High Level Synthesis for Packet Processing Pipelines Cristian
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Packet Processing at Wire Speed Using Network Processors
Packet processing at wire speed using Network processors Chethan Kumar and Hao Che University of Texas at Arlington {ckumar, hche}@cse.uta.edu Abstract 1 Introduction Recent developments in fiber optics and the new The modern day Internet has seen an explosive bandwidth hungry applications have put more stress growth of applications being used on it. As more and on the active components (switches, routers etc.,) of a more applications are being developed, there is an network. Optical fiber bandwidth is no longer a increase in the amount of load put on the internet. At constraint for increasing the network bandwidth. the same time the fiber optics bandwidth has However, the processing power of the network has not increased dramatically to meet the traffic demand, but scaled upto the increase in the fiber bandwidth. the present day routers have limited processing power Communication industry is looking forward for more to handle this profound demand increase. Hence the innovative ways of designing router1 architecture and networking and telecommunications industry is research is being conducted to develop a scalable, compelled to look for new solutions for improving flexible and cost-effective architecture for routers. A the performance and the processing power of the successful outcome of this effort is a specialized routers. processor called Network processor. Network processor provides performance at hardware speeds One of the industry’s solutions to the challenges while attaining the flexibility of software. Network posed by the increased demand for the processing processors from different vendors employ different power is programmable functional units grouped into architectures and the choice of a particular type of a processor called Application Specific Instruction network processor can affect the architecture of the Processor (ASIP) or Network processor (NP)2. -

Packet Processing Execution Engine (PROX) - Performance Characterization for NFVI User Guide
USER GUIDE Intel Corporation Packet pROcessing eXecution Engine (PROX) - Performance Characterization for NFVI User Guide Authors 1 Introduction Yury Kylulin Properly designed Network Functions Virtualization Infrastructure (NFVI) environments deliver high packet processing rates, which are also a required dependency for Luc Provoost onboarded network functions. NFVI testing methodology typically includes both Petar Torre functionality testing and performance characterization testing, to ensure that NFVI both exposes the correct APIs and is capable of packet processing. This document describes how to use open source software tools to automate peak traffic (also called saturation) throughput testing to characterize the performance of a containerized NFVI system. The text and examples in this document are intended for architects and testing engineers for Communications Service Providers (CSPs) and their vendors. This document describes tools used during development to evaluate whether or not a containerized NFVI can perform the required rates of packet processing within set packet drop rates and latency percentiles. This document is part of the Network Transformation Experience Kit, which is available at https://networkbuilders.intel.com/network-technologies/network-transformation-exp- kits. 1 User Guide | Packet pROcessing eXecution Engine (PROX) - Performance Characterization for NFVI Table of Contents 1 Introduction ................................................................................................................................................................................................................ -

Lightweight Internet Protocol Stack Ideal Choice for High-Performance HFT and Telecom Packet Processing Applications Lightweight Internet Protocol Stack
GE Intelligent Platforms Lightweight Internet Protocol Stack Ideal Choice for High-Performance HFT and Telecom Packet Processing Applications Lightweight Internet Protocol Stack Introduction The number of devices connected to IP networks will be nearly three times as high as the global population in 2016. There will be nearly three networked devices per capita in 2016, up from over one networked device per capita in 2011. Driven in part by the increase in devices and the capabilities of those devices, IP traffic per capita will reach 15 gigabytes per capita in 2016, up from 4 gigabytes per capita in 2011 (Cisco VNI). Figure 1 shows the anticipated growth in IP traffic and networked devices. The IP traffic is increasing globally at the breath-taking pace. The rate at which these IP data packets needs to be processed to ensure not only their routing, security and delivery in the core of the network but also the identification and extraction of payload content for various end-user applications such as high frequency trading (HFT), has also increased. In order to support the demand of high-performance IP packet processing, users and developers are increasingly moving to a novel approach of combining PCI Express packet processing accelerator cards in a standalone network server to create an accelerated network server. The benefits of using such a hardware solu- tion are explained in the GE Intelligent Platforms white paper, Packet Processing in Telecommunications – A Case for the Accelerated Network Server. 80 2016 The number of networked devices -

