Syllable Fusion in Hong Kong Cantonese Connected Speech
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Advantages and Disadvantages of Different Social Welfare Strategies
Throughout the world, societies are reexamining, reforming, and restructuring their social welfare systems. New ways are being sought to manage and finance these systems, and new approaches are being developed that alter the relative roles of government, private business, and individ- uals. Not surprisingly, this activity has triggered spirited debate about the relative merits of the various ways of structuring social welfare systems in general and social security programs in particular. The current changes respond to a vari- ety of forces. First, many societies are ad- justing their institutions to reflect changes in social philosophies about the relative responsibilities of government and the individual. These philosophical changes are especially dramatic in China, the former socialist countries of Eastern Europe, and the former Soviet Union; but The Advantages and Disadvantages they are also occurring in what has tradi- of Different Social Welfare Strategies tionally been thought of as the capitalist West. Second, some societies are strug- by Lawrence H. Thompson* gling to adjust to the rising costs associated with aging populations, a problem particu- The following was delivered by the author to the High Level American larly acute in the OECD countries of Asia, Meeting of Experts on The Challenges of Social Reform and New Adminis- Europe, and North America. Third, some trative and Financial Management Techniques. The meeting, which took countries are adjusting their social institu- tions to reflect new development strate- place September 5-7, 1994, in Mar de1 Plata, Argentina, was sponsored gies, a change particularly important in by the International Social Security Association at the invitation of the those countries in the Americas that seek Argentine Secretariat for Social Security in collaboration with the ISSA economic growth through greater eco- Member Organizations of that country. -

CONNECTED SPEECH IPA Symbols Represent the Correct Pronunciation
CONNECTED SPEECH IPA symbols represent the correct pronunciation of single words or segments of speech. However, we use single words or segments in isolation only occasionally. E.g., we can say “ah!” /ɑː/ to express surprise, or “sh!” /ʃ/ if we want to tell somebody to be quiet. Most commonly we use segments of speech or single words in a sequence, to form phrases or sentences. The sound “ah!” /ɑː/, for example, is likely to be found in whole sentences, to express: - surprise (“Ah, there you are!”) - pleasure (“Ah, this coffee is good.”) - admiration or sympathy (“Ah well, better luck next time.”) - when you disagree with somebody (“Ah, but that may not be true.”) In fact, we commonly use language in continuous, connected speech. Connected speech means speech produced without pauses. A consequence of connected speech is that single segments of speech are influenced by neighbouring segments (that is to say, speech sounds that come before and after them), and may slightly change their place or manner of articulation, or may sometimes totally disappear. Therefore the pronunciation of an isolated word may be different from the pronunciation of the same word in connected speech. These changes fall into two main types: assimilation and elision. ASSIMILATION In assimilation, one sound becomes phonetically similar to an adjacent sound. For example, the two words this and shop in isolation are pronounced - this /ðɪs/ - shop /ʃɒp/. In rapid speech, when the two words are pronounced together, the sound /s/ in this is influenced by the following initial sound and changes to /ʃ/. What we actually hear is: - this shop /ðɪʃʃɒp/. -

