Operating System
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Comparing UNIX with Other Systems
Comparing UNIX with other systems Timothy DO' Chase Corporate Computer systems, Inc. 33 West Main Street Holmdel, New Jersey he original concept behind this article was to make a grand comparison between UNIX Tand several other well known systems. This was to beall encompassing and packed with vital information summarized in neat charts, tables and graphs. As the work began, the realization settled in that this was not only difficult to do, but would result in a work so boring as to beincomprehensible. The reader, faced with such awealth ofinformation would be lost at best. Conclusions would be difficult to draw and, in short, the result would be worthless. Mtertearfully filling my waste basket with the initial efforts, I regrouped and began by as king myself why would anyone be interested in comparing UNIX with another operating system? There appears to be only two answers. First, one might hope to learn something about UNIX by analogy. IfI understand the file system on MPEN and someone tells me that UNIX is like that except for such and so, then I might be more quickly able to under stand UNIX. This I felt was an unlikely motivation. After all, there are much simpler ways to learn UNIX. Instead, the motivation for comparing UNIX to other systems must come from a need to evaluate UNIX. Ifwe are aware of the features or short comings ofother systems, then we can benefit by evaluating UNIX relative to those systems. Choosing an operating system or computer is a major decision which we can benefit from or be stuck with for a long time. -

Pre-Award Documentation for Solicitation No. RS-AED
QYc o Qi&cx5Scm QSCIENTECH Cost Proposal To United States Nuclear Regulatory Commission For Revised Request for Proposal (RFP) No. RS-AED-00-300 Emergency Response Data System (ERDS) Maintenance 2000 - 2003, Plus Two Optional Years Revision 0 SCIENTECH Proposal Number 99000-0001-055 January 3, 2000 This proposal or quotation includes data that shall not be disclosed outside the U. S. Nuclear Regulatory Commission or the Government and shall not be duplicated, used, or disclosed--in whole or in part--for any purpose other than to evaluate this proposal or quotation. If, however, a contract is awarded to this Offeror or quoter as a result of--or in connection with-the submission of this data, the NRC and the Government shall have the right to duplicate, use, or disclose the data to the extent provided in the resulting contract This restriction does not limit the NRC's or the Government's right to use information contained in this data if it is obtained from another source without restriction. The data subject to this restriction are contained in all sheets. SCIENTECH Inc., Proprietaryand Confidential ADM02 Template=ADM-008 OSCIENTetH. ERDS Maintenance, Rev. 0 TABLE OF CONTENTS Page 1. INTRODUCTION ....................................................................................................................................... 1 2. SF 1449 SOLICITATION/CONTRACT/ORDER FOR COMMERCIAL ITEMS ............................... 2 3. COST ESTIMATE BY CLIN ..................................................................................................... ...... 6 4. ORGANIZATIONAL CONFLICT OF INTEREST ............................................................................. 7 5. OFFEROR REPRESENTATIONS AND CERTIFICATIONS- COMMERCIAL ITEMS ................. 9 Attachment A SF 1449 Attachment B Offeror Representations and Certifications Attachment C SF 3881 SCIENTECH Inc., Proprietaryand Confidentialsubject to cover page disclosure OSCIENTECH* 1. Introduction SCIENTECH, Inc., is pleased to submit this Cost Proposal in response to U. -

E Memorandum 5% 7
E MEMORANDUM TO: DISTRIBUTION DATE: February 13, 1975 FROM: Dave Nelson DEPT: 11 Planning/Architecture EXT: 4509 LOC: ML5/8- 67 5% 7 SUBJ: PROPOSAL FOR PDP-11 1/0 ARCHITECTURE 'P I propose that the attached specification be adopted in future im n- tations of the PDP-11 architecture. For background information, reference is made to Section I (I/O Systems) and Section I1 (Interrupt System) of the 1/22/75 version of the PDP-11 Architectural Enhancement Strategy publication. Many discussions have been held with people in Software Engineering, Peripheral Engineering, Micro Products, Communications Engineering, Hardware Engineering, and R/D, all of whom have contributed in various ways. The attached document appears somewhat revolutionary in that some new terminology is introduced. I believe, however, that this terminology is necessary if we wish to realize the full potential of the approach and avoid some of the past mistakes. I'd appreciate whatever comments you have, and I'll be holding some de- sign review sessions shortly. Regards. DN:elb DIS TRIR UT I ON Phil Arnold Tom Fava Larry Portner Jega Arulpragasam Robin Frith Bob Puffer Vince Bastiani Lorrin Gale Maurice Richeson Gordon Belli Mike Garry A1 Ryder Jim Bell Andy Goldstein Grant Saviers Ron Brender John Holman Bill Strecker J.ack Burness John Hughes Steve Teicher Roger Cady Chuck Kaman Nate Teichholtz Dick Clayton Julius Marcus Mike Tomasic Skip Coombe Craig Mudge Pete van Roekens Dave Cutler Clay Neil Larry Wade Bruce Delagi Jim O'Loughlin Stu Wecker Bill Demmer Ralph Platz Garth Wolfendale PDP-11 I/O PHILOSOPHY Some discussion regarding the philosophy and intended direction of the PDP-11 is warranted as an introduction to the proposed concepts and their motivations. -

