Bangor University DOCTOR of PHILOSOPHY a Novel Mirna Cluster Within the Circadian Clock Gene NPAS2 and the Implications of Rs181
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Htra1 Is a Novel Transcriptional Target of RUNX2 That Promotes Osteogenic Differentiation
Cellular Physiology Cell Physiol Biochem 2019;53:832-850 DOI: 10.33594/00000017610.33594/000000176 © 2019 The Author(s).© 2019 Published The Author(s) by and Biochemistry Published online: online: 9 9November November 2019 2019 Cell Physiol BiochemPublished Press GmbH&Co. by Cell Physiol KG Biochem 832 Press GmbH&Co. KG, Duesseldorf IyyanarAccepted: et 7al.: November Runx2 Regulates 2019 Htra1 During Osteogenesiswww.cellphysiolbiochem.com This article is licensed under the Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 Interna- tional License (CC BY-NC-ND). Usage and distribution for commercial purposes as well as any distribution of modified material requires written permission. Original Paper Htra1 is a Novel Transcriptional Target of RUNX2 That Promotes Osteogenic Differentiation Paul P.R. Iyyanara,b Merlin P. Thangaraja B. Frank Eamesc Adil J. Nazaralia aLaboratory of Molecular Cell Biology, College of Pharmacy and Nutrition and Neuroscience Research Cluster, University of Saskatchewan, Saskatoon, SK, Canada, bDivision of Developmental Biology, Cincinnati Children’s Hospital Medical Center, Cincinnati, OH, USA, cDepartment of Anatomy and Cell Biology, University of Saskatchewan, Saskatoon, SK, Canada Key Words Runx2 • Htra1 • Osteoblast differentiation • Matrix mineralization Abstract Background/Aims: Runt-related transcription factor 2 (Runx2) is a master regulator of osteogenic differentiation, but most of the direct downstream targets of RUNX2 during osteogenesis are unknown. Likewise, High-temperature requirement factor A1 (HTRA1) is a serine protease expressed in bone, yet the role of Htra1 during osteoblast differentiation remains elusive. We investigated the role of Htra1 in osteogenic differentiation and the transcriptional regulation of Htra1 by RUNX2 in primary mouse mesenchymal progenitor cells. Methods: Overexpression of Htra1 was carried out in primary mouse mesenchymal progenitor cells to evaluate the extent of osteoblast differentiation. -

Noelia Díaz Blanco
Effects of environmental factors on the gonadal transcriptome of European sea bass (Dicentrarchus labrax), juvenile growth and sex ratios Noelia Díaz Blanco Ph.D. thesis 2014 Submitted in partial fulfillment of the requirements for the Ph.D. degree from the Universitat Pompeu Fabra (UPF). This work has been carried out at the Group of Biology of Reproduction (GBR), at the Department of Renewable Marine Resources of the Institute of Marine Sciences (ICM-CSIC). Thesis supervisor: Dr. Francesc Piferrer Professor d’Investigació Institut de Ciències del Mar (ICM-CSIC) i ii A mis padres A Xavi iii iv Acknowledgements This thesis has been made possible by the support of many people who in one way or another, many times unknowingly, gave me the strength to overcome this "long and winding road". First of all, I would like to thank my supervisor, Dr. Francesc Piferrer, for his patience, guidance and wise advice throughout all this Ph.D. experience. But above all, for the trust he placed on me almost seven years ago when he offered me the opportunity to be part of his team. Thanks also for teaching me how to question always everything, for sharing with me your enthusiasm for science and for giving me the opportunity of learning from you by participating in many projects, collaborations and scientific meetings. I am also thankful to my colleagues (former and present Group of Biology of Reproduction members) for your support and encouragement throughout this journey. To the “exGBRs”, thanks for helping me with my first steps into this world. Working as an undergrad with you Dr. -