Vowel Quality and Phonological Projection
i Vowel Quality and Phonological Pro jection Marc van Oostendorp PhD Thesis Tilburg University September Acknowledgements The following p eople have help ed me prepare and write this dissertation John Alderete Elena Anagnostop oulou Sjef Barbiers Outi BatEl Dorothee Beermann Clemens Bennink Adams Bo domo Geert Bo oij Hans Bro ekhuis Norb ert Corver Martine Dhondt Ruud and Henny Dhondt Jo e Emonds Dicky Gilb ers Janet Grijzenhout Carlos Gussenhoven Gert jan Hakkenb erg Marco Haverkort Lars Hellan Ben Hermans Bart Holle brandse Hannekevan Ho of Angeliek van Hout Ro eland van Hout Harry van der Hulst Riny Huybregts Rene Kager HansPeter Kolb Emiel Krah mer David Leblanc Winnie Lechner Klarien van der Linde John Mc Carthy Dominique Nouveau Rolf Noyer Jaap and Hannyvan Oosten dorp Paola Monachesi Krisztina Polgardi Alan Prince Curt Rice Henk van Riemsdijk Iggy Ro ca Sam Rosenthall Grazyna Rowicka Lisa Selkirk Chris Sijtsma Craig Thiersch MiekeTrommelen Rub en van der Vijver Janneke Visser Riet Vos Jero en van de Weijer Wim Zonneveld Iwant to thank them all They have made the past four years for what it was the most interesting and happiest p erio d in mylife until now ii Contents Intro duction The Headedness of Syllables The Headedness Hyp othesis HH Theoretical Background Syllable Structure Feature geometry Sp ecication and Undersp ecicati on Skeletal tier Mo del of the grammar Optimality Theory Data Organisation of the thesis Chapter Chapter -
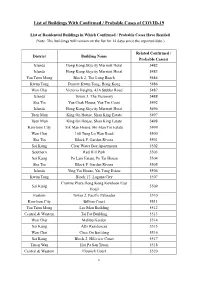
List of Buildings with Confirmed / Probable Cases of COVID-19
List of Buildings With Confirmed / Probable Cases of COVID-19 List of Residential Buildings in Which Confirmed / Probable Cases Have Resided (Note: The buildings will remain on the list for 14 days since the reported date.) Related Confirmed / District Building Name Probable Case(s) Islands Hong Kong Skycity Marriott Hotel 5482 Islands Hong Kong Skycity Marriott Hotel 5483 Yau Tsim Mong Block 2, The Long Beach 5484 Kwun Tong Dorsett Kwun Tong, Hong Kong 5486 Wan Chai Victoria Heights, 43A Stubbs Road 5487 Islands Tower 3, The Visionary 5488 Sha Tin Yue Chak House, Yue Tin Court 5492 Islands Hong Kong Skycity Marriott Hotel 5496 Tuen Mun King On House, Shan King Estate 5497 Tuen Mun King On House, Shan King Estate 5498 Kowloon City Sik Man House, Ho Man Tin Estate 5499 Wan Chai 168 Tung Lo Wan Road 5500 Sha Tin Block F, Garden Rivera 5501 Sai Kung Clear Water Bay Apartments 5502 Southern Red Hill Park 5503 Sai Kung Po Lam Estate, Po Tai House 5504 Sha Tin Block F, Garden Rivera 5505 Islands Ying Yat House, Yat Tung Estate 5506 Kwun Tong Block 17, Laguna City 5507 Crowne Plaza Hong Kong Kowloon East Sai Kung 5509 Hotel Eastern Tower 2, Pacific Palisades 5510 Kowloon City Billion Court 5511 Yau Tsim Mong Lee Man Building 5512 Central & Western Tai Fat Building 5513 Wan Chai Malibu Garden 5514 Sai Kung Alto Residences 5515 Wan Chai Chee On Building 5516 Sai Kung Block 2, Hillview Court 5517 Tsuen Wan Hoi Pa San Tsuen 5518 Central & Western Flourish Court 5520 1 Related Confirmed / District Building Name Probable Case(s) Wong Tai Sin Fu Tung House, Tung Tau Estate 5521 Yau Tsim Mong Tai Chuen Building, Cosmopolitan Estates 5523 Yau Tsim Mong Yan Hong Building 5524 Sha Tin Block 5, Royal Ascot 5525 Sha Tin Yiu Ping House, Yiu On Estate 5526 Sha Tin Block 5, Royal Ascot 5529 Wan Chai Block E, Beverly Hill 5530 Yau Tsim Mong Tower 1, The Harbourside 5531 Yuen Long Wah Choi House, Tin Wah Estate 5532 Yau Tsim Mong Lee Man Building 5533 Yau Tsim Mong Paradise Square 5534 Kowloon City Tower 3, K. -

The Status of Cantonese in the Education Policy of Hong Kong Kwai Sang Lee and Wai Mun Leung*
Lee and Leung Multilingual Education 2012, 2:2 http://www.multilingual-education.com/2/1/2 RESEARCH Open Access The status of Cantonese in the education policy of Hong Kong Kwai Sang Lee and Wai Mun Leung* * Correspondence: waimun@ied. Abstract edu.hk Department of Chinese, The Hong After the handover of Hong Kong to China, a first-ever policy of “bi-literacy and Kong Institute of Education, Hong tri-lingualism” was put forward by the Special Administrative Region Government. Kong Under the trilingual policy, Cantonese, the most dominant local language, equally shares the official status with Putonghua and English only in name but not in spirit, as neither the promotion nor the funding approaches on Cantonese match its legal status. This paper reviews the status of Cantonese in Hong Kong under this policy with respect to the levels of government, education and curriculum, considers the consequences of neglecting Cantonese in the school curriculum, and discusses the importance of large-scale surveys for language policymaking. Keywords: the status of Cantonese, “bi-literacy and tri-lingualism” policy, language survey, Cantonese language education Background The adjustment of the language policy is a common phenomenon in post-colonial societies. It always results in raising the status of the regional vernacular, but the lan- guage of the ex-colonist still maintains a very strong influence on certain domains. Taking Singapore as an example, English became the dominant language in the work- place and families, and the local dialects were suppressed. It led to the degrading of both English and Chinese proficiency levels according to scholars’ evaluation (Goh 2009a, b). -