ETHERNET and the FIFTH GENERATION Gordon Bell Vice
THE ENGINEERING OF THE VAX-11 COMPUTING ENVIRONMENT The VAX-11 architectural design and implementation began in 1975 with the goals of a wide range of system sizes and different styles of use. While much of the implementation has been "as planned", various nodes (eg. computers, disk servers) and combined structures (eg. clusters) have evolved in response to the technology forces, user requirements and constraints. The future offers even more possibilities for interesting structures. ETHERNET AND THE FIFTH GENERATION Gordon Bell Vice President, Engineering Digital Equipment Corporation In the Fifth Computer Generation, a wide variety of computers will communicate with one another. No one argues about this. The concern is about how to do it and what form the computers will take. A standard communications language is the key. I believe Ethernet is this unifying key to the 5th computer generation because it interconnects all sizes and types of computers in a passive, tightly-coupled, high performance fashion, permiting the formation of local-area networks. HOW THE JAPANESE HAVE CONVERTED WORLD INDUSTRY INTO DISTRIBUTORSHIPS -- CONCERN NOW FOR SEMICONDUCTORS AND COMPUTERS Gordon Bell Vice President Digital Equipment Corporation Abstract We all must be impressed with the intense drive, technical and manufacturing ability of the Japanese. As an island with few natural resources, and only very bright, hard working people they have set about and accomplished the market domination of virtually all manufactured consumer goods and the components and processes to make these goods (i.e., vertical integration). Currently the U.S. has a dominant position in computers and semiconductors. However, there's no fundamental reason why the Japanese won't attain a basic goal to dominate these industries, given their history in other areas and helped by our governments. -

