Hadoop Ecosystem Why an Ecosystem
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Apache Oozie Apache Oozie Get a Solid Grounding in Apache Oozie, the Workflow Scheduler System for “In This Book, the Managing Hadoop Jobs
Apache Oozie Apache Oozie Apache Get a solid grounding in Apache Oozie, the workflow scheduler system for “In this book, the managing Hadoop jobs. In this hands-on guide, two experienced Hadoop authors have striven for practitioners walk you through the intricacies of this powerful and flexible platform, with numerous examples and real-world use cases. practicality, focusing on Once you set up your Oozie server, you’ll dive into techniques for writing the concepts, principles, and coordinating workflows, and learn how to write complex data pipelines. tips, and tricks that Advanced topics show you how to handle shared libraries in Oozie, as well developers need to get as how to implement and manage Oozie’s security capabilities. the most out of Oozie. ■ Install and confgure an Oozie server, and get an overview of A volume such as this is basic concepts long overdue. Developers ■ Journey through the world of writing and confguring will get a lot more out of workfows the Hadoop ecosystem ■ Learn how the Oozie coordinator schedules and executes by reading it.” workfows based on triggers —Raymie Stata ■ Understand how Oozie manages data dependencies CEO, Altiscale ■ Use Oozie bundles to package several coordinator apps into Oozie simplifies a data pipeline “ the managing and ■ Learn about security features and shared library management automating of complex ■ Implement custom extensions and write your own EL functions and actions Hadoop workloads. ■ Debug workfows and manage Oozie’s operational details This greatly benefits Apache both developers and Mohammad Kamrul Islam works as a Staff Software Engineer in the data operators alike.” engineering team at Uber. -
Unravel Data Systems Version 4.5
UNRAVEL DATA SYSTEMS VERSION 4.5 Component name Component version name License names jQuery 1.8.2 MIT License Apache Tomcat 5.5.23 Apache License 2.0 Tachyon Project POM 0.8.2 Apache License 2.0 Apache Directory LDAP API Model 1.0.0-M20 Apache License 2.0 apache/incubator-heron 0.16.5.1 Apache License 2.0 Maven Plugin API 3.0.4 Apache License 2.0 ApacheDS Authentication Interceptor 2.0.0-M15 Apache License 2.0 Apache Directory LDAP API Extras ACI 1.0.0-M20 Apache License 2.0 Apache HttpComponents Core 4.3.3 Apache License 2.0 Spark Project Tags 2.0.0-preview Apache License 2.0 Curator Testing 3.3.0 Apache License 2.0 Apache HttpComponents Core 4.4.5 Apache License 2.0 Apache Commons Daemon 1.0.15 Apache License 2.0 classworlds 2.4 Apache License 2.0 abego TreeLayout Core 1.0.1 BSD 3-clause "New" or "Revised" License jackson-core 2.8.6 Apache License 2.0 Lucene Join 6.6.1 Apache License 2.0 Apache Commons CLI 1.3-cloudera-pre-r1439998 Apache License 2.0 hive-apache 0.5 Apache License 2.0 scala-parser-combinators 1.0.4 BSD 3-clause "New" or "Revised" License com.springsource.javax.xml.bind 2.1.7 Common Development and Distribution License 1.0 SnakeYAML 1.15 Apache License 2.0 JUnit 4.12 Common Public License 1.0 ApacheDS Protocol Kerberos 2.0.0-M12 Apache License 2.0 Apache Groovy 2.4.6 Apache License 2.0 JGraphT - Core 1.2.0 (GNU Lesser General Public License v2.1 or later AND Eclipse Public License 1.0) chill-java 0.5.0 Apache License 2.0 Apache Commons Logging 1.2 Apache License 2.0 OpenCensus 0.12.3 Apache License 2.0 ApacheDS Protocol -

Persisting Big-Data the Nosql Landscape
Information Systems 63 (2017) 1–23 Contents lists available at ScienceDirect Information Systems journal homepage: www.elsevier.com/locate/infosys Persisting big-data: The NoSQL landscape Alejandro Corbellini n, Cristian Mateos, Alejandro Zunino, Daniela Godoy, Silvia Schiaffino ISISTAN (CONICET-UNCPBA) Research Institute1, UNICEN University, Campus Universitario, Tandil B7001BBO, Argentina article info abstract Article history: The growing popularity of massively accessed Web applications that store and analyze Received 11 March 2014 large amounts of data, being Facebook, Twitter and Google Search some prominent Accepted 21 July 2016 examples of such applications, have posed new requirements that greatly challenge tra- Recommended by: G. Vossen ditional RDBMS. In response to this reality, a new way of creating and manipulating data Available online 30 July 2016 stores, known as NoSQL databases, has arisen. This paper reviews implementations of Keywords: NoSQL databases in order to provide an understanding of current tools and their uses. NoSQL databases First, NoSQL databases are compared with traditional RDBMS and important concepts are Relational databases explained. Only databases allowing to persist data and distribute them along different Distributed systems computing nodes are within the scope of this review. Moreover, NoSQL databases are Database persistence divided into different types: Key-Value, Wide-Column, Document-oriented and Graph- Database distribution Big data oriented. In each case, a comparison of available databases -