The Phonetics-Phonology Interface in Romance Languages José Ignacio Hualde, Ioana Chitoran
Surface sound and underlying structure : The phonetics-phonology interface in Romance languages José Ignacio Hualde, Ioana Chitoran To cite this version: José Ignacio Hualde, Ioana Chitoran. Surface sound and underlying structure : The phonetics- phonology interface in Romance languages. S. Fischer and C. Gabriel. Manual of grammatical interfaces in Romance, 10, Mouton de Gruyter, pp.23-40, 2016, Manuals of Romance Linguistics, 978-3-11-031186-0. hal-01226122 HAL Id: hal-01226122 https://hal-univ-paris.archives-ouvertes.fr/hal-01226122 Submitted on 24 Dec 2016 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Manual of Grammatical Interfaces in Romance MRL 10 Brought to you by | Université de Paris Mathematiques-Recherche Authenticated | [email protected] Download Date | 11/1/16 3:56 PM Manuals of Romance Linguistics Manuels de linguistique romane Manuali di linguistica romanza Manuales de lingüística románica Edited by Günter Holtus and Fernando Sánchez Miret Volume 10 Brought to you by | Université de Paris Mathematiques-Recherche Authenticated | [email protected] Download Date | 11/1/16 3:56 PM Manual of Grammatical Interfaces in Romance Edited by Susann Fischer and Christoph Gabriel Brought to you by | Université de Paris Mathematiques-Recherche Authenticated | [email protected] Download Date | 11/1/16 3:56 PM ISBN 978-3-11-031178-5 e-ISBN (PDF) 978-3-11-031186-0 e-ISBN (EPUB) 978-3-11-039483-2 Library of Congress Cataloging-in-Publication Data A CIP catalog record for this book has been applied for at the Library of Congress. -

French Names Noeline Bridge
names collated:Chinese personal names and 100 surnames.qxd 29/09/2006 13:00 Page 8 The hundred surnames Pinyin Hanzi (simplified) Wade Giles Other forms Well-known names Pinyin Hanzi (simplified) Wade Giles Other forms Well-known names Zang Tsang Zang Lin Zhu Chu Gee Zhu Yuanzhang, Zhu Xi Zeng Tseng Tsang, Zeng Cai, Zeng Gong Zhu Chu Zhu Danian Dong, Zhu Chu Zhu Zhishan, Zhu Weihao Jeng Zhu Chu Zhu jin, Zhu Sheng Zha Cha Zha Yihuang, Zhuang Chuang Zhuang Zhou, Zhuang Zi Zha Shenxing Zhuansun Chuansun Zhuansun Shi Zhai Chai Zhai Jin, Zhai Shan Zhuge Chuko Zhuge Liang, Zhan Chan Zhan Ruoshui Zhuge Kongming Zhan Chan Chaim Zhan Xiyuan Zhuo Cho Zhuo Mao Zhang Chang Zhang Yuxi Zi Tzu Zi Rudao Zhang Chang Cheung, Zhang Heng, Ziche Tzuch’e Ziche Zhongxing Chiang Zhang Chunqiao Zong Tsung Tsung, Zong Xihua, Zhang Chang Zhang Shengyi, Dung Zong Yuanding Zhang Xuecheng Zongzheng Tsungcheng Zongzheng Zhensun Zhangsun Changsun Zhangsun Wuji Zou Tsou Zou Yang, Zou Liang, Zhao Chao Chew, Zhao Kuangyin, Zou Yan Chieu, Zhao Mingcheng Zu Tsu Zu Chongzhi Chiu Zuo Tso Zuo Si Zhen Chen Zhen Hui, Zhen Yong Zuoqiu Tsoch’iu Zuoqiu Ming Zheng Cheng Cheng, Zheng Qiao, Zheng He, Chung Zheng Banqiao The hundred surnames is one of the most popular reference Zhi Chih Zhi Dake, Zhi Shucai sources for the Han surnames. It was originally compiled by an Zhong Chung Zhong Heqing unknown author in the 10th century and later recompiled many Zhong Chung Zhong Shensi times. The current widely used version includes 503 surnames. Zhong Chung Zhong Sicheng, Zhong Xing The Pinyin index of the 503 Chinese surnames provides an access Zhongli Chungli Zhongli Zi to this great work for Western people. -

