Big Data Security Analysis and Secure Hadoop Server
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Apache Oozie Apache Oozie Get a Solid Grounding in Apache Oozie, the Workflow Scheduler System for “In This Book, the Managing Hadoop Jobs
Apache Oozie Apache Oozie Apache Get a solid grounding in Apache Oozie, the workflow scheduler system for “In this book, the managing Hadoop jobs. In this hands-on guide, two experienced Hadoop authors have striven for practitioners walk you through the intricacies of this powerful and flexible platform, with numerous examples and real-world use cases. practicality, focusing on Once you set up your Oozie server, you’ll dive into techniques for writing the concepts, principles, and coordinating workflows, and learn how to write complex data pipelines. tips, and tricks that Advanced topics show you how to handle shared libraries in Oozie, as well developers need to get as how to implement and manage Oozie’s security capabilities. the most out of Oozie. ■ Install and confgure an Oozie server, and get an overview of A volume such as this is basic concepts long overdue. Developers ■ Journey through the world of writing and confguring will get a lot more out of workfows the Hadoop ecosystem ■ Learn how the Oozie coordinator schedules and executes by reading it.” workfows based on triggers —Raymie Stata ■ Understand how Oozie manages data dependencies CEO, Altiscale ■ Use Oozie bundles to package several coordinator apps into Oozie simplifies a data pipeline “ the managing and ■ Learn about security features and shared library management automating of complex ■ Implement custom extensions and write your own EL functions and actions Hadoop workloads. ■ Debug workfows and manage Oozie’s operational details This greatly benefits Apache both developers and Mohammad Kamrul Islam works as a Staff Software Engineer in the data operators alike.” engineering team at Uber. -
Unravel Data Systems Version 4.5
UNRAVEL DATA SYSTEMS VERSION 4.5 Component name Component version name License names jQuery 1.8.2 MIT License Apache Tomcat 5.5.23 Apache License 2.0 Tachyon Project POM 0.8.2 Apache License 2.0 Apache Directory LDAP API Model 1.0.0-M20 Apache License 2.0 apache/incubator-heron 0.16.5.1 Apache License 2.0 Maven Plugin API 3.0.4 Apache License 2.0 ApacheDS Authentication Interceptor 2.0.0-M15 Apache License 2.0 Apache Directory LDAP API Extras ACI 1.0.0-M20 Apache License 2.0 Apache HttpComponents Core 4.3.3 Apache License 2.0 Spark Project Tags 2.0.0-preview Apache License 2.0 Curator Testing 3.3.0 Apache License 2.0 Apache HttpComponents Core 4.4.5 Apache License 2.0 Apache Commons Daemon 1.0.15 Apache License 2.0 classworlds 2.4 Apache License 2.0 abego TreeLayout Core 1.0.1 BSD 3-clause "New" or "Revised" License jackson-core 2.8.6 Apache License 2.0 Lucene Join 6.6.1 Apache License 2.0 Apache Commons CLI 1.3-cloudera-pre-r1439998 Apache License 2.0 hive-apache 0.5 Apache License 2.0 scala-parser-combinators 1.0.4 BSD 3-clause "New" or "Revised" License com.springsource.javax.xml.bind 2.1.7 Common Development and Distribution License 1.0 SnakeYAML 1.15 Apache License 2.0 JUnit 4.12 Common Public License 1.0 ApacheDS Protocol Kerberos 2.0.0-M12 Apache License 2.0 Apache Groovy 2.4.6 Apache License 2.0 JGraphT - Core 1.2.0 (GNU Lesser General Public License v2.1 or later AND Eclipse Public License 1.0) chill-java 0.5.0 Apache License 2.0 Apache Commons Logging 1.2 Apache License 2.0 OpenCensus 0.12.3 Apache License 2.0 ApacheDS Protocol -

