The Chondrus Crispus Genome – Supplementary Material
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
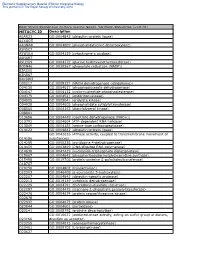
METACYC ID Description A0AR23 GO:0004842 (Ubiquitin-Protein Ligase
Electronic Supplementary Material (ESI) for Integrative Biology This journal is © The Royal Society of Chemistry 2012 Heat Stress Responsive Zostera marina Genes, Southern Population (α=0. -

Gene Symbol Gene Description ACVR1B Activin a Receptor, Type IB
Table S1. Kinase clones included in human kinase cDNA library for yeast two-hybrid screening Gene Symbol Gene Description ACVR1B activin A receptor, type IB ADCK2 aarF domain containing kinase 2 ADCK4 aarF domain containing kinase 4 AGK multiple substrate lipid kinase;MULK AK1 adenylate kinase 1 AK3 adenylate kinase 3 like 1 AK3L1 adenylate kinase 3 ALDH18A1 aldehyde dehydrogenase 18 family, member A1;ALDH18A1 ALK anaplastic lymphoma kinase (Ki-1) ALPK1 alpha-kinase 1 ALPK2 alpha-kinase 2 AMHR2 anti-Mullerian hormone receptor, type II ARAF v-raf murine sarcoma 3611 viral oncogene homolog 1 ARSG arylsulfatase G;ARSG AURKB aurora kinase B AURKC aurora kinase C BCKDK branched chain alpha-ketoacid dehydrogenase kinase BMPR1A bone morphogenetic protein receptor, type IA BMPR2 bone morphogenetic protein receptor, type II (serine/threonine kinase) BRAF v-raf murine sarcoma viral oncogene homolog B1 BRD3 bromodomain containing 3 BRD4 bromodomain containing 4 BTK Bruton agammaglobulinemia tyrosine kinase BUB1 BUB1 budding uninhibited by benzimidazoles 1 homolog (yeast) BUB1B BUB1 budding uninhibited by benzimidazoles 1 homolog beta (yeast) C9orf98 chromosome 9 open reading frame 98;C9orf98 CABC1 chaperone, ABC1 activity of bc1 complex like (S. pombe) CALM1 calmodulin 1 (phosphorylase kinase, delta) CALM2 calmodulin 2 (phosphorylase kinase, delta) CALM3 calmodulin 3 (phosphorylase kinase, delta) CAMK1 calcium/calmodulin-dependent protein kinase I CAMK2A calcium/calmodulin-dependent protein kinase (CaM kinase) II alpha CAMK2B calcium/calmodulin-dependent -

Structure and Function of the Human Recq DNA Helicases
Zurich Open Repository and Archive University of Zurich Main Library Strickhofstrasse 39 CH-8057 Zurich www.zora.uzh.ch Year: 2005 Structure and function of the human RecQ DNA helicases Garcia, P L Posted at the Zurich Open Repository and Archive, University of Zurich ZORA URL: https://doi.org/10.5167/uzh-34420 Dissertation Published Version Originally published at: Garcia, P L. Structure and function of the human RecQ DNA helicases. 2005, University of Zurich, Faculty of Science. Structure and Function of the Human RecQ DNA Helicases Dissertation zur Erlangung der naturwissenschaftlichen Doktorw¨urde (Dr. sc. nat.) vorgelegt der Mathematisch-naturwissenschaftlichen Fakultat¨ der Universitat¨ Z ¨urich von Patrick L. Garcia aus Unterseen BE Promotionskomitee Prof. Dr. Josef Jiricny (Vorsitz) Prof. Dr. Ulrich H ¨ubscher Dr. Pavel Janscak (Leitung der Dissertation) Z ¨urich, 2005 For my parents ii Summary The RecQ DNA helicases are highly conserved from bacteria to man and are required for the maintenance of genomic stability. All unicellular organisms contain a single RecQ helicase, whereas the number of RecQ homologues in higher organisms can vary. Mu- tations in the genes encoding three of the five human members of the RecQ family give rise to autosomal recessive disorders called Bloom syndrome, Werner syndrome and Rothmund-Thomson syndrome. These diseases manifest commonly with genomic in- stability and a high predisposition to cancer. However, the genetic alterations vary as well as the types of tumours in these syndromes. Furthermore, distinct clinical features are observed, like short stature and immunodeficiency in Bloom syndrome patients or premature ageing in Werner Syndrome patients. Also, the biochemical features of the human RecQ-like DNA helicases are diverse, pointing to different roles in the mainte- nance of genomic stability. -