SUPPLEMENTARY MATERIAL Bone Morphogenetic Protein 4 Promotes
www.intjdevbiol.com doi: 10.1387/ijdb.160040mk SUPPLEMENTARY MATERIAL corresponding to: Bone morphogenetic protein 4 promotes craniofacial neural crest induction from human pluripotent stem cells SUMIYO MIMURA, MIKA SUGA, KAORI OKADA, MASAKI KINEHARA, HIROKI NIKAWA and MIHO K. FURUE* *Address correspondence to: Miho Kusuda Furue. Laboratory of Stem Cell Cultures, National Institutes of Biomedical Innovation, Health and Nutrition, 7-6-8, Saito-Asagi, Ibaraki, Osaka 567-0085, Japan. Tel: 81-72-641-9819. Fax: 81-72-641-9812. E-mail: [email protected] Full text for this paper is available at: http://dx.doi.org/10.1387/ijdb.160040mk TABLE S1 PRIMER LIST FOR QRT-PCR Gene forward reverse AP2α AATTTCTCAACCGACAACATT ATCTGTTTTGTAGCCAGGAGC CDX2 CTGGAGCTGGAGAAGGAGTTTC ATTTTAACCTGCCTCTCAGAGAGC DLX1 AGTTTGCAGTTGCAGGCTTT CCCTGCTTCATCAGCTTCTT FOXD3 CAGCGGTTCGGCGGGAGG TGAGTGAGAGGTTGTGGCGGATG GAPDH CAAAGTTGTCATGGATGACC CCATGGAGAAGGCTGGGG MSX1 GGATCAGACTTCGGAGAGTGAACT GCCTTCCCTTTAACCCTCACA NANOG TGAACCTCAGCTACAAACAG TGGTGGTAGGAAGAGTAAAG OCT4 GACAGGGGGAGGGGAGGAGCTAGG CTTCCCTCCAACCAGTTGCCCCAAA PAX3 TTGCAATGGCCTCTCAC AGGGGAGAGCGCGTAATC PAX6 GTCCATCTTTGCTTGGGAAA TAGCCAGGTTGCGAAGAACT p75 TCATCCCTGTCTATTGCTCCA TGTTCTGCTTGCAGCTGTTC SOX9 AATGGAGCAGCGAAATCAAC CAGAGAGATTTAGCACACTGATC SOX10 GACCAGTACCCGCACCTG CGCTTGTCACTTTCGTTCAG Suppl. Fig. S1. Comparison of the gene expression profiles of the ES cells and the cells induced by NC and NC-B condition. Scatter plots compares the normalized expression of every gene on the array (refer to Table S3). The central line -
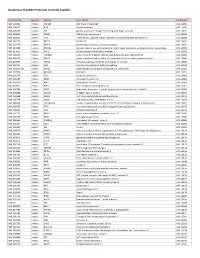
Quantigene Flowrna Probe Sets Currently Available
QuantiGene FlowRNA Probe Sets Currently Available Accession No. Species Symbol Gene Name Catalog No. NM_003452 Human ZNF189 zinc finger protein 189 VA1-10009 NM_000057 Human BLM Bloom syndrome VA1-10010 NM_005269 Human GLI glioma-associated oncogene homolog (zinc finger protein) VA1-10011 NM_002614 Human PDZK1 PDZ domain containing 1 VA1-10015 NM_003225 Human TFF1 Trefoil factor 1 (breast cancer, estrogen-inducible sequence expressed in) VA1-10016 NM_002276 Human KRT19 keratin 19 VA1-10022 NM_002659 Human PLAUR plasminogen activator, urokinase receptor VA1-10025 NM_017669 Human ERCC6L excision repair cross-complementing rodent repair deficiency, complementation group 6-like VA1-10029 NM_017699 Human SIDT1 SID1 transmembrane family, member 1 VA1-10032 NM_000077 Human CDKN2A cyclin-dependent kinase inhibitor 2A (melanoma, p16, inhibits CDK4) VA1-10040 NM_003150 Human STAT3 signal transducer and activator of transcripton 3 (acute-phase response factor) VA1-10046 NM_004707 Human ATG12 ATG12 autophagy related 12 homolog (S. cerevisiae) VA1-10047 NM_000737 Human CGB chorionic gonadotropin, beta polypeptide VA1-10048 NM_001017420 Human ESCO2 establishment of cohesion 1 homolog 2 (S. cerevisiae) VA1-10050 NM_197978 Human HEMGN hemogen VA1-10051 NM_001738 Human CA1 Carbonic anhydrase I VA1-10052 NM_000184 Human HBG2 Hemoglobin, gamma G VA1-10053 NM_005330 Human HBE1 Hemoglobin, epsilon 1 VA1-10054 NR_003367 Human PVT1 Pvt1 oncogene homolog (mouse) VA1-10061 NM_000454 Human SOD1 Superoxide dismutase 1, soluble (amyotrophic lateral sclerosis 1 (adult)) -

Supplementary Table S4. FGA Co-Expressed Gene List in LUAD