Formal Grammar, Usage Probabilities, and English Tensed Auxiliary Contraction (Revised June 15, 2020)
Formal grammar, usage probabilities, and English tensed auxiliary contraction (revised June 15, 2020) Joan Bresnan 1 At first sight, formal theories of grammar and usage-based linguistics ap- pear completely opposed in their fundamental assumptions. As Diessel (2007) describes it, formal theories adhere to a rigid division between grammar and language use: grammatical structures are independent of their use, grammar is a closed and stable system, and is not affected by pragmatic and psycholinguis- tic principles involved in language use. Usage-based theories, in contrast, view grammatical structures as emerging from language use and constantly changing through psychological processing. Yet there are hybrid models of the mental lexicon that combine formal representational and usage-based features, thereby accounting for properties unexplained by either component of the model alone (e.g. Pierrehumbert 2001, 2002, 2006) at the level of word phonetics. Such hybrid models may associate a set of ‘labels’ (for example levels of representation from formal grammar) with memory traces of language use, providing detailed probability distributions learned from experience and constantly updated through life. The present study presents evidence for a hybrid model at the syntactic level for English tensed auxiliary contractions, using lfg with lexical sharing (Wescoat 2002, 2005) as the representational basis for the syntax and a dynamic exemplar model of the mental lexicon similar to the hybrid model proposals at the phonetic word level. However, the aim of this study is not to present a formalization of a particular hybrid model or to argue for a specific formal grammar. The aim is to show the empirical and theoretical value of combining formal and usage-based data and methods into a shared framework—a theory of lexical syntax and a dynamic usage-based lexicon that includes multi-word sequences. -

The Globalization of Chinese Food ANTHROPOLOGY of ASIA SERIES Series Editor: Grant Evans, University Ofhong Kong
The Globalization of Chinese Food ANTHROPOLOGY OF ASIA SERIES Series Editor: Grant Evans, University ofHong Kong Asia today is one ofthe most dynamic regions ofthe world. The previously predominant image of 'timeless peasants' has given way to the image of fast-paced business people, mass consumerism and high-rise urban conglomerations. Yet much discourse remains entrenched in the polarities of 'East vs. West', 'Tradition vs. Change'. This series hopes to provide a forum for anthropological studies which break with such polarities. It will publish titles dealing with cosmopolitanism, cultural identity, representa tions, arts and performance. The complexities of urban Asia, its elites, its political rituals, and its families will also be explored. Dangerous Blood, Refined Souls Death Rituals among the Chinese in Singapore Tong Chee Kiong Folk Art Potters ofJapan Beyond an Anthropology of Aesthetics Brian Moeran Hong Kong The Anthropology of a Chinese Metropolis Edited by Grant Evans and Maria Tam Anthropology and Colonialism in Asia and Oceania Jan van Bremen and Akitoshi Shimizu Japanese Bosses, Chinese Workers Power and Control in a Hong Kong Megastore WOng Heung wah The Legend ofthe Golden Boat Regulation, Trade and Traders in the Borderlands of Laos, Thailand, China and Burma Andrew walker Cultural Crisis and Social Memory Politics of the Past in the Thai World Edited by Shigeharu Tanabe and Charles R Keyes The Globalization of Chinese Food Edited by David Y. H. Wu and Sidney C. H. Cheung The Globalization of Chinese Food Edited by David Y. H. Wu and Sidney C. H. Cheung UNIVERSITY OF HAWAI'I PRESS HONOLULU Editorial Matter © 2002 David Y. -