Comparative Modeling and Functional Characterization of Two Enzymes of the Cyclooxygenase Pathway in Drosophila Melanogaster
City University of New York (CUNY) CUNY Academic Works All Dissertations, Theses, and Capstone Projects Dissertations, Theses, and Capstone Projects 2-2014 Comparative Modeling and Functional Characterization of Two Enzymes of the Cyclooxygenase Pathway in Drosophila melanogaster Yan Qi Graduate Center, City University of New York How does access to this work benefit ou?y Let us know! More information about this work at: https://academicworks.cuny.edu/gc_etds/94 Discover additional works at: https://academicworks.cuny.edu This work is made publicly available by the City University of New York (CUNY). Contact: [email protected] Comparative Modeling and Functional Characterization of Two Enzymes of the Cyclooxygenase Pathway in Drosophila melanogaster by Yan Qi A dissertation submitted to the Graduate Faculty in Biology in partial fulfillment of the requirements for the degree of Doctor of Philosophy, The City University of New York 2014 i © 2014 Yan Qi All Rights Reserved ii This manuscript has been read and accepted for the Graduate Faculty in Biology in satisfaction of the dissertation requirement for the degree of Doctor of Philosophy. _______ ______________________ Date Chair of Examining Committee Dr. Shaneen Singh, Brooklyn College _______ ______________________ Date Executive Officer Dr. Laurel A. Eckhardt ______________________ Dr. Peter Lipke, Brooklyn College ______________________ Dr. Shubha Govind, City College ______________________ Dr. Richard Magliozzo, Brooklyn College ______________________ Dr. Evros Vassiliou, Kean University Supervising Committee The City University of New York iii Abstract Comparative Modeling and Functional Characterization of Two Enzymes of the Cyclooxygenase Pathway in Drosophila melanogaster by Yan Qi Mentor: Shaneen Singh Eicosanoids are biologically active molecules oxygenated from twenty carbon polyunsaturated fatty acids. -

Atlas Antibodies in Breast Cancer Research Table of Contents
ATLAS ANTIBODIES IN BREAST CANCER RESEARCH TABLE OF CONTENTS The Human Protein Atlas, Triple A Polyclonals and PrecisA Monoclonals (4-5) Clinical markers (6) Antibodies used in breast cancer research (7-13) Antibodies against MammaPrint and other gene expression test proteins (14-16) Antibodies identified in the Human Protein Atlas (17-14) Finding cancer biomarkers, as exemplified by RBM3, granulin and anillin (19-22) Co-Development program (23) Contact (24) Page 2 (24) Page 3 (24) The Human Protein Atlas: a map of the Human Proteome The Human Protein Atlas (HPA) is a The Human Protein Atlas consortium cell types. All the IHC images for Swedish-based program initiated in is mainly funded by the Knut and Alice the normal tissue have undergone 2003 with the aim to map all the human Wallenberg Foundation. pathology-based annotation of proteins in cells, tissues and organs expression levels. using integration of various omics The Human Protein Atlas consists of technologies, including antibody- six separate parts, each focusing on References based imaging, mass spectrometry- a particular aspect of the genome- 1. Sjöstedt E, et al. (2020) An atlas of the based proteomics, transcriptomics wide analysis of the human proteins: protein-coding genes in the human, pig, and and systems biology. mouse brain. Science 367(6482) 2. Thul PJ, et al. (2017) A subcellular map of • The Tissue Atlas shows the the human proteome. Science. 356(6340): All the data in the knowledge resource distribution of proteins across all eaal3321 is open access to allow scientists both major tissues and organs in the 3. -