Supplementary Table S4. FGA co-expressed gene list in LUAD tumors Symbol R Locus Description FGG 0.919 4q28 fibrinogen gamma chain FGL1 0.635 8p22 fibrinogen-like 1 SLC7A2 0.536 8p22 solute carrier family 7 (cationic amino acid transporter, y+ system), member 2 DUSP4 0.521 8p12-p11 dual specificity phosphatase 4 HAL 0.51 12q22-q24.1histidine ammonia-lyase PDE4D 0.499 5q12 phosphodiesterase 4D, cAMP-specific FURIN 0.497 15q26.1 furin (paired basic amino acid cleaving enzyme) CPS1 0.49 2q35 carbamoyl-phosphate synthase 1, mitochondrial TESC 0.478 12q24.22 tescalcin INHA 0.465 2q35 inhibin, alpha S100P 0.461 4p16 S100 calcium binding protein P VPS37A 0.447 8p22 vacuolar protein sorting 37 homolog A (S. cerevisiae) SLC16A14 0.447 2q36.3 solute carrier family 16, member 14 PPARGC1A 0.443 4p15.1 peroxisome proliferator-activated receptor gamma, coactivator 1 alpha SIK1 0.435 21q22.3 salt-inducible kinase 1 IRS2 0.434 13q34 insulin receptor substrate 2 RND1 0.433 12q12 Rho family GTPase 1 HGD 0.433 3q13.33 homogentisate 1,2-dioxygenase PTP4A1 0.432 6q12 protein tyrosine phosphatase type IVA, member 1 C8orf4 0.428 8p11.2 chromosome 8 open reading frame 4 DDC 0.427 7p12.2 dopa decarboxylase (aromatic L-amino acid decarboxylase) TACC2 0.427 10q26 transforming, acidic coiled-coil containing protein 2 MUC13 0.422 3q21.2 mucin 13, cell surface associated C5 0.412 9q33-q34 complement component 5 NR4A2 0.412 2q22-q23 nuclear receptor subfamily 4, group A, member 2 EYS 0.411 6q12 eyes shut homolog (Drosophila) GPX2 0.406 14q24.1 glutathione peroxidase -

Rabbit Anti-Osterix/FITC Conjugated Antibody-SL1110R-FITC
SunLong Biotech Co.,LTD Tel: 0086-571- 56623320 Fax:0086-571- 56623318 E-mail:[email protected] www.sunlongbiotech.com Rabbit Anti-Osterix/FITC Conjugated antibody SL1110R-FITC Product Name: Anti-Osterix/FITC Chinese Name: FITC标记的成骨相关转录因子抗体 Osterix; MGC126598; Osx; Sp 7; Sp7; Sp7 transcription factor; Transcription factor Alias: Sp7; Zinc finger protein osterix; SP7_HUMAN. Organism Species: Rabbit Clonality: Polyclonal React Species: Human,Mouse,Rat,Dog,Pig,Cow,Horse,Rabbit, Flow-Cyt=1:50-200IF=1:50-200 Applications: not yet tested in other applications. optimal dilutions/concentrations should be determined by the end user. Molecular weight: 45kDa Form: Lyophilized or Liquid Concentration: 1mg/ml immunogen: KLH conjugated synthetic peptide derived from human Osterix Lsotype: IgG Purification: affinity purified by Protein A Storage Buffer: 0.01M TBS(pH7.4) with 1% BSA, 0.03% Proclin300 and 50% Glycerol. Storewww.sunlongbiotech.com at -20 °C for one year. Avoid repeated freeze/thaw cycles. The lyophilized antibody is stable at room temperature for at least one month and for greater than a year Storage: when kept at -20°C. When reconstituted in sterile pH 7.4 0.01M PBS or diluent of antibody the antibody is stable for at least two weeks at 2-4 °C. background: This gene encodes a member of the Sp subfamily of Sp/XKLF transcription factors. Sp family proteins are sequence-specific DNA-binding proteins characterized by an amino- terminal trans-activation domain and three carboxy-terminal zinc finger motifs. This Product Detail: protein is a bone specific transcription factor and is required for osteoblast differentiation and bone formation.[provided by RefSeq, Jul 2010] Function: Transcriptional activator essential for osteoblast differentiation. -

Ingenuity Pathway Analysis of Human Facet Joint Tissues: Insight Into Facet Joint Osteoarthritis
