Line Segment Intersection
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Proofs with Perpendicular Lines
3.4 Proofs with Perpendicular Lines EEssentialssential QQuestionuestion What conjectures can you make about perpendicular lines? Writing Conjectures Work with a partner. Fold a piece of paper D in half twice. Label points on the two creases, as shown. a. Write a conjecture about AB— and CD — . Justify your conjecture. b. Write a conjecture about AO— and OB — . AOB Justify your conjecture. C Exploring a Segment Bisector Work with a partner. Fold and crease a piece A of paper, as shown. Label the ends of the crease as A and B. a. Fold the paper again so that point A coincides with point B. Crease the paper on that fold. b. Unfold the paper and examine the four angles formed by the two creases. What can you conclude about the four angles? B Writing a Conjecture CONSTRUCTING Work with a partner. VIABLE a. Draw AB — , as shown. A ARGUMENTS b. Draw an arc with center A on each To be prof cient in math, side of AB — . Using the same compass you need to make setting, draw an arc with center B conjectures and build a on each side of AB— . Label the C O D logical progression of intersections of the arcs C and D. statements to explore the c. Draw CD — . Label its intersection truth of your conjectures. — with AB as O. Write a conjecture B about the resulting diagram. Justify your conjecture. CCommunicateommunicate YourYour AnswerAnswer 4. What conjectures can you make about perpendicular lines? 5. In Exploration 3, f nd AO and OB when AB = 4 units. -

Some Intersection Theorems for Ordered Sets and Graphs
IOURNAL OF COMBINATORIAL THEORY, Series A 43, 23-37 (1986) Some Intersection Theorems for Ordered Sets and Graphs F. R. K. CHUNG* AND R. L. GRAHAM AT&T Bell Laboratories, Murray Hill, New Jersey 07974 and *Bell Communications Research, Morristown, New Jersey P. FRANKL C.N.R.S., Paris, France AND J. B. SHEARER' Universify of California, Berkeley, California Communicated by the Managing Editors Received May 22, 1984 A classical topic in combinatorics is the study of problems of the following type: What are the maximum families F of subsets of a finite set with the property that the intersection of any two sets in the family satisfies some specified condition? Typical restrictions on the intersections F n F of any F and F’ in F are: (i) FnF’# 0, where all FEF have k elements (Erdos, Ko, and Rado (1961)). (ii) IFn F’I > j (Katona (1964)). In this paper, we consider the following general question: For a given family B of subsets of [n] = { 1, 2,..., n}, what is the largest family F of subsets of [n] satsifying F,F’EF-FnFzB for some BE B. Of particular interest are those B for which the maximum families consist of so- called “kernel systems,” i.e., the family of all supersets of some fixed set in B. For example, we show that the set of all (cyclic) translates of a block of consecutive integers in [n] is such a family. It turns out rather unexpectedly that many of the results we obtain here depend strongly on properties of the well-known entropy function (from information theory). -

Sweeping the Sphere
Sweeping the Sphere Joao˜ Dinis Margarida Mamede Departamento de F´ısica CITI, Departamento de Informatica´ Faculdade de Ciencias,ˆ Universidade de Lisboa Faculdade de Cienciasˆ e Tecnologia, FCT Campo Grande, Edif´ıcio C8 Universidade Nova de Lisboa 1749-016 Lisboa, Portugal 2829-516 Caparica, Portugal [email protected] [email protected] Abstract—We introduce the first sweep line algorithm for and Hong [5], [6], which is O(n log n) worst case optimal, computing spherical Voronoi diagrams, which proves that where n is the number of sites. An asymptotically slower Fortune’s method can be extended to points on a sphere alternative in the worst case is the randomized incremental surface. This algorithm is similar to Fortune’s plane sweep algorithm, sweeping the sphere with a circular line instead of algorithm of Clarkson and Shor [7], whose expected running a straight one. time is O(n log n). The well-known Quickhull algorithm of Like its planar counterpart, the novel linear-space algorithm Barber et al. [8] can be seen as an efficient variation of the has worst-case optimal running time. Furthermore, it copes previous algorithm. very well with degeneracies and is easy to implement. Experi- A different approach is to adapt the randomized incremen- mental results show that the performance of our algorithm is very similar to that of Fortune’s algorithm, both with synthetic tal algorithm that computes the planar Delaunay triangula- data sets and with real data. tion [9], [10]. The essential operation used in the incremental The usual solutions make use of the connection between step, which checks if a circle defined by three sites contains a convex hulls and spherical Delaunay triangulations. -