Itraq-Based Quantitative Proteomics Analysis Reveals the Mechanism Underlying the Weakening of Carbon Metabolism in Chlorotic Tea Leaves
Article iTRAQ-Based Quantitative Proteomics Analysis Reveals the Mechanism Underlying the Weakening of Carbon Metabolism in Chlorotic Tea Leaves Fang Dong 1,2, Yuanzhi Shi 1,2, Meiya Liu 1,2, Kai Fan 1,2, Qunfeng Zhang 1,2,* and Jianyun Ruan 1,2 1 Tea Research Institute, Chinese Academy of Agricultural Sciences, Hangzhou 310008, China; [email protected] (F.D.); [email protected] (Y.S.); [email protected] (M.L.); [email protected] (K.F.); [email protected] (J.R.) 2 Key Laboratory for Plant Biology and Resource Application of Tea, the Ministry of Agriculture, Hangzhou 310008, China * Correspondence: [email protected]; Tel.: +86-571-8527-0665 Received: 7 November 2018; Accepted: 5 December 2018; Published: 7 December 2018 Abstract: To uncover mechanism of highly weakened carbon metabolism in chlorotic tea (Camellia sinensis) plants, iTRAQ (isobaric tags for relative and absolute quantification)-based proteomic analyses were employed to study the differences in protein expression profiles in chlorophyll-deficient and normal green leaves in the tea plant cultivar “Huangjinya”. A total of 2110 proteins were identified in “Huangjinya”, and 173 proteins showed differential accumulations between the chlorotic and normal green leaves. Of these, 19 proteins were correlated with RNA expression levels, based on integrated analyses of the transcriptome and proteome. Moreover, the results of our analysis of differentially expressed proteins suggested that primary carbon metabolism (i.e., carbohydrate synthesis and transport) was inhibited in chlorotic tea leaves. The differentially expressed genes and proteins combined with photosynthetic phenotypic data indicated that 4-coumarate-CoA ligase (4CL) showed a major effect on repressing flavonoid metabolism, and abnormal developmental chloroplast inhibited the accumulation of chlorophyll and flavonoids because few carbon skeletons were provided as a result of a weakened primary carbon metabolism. -

Genome-Wide Approach to Identify Risk Factors for Therapy-Related Myeloid Leukemia
Leukemia (2006) 20, 239–246 & 2006 Nature Publishing Group All rights reserved 0887-6924/06 $30.00 www.nature.com/leu ORIGINAL ARTICLE Genome-wide approach to identify risk factors for therapy-related myeloid leukemia A Bogni1, C Cheng2, W Liu2, W Yang1, J Pfeffer1, S Mukatira3, D French1, JR Downing4, C-H Pui4,5,6 and MV Relling1,6 1Department of Pharmaceutical Sciences, The University of Tennessee, Memphis, TN, USA; 2Department of Biostatistics, The University of Tennessee, Memphis, TN, USA; 3Hartwell Center, The University of Tennessee, Memphis, TN, USA; 4Department of Pathology, The University of Tennessee, Memphis, TN, USA; 5Department of Hematology/Oncology St Jude Children’s Research Hospital, The University of Tennessee, Memphis, TN, USA; and 6Colleges of Medicine and Pharmacy, The University of Tennessee, Memphis, TN, USA Using a target gene approach, only a few host genetic risk therapy increases, the importance of identifying host factors for factors for treatment-related myeloid leukemia (t-ML) have been secondary neoplasms increases. defined. Gene expression microarrays allow for a more 4 genome-wide approach to assess possible genetic risk factors Because DNA microarrays interrogate multiple ( 10 000) for t-ML. We assessed gene expression profiles (n ¼ 12 625 genes in one experiment, they allow for a ‘genome-wide’ probe sets) in diagnostic acute lymphoblastic leukemic cells assessment of genes that may predispose to leukemogenesis. from 228 children treated on protocols that included leukemo- DNA microarray analysis of gene expression has been used to genic agents such as etoposide, 13 of whom developed t-ML. identify distinct expression profiles that are characteristic of Expression of 68 probes, corresponding to 63 genes, was different leukemia subtypes.13,14 Studies using this method have significantly related to risk of t-ML. -