Evaluating the Power of Flexible Packet Processing for Network Resource Allocation Naveen Kr
Evaluating the Power of Flexible Packet Processing for Network Resource Allocation Naveen Kr. Sharma, Antoine Kaufmann, and Thomas Anderson, University of Washington; Changhoon Kim, Barefoot Networks; Arvind Krishnamurthy, University of Washington; Jacob Nelson, Microsoft Research; Simon Peter, The University of Texas at Austin https://www.usenix.org/conference/nsdi17/technical-sessions/presentation/sharma This paper is included in the Proceedings of the 14th USENIX Symposium on Networked Systems Design and Implementation (NSDI ’17). March 27–29, 2017 • Boston, MA, USA ISBN 978-1-931971-37-9 Open access to the Proceedings of the 14th USENIX Symposium on Networked Systems Design and Implementation is sponsored by USENIX. Evaluating the Power of Flexible Packet Processing for Network Resource Allocation Naveen Kr. Sharma∗ Antoine Kaufmann∗ Thomas Anderson∗ Changhoon Kim† Arvind Krishnamurthy∗ Jacob Nelson‡ Simon Peter§ Abstract of the packet header, perform simple computations on Recent hardware switch architectures make it feasible values in packet headers, and maintain mutable state that to perform flexible packet processing inside the net- preserves the results of computations across packets. Im- work. This allows operators to configure switches to portantly, these advanced data-plane processing features parse and process custom packet headers using flexi- operate at line rate on every packet, addressing a ma- ble match+action tables in order to exercise control over jor limitation of earlier solutions such as OpenFlow [22] how packets are processed and routed. However, flexible which could only operate on a small fraction of packets, switches have limited state, support limited types of op- e.g., for flow setup. FlexSwitches thus hold the promise erations, and limit per-packet computation in order to be of ushering in the new paradigm of a software defined able to operate at line rate. -

An Architecture for High-Speed Packet Switched Networks (Thesis)
Purdue University Purdue e-Pubs Department of Computer Science Technical Reports Department of Computer Science 1989 An Architecture for High-Speed Packet Switched Networks (Thesis) Rajendra Shirvaram Yavatkar Report Number: 89-898 Yavatkar, Rajendra Shirvaram, "An Architecture for High-Speed Packet Switched Networks (Thesis)" (1989). Department of Computer Science Technical Reports. Paper 765. https://docs.lib.purdue.edu/cstech/765 This document has been made available through Purdue e-Pubs, a service of the Purdue University Libraries. Please contact [email protected] for additional information. AN ARCIITTECTURE FOR IDGH-SPEED PACKET SWITCHED NETWORKS Rajcndra Shivaram Yavalkar CSD-TR-898 AugusL 1989 AN ARCHITECTURE FOR HIGH-SPEED PACKET SWITCHED NETWORKS A Thesis Submitted to the Faculty of Purdue University by Rajendra Shivaram Yavatkar In Partial Fulfillment of the Requirements for the Degree of Doctor of Philosophy August 1989 Il TABLE OF CONTENTS Page LIST OF FIGURES Vl ABSTRACT ................................... Vlll 1. INTRODUCTION 1 1.1 BackgroWld... 2 1.1.1 Network Architecture 2 1.1.2 Network-Level Services. 7 1.1.3 Circuit Switching. 7 1.1.4 Packet Switching . 8 1.1.5 Summary.... 11 1.2 The Proposed Solution. 12 1.3 Plan of Thesis. ..... 14 2. DEFINITIONS AND TERMINOLOGY 15 2.1 Components of Packet Switched Networks 15 2.2 Concept Of Internetworking .. 16 2.3 Communication Services .... 17 2.4 Flow And Congestion Control. 18 3. NETWORK ARCHITECTURE 19 3.1 Basic Model . ... 20 3.2 Services Provided. 22 3.3 Protocol Hierarchy 24 3.4 Addressing . 26 3.5 Routing .. 29 3.6 Rate-based Congestion Avoidance 31 3.7 Responsibilities of a Router 32 3.8 Autoconfiguration .. -

