I Recommend That You Start with the Exact Same Structure for Running the Models That I Use
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Fundamentals of UNIX Lab 5.4.6 – Listing Directory Information (Estimated Time: 30 Min.)
Fundamentals of UNIX Lab 5.4.6 – Listing Directory Information (Estimated time: 30 min.) Objectives: • Learn to display directory and file information • Use the ls (list files) command with various options • Display hidden files • Display files and file types • Examine and interpret the results of a long file listing • List individual directories • List directories recursively Background: In this lab, the student will use the ls command, which is used to display the contents of a directory. This command will display a listing of all files and directories within the current directory or specified directory or directories. If no pathname is given as an argument, ls will display the contents of the current directory. The ls command will list any subdirectories and files that are in the current working directory if a pathname is specified. The ls command will also default to a wide listing and display only file and directory names. There are many options that can be used with the ls command, which makes this command one of the more flexible and useful UNIX commands. Command Format: ls [-option(s)] [pathname[s]] Tools / Preparation: a) Before starting this lab, the student should review Chapter 5, Section 4 – Listing Directory Contents b) The student will need the following: 1. A login user ID, for example user2, and a password assigned by their instructor. 2. A computer running the UNIX operating system with CDE. 3. Networked computers in classroom. Notes: 1 - 5 Fundamentals UNIX 2.0—-Lab 5.4.6 Copyright 2002, Cisco Systems, Inc. Use the diagram of the sample Class File system directory tree to assist with this lab. -
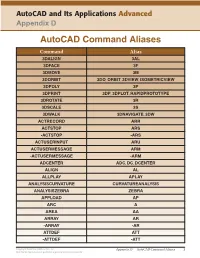
Autocad Command Aliases
AutoCAD and Its Applications Advanced Appendix D AutoCAD Command Aliases Command Alias 3DALIGN 3AL 3DFACE 3F 3DMOVE 3M 3DORBIT 3DO, ORBIT, 3DVIEW, ISOMETRICVIEW 3DPOLY 3P 3DPRINT 3DP, 3DPLOT, RAPIDPROTOTYPE 3DROTATE 3R 3DSCALE 3S 3DWALK 3DNAVIGATE, 3DW ACTRECORD ARR ACTSTOP ARS -ACTSTOP -ARS ACTUSERINPUT ARU ACTUSERMESSAGE ARM -ACTUSERMESSAGE -ARM ADCENTER ADC, DC, DCENTER ALIGN AL ALLPLAY APLAY ANALYSISCURVATURE CURVATUREANALYSIS ANALYSISZEBRA ZEBRA APPLOAD AP ARC A AREA AA ARRAY AR -ARRAY -AR ATTDEF ATT -ATTDEF -ATT Copyright Goodheart-Willcox Co., Inc. Appendix D — AutoCAD Command Aliases 1 May not be reproduced or posted to a publicly accessible website. Command Alias ATTEDIT ATE -ATTEDIT -ATE, ATTE ATTIPEDIT ATI BACTION AC BCLOSE BC BCPARAMETER CPARAM BEDIT BE BLOCK B -BLOCK -B BOUNDARY BO -BOUNDARY -BO BPARAMETER PARAM BREAK BR BSAVE BS BVSTATE BVS CAMERA CAM CHAMFER CHA CHANGE -CH CHECKSTANDARDS CHK CIRCLE C COLOR COL, COLOUR COMMANDLINE CLI CONSTRAINTBAR CBAR CONSTRAINTSETTINGS CSETTINGS COPY CO, CP CTABLESTYLE CT CVADD INSERTCONTROLPOINT CVHIDE POINTOFF CVREBUILD REBUILD CVREMOVE REMOVECONTROLPOINT CVSHOW POINTON Copyright Goodheart-Willcox Co., Inc. Appendix D — AutoCAD Command Aliases 2 May not be reproduced or posted to a publicly accessible website. Command Alias CYLINDER CYL DATAEXTRACTION DX DATALINK DL DATALINKUPDATE DLU DBCONNECT DBC, DATABASE, DATASOURCE DDGRIPS GR DELCONSTRAINT DELCON DIMALIGNED DAL, DIMALI DIMANGULAR DAN, DIMANG DIMARC DAR DIMBASELINE DBA, DIMBASE DIMCENTER DCE DIMCONSTRAINT DCON DIMCONTINUE DCO, DIMCONT DIMDIAMETER DDI, DIMDIA DIMDISASSOCIATE DDA DIMEDIT DED, DIMED DIMJOGGED DJO, JOG DIMJOGLINE DJL DIMLINEAR DIMLIN, DLI DIMORDINATE DOR, DIMORD DIMOVERRIDE DOV, DIMOVER DIMRADIUS DIMRAD, DRA DIMREASSOCIATE DRE DIMSTYLE D, DIMSTY, DST DIMTEDIT DIMTED DIST DI, LENGTH DIVIDE DIV DONUT DO DRAWINGRECOVERY DRM DRAWORDER DR Copyright Goodheart-Willcox Co., Inc. -