General Disclaimer One Or More of the Following Statements May Affect
General Disclaimer One or more of the Following Statements may affect this Document This document has been reproduced from the best copy furnished by the organizational source. It is being released in the interest of making available as much information as possible. This document may contain data, which exceeds the sheet parameters. It was furnished in this condition by the organizational source and is the best copy available. This document may contain tone-on-tone or color graphs, charts and/or pictures, which have been reproduced in black and white. This document is paginated as submitted by the original source. Portions of this document are not fully legible due to the historical nature of some of the material. However, it is the best reproduction available from the original submission. Produced by the NASA Center for Aerospace Information (CASI) TORY SERIES (NASA-TM-04792) MULTIM"SiLN MODULAR -2 1041 SPACECRAFT GRUUNU SUPPORT SCF'IWARE SYSTEM VIMSA;SSS) STATE-UF -TNE-A dT CCMPUTER SYST!,MS/ COMPATIBILITY STUDY (NASA) 08 N fiC A04/M F A01 Unclas 03/01 28397 ^llLTl^ISSIODULA^ACEC GROUND SUP T Sq^TVITARE SY (Mr1AS/G8.RS) STATE—OF—THE-ART ICOMPl1T SYSTEMS/COMPATIBILITY STUDY MAY 1 s f Canna► i iilk SOFTWARE ENGINEERING LABORATORY SERIES SEL-80-003 MULTRAISSION MODULAR SPACECRAFT GROUND SUPPORT SOFTWARE SYSTEM (MMS/GSSS) STATE-OF-THE-ART COMPUTER SYSTEMS/COMPATIBILITY STUDY MAY 1980 Goddard Space Flight Center FOREWORD The Software Engineering Laboratory (SEL) is an organization sponsored by the National Aeronautics and Space Administra- tion Goddard Space Flight Center (NASA/GSFC) and created for the purpose of investigating the effectiveness of software engineering technologies when applied to the development of applications software. -
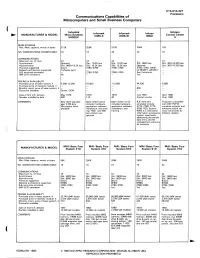
Communications Capabilities of Minicomputers and Small Business
C13-010-221 Processors Communications Capabilities of Minicomputers and Small Business Computers ( Industrial Infomark Infotecs Infomark Inforex Control Center MANUFACTURER & MODEL Micro Systems OMS-II OMS-III 9000 5000SX II MAIN STORAGE Min.lMax. capacity, words or bytes 512K 256K 512K 256K 1M NO. WORKSTATIONS CONNECTABLE 16 16 24 24 16 COMMUNICATIONS Maximum no. of lines 24 16 24 - 16 Synchronous Optional Opt.; 19.2K bps Opt.; 19.2K bps Std.; 9600 bps Std.; 300-19,200 bps Asynchronous Std.; 9600-19.2K bps Std.; 19.2K bps Std.; 19.2K bps Optional Std.; 300-19,200 bps Protocols supported Async 2780/3780 2780/3780 2780/3780, HASP, - Network architecture supported Turbodos (opt.) - - ULTRANET, ARCNET - RJE terminals emulated - 2780/3780 2780/3780 See Comments - IBM 3270 emulation No - - Yes - PRICING & AVAlLA81L1TY Purchase price of basic system, $ 3,000-12,000 67,000 113,300 44,630 6,995 Purchase price of memory module, $ - - - - - Monthly maint. price of basic system, $ - - - 800 - Discounts available Dealer, OEM - - - - Date of first U.S. delivery May 1979 1976 1976 July 1981 April 1980 Number installed to date 500 110 40 Contact vendor Over 1000 COMMENTS New table-top pack- 8asic system price 8asic system price RJE terminals Programs compatible age; 5.5M-byte includes hardware, includes hardware, emulated include with DEC PDP-8; Winchester drive application software application software, 2770, 2780, 3770, complete systems and available installation, and train- installation, and 3780, RES; System software sold & ser- ing; *600- and 900- training 9000 is a distributed viced nationwide by Ipm printers are information processing Infotecs' dealers optional system, specifically addressing distributed data entry and file management solutions for business MAli Basic Four MAl/Basic Four MAl/Basic Four MAli Basic Four MANUFACTURER & MODEL MAl/Basic Four System 210 System 310 System 510 System 610 System 710 MAIN STORAGE Min.lMax. -

Validated Products List, 1995 No. 2
A111D4 NISTIR 5629 (Supersedes NISTIR 5585) VALIDATED PRODUCTS LIST Volume 1 1995 No. 2 Programming Languages Database Language SQL Judy B. Kaiiey Graphics Editor POSIX U.S. DEPARTMENT OF COMMERCE Computer Security Technology Administration National Institute of Standards and Technology Computer Systems Laboratory Software Standards Validation Group Gaithersburg, MD 20899 April 1995 GC 100 NIST . U56 no. 5629 VI fi0.2 NISTIR 5629 (Supersedes NISTIR 5585) VALIDATED PRODUCTS LIST Volume 1 1995 No. 2 Programming Languages Database Language SQL Judy B. Kailey Graphics Editor POSIX U.S. DEPARTMENT OF COMMERCE Computer Security Technology Administration National Institute of Standards and Technology Computer Systems Laboratory Software Standards Validation Group Gaithersburg, MD 20899 April 1995 (Supersedes January 1995 issue) U.S. DEPARTMENT OF COMMERCE Ronald H. Brown, Secretary TECHNOLOGY ADMINISTRATION Mary L. Good, Under Secretary for Technology NATIONAL INSTITUTE OF STANDARDS AND TECHNOLOGY Arab Prabhakar, Director FOREWORD The Validated Products List (VPL) identifies information technology products that have been tested for conformance to Federal Information Processing Standards (FIPS) in accordance with Computer Systems Laboratory (CSL) conformance testing procedures, and have a current validation certificate or registered test report. The VPL also contains information about the organizations, test methods and procedures that support the validation programs for the FIPS identified in this document. The VPL includes computer language processors for programming languages COBOL, Fortran, Ada, Pascal, C, M[UMPS], and database language SQL; computer graphic implementations for GKS, CGM, PHIGS, and Raster Graphics; operating system implementations for POSIX; open systems interconnect implementations for GOSIP; and computer security implementations for DES, MAC and Key Management.