ICMP for Ipv6
ICMP for IPv6 ICMP in IPv6 functions the same as ICMP in IPv4. ICMP for IPv6 generates error messages, such as ICMP destination unreachable messages, and informational messages, such as ICMP echo request and reply messages. • Information About ICMP for IPv6, on page 1 • Additional References for IPv6 Neighbor Discovery Multicast Suppress, on page 3 Information About ICMP for IPv6 ICMP for IPv6 Internet Control Message Protocol (ICMP) in IPv6 functions the same as ICMP in IPv4. ICMP generates error messages, such as ICMP destination unreachable messages, and informational messages, such as ICMP echo request and reply messages. Additionally, ICMP packets in IPv6 are used in the IPv6 neighbor discovery process, path MTU discovery, and the Multicast Listener Discovery (MLD) protocol for IPv6. MLD is used by IPv6 devices to discover multicast listeners (nodes that want to receive multicast packets destined for specific multicast addresses) on directly attached links. MLD is based on version 2 of the Internet Group Management Protocol (IGMP) for IPv4. A value of 58 in the Next Header field of the basic IPv6 packet header identifies an IPv6 ICMP packet. ICMP packets in IPv6 are like a transport-layer packet in the sense that the ICMP packet follows all the extension headers and is the last piece of information in the IPv6 packet. Within IPv6 ICMP packets, the ICMPv6 Type and ICMPv6 Code fields identify IPv6 ICMP packet specifics, such as the ICMP message type. The value in the Checksum field is derived (computed by the sender and checked by the receiver) from the fields in the IPv6 ICMP packet and the IPv6 pseudoheader. -
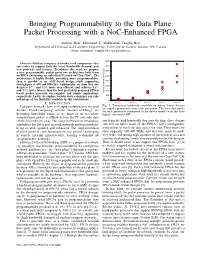
Packet Processing with a Noc-Enhanced FPGA
Bringing Programmability to the Data Plane: Packet Processing with a NoC-Enhanced FPGA Andrew Bitar, Mohamed S. Abdelfattah, Vaughn Betz Department of Electrical and Computer Engineering, University of Toronto, Toronto, ON, Canada fbitar, mohamed, [email protected] 4000 Abstract—Modern computer networks need components that can evolve to support both the latest bandwidth demands and 3500 new protocols and features. To address this need, we propose a new programmable packet processor architecture built from 3000 an FPGA containing an embedded Network-on-Chip (NoC). The 2500 architecture is highly flexible, providing more programmability than is possible in an ASIC-based design, while supporting 2000 throughputs of 400 and 800 Gb/s. Additionally, we show that our 1500 design is 1.7× and 3.2× more area efficient, and achieves 1.5× and 3.7× lower latency than the best previously proposed FPGA- 1000 based packet processor on complex and simple applications, (Gb/s) BW Tranceiver Total respectively. Lastly, we explore various ways a designer can take 500 advantage of the flexibility available in this architecture. 0 I. INTRODUCTION Stratix I Stratix II Stratix IV Stratix V Stratix X Computer networks have seen rapid evolution over the past Fig. 1: Transceiver bandwidth available on Altera Stratix devices has rapidly grown with every new generation. The three data points decade. “Cloud computing” and the “Internet of Things” are for each generation correspond to the device models with the three becoming household terms, as we move to an era where highest transceiver BW. computational power is offloaded from the PC and onto data centers located miles away. -