CS101 Lecture 9
How do you copy/move/rename/remove files? How do you create a directory ? What is redirection and piping? Readings: See CCSO’s Unix pages and 9-2 cp option file1 file2 First Version cp file1 file2 file3 … dirname Second Version This is one version of the cp command. file2 is created and the contents of file1 are copied into file2. If file2 already exits, it This version copies the files file1, file2, file3,… into the directory will be replaced with a new one. dirname. where option is -i Protects you from overwriting an existing file by asking you for a yes or no before it copies a file with an existing name. -r Can be used to copy directories and all their contents into a new directory 9-3 9-4 cs101 jsmith cs101 jsmith pwd data data mp1 pwd mp1 {FILES: mp1_data.m, mp1.m } {FILES: mp1_data.m, mp1.m } Copy the file named mp1_data.m from the cs101/data Copy the file named mp1_data.m from the cs101/data directory into the pwd. directory into the mp1 directory. > cp ~cs101/data/mp1_data.m . > cp ~cs101/data/mp1_data.m mp1 The (.) dot means “here”, that is, your pwd. 9-5 The (.) dot means “here”, that is, your pwd. 9-6 Example: To create a new directory named “temp” and to copy mv option file1 file2 First Version the contents of an existing directory named mp1 into temp, This is one version of the mv command. file1 is renamed file2. where option is -i Protects you from overwriting an existing file by asking you > cp -r mp1 temp for a yes or no before it copies a file with an existing name. -

Windows Command Prompt Cheatsheet
Windows Command Prompt Cheatsheet - Command line interface (as opposed to a GUI - graphical user interface) - Used to execute programs - Commands are small programs that do something useful - There are many commands already included with Windows, but we will use a few. - A filepath is where you are in the filesystem • C: is the C drive • C:\user\Documents is the Documents folder • C:\user\Documents\hello.c is a file in the Documents folder Command What it Does Usage dir Displays a list of a folder’s files dir (shows current folder) and subfolders dir myfolder cd Displays the name of the current cd filepath chdir directory or changes the current chdir filepath folder. cd .. (goes one directory up) md Creates a folder (directory) md folder-name mkdir mkdir folder-name rm Deletes a folder (directory) rm folder-name rmdir rmdir folder-name rm /s folder-name rmdir /s folder-name Note: if the folder isn’t empty, you must add the /s. copy Copies a file from one location to copy filepath-from filepath-to another move Moves file from one folder to move folder1\file.txt folder2\ another ren Changes the name of a file ren file1 file2 rename del Deletes one or more files del filename exit Exits batch script or current exit command control echo Used to display a message or to echo message turn off/on messages in batch scripts type Displays contents of a text file type myfile.txt fc Compares two files and displays fc file1 file2 the difference between them cls Clears the screen cls help Provides more details about help (lists all commands) DOS/Command Prompt help command commands Source: https://technet.microsoft.com/en-us/library/cc754340.aspx. -

Disk Clone Industrial
Disk Clone Industrial USER MANUAL Ver. 1.0.0 Updated: 9 June 2020 | Contents | ii Contents Legal Statement............................................................................... 4 Introduction......................................................................................4 Cloning Data.................................................................................................................................... 4 Erasing Confidential Data..................................................................................................................5 Disk Clone Overview.......................................................................6 System Requirements....................................................................................................................... 7 Software Licensing........................................................................................................................... 7 Software Updates............................................................................................................................. 8 Getting Started.................................................................................9 Disk Clone Installation and Distribution.......................................................................................... 12 Launching and initial Configuration..................................................................................................12 Navigating Disk Clone.....................................................................................................................14 -