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -

Effect of Pyrroloquinoline Quinone Disodium in Female Rats During
Downloaded from British Journal of Nutrition (2019), 121, 818–830 doi:10.1017/S0007114519000047 © The Authors 2019 https://www.cambridge.org/core Effect of pyrroloquinoline quinone disodium in female rats during gestating and lactating on reproductive performance and the intestinal barrier functions in the progeny . IP address: Boru Zhang, Wei Yang, Hongyun Zhang, Shiqi He, Qingwei Meng, Zhihui Chen and Anshan Shan* Institute of Animal Nutrition, Northeast Agricultural University, Harbin 150030, People’s Republic of China 170.106.202.226 (Submitted 26 September 2018 – Final revision received 21 December 2018 – Accepted 28 December 2018 – First published online 28 January 2019) , on Abstract 30 Sep 2021 at 19:42:41 The objective of this study was to investigate the effects of dietary pyrroloquinoline quinone disodium (PQQ·Na2) supplementation on the reproductive performance and intestinal barrier functions of gestating and lactating female Sprague–Dawley (SD) rats and their offspring. Dietary supplementation with PQQ·Na2 increased the number of implanted embryos per litter during gestation and lactation at GD 20 and increased the number of viable fetuses per litter, and the weight of uterine horns with fetuses increased at 1 d of newborn. The mRNA expression levels of catalase (CAT), glutathione peroxidase (GPx2), superoxide dismutase (SOD1), solute carrier family 2 member 1 (Slc2a1) · and solute carrier family 2 member 3 (Slc2a3) in the placenta were increased with dietary PQQ Na2 supplementation. Dietary , subject to the Cambridge Core terms of use, available at supplementation with PQQ·Na2 in gestating and lactating rats increased the CAT, SOD and GPx activities of the jejunal mucosa of weaned rats on PD 21. -

4-6 Weeks Old Female C57BL/6 Mice Obtained from Jackson Labs Were Used for Cell Isolation
Methods Mice: 4-6 weeks old female C57BL/6 mice obtained from Jackson labs were used for cell isolation. Female Foxp3-IRES-GFP reporter mice (1), backcrossed to B6/C57 background for 10 generations, were used for the isolation of naïve CD4 and naïve CD8 cells for the RNAseq experiments. The mice were housed in pathogen-free animal facility in the La Jolla Institute for Allergy and Immunology and were used according to protocols approved by the Institutional Animal Care and use Committee. Preparation of cells: Subsets of thymocytes were isolated by cell sorting as previously described (2), after cell surface staining using CD4 (GK1.5), CD8 (53-6.7), CD3ε (145- 2C11), CD24 (M1/69) (all from Biolegend). DP cells: CD4+CD8 int/hi; CD4 SP cells: CD4CD3 hi, CD24 int/lo; CD8 SP cells: CD8 int/hi CD4 CD3 hi, CD24 int/lo (Fig S2). Peripheral subsets were isolated after pooling spleen and lymph nodes. T cells were enriched by negative isolation using Dynabeads (Dynabeads untouched mouse T cells, 11413D, Invitrogen). After surface staining for CD4 (GK1.5), CD8 (53-6.7), CD62L (MEL-14), CD25 (PC61) and CD44 (IM7), naïve CD4+CD62L hiCD25-CD44lo and naïve CD8+CD62L hiCD25-CD44lo were obtained by sorting (BD FACS Aria). Additionally, for the RNAseq experiments, CD4 and CD8 naïve cells were isolated by sorting T cells from the Foxp3- IRES-GFP mice: CD4+CD62LhiCD25–CD44lo GFP(FOXP3)– and CD8+CD62LhiCD25– CD44lo GFP(FOXP3)– (antibodies were from Biolegend). In some cases, naïve CD4 cells were cultured in vitro under Th1 or Th2 polarizing conditions (3, 4). -