Persisting Big-Data the Nosql Landscape
Information Systems 63 (2017) 1–23 Contents lists available at ScienceDirect Information Systems journal homepage: www.elsevier.com/locate/infosys Persisting big-data: The NoSQL landscape Alejandro Corbellini n, Cristian Mateos, Alejandro Zunino, Daniela Godoy, Silvia Schiaffino ISISTAN (CONICET-UNCPBA) Research Institute1, UNICEN University, Campus Universitario, Tandil B7001BBO, Argentina article info abstract Article history: The growing popularity of massively accessed Web applications that store and analyze Received 11 March 2014 large amounts of data, being Facebook, Twitter and Google Search some prominent Accepted 21 July 2016 examples of such applications, have posed new requirements that greatly challenge tra- Recommended by: G. Vossen ditional RDBMS. In response to this reality, a new way of creating and manipulating data Available online 30 July 2016 stores, known as NoSQL databases, has arisen. This paper reviews implementations of Keywords: NoSQL databases in order to provide an understanding of current tools and their uses. NoSQL databases First, NoSQL databases are compared with traditional RDBMS and important concepts are Relational databases explained. Only databases allowing to persist data and distribute them along different Distributed systems computing nodes are within the scope of this review. Moreover, NoSQL databases are Database persistence divided into different types: Key-Value, Wide-Column, Document-oriented and Graph- Database distribution Big data oriented. In each case, a comparison of available databases -

Assessment of Multiple Ingest Strategies for Accumulo Key-Value Store
Assessment of Multiple Ingest Strategies for Accumulo Key-Value Store by Hai Pham A thesis submitted to the Graduate Faculty of Auburn University in partial fulfillment of the requirements for the Degree of Master of Science Auburn, Alabama May 7, 2016 Keywords: Accumulo, noSQL, ingest Copyright 2016 by Hai Pham Approved by Weikuan Yu, Co-Chair, Associate Professor of Computer Science, Florida State University Saad Biaz, Co-Chair, Professor of Computer Science and Software Engineering, Auburn University Sanjeev Baskiyar, Associate Professor of Computer Science and Software Engineering, Auburn University Abstract In recent years, the emergence of heterogeneous data, especially of the unstructured type, has been extremely rapid. The data growth happens concurrently in 3 dimensions: volume (size), velocity (growth rate) and variety (many types). This emerging trend has opened a new broad area of research, widely accepted as Big Data, which focuses on how to acquire, organize and manage huge amount of data effectively and efficiently. When coping with such Big Data, the traditional approach using RDBMS has been inefficient; because of this problem, a more efficient system named noSQL had to be created. This thesis will give an overview knowledge on the aforementioned noSQL systems and will then delve into a more specific instance of them which is Accumulo key-value store. Furthermore, since Accumulo is not designed with an ingest interface for users, this thesis focuses on investigating various methods for ingesting data, improving the performance and dealing with numerous parameters affecting this process. ii Acknowledgments First and foremost, I would like to express my profound gratitude to Professor Yu who with great kindness and patience has guided me through not only every aspect of computer science research but also many great directions towards my personal issues. -

The Dzone Guide to Volume Ii
THE D ZONE GUIDE TO MODERN JAVA VOLUME II BROUGHT TO YOU IN PARTNERSHIP WITH DZONE.COM/GUIDES DZONE’S 2016 GUIDE TO MODERN JAVA Dear Reader, TABLE OF CONTENTS 3 EXECUTIVE SUMMARY Why isn’t Java dead after more than two decades? A few guesses: Java is (still) uniquely portable, readable to 4 KEY RESEARCH FINDINGS fresh eyes, constantly improving its automatic memory management, provides good full-stack support for high- 10 THE JAVA 8 API DESIGN PRINCIPLES load web services, and enjoys a diverse and enthusiastic BY PER MINBORG community, mature toolchain, and vigorous dependency 13 PROJECT JIGSAW IS COMING ecosystem. BY NICOLAI PARLOG Java is growing with us, and we’re growing with Java. Java 18 REACTIVE MICROSERVICES: DRIVING APPLICATION 8 just expanded our programming paradigm horizons (add MODERNIZATION EFFORTS Church and Curry to Kay and Gosling) and we’re still learning BY MARKUS EISELE how to mix functional and object-oriented code. Early next 21 CHECKLIST: 7 HABITS OF SUPER PRODUCTIVE JAVA DEVELOPERS year Java 9 will add a wealth of bigger-picture upgrades. 22 THE ELEMENTS OF MODERN JAVA STYLE But Java remains vibrant for many more reasons than the BY MICHAEL TOFINETTI robustness of the language and the comprehensiveness of the platform. JVM languages keep multiplying (Kotlin went 28 12 FACTORS AND BEYOND IN JAVA GA this year!), Android keeps increasing market share, and BY PIETER HUMPHREY AND MARK HECKLER demand for Java developers (measuring by both new job 31 DIVING DEEPER INTO JAVA DEVELOPMENT posting frequency and average salary) remains high. The key to the modernization of Java is not a laundry-list of JSRs, but 34 INFOGRAPHIC: JAVA'S IMPACT ON THE MODERN WORLD rather the energy of the Java developer community at large. -