EXPERIMENTAL AND THERAPEUTIC MEDICINE 19: 2997-3008, 2020 Ingenuity pathway analysis of human facet joint tissues: Insight into facet joint osteoarthritis CHU CHEN*, SHENGYU CUI*, WEIDONG LI, HURICHA JIN, JIANBO FAN, YUYU SUN and ZHIMING CUI Department of Spine Surgery, The Second Affiliated Hospital of Nantong University, Nantong, Jiangsu 226001, P.R. China Received August 17, 2019; Accepted January 30, 2020 DOI: 10.3892/etm.2020.8555 Abstract. Facet joint osteoarthritis (FJOA) is a common the top 5 IPA networks (with a score >30). The present study degenerative joint disorder with high prevalence in the elderly. provides insight into the pathological processes of FJOA from FJOA causes lower back pain and lower extremity pain, and a genetic perspective and may thus benefit the clinical treat- thus severely impacts the quality of life of affected patients. ment of FJOA. Emerging studies have focused on the histomorphological and histomorphometric changes in FJOA. However, the dynamic Introduction genetic changes in FJOA have remained to be clearly deter- mined. In the present study, previously obtained RNA deep Facet joint osteoarthritis (FJOA) is a common degenerative sequencing data were subjected to an ingenuity pathway joint disorder that causes the degeneration and breakdown analysis (IPA) and canonical signaling pathways of differ- of cartilage and restricts the movement of joints (1). It has entially expressed genes (DEGs) in FJOA were studied. The been reported that lumbar FJOA occurs at high prevalence top 25 enriched canonical signaling pathways were identified and the presence of FJOA is highly associated with age (2,3). and canonical signaling pathways with high absolute values A community-based cross-sectional study indicated that of z-scores, specifically leukocyte extravasation signaling, in populations aged <50 years, the prevalence of FJOA was Tec kinase signaling and osteoarthritis pathway, were inves- <45%, while it was ~75% in populations aged >50 years (4). -

Microrna Mir-378 Promotes BMP2-Induced Osteogenic
Hupkes et al. BMC Molecular Biology 2014, 15:1 http://www.biomedcentral.com/1471-2199/15/1 RESEARCH ARTICLE Open Access MicroRNA miR-378 promotes BMP2-induced osteogenic differentiation of mesenchymal progenitor cells Marlinda Hupkes1*, Ana M Sotoca1, José M Hendriks1, Everardus J van Zoelen1 and Koen J Dechering1,2,3 Abstract Background: MicroRNAs (miRNAs) are a family of small, non-coding single-stranded RNA molecules involved in post-transcriptional regulation of gene expression. As such, they are believed to play a role in regulating the step-wise changes in gene expression patterns that occur during cell fate specification of multipotent stem cells. Here, we have studied whether terminal differentiation of C2C12 myoblasts is indeed controlled by lineage-specific changes in miRNA expression. Results: Using a previously generated RNA polymerase II (Pol-II) ChIP-on-chip dataset, we show differential Pol-II occupancy at the promoter regions of six miRNAs during C2C12 myogenic versus BMP2-induced osteogenic differentiation. Overexpression of one of these miRNAs, miR-378, enhances Alp activity, calcium deposition and mRNA expression of osteogenic marker genes in the presence of BMP2. Conclusions: Our results demonstrate a previously unknown role for miR-378 in promoting BMP2-induced osteogenic differentiation. Background nucleotides) involved in post-transcriptional gene silencing The generation of distinct populations of terminally dif- and as such play important roles in diverse biological pro- ferentiated, mature specialized cell types from multipo- cesses such as developmental timing [3], insulin secretion tent stem cells, via progenitor cells, is characterized by a [4], apoptosis [5], oncogenesis [6] and organ development progressive restriction of differentiation potential that [7,8]. -

Gene 599 (2017) 36–52