HDP 3.1.4 Release Notes Date of Publish: 2019-08-26
Release Notes 3 HDP 3.1.4 Release Notes Date of Publish: 2019-08-26 https://docs.hortonworks.com Release Notes | Contents | ii Contents HDP 3.1.4 Release Notes..........................................................................................4 Component Versions.................................................................................................4 Descriptions of New Features..................................................................................5 Deprecation Notices.................................................................................................. 6 Terminology.......................................................................................................................................................... 6 Removed Components and Product Capabilities.................................................................................................6 Testing Unsupported Features................................................................................ 6 Descriptions of the Latest Technical Preview Features.......................................................................................7 Upgrading to HDP 3.1.4...........................................................................................7 Behavioral Changes.................................................................................................. 7 Apache Patch Information.....................................................................................11 Accumulo........................................................................................................................................................... -

SAS 9.4 Hadoop Configuration Guide for Base SAS And
SAS® 9.4 Hadoop Configuration Guide for Base SAS® and SAS/ACCESS® Second Edition SAS® Documentation The correct bibliographic citation for this manual is as follows: SAS Institute Inc. 2015. SAS® 9.4 Hadoop Configuration Guide for Base SAS® and SAS/ACCESS®, Second Edition. Cary, NC: SAS Institute Inc. SAS® 9.4 Hadoop Configuration Guide for Base SAS® and SAS/ACCESS®, Second Edition Copyright © 2015, SAS Institute Inc., Cary, NC, USA All rights reserved. Produced in the United States of America. For a hard-copy book: No part of this publication may be reproduced, stored in a retrieval system, or transmitted, in any form or by any means, electronic, mechanical, photocopying, or otherwise, without the prior written permission of the publisher, SAS Institute Inc. For a web download or e-book: Your use of this publication shall be governed by the terms established by the vendor at the time you acquire this publication. The scanning, uploading, and distribution of this book via the Internet or any other means without the permission of the publisher is illegal and punishable by law. Please purchase only authorized electronic editions and do not participate in or encourage electronic piracy of copyrighted materials. Your support of others' rights is appreciated. U.S. Government License Rights; Restricted Rights: The Software and its documentation is commercial computer software developed at private expense and is provided with RESTRICTED RIGHTS to the United States Government. Use, duplication or disclosure of the Software by the United States Government is subject to the license terms of this Agreement pursuant to, as applicable, FAR 12.212, DFAR 227.7202-1(a), DFAR 227.7202-3(a) and DFAR 227.7202-4 and, to the extent required under U.S. -

Hortonworks Data Platform Date of Publish: 2018-09-21
Release Notes 3 Hortonworks Data Platform Date of Publish: 2018-09-21 http://docs.hortonworks.com Contents HDP 3.0.1 Release Notes..........................................................................................3 Component Versions.............................................................................................................................................3 New Features........................................................................................................................................................ 3 Deprecation Notices..............................................................................................................................................4 Terminology.............................................................................................................................................. 4 Removed Components and Product Capabilities.....................................................................................4 Unsupported Features........................................................................................................................................... 4 Technical Preview Features......................................................................................................................4 Upgrading to HDP 3.0.1...................................................................................................................................... 5 Before you begin..................................................................................................................................... -

CLUSTER CONTINUOUS DELIVERY with OOZIE Clay Baenziger – Bloomberg Hadoop Infrastructure
CLUSTER CONTINUOUS DELIVERY WITH OOZIE Clay Baenziger – Bloomberg Hadoop Infrastructure ApacheCon Big Data – 5/18/2017 ABOUT BLOOMBERG 2 BIG DATA AT BLOOMBERG Bloomberg quickly and accurately delivers business and financial information, news and insight around the world. A sense of scale: ● 550 exchange feeds and over 100 billion market data messages a day ● 400 million emails and 17 million IM’s daily across the Bloomberg Professional Service ● More than 2,400 journalists in over 120 countries ─ Produce more than 5,000 stories a day ─ Reaching over 360 million homes world wide 3 BLOOMBERG BIG DATA APACHE OPEN SOURCE Solr: 3 committers – commits in every Solr release since 4.6 Project JIRAs Project JIRAs Project JIRAs Phoenix 24 HBase 20 Spark 9 Zookeeper 8 HDFS 6 Bigtop 3 Oozie 4 Storm 2 Hive 2 Hadoop 2 YARN 2 Kafka 2 Flume 1 HAWQ 1 Total* 86 * Reporter or assignee from our Foundational Services group and affiliated projects 4 APACHE OOZIE What is Oozie: ● Oozie is a workflow scheduler system to manage Apache Hadoop jobs. ● Oozie workflow jobs are Directed Acyclical Graphs (DAGs) of actions. ● Oozie coordinator jobs are recurrent Oozie workflow jobs triggerd by time and data availability. ● Oozie is integrated with the rest of the Hadoop stack supporting several types of Hadoop jobs as well as system specific jobs out of the box. ● Oozie is a scalable, reliable and extensible system. Paraphrased from: Actions: http://oozie.apache.org/ ● Map/Reduce ● HDFS ● Spark ● Decision ● Hive ● Java ● Sub-Workflow ● Fork ● Pig ● Shell ● E-Mail ● Join -