Pathminer Powered Predictable Packet Processing
PathMiner Powered Predictable Packet Processing John Sonchack and Jonathan M. Smith University of Pennsylvania f jsonch, jms [email protected] Abstract—Performance advances have made software packet Symbolic Execution Genetic Algorithms processing a compelling alternative to hardware. However, soft- Execution Tree Path Guided Supervised ware still lacks the delay predictability of hardware, an important Exploration Packet Evolution Learning property for security and quality of service. As a solution, we Path Constraints introduce PathMiner, an analysis tool that automatically builds ? Example Packets performance models for software packet processors at the fine ? granularity of per-packet execution times. PathMiner combines symbolic execution and genetic algorithms in an iterative feed- back loop to rapidly mine a packet processor binary for diverse packets that invoke complex execution paths. With these packets, PathMiner trains machine learning models that predict packet PathMiner execution times and paths based on raw packet header bytes. We Packet Processor Performance implement a prototype of PathMiner and test it by profiling Binary Models a software IP router. The evaluation shows that PathMiner’s models predict delay with low error – for over 40% of packets Fig. 1. PathMiner mines packet processors for execution paths and sample they predicted the router’s execution time to within 10 cycles. packets to train models. Closer examination shows that PathMiner’s effectiveness is due to higher execution path coverage than symbolic execution and the capability to generate diverse training samples efficiently. timing deadlines, e.g., processing one packet per cycle [29], PathMiner takes an important step towards making it practical [2], [15] to guarantee line rate. -

Impressive Packet Processing Performance Enables Greater Workload Consolidation Single Intel® Xeon® Processor Platform Achieves Over 80 Mpps Throughput1
Solution Brief Packet Processing on Intel® Architecture Impressive Packet Processing Performance Enables Greater Workload Consolidation Single Intel® Xeon® processor platform achieves Over 80 Mpps throughput1 With Intel® processors, it’s possible support teams, and faster time-to- to transition from using discrete market with a solution benefiting architectures per major workload from the economies of scale of the (application, control plane, packet server industry. Such a notable level and signal processing) to a single of consolidation is achievable through architecture that consolidates the industry-leading performance, I/O workloads into a more scalable and throughput and performance per watt simplified solution. This software- density – all on a standards-based based approach, depicted in Figure 1, platform. Solution providers listed in yields further benefits with Intel’s 4:1 this paper are ready to help equipment workload consolidation strategy. The architects jumpstart their next designs. hardware platform – based on general- purpose server technology – has been optimized using the best practices of 2011 2012 2013 the communications industry to ensure system robustness with core, memory Application and I/O scalability and performance Processing Intel® Xeon® Intel® Xeon® Next improvements, to meet network Processor Processor Generation operator’s low to high-end system C3500/C5500 E5-2600 series requirements. Control Processing Intel® QuickAssist This framework is made possible by Technology the high performance level of Intel Software Library processors plus the Intel® Data Plane Packet Development Kit (Intel® DPDK), which NPU/ASIC Processing greatly boosts packet processing Intel® Data Plane Development Kit performance and throughput, allowing more time for data plane applications. Signal As a result, telecom and network DSP DSP Processing Intel® Signal Processing equipment manufacturers (TEMs/ Development Kit NEMs) can take advantage of lower development costs, fewer tools and Figure 1. -