Uwaterloo Latex Thesis Template
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by University of Waterloo's Institutional Repository Approximation Algorithms for Geometric Covering Problems for Disks and Squares by Nan Hu A thesis presented to the University of Waterloo in fulfillment of the thesis requirement for the degree of Master of Mathematics in Computer Science Waterloo, Ontario, Canada, 2013 c Nan Hu 2013 I hereby declare that I am the sole author of this thesis. This is a true copy of the thesis, including any required final revisions, as accepted by my examiners. I understand that my thesis may be made electronically available to the public. ii Abstract Geometric covering is a well-studied topic in computational geometry. We study three covering problems: Disjoint Unit-Disk Cover, Depth-(≤ K) Packing and Red-Blue Unit- Square Cover. In the Disjoint Unit-Disk Cover problem, we are given a point set and want to cover the maximum number of points using disjoint unit disks. We prove that the problem is NP-complete and give a polynomial-time approximation scheme (PTAS) for it. In Depth-(≤ K) Packing for Arbitrary-Size Disks/Squares, we are given a set of arbitrary-size disks/squares, and want to find a subset with depth at most K and maxi- mizing the total area. We prove a depth reduction theorem and present a PTAS. In Red-Blue Unit-Square Cover, we are given a red point set, a blue point set and a set of unit squares, and want to find a subset of unit squares to cover all the blue points and the minimum number of red points. -

Complete Intersection Dimension
PUBLICATIONS MATHÉMATIQUES DE L’I.H.É.S. LUCHEZAR L. AVRAMOV VESSELIN N. GASHAROV IRENA V. PEEVA Complete intersection dimension Publications mathématiques de l’I.H.É.S., tome 86 (1997), p. 67-114 <http://www.numdam.org/item?id=PMIHES_1997__86__67_0> © Publications mathématiques de l’I.H.É.S., 1997, tous droits réservés. L’accès aux archives de la revue « Publications mathématiques de l’I.H.É.S. » (http:// www.ihes.fr/IHES/Publications/Publications.html) implique l’accord avec les conditions géné- rales d’utilisation (http://www.numdam.org/conditions). Toute utilisation commerciale ou im- pression systématique est constitutive d’une infraction pénale. Toute copie ou impression de ce fichier doit contenir la présente mention de copyright. Article numérisé dans le cadre du programme Numérisation de documents anciens mathématiques http://www.numdam.org/ COMPLETE INTERSECTION DIMENSION by LUGHEZAR L. AVRAMOV, VESSELIN N. GASHAROV, and IRENA V. PEEVA (1) Abstract. A new homological invariant is introduced for a finite module over a commutative noetherian ring: its CI-dimension. In the local case, sharp quantitative and structural data are obtained for modules of finite CI- dimension, providing the first class of modules of (possibly) infinite projective dimension with a rich structure theory of free resolutions. CONTENTS Introduction ................................................................................ 67 1. Homological dimensions ................................................................... 70 2. Quantum regular sequences .............................................................. -
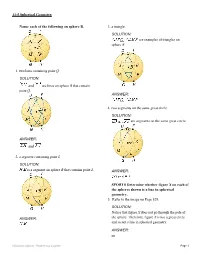
And Are Lines on Sphere B That Contain Point Q
11-5 Spherical Geometry Name each of the following on sphere B. 3. a triangle SOLUTION: are examples of triangles on sphere B. 1. two lines containing point Q SOLUTION: and are lines on sphere B that contain point Q. ANSWER: 4. two segments on the same great circle SOLUTION: are segments on the same great circle. ANSWER: and 2. a segment containing point L SOLUTION: is a segment on sphere B that contains point L. ANSWER: SPORTS Determine whether figure X on each of the spheres shown is a line in spherical geometry. 5. Refer to the image on Page 829. SOLUTION: Notice that figure X does not go through the pole of ANSWER: the sphere. Therefore, figure X is not a great circle and so not a line in spherical geometry. ANSWER: no eSolutions Manual - Powered by Cognero Page 1 11-5 Spherical Geometry 6. Refer to the image on Page 829. 8. Perpendicular lines intersect at one point. SOLUTION: SOLUTION: Notice that the figure X passes through the center of Perpendicular great circles intersect at two points. the ball and is a great circle, so it is a line in spherical geometry. ANSWER: yes ANSWER: PERSEVERANC Determine whether the Perpendicular great circles intersect at two points. following postulate or property of plane Euclidean geometry has a corresponding Name two lines containing point M, a segment statement in spherical geometry. If so, write the containing point S, and a triangle in each of the corresponding statement. If not, explain your following spheres. reasoning. 7. The points on any line or line segment can be put into one-to-one correspondence with real numbers. -