Return of Organization Exempt from Income
OMB No. 1545-0047 Return of Organization Exempt From Income Tax Form 990 Under section 501(c), 527, or 4947(a)(1) of the Internal Revenue Code (except black lung benefit trust or private foundation) Open to Public Department of the Treasury Internal Revenue Service The organization may have to use a copy of this return to satisfy state reporting requirements. Inspection A For the 2011 calendar year, or tax year beginning 5/1/2011 , and ending 4/30/2012 B Check if applicable: C Name of organization The Apache Software Foundation D Employer identification number Address change Doing Business As 47-0825376 Name change Number and street (or P.O. box if mail is not delivered to street address) Room/suite E Telephone number Initial return 1901 Munsey Drive (909) 374-9776 Terminated City or town, state or country, and ZIP + 4 Amended return Forest Hill MD 21050-2747 G Gross receipts $ 554,439 Application pending F Name and address of principal officer: H(a) Is this a group return for affiliates? Yes X No Jim Jagielski 1901 Munsey Drive, Forest Hill, MD 21050-2747 H(b) Are all affiliates included? Yes No I Tax-exempt status: X 501(c)(3) 501(c) ( ) (insert no.) 4947(a)(1) or 527 If "No," attach a list. (see instructions) J Website: http://www.apache.org/ H(c) Group exemption number K Form of organization: X Corporation Trust Association Other L Year of formation: 1999 M State of legal domicile: MD Part I Summary 1 Briefly describe the organization's mission or most significant activities: to provide open source software to the public that we sponsor free of charge 2 Check this box if the organization discontinued its operations or disposed of more than 25% of its net assets. -

4.3.0 Third Party License Files
Third Party Terms Third Party License(s) of Terracotta Version 4.3 THE FOLLOWING THIRD PARTY COMPONENTS MAY BE UTILIZED, EMBEDDED, BUNDLED OR OTHERWISE INCLUDED IN SOME OF THE PRODUCTS ("Product") YOU HAVE LICENSED FROM TERRACOTTA, INC..THESE THIRD PARTY COMPONENTS MAY BE SUBJECT TO ADDITIONAL OR DIFFERENT LICENSE RIGHTS, TERMS AND CONDITIONS AND / OR REQUIRE CERTAIN NOTICES BY THEIR THIRD PARTY LICENSORS. SOFTWARE AG IS OBLIGED TO PASS ANY CURRENT AND FUTURE TERMS OF SUCH LICENSES THROUGH TO ITS LICENSEES. TP Product Name TP Product Version apache-commons-io 2.4 apache-commons-lang 2.5 apache-commons-logging 1.0.3 apache-jakarta-commons-beanutils 1.8.3 apache-jakarta-commons-cli 1.1 apache-jakarta-commons-collections 3.2.1 apache-jakarta-commons-logging 1.1.1 apache-log4j 1.2.17 apache-shiro 1.2.3 apache-xmlbeans 2.4.0 beanshell-project 2.0b4 commons-lang 2.6 fasterxml-jackson-annotations 2.3 gf.aopalliance-repackaged.jar 2.2.0 gf.hk2.api.jar 2.2.0 gf.hk2.locator.jar 2.2.0 Copyright (c) 2015 Software AG, Darmstadt, Germany Third Party License(s) of Terracotta Version 4.3 TP Product Name TP Product Version gf.hk2-utils.jar 2.2.0 gf.javax.annotation-api.jar 1.20 gf.javax.annotation.jar 1.1 gf.javax.inject.jar 2.2.0 gf.javax.jms.jar 1.1 gf.javax.mail.jar 1.4.4 (API 1.4) gf.javax.security.auth.message.jar 1.0 gf.javax.servlet-api.jar 3.0.1 gf.javax.transaction.jar 1.1 gf.javax.ws.rs-api.jar 2.00 gf.jersey-client.jar 2.6.0 gf.jersey-common.jar 2.6.0 gf.jersey-container-servlet-core.jar 2.6.0 gf.jersey-container-servlet.jar 2.6 gf.jersey-guava.jar -