Annotation Guidelines for Experimental Procedures
Annotation Guidelines for Experimental Procedures Developed By Mohammed Alliheedi Robert Mercer Version 1 April 14th, 2018 1- Introduction and background information What is rhetorical move? A rhetorical move can be defined as a text fragment that conveys a distinct communicative goal, in other words, a sentence that implies an author’s specific purpose to readers. What are the types of rhetorical moves? There are several types of rhetorical moves. However, we are interested in 4 rhetorical moves that are common in the method section of a scientific article that follows the Introduction Methods Results and Discussion (IMRaD) structure. 1- Description of a method: It is concerned with a sentence(s) that describes experimental events (e.g., “Beads with bound proteins were washed six times (for 10 min under rotation at 4°C) with pulldown buffer and proteins harvested in SDS-sample buffer, separated by SDS-PAGE, and analyzed by autoradiography.” (Ester & Uetz, 2008)). 2- Appeal to authority: It is concerned with a sentence(s) that discusses the use of standard methods, protocols, and procedures. There are two types of this move: - A reference to a well-established “standard” method (e.g., the use of a method like “PCR” or “electrophoresis”). - A reference to a method that was previously described in the literature (e.g., “Protein was determined using fluorescamine assay [41].” (Larsen, Frandesn and Treiman, 2001)). 3- Source of materials: It is concerned with a sentence(s) that lists the source of biological materials that are used in the experiment (e.g., “All microalgal strains used in this study are available at the Elizabeth Aidar Microalgae Culture Collection, Department of Marine Biology, Federal Fluminense University, Brazil.” (Larsen, Frandesn and Treiman, 2001)). -

Structure of Pigment Metabolic Pathways and Their Contributions to White Tepal Color Formation of Chinese Narcissus Tazetta Var
International Journal of Molecular Sciences Article Structure of Pigment Metabolic Pathways and Their Contributions to White Tepal Color Formation of Chinese Narcissus tazetta var. chinensis cv Jinzhanyintai Yujun Ren † ID , Jingwen Yang †, Bingguo Lu, Yaping Jiang, Haiyang Chen, Yuwei Hong, Binghua Wu and Ying Miao * Center for Molecular Cell and Systems Biology, Fujian Provincial Key Laboratory of Haixia Applied Plant Systems Biology, College of Life Sciences, Fujian Agriculture and Forestry University, Fuzhou 350002, China; [email protected] (Y.R.); [email protected] (J.Y.); [email protected] (B.L.); [email protected] (Y.J.); [email protected] (H.C.); [email protected] (Y.H.); [email protected] (B.W.) * Correspondence: [email protected]; Tel.:/Fax: +86-591-8639-2987 † These authors contributed equally to this work. Received: 7 August 2017; Accepted: 4 September 2017; Published: 8 September 2017 Abstract: Chinese narcissus (Narcissus tazetta var. chinensis) is one of the ten traditional flowers in China and a famous bulb flower in the world flower market. However, only white color tepals are formed in mature flowers of the cultivated varieties, which constrains their applicable occasions. Unfortunately, for lack of genome information of narcissus species, the explanation of tepal color formation of Chinese narcissus is still not clear. Concerning no genome information, the application of transcriptome profile to dissect biological phenomena in plants was reported to be effective. As known, pigments are metabolites of related metabolic pathways, which dominantly decide flower color. In this study, transcriptome profile and pigment metabolite analysis methods were used in the most widely cultivated Chinese narcissus “Jinzhanyintai” to discover the structure of pigment metabolic pathways and their contributions to white tepal color formation during flower development and pigmentation processes.