Hortonworks Data Platform Release Notes (October 30, 2017)
Hortonworks Data Platform Release Notes (October 30, 2017) docs.cloudera.com Hortonworks Data Platform October 30, 2017 Hortonworks Data Platform: Release Notes Copyright © 2012-2017 Hortonworks, Inc. Some rights reserved. The Hortonworks Data Platform, powered by Apache Hadoop, is a massively scalable and 100% open source platform for storing, processing and analyzing large volumes of data. It is designed to deal with data from many sources and formats in a very quick, easy and cost-effective manner. The Hortonworks Data Platform consists of the essential set of Apache Software Foundation projects that focus on the storage and processing of Big Data, along with operations, security, and governance for the resulting system. This includes Apache Hadoop -- which includes MapReduce, Hadoop Distributed File System (HDFS), and Yet Another Resource Negotiator (YARN) -- along with Ambari, Falcon, Flume, HBase, Hive, Kafka, Knox, Oozie, Phoenix, Pig, Ranger, Slider, Spark, Sqoop, Storm, Tez, and ZooKeeper. Hortonworks is the major contributor of code and patches to many of these projects. These projects have been integrated and tested as part of the Hortonworks Data Platform release process and installation and configuration tools have also been included. Unlike other providers of platforms built using Apache Hadoop, Hortonworks contributes 100% of our code back to the Apache Software Foundation. The Hortonworks Data Platform is Apache-licensed and completely open source. We sell only expert technical support, training and partner-enablement services. All of our technology is, and will remain, free and open source. Please visit the Hortonworks Data Platform page for more information on Hortonworks technology. For more information on Hortonworks services, please visit either the Support or Training page. -

Big Data Security Analysis and Secure Hadoop Server
Big Data Security Analysis And Secure Hadoop Server Kripa Shanker Master’s thesis January 2018 Master's Degree in Information Technology 2 ABSTRACT Tampereen Ammattikorkeakoulu Tampere University of Applied Sciences Master's Degree in Information Technology Kripa Shanker Big data security analysis and secure hadoop server Master's thesis 62 pages, appendices 4 pages January 2018 Hadoop is a so influential technology that’s let us to do incredible things but major thing to secure informative data and environment is a big challenge as there are many bad guys (crackers, hackers) are there to harm the society using this data. Hadoop is now used in retail, banking, and healthcare applications; it has attracted the attention of thieves as well. While storing sensitive huge data, security plays an important role to keep it safe. Security was not that much considered when Hadoop was initially designed. Security is an important topic in Hadoop cluster. Plenty of examples are available in open media on data breaches and most recently was RANSOMEWARE which get access in server level which is more dangerous for an organizations. This is best time to only focus on security at any cost and time needed to secure data and platform. Hadoop is designed to run code on a distributed cluster of machines so without proper authentication anyone could submit code and it would be executed. Different projects have started to improve the security of Hadoop. In this thesis, the security of the system in Hadoop version 1, Hadoop version 2 and Hadoop version 3 is evaluated and different security enhancements are proposed, considering security improvements made by the two mentioned projects, Project Apache Knox Gateway, Project Apache Ranger and Apache Sentry, in terms of encryption, authentication, and authorization. -
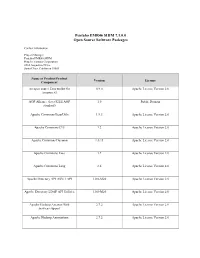
Pentaho EMR46 SHIM 7.1.0.0 Open Source Software Packages
Pentaho EMR46 SHIM 7.1.0.0 Open Source Software Packages Contact Information: Project Manager Pentaho EMR46 SHIM Hitachi Vantara Corporation 2535 Augustine Drive Santa Clara, California 95054 Name of Product/Product Version License Component An open source Java toolkit for 0.9.0 Apache License Version 2.0 Amazon S3 AOP Alliance (Java/J2EE AOP 1.0 Public Domain standard) Apache Commons BeanUtils 1.9.3 Apache License Version 2.0 Apache Commons CLI 1.2 Apache License Version 2.0 Apache Commons Daemon 1.0.13 Apache License Version 2.0 Apache Commons Exec 1.2 Apache License Version 2.0 Apache Commons Lang 2.6 Apache License Version 2.0 Apache Directory API ASN.1 API 1.0.0-M20 Apache License Version 2.0 Apache Directory LDAP API Utilities 1.0.0-M20 Apache License Version 2.0 Apache Hadoop Amazon Web 2.7.2 Apache License Version 2.0 Services support Apache Hadoop Annotations 2.7.2 Apache License Version 2.0 Name of Product/Product Version License Component Apache Hadoop Auth 2.7.2 Apache License Version 2.0 Apache Hadoop Common - 2.7.2 Apache License Version 2.0 org.apache.hadoop:hadoop-common Apache Hadoop HDFS 2.7.2 Apache License Version 2.0 Apache HBase - Client 1.2.0 Apache License Version 2.0 Apache HBase - Common 1.2.0 Apache License Version 2.0 Apache HBase - Hadoop 1.2.0 Apache License Version 2.0 Compatibility Apache HBase - Protocol 1.2.0 Apache License Version 2.0 Apache HBase - Server 1.2.0 Apache License Version 2.0 Apache HBase - Thrift - 1.2.0 Apache License Version 2.0 org.apache.hbase:hbase-thrift Apache HttpComponents Core -