HDP 3.1.4 Release Notes Date of Publish: 2019-08-26
Release Notes 3 HDP 3.1.4 Release Notes Date of Publish: 2019-08-26 https://docs.hortonworks.com Release Notes | Contents | ii Contents HDP 3.1.4 Release Notes..........................................................................................4 Component Versions.................................................................................................4 Descriptions of New Features..................................................................................5 Deprecation Notices.................................................................................................. 6 Terminology.......................................................................................................................................................... 6 Removed Components and Product Capabilities.................................................................................................6 Testing Unsupported Features................................................................................ 6 Descriptions of the Latest Technical Preview Features.......................................................................................7 Upgrading to HDP 3.1.4...........................................................................................7 Behavioral Changes.................................................................................................. 7 Apache Patch Information.....................................................................................11 Accumulo........................................................................................................................................................... -

SAS 9.4 Hadoop Configuration Guide for Base SAS And
SAS® 9.4 Hadoop Configuration Guide for Base SAS® and SAS/ACCESS® Second Edition SAS® Documentation The correct bibliographic citation for this manual is as follows: SAS Institute Inc. 2015. SAS® 9.4 Hadoop Configuration Guide for Base SAS® and SAS/ACCESS®, Second Edition. Cary, NC: SAS Institute Inc. SAS® 9.4 Hadoop Configuration Guide for Base SAS® and SAS/ACCESS®, Second Edition Copyright © 2015, SAS Institute Inc., Cary, NC, USA All rights reserved. Produced in the United States of America. For a hard-copy book: No part of this publication may be reproduced, stored in a retrieval system, or transmitted, in any form or by any means, electronic, mechanical, photocopying, or otherwise, without the prior written permission of the publisher, SAS Institute Inc. For a web download or e-book: Your use of this publication shall be governed by the terms established by the vendor at the time you acquire this publication. The scanning, uploading, and distribution of this book via the Internet or any other means without the permission of the publisher is illegal and punishable by law. Please purchase only authorized electronic editions and do not participate in or encourage electronic piracy of copyrighted materials. Your support of others' rights is appreciated. U.S. Government License Rights; Restricted Rights: The Software and its documentation is commercial computer software developed at private expense and is provided with RESTRICTED RIGHTS to the United States Government. Use, duplication or disclosure of the Software by the United States Government is subject to the license terms of this Agreement pursuant to, as applicable, FAR 12.212, DFAR 227.7202-1(a), DFAR 227.7202-3(a) and DFAR 227.7202-4 and, to the extent required under U.S. -