Using a Radical-Derived Character E-Learning Platform to Increase Learner Knowledge of Chinese Characters
Language Learning & Technology February 2013, Volume 17, Number 1 http://llt.msu.edu/issues/february2013/chenetal.pdf pp. 89–106 USING A RADICAL-DERIVED CHARACTER E-LEARNING PLATFORM TO INCREASE LEARNER KNOWLEDGE OF CHINESE CHARACTERS Hsueh-Chih Chen, National Taiwan Normal University Chih-Chun Hsu, National Defense University Li-Yun Chang, University of Pittsburgh Yu-Chi Lin, National Taiwan Normal University Kuo-En Chang, National Taiwan Normal University Yao-Ting Sung, National Taiwan Normal University The present study is aimed at investigating the effect of a radical-derived Chinese character teaching strategy on enhancing Chinese as a Foreign Language (CFL) learners’ Chinese orthographic awareness. An e-learning teaching platform, based on statistical data from the Chinese Orthography Database Explorer (Chen, Chang, L.Y., Chou, Sung, & Chang, K.E., 2011), was established and used as an auxiliary teaching tool. A nonequivalent pretest-posttest quasi-experiment was conducted, with 129 Chinese- American CFL learners as participants (69 people in the experimental group and 60 people in the comparison group), to examine the effectiveness of the e-learning platform. After a three-week course—involving instruction on Chinese orthographic knowledge and at least seven phonetic/semantic radicals and their derivative characters per week—the experimental group performed significantly better than the comparison group on a phonetic radical awareness test, a semantic radical awareness test, as well as an orthography knowledge test. Keywords: Chinese as a Foreign Language (CFL), Chinese Orthographic Awareness, Radical-Derived Character Instructional Method, Phonetic/Semantic Radicals INTRODUCTION The rise of China to international prominence in recent years has made learning Chinese extremely popular, and increasing numbers of non-native Chinese students have begun to choose Chinese as their second language of study. -

The Reconstruction of Proto-Yue Vowels
W O R K I N G P A P E R S I N L I N G U I S T I C S The notes and articles in this series are progress reports on work being carried on by students and faculty in the Department. Because these papers are not finished products, readers are asked not to cite from them without noting their preliminary nature. The authors welcome any comments and suggestions that readers might offer. Volume 40(2) 2009 (March) DEPARTMENT OF LINGUISTICS UNIVERSITY OF HAWAI‘I AT MĀNOA HONOLULU 96822 An Equal Opportunity/Affirmative Action Institution WORKING PAPERS IN LINGUISTICS: UNIVERSITY OF HAWAI‘I AT MĀNOA, VOL. 40(2) DEPARTMENT OF LINGUISTICS FACULTY 2009 Victoria B. Anderson Byron W. Bender (Emeritus) Benjamin Bergen Derek Bickerton (Emeritus) Robert A. Blust Robert L. Cheng (Adjunct) Kenneth W. Cook (Adjunct) Kamil Ud Deen Patricia J. Donegan (Co-Graduate Chair) Emanuel J. Drechsel (Adjunct) Michael L. Forman (Emeritus) George W. Grace (Emeritus) John H. Haig (Adjunct) Roderick A. Jacobs (Emeritus) Paul Lassettre P. Gregory Lee Patricia A. Lee Howard P. McKaughan (Emeritus) William O’Grady (Chair) Yuko Otsuka Ann Marie Peters (Emeritus, Co-Graduate Chair) Kenneth L. Rehg Lawrence A. Reid (Emeritus) Amy J. Schafer Albert J. Schütz, (Emeritus, Editor) Ho Min Sohn (Adjunct) Nicholas Thieberger Laurence C. Thompson (Emeritus) ii A RECONSTRUCTION OF PROTO-YUE VOWELS KAREN HUANG This paper presents an alternative reconstruction of Proto-Yue vowels in the literary stratum. Opposed to previous studies, the rhyme categories are not considered. I analyze the literary stratum of eighteen Yue dialects and reconstruct the vowel system based on the comparative method. -

Language Specific Peculiarities Document for Cantonese As
Language Specific Peculiarities Document for Cantonese as Spoken in the Guangdong and Guangxi Provinces of China 1. Dialects The name "Cantonese" is used either for all of the language varieties spoken in specific regions in the Guangdong and Guangxi Provinces of China and Hong Kong (i.e., the Yue dialects of Chinese), or as one particular variety referred to as the "Guangfu group" (Bauer & Benedict 1997). In instances where Cantonese is described as 'Cantonese "proper"' (i.e. used in the narrower sense), it refers to a variety of Cantonese that is spoken in the capital cities Guangzhou and Nanning, as well as in Hong Kong and Macau. This database includes Cantonese as spoken in the Guangdong and Guangxi Provinces of China only (i.e. not in Hong Kong); five dialect groups have been defined for Cantonese (see the following table)1. Three general principles have been used in defining these dialect groupings: (i) phonological variation, (ii) geographical variation, and (iii) lexical variation. With relation to phonological variation, although Cantonese is spoken in all of the regions listed in the table, there are differences in pronunciation. Differences in geographic locations also correlate with variations in lexical choice. Cultural differences are also correlated with linguistic differences, particularly in lexical choices. Area Cities (examples) Central Guangzhou, Conghua, Fogang (Shijiao), Guangdong Longmen, Zengcheng, Huaxian Group Northern Shaoguan, Qijiang, Lian Xian, Liannan, Guangdong Yangshan, Yingde, Taiping Group Northern