High Level Synthesis Tool for High Speed Packet Processing
Y.Wang & V.S.Pakki Y.Wang High Level Synthesis for Tool Master’s Thesis High Level Synthesis Tool for High Speed Packet Processing High Speed Packet Processing SpeedHigh Packet Yian Wang Venkata Soumya Pakki Series of Master’s theses Department of Electrical and Information Technology LU/LTH-EIT 2014-417 Department of Electrical and Information Technology, http://www.eit.lth.se Faculty of Engineering, LTH, Lund University, December 2013. High Level Synthesis Tool for High Speed Packet Processing by Yian Wang and Venkata Soumya Pakki Master’s of Science in System on Chip Department of Electrical and Information Technology Lund University Dec 2013 Abstract The main objective of this Master Thesis is to design and implement a high level synthesis tool for high speed packet processing. For a given network packet, determining the destination and performing the required alterations to the packet are the key parts of Packet Processing. The idea is to provide customers a customized Ethernet switch which is reliable and flexible. As a requirement for this, a high level packet processing language (PPL) is designed instead of any hardware descriptive language because of the regularity of packet processing. The packet processing is described in a powerful way based on the PPL. In this thesis, a design of Ethernet switch based on the PPL is proposed. Hardware implementation is done for the design and MyHDL is used as the hardware description language. Using Python, the compiled PPL program is translated into an hardware model. A tool has been developed which consists of a hardware generator and certain hardware infrastructures. -

High Performance Packet Processing with Flexnic
High Performance Packet Processing with FlexNIC Antoine Kaufmann1 Simon Peter2 Naveen Kr. Sharma1 Thomas Anderson1 Arvind Krishnamurthy1 1University of Washington 2The University of Texas at Austin fantoinek,naveenks,tom,[email protected] [email protected] Abstract newer processors. A 40 Gbps interface can receive a cache- The recent surge of network I/O performance has put enor- line sized (64B) packet close to every 12 ns. At that speed, mous pressure on memory and software I/O processing sub- OS kernel bypass [5; 39] is a necessity but not enough by it- systems. We argue that the primary reason for high mem- self. Even a single last-level cache access in the packet data ory and processing overheads is the inefficient use of these handling path can prevent software from keeping up with ar- resources by current commodity network interface cards riving network traffic. (NICs). We claim that the primary reason for high memory and We propose FlexNIC, a flexible network DMA interface processing overheads is the inefficient use of these resources that can be used by operating systems and applications alike by current commodity network interface cards (NICs). NICs to reduce packet processing overheads. FlexNIC allows ser- communicate with software by accessing data in server vices to install packet processing rules into the NIC, which memory, either in DRAM or via a designated last-level cache then executes simple operations on packets while exchang- (e.g., via DDIO [21], DCA [20], or TPH [38]). Packet de- ing them with host memory. Thus, our proposal moves some scriptor queues instruct the NIC as to where in server mem- of the packet processing traditionally done in software to the ory it should place the next packet and from where to read NIC, where it can be done flexibly and at high speed. -

IMPLEMENTING VOICE OVER IP Copyright 6 2003 by John Wiley & Sons, Inc
IMPLEMENTING VOICE OVER IP Copyright 6 2003 by John Wiley & Sons, Inc. All rights reserved. Published by John Wiley & Sons, Inc., Hoboken, New Jersey. Published simultaneously in Canada. No part of this publication may be reproduced, stored in a retrieval system, or transmitted in any form or by any means, electronic, mechanical, photocopying, recording, scanning, or otherwise, except as permitted under Section 107 or 108 of the 1976 United States Copyright Act, without either the prior written permission of the Publisher, or authorization through payment of the appropriate per-copy fee to the Copyright Clearance Center, Inc., 222 Rosewood Drive, Danvers, MA 01923, 978-750-8400, fax 978-750-4470, or on the web at www.copyright.com. Requests to the Publisher for permission should be addressed to the Permissions Department, John Wiley & Sons, Inc., 111 River Street, Hoboken, NJ 07030, (201) 748-6011, fax (201) 748-6008, e-mail: [email protected]. Limit of Liability/Disclaimer of Warranty: While the publisher and author have used their best e¤orts in preparing this book, they make no representations or warranties with respect to the accuracy or completeness of the contents of this book and specifically disclaim any implied warranties of merchantability or fitness for a particular purpose. No warranty may be created or extended by sales representatives or written sales materials. The advice and strategies contained herein may not be suitable for your situation. You should consult with a professional where appropriate. Neither the publisher nor author shall be liable for any loss of profit or any other commercial damages, including but not limited to special, incidental, consequential, or other damages.