Full-Graph-Limited-Mvn-Deps.Pdf
org.jboss.cl.jboss-cl-2.0.9.GA org.jboss.cl.jboss-cl-parent-2.2.1.GA org.jboss.cl.jboss-classloader-N/A org.jboss.cl.jboss-classloading-vfs-N/A org.jboss.cl.jboss-classloading-N/A org.primefaces.extensions.master-pom-1.0.0 org.sonatype.mercury.mercury-mp3-1.0-alpha-1 org.primefaces.themes.overcast-${primefaces.theme.version} org.primefaces.themes.dark-hive-${primefaces.theme.version}org.primefaces.themes.humanity-${primefaces.theme.version}org.primefaces.themes.le-frog-${primefaces.theme.version} org.primefaces.themes.south-street-${primefaces.theme.version}org.primefaces.themes.sunny-${primefaces.theme.version}org.primefaces.themes.hot-sneaks-${primefaces.theme.version}org.primefaces.themes.cupertino-${primefaces.theme.version} org.primefaces.themes.trontastic-${primefaces.theme.version}org.primefaces.themes.excite-bike-${primefaces.theme.version} org.apache.maven.mercury.mercury-external-N/A org.primefaces.themes.redmond-${primefaces.theme.version}org.primefaces.themes.afterwork-${primefaces.theme.version}org.primefaces.themes.glass-x-${primefaces.theme.version}org.primefaces.themes.home-${primefaces.theme.version} org.primefaces.themes.black-tie-${primefaces.theme.version}org.primefaces.themes.eggplant-${primefaces.theme.version} org.apache.maven.mercury.mercury-repo-remote-m2-N/Aorg.apache.maven.mercury.mercury-md-sat-N/A org.primefaces.themes.ui-lightness-${primefaces.theme.version}org.primefaces.themes.midnight-${primefaces.theme.version}org.primefaces.themes.mint-choc-${primefaces.theme.version}org.primefaces.themes.afternoon-${primefaces.theme.version}org.primefaces.themes.dot-luv-${primefaces.theme.version}org.primefaces.themes.smoothness-${primefaces.theme.version}org.primefaces.themes.swanky-purse-${primefaces.theme.version} -
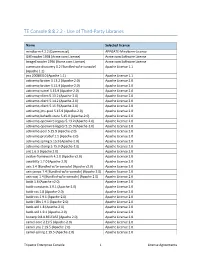
TE Console 8.8.2.2 - Use of Third-Party Libraries
TE Console 8.8.2.2 - Use of Third-Party Libraries Name Selected License mindterm 4.2.2 (Commercial) APPGATE-Mindterm-License GifEncoder 1998 (Acme.com License) Acme.com Software License ImageEncoder 1996 (Acme.com License) Acme.com Software License commons-discovery 0.2 [Bundled w/te-console] Apache License 1.1 (Apache 1.1) jrcs 20080310 (Apache 1.1) Apache License 1.1 activemQ-broker 5.13.2 (Apache-2.0) Apache License 2.0 activemQ-broker 5.15.9 (Apache-2.0) Apache License 2.0 activemQ-camel 5.15.9 (Apache-2.0) Apache License 2.0 activemQ-client 5.13.2 (Apache-2.0) Apache License 2.0 activemQ-client 5.14.2 (Apache-2.0) Apache License 2.0 activemQ-client 5.15.9 (Apache-2.0) Apache License 2.0 activemQ-jms-pool 5.15.9 (Apache-2.0) Apache License 2.0 activemQ-kahadb-store 5.15.9 (Apache-2.0) Apache License 2.0 activemQ-openwire-legacy 5.13.2 (Apache-2.0) Apache License 2.0 activemQ-openwire-legacy 5.15.9 (Apache-2.0) Apache License 2.0 activemQ-pool 5.15.9 (Apache-2.0) Apache License 2.0 activemQ-protobuf 1.1 (Apache-2.0) Apache License 2.0 activemQ-spring 5.15.9 (Apache-2.0) Apache License 2.0 activemQ-stomp 5.15.9 (Apache-2.0) Apache License 2.0 ant 1.6.3 (Apache 2.0) Apache License 2.0 avalon-framework 4.2.0 (Apache v2.0) Apache License 2.0 awaitility 1.7.0 (Apache-2.0) Apache License 2.0 axis 1.4 [Bundled w/te-console] (Apache v2.0) Apache License 2.0 axis-jaxrpc 1.4 [Bundled w/te-console] (Apache 2.0) Apache License 2.0 axis-saaj 1.4 [Bundled w/te-console] (Apache 2.0) Apache License 2.0 batik 1.6 (Apache v2.0) Apache License 2.0 batik-constants -

Licensing Information User Manual Release 4 (4.9) E87604-01
Oracle® Big Data Appliance Licensing Information User Manual Release 4 (4.9) E87604-01 May 2017 Describes licensing and support for Oracle Big Data Appliance. Oracle Big Data Appliance Licensing Information User Manual, Release 4 (4.9) E87604-01 Copyright © 2011, 2017, Oracle and/or its affiliates. All rights reserved. Primary Author: Frederick Kush This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. If this is software or related documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, then the following notice is applicable: U.S. GOVERNMENT END USERS: Oracle programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, delivered to U.S. Government end users are "commercial computer software" pursuant to the applicable Federal Acquisition Regulation and agency- specific supplemental regulations. As such, use, duplication, disclosure, modification, and adaptation of the programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, shall be subject to license terms and license restrictions applicable to the programs.