Nahas-181025.Pdf
Introduction to CMOS VLSI Design Semiconductor Memory Harris and Weste, Chapter 12 25 October 2018 J. J. Nahas and P. M. Kogge Modified from slides by Jay Brockman 2008 [Including slides from Harris & Weste, Ed 4, Adapted from Mary Jane Irwin and Vijay Narananan, CSE Penn State adaptation of Rabaey’s Digital Integrated Circuits, ©2002, J. Rabaey et al.] Semiconductor Memory Slide 1 Outline Memory features and comparisons Generic Memory Architecture – Architecture Overview – Row and Column Decoders – Redundancy and Error Correction Static Random Access Memory (SRAM) Dynamic Random Access Memory (DRAM) Flash (EEPROM) Memory Other Memory Types Semiconductor MemoryCMOS VLSI Design Slide 2 1 Memory Features and Comparisons Semiconductor MemoryCMOS VLSI Design Slide 3 Memory Characteristics Read/Write Attributes – Read-Only Memory (ROM): Programmed at manufacture • Being phased out of use in favor of Flash – Read-Write Memory: Can change value dynamically • SRAM, DRAM – Read-Mostly: Can write, but much more slowly than read • EEPROM (Electrically Eraseable, Programable Read Only Memory) (pronounced “Double E Prom”) • Flash (A form of EEPROM) Volatility: sensitivity to losing power – Volatile: loses contents when power turned off – Non-volatile: does not lose contents Semiconductor MemoryCMOS VLSI Design Slide 4 2 Memory Characteristics Addressability – Random-Access: provide address to access a “word” of data • No correlation between successive addresses – Block oriented: read and write large blocks of data at a time – Content-addressable: -

Project 5: Geekos File System 2
Project 5: GeekOS File System 2 1 Overview The purpose of this project is to add a writable filesystem, GFS2, to GeekOS. Unlike the existing PFAT, GFS2 includes directories, inodes, direntries, etc. The new filesystem will reside on the second IDE disk drive in the emulator. The PFAT drive will continue to hold user programs while you format and test your implementation of GFS2. 1.1 VFS Introduction Since GeekOS will have two types of filesystems (PFAT and GFS2), it will have a virtual filesystem layer (VFS) to direct requests to an appropriate filesystem (see figure below). We have provided an implementation of the VFS layer in the file vfs.c. The VFS layer will call the appropriate GFS2 routines when a file operation refers to a file in GFS2. The implementation of PFAT is in pfat.c. You will implement GFS2 in gfs2.c and relevant system calls in syscall.c. VFS picks the functions to call based on supplied structures containing function pointers, one for each operation. For example, see Init PFAT in pfat.c: this initializes the PFAT filesystem with VFS by passing it a pointer to s pfatFilesystemOps, a structure that contains function pointers to PFAT routines for mounting (and formatting) a filesystem. Other PFAT functions are stored in different structures (e.g., look at the PFAT Open routine, which passes the gs pfatFileOps structure to VFS). You will analogously use s gfs2FilesystemOps, s gfs2MountPointOps, s gfs2DirOps, and s gfs2FileOps in gfs2.c. You should also add a call to Init GFS2 provided in gfs2.c to main.c to 1 register the GFS2 filesystem. -

Semiconductor Memories
SEMICONDUCTOR MEMORIES Digital Integrated Circuits Memory © Prentice Hall 1995 Chapter Overview • Memory Classification • Memory Architectures • The Memory Core • Periphery • Reliability Digital Integrated Circuits Memory © Prentice Hall 1995 Semiconductor Memory Classification RWM NVRWM ROM Random Non-Random EPROM Mask-Programmed Access Access 2 E PROM Programmable (PROM) SRAM FIFO FLASH DRAM LIFO Shift Register CAM Digital Integrated Circuits Memory © Prentice Hall 1995 Memory Architecture: Decoders M bits M bits S S0 0 Word 0 Word 0 S1 Word 1 A0 Word 1 S2 Storage Storage s Word 2 Word 2 d Cell A1 Cell r r o e d W o c N AK-1 e S D N-2 Word N-2 Word N-2 SN_1 Word N-1 Word N-1 Input-Output Input-Output (M bits) (M bits) N words => N select signals Decoder reduces # of select signals Too many select signals K = log2N Digital Integrated Circuits Memory © Prentice Hall 1995 Array-Structured Memory Architecture Problem: ASPECT RATIO or HEIGHT >> WIDTH 2L-K Bit Line Storage Cell AK r e d Word Line AK+1 o c e D AL-1 w o R M.2K Sense Amplifiers / Drivers Amplify swing to rail-to-rail amplitude A 0 Column Decoder Selects appropriate AK-1 word Input-Output (M bits) Digital Integrated Circuits Memory © Prentice Hall 1995 Hierarchical Memory Architecture Row Address Column Address Block Address Global Data Bus Control Block Selector Global Circuitry Amplifier/Driver I/O Advantages: 1. Shorter wires within blocks 2. Block address activates only 1 block => power savings Digital Integrated Circuits Memory © Prentice Hall 1995 Memory Timing: Definitions -

CS/COE1541: Introduction to Computer Architecture Dept
CS/COE1541: Introduction to Computer Architecture Dept. of Computer Science University of Pittsburgh http://www.cs.pitt.edu/~melhem/courses/1541p/index.html Chapter 5: Exploiting the Memory Hierarchy Lecture 2 Lecturer: Rami Melhem 1 The Basics of Caches • Until specified otherwise, it will be assumed that a block is one word of data • Three issues: – How do we know if a data item is in the cache? – If it is, how do we find it? address – If it is not, what do we do? Main CPU Cache memory • It boils down to – where do we put an item in the cache? – how do we identify the items in the cache? data • Two solutions – put item anywhere in cache (associative cache) – associate specific locations to specific items (direct mapped cache) Note: we will assume that memory requests are for words (4 Bytes) although an instruction can address a byte 2 Fully associative cache 00000 00001 To cache a data word, d, whose memory address is L: 00010 00011 •Put d in any location in the cache 00100 00101 • Tag the data with the memory address L. 00110 00111 01000 Cache index 01001 01010 01011 000 01001000 01100 Example: 001 001 01101 010 010 01110 • An 8-word cache 011 011 01111 (indexed by 000, … , 111) 100 11000100 10000 101 101 10001 • A 32-words memory 110 01110110 10010 111 111 10011 (addresses 00000, … , 11111) Tags Data 10100 10101 Cache 10110 10111 11000 Advantage: can fully utilize the cache capacity 11001 11010 Disadvantage: need to search all tags to find data 11011 11100 Memory word addresses 11101 11110 (without the 2-bits byte offset) 11111 Memory 3 Direct Mapped Cache (direct hashing) 00000 Assume that the size of the cache is N words.