Technology Overview
Big Data Technology Overview Term Description See Also Big Data - the 5 Vs Everyone Must Volume, velocity and variety. And some expand the definition further to include veracity 3 Vs Know and value as well. 5 Vs of Big Data From Wikipedia, “Agile software development is a group of software development methods based on iterative and incremental development, where requirements and solutions evolve through collaboration between self-organizing, cross-functional teams. Agile The Agile Manifesto It promotes adaptive planning, evolutionary development and delivery, a time-boxed iterative approach, and encourages rapid and flexible response to change. It is a conceptual framework that promotes foreseen tight iterations throughout the development cycle.” A data serialization system. From Wikepedia, Avro Apache Avro “It is a remote procedure call and serialization framework developed within Apache's Hadoop project. It uses JSON for defining data types and protocols, and serializes data in a compact binary format.” BigInsights Enterprise Edition provides a spreadsheet-like data analysis tool to help Big Insights IBM Infosphere Biginsights organizations store, manage, and analyze big data. A scalable multi-master database with no single points of failure. Cassandra Apache Cassandra It provides scalability and high availability without compromising performance. Cloudera Inc. is an American-based software company that provides Apache Hadoop- Cloudera Cloudera based software, support and services, and training to business customers. Wikipedia - Data Science Data science The study of the generalizable extraction of knowledge from data IBM - Data Scientist Coursera Big Data Technology Overview Term Description See Also Distributed system developed at Google for interactively querying large datasets. Dremel Dremel It empowers business analysts and makes it easy for business users to access the data Google Research rather than having to rely on data engineers. -

HPC-ABDS High Performance Computing Enhanced Apache Big Data Stack
HPC-ABDS High Performance Computing Enhanced Apache Big Data Stack Geoffrey C. Fox, Judy Qiu, Supun Kamburugamuve Shantenu Jha, Andre Luckow School of Informatics and Computing RADICAL Indiana University Rutgers University Bloomington, IN 47408, USA Piscataway, NJ 08854, USA fgcf, xqiu, [email protected] [email protected], [email protected] Abstract—We review the High Performance Computing En- systems as they illustrate key capabilities and often motivate hanced Apache Big Data Stack HPC-ABDS and summarize open source equivalents. the capabilities in 21 identified architecture layers. These The software is broken up into layers so that one can dis- cover Message and Data Protocols, Distributed Coordination, Security & Privacy, Monitoring, Infrastructure Management, cuss software systems in smaller groups. The layers where DevOps, Interoperability, File Systems, Cluster & Resource there is especial opportunity to integrate HPC are colored management, Data Transport, File management, NoSQL, SQL green in figure. We note that data systems that we construct (NewSQL), Extraction Tools, Object-relational mapping, In- from this software can run interoperably on virtualized or memory caching and databases, Inter-process Communication, non-virtualized environments aimed at key scientific data Batch Programming model and Runtime, Stream Processing, High-level Programming, Application Hosting and PaaS, Li- analysis problems. Most of ABDS emphasizes scalability braries and Applications, Workflow and Orchestration. We but not performance and one of our goals is to produce summarize status of these layers focusing on issues of impor- high performance environments. Here there is clear need tance for data analytics. We highlight areas where HPC and for better node performance and support of accelerators like ABDS have good opportunities for integration.