Gene 599 (2017) 36–52 Contents lists available at ScienceDirect Gene journal homepage: www.elsevier.com/locate/gene Research paper Old age and the associated impairment of bones' adaptation to loading are associated with transcriptomic changes in cellular metabolism, cell-matrix interactions and the cell cycle Gabriel L. Galea, PhD a,1, Lee B. Meakin, PhD a,⁎,1, Marie A. Harris, PhD b, Peter J. Delisser, BVSc(Hons) a, Lance E. Lanyon, DSc a, Stephen E. Harris, PhD b, Joanna S. Price, PhD a a School of Veterinary Sciences, University of Bristol, Bristol, UK b Department of Periodontics & Cellular and Structural Biology, University of Texas Health Science Centre, San Antonio, USA article info abstract Article history: In old animals, bone's ability to adapt its mass and architecture to functional load-bearing requirements is dimin- Received 15 October 2016 ished, resulting in bone loss characteristic of osteoporosis. Here we investigate transcriptomic changes associated Accepted 6 November 2016 with this impaired adaptive response. Young adult (19-week-old) and aged (19-month-old) female mice were Available online 10 November 2016 subjected to unilateral axial tibial loading and their cortical shells harvested for microarray analysis between 1 h and 24 h following loading (36 mice per age group, 6 mice per loading group at 6 time points). In non-loaded Keywords: aged bones, down-regulated genes are enriched for MAPK, Wnt and cell cycle components, including E2F1. E2F1 Ageing Bone is the transcription factor most closely associated with genes down-regulated by ageing and is down-regulated at Mechanical loading the protein level in osteocytes. -

Identification of Transcriptional Mechanisms Downstream of Nf1 Gene Defeciency in Malignant Peripheral Nerve Sheath Tumors Daochun Sun Wayne State University
Wayne State University DigitalCommons@WayneState Wayne State University Dissertations 1-1-2012 Identification of transcriptional mechanisms downstream of nf1 gene defeciency in malignant peripheral nerve sheath tumors Daochun Sun Wayne State University, Follow this and additional works at: http://digitalcommons.wayne.edu/oa_dissertations Recommended Citation Sun, Daochun, "Identification of transcriptional mechanisms downstream of nf1 gene defeciency in malignant peripheral nerve sheath tumors" (2012). Wayne State University Dissertations. Paper 558. This Open Access Dissertation is brought to you for free and open access by DigitalCommons@WayneState. It has been accepted for inclusion in Wayne State University Dissertations by an authorized administrator of DigitalCommons@WayneState. IDENTIFICATION OF TRANSCRIPTIONAL MECHANISMS DOWNSTREAM OF NF1 GENE DEFECIENCY IN MALIGNANT PERIPHERAL NERVE SHEATH TUMORS by DAOCHUN SUN DISSERTATION Submitted to the Graduate School of Wayne State University, Detroit, Michigan in partial fulfillment of the requirements for the degree of DOCTOR OF PHILOSOPHY 2012 MAJOR: MOLECULAR BIOLOGY AND GENETICS Approved by: _______________________________________ Advisor Date _______________________________________ _______________________________________ _______________________________________ © COPYRIGHT BY DAOCHUN SUN 2012 All Rights Reserved DEDICATION This work is dedicated to my parents and my wife Ze Zheng for their continuous support and understanding during the years of my education. I could not achieve my goal without them. ii ACKNOWLEDGMENTS I would like to express tremendous appreciation to my mentor, Dr. Michael Tainsky. His guidance and encouragement throughout this project made this dissertation come true. I would also like to thank my committee members, Dr. Raymond Mattingly and Dr. John Reiners Jr. for their sustained attention to this project during the monthly NF1 group meetings and committee meetings, Dr. -