Mac Keyboard Shortcuts Cut, Copy, Paste, and Other Common Shortcuts
Mac keyboard shortcuts By pressing a combination of keys, you can do things that normally need a mouse, trackpad, or other input device. To use a keyboard shortcut, hold down one or more modifier keys while pressing the last key of the shortcut. For example, to use the shortcut Command-C (copy), hold down Command, press C, then release both keys. Mac menus and keyboards often use symbols for certain keys, including the modifier keys: Command ⌘ Option ⌥ Caps Lock ⇪ Shift ⇧ Control ⌃ Fn If you're using a keyboard made for Windows PCs, use the Alt key instead of Option, and the Windows logo key instead of Command. Some Mac keyboards and shortcuts use special keys in the top row, which include icons for volume, display brightness, and other functions. Press the icon key to perform that function, or combine it with the Fn key to use it as an F1, F2, F3, or other standard function key. To learn more shortcuts, check the menus of the app you're using. Every app can have its own shortcuts, and shortcuts that work in one app may not work in another. Cut, copy, paste, and other common shortcuts Shortcut Description Command-X Cut: Remove the selected item and copy it to the Clipboard. Command-C Copy the selected item to the Clipboard. This also works for files in the Finder. Command-V Paste the contents of the Clipboard into the current document or app. This also works for files in the Finder. Command-Z Undo the previous command. You can then press Command-Shift-Z to Redo, reversing the undo command. -
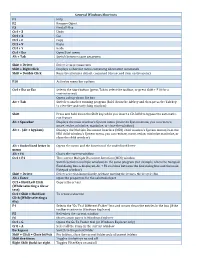
General Windows Shortcuts
General Windows Shortcuts F1 Help F2 Rename Object F3 Find all files Ctrl + Z Undo Ctrl + X Cut Ctrl + C Copy Ctrl + V Paste Ctrl + Y Redo Ctrl + Esc Open Start menu Alt + Tab Switch between open programs Alt + F4 Quit program Shift + Delete Delete item permanently Shift + Right Click Displays a shortcut menu containing alternative commands Shift + Double Click Runs the alternate default command ( the second item on the menu) Alt + Double Click Displays properties F10 Activates menu bar options Shift + F10 Opens a contex t menu ( same as righ t click) Ctrl + Esc or Esc Selects the Start button (press Tab to select the taskbar, or press Shift + F10 for a context menu) Alt + Down Arrow Opens a drop‐down list box Alt + Tab Switch to another running program (hold down the Alt key and then press the Tab key to view the task‐switching window) Alt + Shift + Tab Swit ch b ackward s b etween open appli cati ons Shift Press and hold down the Shift key while you insert a CD‐ROM to bypass the automatic‐ run feature Alt + Spacebar Displays the main window's System menu (from the System menu, you can restore, move, resize, minimize, maximize, or close the window) Alt + (Alt + hyphen) Displays the Multiple Document Interface (MDI) child window's System menu (from the MDI child window's System menu, you can restore, move, resize, minimize maximize, or close the child window) Ctrl + Tab Switch to t h e next child window o f a Multi ple D ocument Interf ace (MDI) pr ogram Alt + Underlined letter in Opens the menu and the function of the underlined letter -

This Document Explains How to Copy Ondemand5 Data to Your Hard Drive
Copying Your Repair DVD Data To Your Hard Drive Introduction This document explains how to copy OnDemand5 Repair data to your hard drive, and how to configure your OnDemand software appropriately. The document is intended for your network professional as a practical guide for implementing Mitchell1’s quarterly updates. The document provides two methods; one using the Xcopy command in a DOS window, and the other using standard Windows Copy and Paste functionality. Preparing your System You will need 8 Gigabytes of free space per DVD to be copied onto a hard drive. Be sure you have the necessary space before beginning this procedure. Turn off screen savers, power down options or any other program that may interfere with this process. IMPORTANT NOTICE – USE AT YOUR OWN RISK: This information is provided as a courtesy to assist those who desire to copy their DVD disks to their hard drive. Minimal technical assistance is available for this procedure. It is not recommended due to the high probability of failure due to DVD drive/disk read problems, over heating, hard drive write errors and memory overrun issues. This procedure is very detailed and should only be performed by users who are very familiar with Windows and/or DOS commands. Novice computers users should not attempt this procedure. Copying Repair data from a DVD is a time-consuming process. Depending on the speed of your processor and/or network, could easily require two or more hours per disk. For this reason, we recommend that you perform the actual copying of data during non-business evening or weekend hours. -