Widespread Establishment and Regulatory Impact of Alu Exons in Human Genes
Widespread establishment and regulatory impact of Alu exons in human genes Shihao Shena,1, Lan Linb,1, James J. Caic, Peng Jiangb, Elizabeth J. Kenkelb, Mallory R. Stroikb, Seiko Satob, Beverly L. Davidsonb,d,e, and Yi Xingb,f,2 Departments of aBiostatistics, bInternal Medicine, dMolecular Physiology and Biophysics, eNeurology, and fBiomedical Engineering, University of Iowa, Iowa City, IA 52242; and cDepartment of Veterinary Integrative Biosciences, Texas A&M University, College Station, TX 77845 Edited* by Wing Hung Wong, Stanford University, Stanford, CA, and approved January 12, 2011 (received for review August 28, 2010) The Alu element has been a major source of new exons during primate ESTs and exon arrays were limited by the incomplete exon cov- evolution. Thousands of human genes contain spliced exons derived erage and low resolution of these technologies. By contrast, deep from Alu elements. However, identifying Alu exons that have ac- RNA-Seq enabled an unbiased analysis of Alu exonization events quired genuine biological functions remains a major challenge. We and allowed us to estimate quantitatively the transcript inclusion investigated the creation and establishment of Alu exons in human levels of Alu exons. Importantly, we found that Alu exons with ′ genes, using transcriptome profiles of human tissues generated by high splicing activities were strongly enriched in the 5 -UTR, and a large fraction of 5′-UTR Alu exons significantly altered mRNA high-throughput RNA sequencing (RNA-Seq) combined with exten- fi sive RT-PCR analysis. More than 25% of Alu exons analyzed by RNA- translational ef ciency. These results suggest an important role for Alu exonization in the evolution of translational regulation in Seq have estimated transcript inclusion levels of at least 50% in the primates and humans. -

Article Association of Systemic Lupus Erythematosus
Article Association of Systemic Lupus Erythematosus Susceptibility Genes with IgA Nephropathy in a Chinese Cohort Xu-Jie Zhou, Fa-Juan Cheng, Li Zhu, Ji-Cheng Lv, Yuan-Yuan Qi, Ping Hou, and Hong Zhang Abstract Background and objectives One hypothesis states that IgA nephropathy (IgAN) is a syndrome with an Renal Division, Peking University First autoimmune component. Recent studies strongly support the notion of shared genetics between immune-related Hospital; Peking diseases. This study investigated single-nucleotide polymorphisms (SNPs) reported to be associated with University Institute of systemic lupus erythematosus (SLE) in a Chinese cohort of patients with IgAN and in controls. Nephrology; Key Laboratory of Renal Disease, Ministry of Design, setting, participants, & measurements This study investigated whether SNP markers that had been Health of China; and reported to be associated with SLE were also associated with IgAN in a Chinese population. The study cohort Key Laboratory of consisted of 1194 patients with IgAN and 902 controls enrolled in Peking University First Hospital from 1997 to Chronic Kidney 2008. Disease Prevention and Treatment (Peking University), Ministry , 3 25 Results Ninety-six SNPs mapping to 60 SLE loci with reported P values 1 10 were investigated. CFH of Education, Beijing, 2 2 2 2 2 (P=8.41310 6), HLA-DRA (P=4.91310 6), HLA-DRB1 (P=9.46310 9), PXK (P=3.62310 4), BLK (P=9.32310 3), People’s Republic of and UBE2L3 (P=4.0731023) were identified as shared genes between IgAN and SLE. All associations reported China herein were corroborated by associations at neighboring SNPs.