Dell EMC Powerstore CLI Guide
Dell EMC PowerStore CLI Guide May 2020 Rev. A01 Notes, cautions, and warnings NOTE: A NOTE indicates important information that helps you make better use of your product. CAUTION: A CAUTION indicates either potential damage to hardware or loss of data and tells you how to avoid the problem. WARNING: A WARNING indicates a potential for property damage, personal injury, or death. © 2020 Dell Inc. or its subsidiaries. All rights reserved. Dell, EMC, and other trademarks are trademarks of Dell Inc. or its subsidiaries. Other trademarks may be trademarks of their respective owners. Contents Additional Resources.......................................................................................................................4 Chapter 1: Introduction................................................................................................................... 5 Overview.................................................................................................................................................................................5 Use PowerStore CLI in scripts.......................................................................................................................................5 Set up the PowerStore CLI client........................................................................................................................................5 Install the PowerStore CLI client.................................................................................................................................. -

Your Performance Task Summary Explanation
Lab Report: 11.2.5 Manage Files Your Performance Your Score: 0 of 3 (0%) Pass Status: Not Passed Elapsed Time: 6 seconds Required Score: 100% Task Summary Actions you were required to perform: In Compress the D:\Graphics folderHide Details Set the Compressed attribute Apply the changes to all folders and files In Hide the D:\Finances folder In Set Read-only on filesHide Details Set read-only on 2017report.xlsx Set read-only on 2018report.xlsx Do not set read-only for the 2019report.xlsx file Explanation In this lab, your task is to complete the following: Compress the D:\Graphics folder and all of its contents. Hide the D:\Finances folder. Make the following files Read-only: D:\Finances\2017report.xlsx D:\Finances\2018report.xlsx Complete this lab as follows: 1. Compress a folder as follows: a. From the taskbar, open File Explorer. b. Maximize the window for easier viewing. c. In the left pane, expand This PC. d. Select Data (D:). e. Right-click Graphics and select Properties. f. On the General tab, select Advanced. g. Select Compress contents to save disk space. h. Click OK. i. Click OK. j. Make sure Apply changes to this folder, subfolders and files is selected. k. Click OK. 2. Hide a folder as follows: a. Right-click Finances and select Properties. b. Select Hidden. c. Click OK. 3. Set files to Read-only as follows: a. Double-click Finances to view its contents. b. Right-click 2017report.xlsx and select Properties. c. Select Read-only. d. Click OK. e. -

The Linux Command Line
The Linux Command Line Fifth Internet Edition William Shotts A LinuxCommand.org Book Copyright ©2008-2019, William E. Shotts, Jr. This work is licensed under the Creative Commons Attribution-Noncommercial-No De- rivative Works 3.0 United States License. To view a copy of this license, visit the link above or send a letter to Creative Commons, PO Box 1866, Mountain View, CA 94042. A version of this book is also available in printed form, published by No Starch Press. Copies may be purchased wherever fine books are sold. No Starch Press also offers elec- tronic formats for popular e-readers. They can be reached at: https://www.nostarch.com. Linux® is the registered trademark of Linus Torvalds. All other trademarks belong to their respective owners. This book is part of the LinuxCommand.org project, a site for Linux education and advo- cacy devoted to helping users of legacy operating systems migrate into the future. You may contact the LinuxCommand.org project at http://linuxcommand.org. Release History Version Date Description 19.01A January 28, 2019 Fifth Internet Edition (Corrected TOC) 19.01 January 17, 2019 Fifth Internet Edition. 17.10 October 19, 2017 Fourth Internet Edition. 16.07 July 28, 2016 Third Internet Edition. 13.07 July 6, 2013 Second Internet Edition. 09.12 December 14, 2009 First Internet Edition. Table of Contents Introduction....................................................................................................xvi Why Use the Command Line?......................................................................................xvi -

Powerview Command Reference
PowerView Command Reference TRACE32 Online Help TRACE32 Directory TRACE32 Index TRACE32 Documents ...................................................................................................................... PowerView User Interface ............................................................................................................ PowerView Command Reference .............................................................................................1 History ...................................................................................................................................... 12 ABORT ...................................................................................................................................... 13 ABORT Abort driver program 13 AREA ........................................................................................................................................ 14 AREA Message windows 14 AREA.CLEAR Clear area 15 AREA.CLOSE Close output file 15 AREA.Create Create or modify message area 16 AREA.Delete Delete message area 17 AREA.List Display a detailed list off all message areas 18 AREA.OPEN Open output file 20 AREA.PIPE Redirect area to stdout 21 AREA.RESet Reset areas 21 AREA.SAVE Save AREA window contents to file 21 AREA.Select Select area 22 AREA.STDERR Redirect area to stderr 23 AREA.STDOUT Redirect area to stdout 23 AREA.view Display message area in AREA window 24 AutoSTOre ..............................................................................................................................