Intersection of Convex Objects in Two and Three Dimensions
Intersection of Convex Objects in Two and Three Dimensions B. CHAZELLE Yale University, New Haven, Connecticut AND D. P. DOBKIN Princeton University, Princeton, New Jersey Abstract. One of the basic geometric operations involves determining whether a pair of convex objects intersect. This problem is well understood in a model of computation in which the objects are given as input and their intersection is returned as output. For many applications, however, it may be assumed that the objects already exist within the computer and that the only output desired is a single piece of data giving a common point if the objects intersect or reporting no intersection if they are disjoint. For this problem, none of the previous lower bounds are valid and algorithms are proposed requiring sublinear time for their solution in two and three dimensions. Categories and Subject Descriptors: E.l [Data]: Data Structures; F.2.2 [Analysis of Algorithms]: Nonnumerical Algorithms and Problems General Terms: Algorithms, Theory, Verification Additional Key Words and Phrases: Convex sets, Fibonacci search, Intersection 1. Introduction This paper describes fast algorithms for testing the predicate, Do convex objects P and Q intersect? where an object is taken to be a line or a polygon in two dimensions or a plane or a polyhedron in three dimensions. The related problem Given convex objects P and Q, compute their intersection has been well studied, resulting in linear lower bounds and linear or quasi-linear upper bounds [2, 4, 11, 15-171. Lower bounds for this problem use arguments This research was supported in part by the National Science Foundation under grants MCS 79-03428, MCS 81-14207, MCS 83-03925, and MCS 83-03926, and by the Defense Advanced Project Agency under contract F33615-78-C-1551, monitored by the Air Force Offtce of Scientific Research. -

Visibility Graphs and Cell Decompositions
Visibility Graphs and Cell Decompositions CIS 390 Kostas Daniilidis With material from Chapter 5 - Roadmaps Principles of Robot Motion: Theory, Algorithms, and Implementation by Howie ChosetÂet al. The MIT Press © 2005 For polygonal obstacles in 2D • Assume robot is a point • Any shortest path from start to goal among a set of disjoint polygonal obstacles is a polygonal path whose inner vertices are convex vertices of the obstacles (imagine a tight rope from start to end) Visibility graph • Vertices: all vertices of the polygonal obstacles plus the start and the goal • Edges: all line segments between vertices that do not intersect obstacles • It is not a planar graph: edges are crossing (not at vertices) Visibility graph construction • Brute force O(n^3) algorithm visits – all n vertices – applies a rotational plane sweep that connects with all other n vertices – and determines whether each segment intersects any of the O(n) edges • We can do better by sorting the vertices. Sweep Line Algorithm • Input: A set of vertices {νi} (whose edges do not intersect) and a vertex ν • Output: A subset of vertices from {νi} that are within line of sight of ν • 1: For each vertex vi, calculate αi, the angle from the horizontal axis to the line segment • ννi. • 2: Create the vertex list E , containing the αi 's sorted in increasing order. • 3: Create the active list S, containing the sorted list of edges that intersect the horizontal • half-line emanating from ν. • 4: for all αi do • 5: if νi is visible to ν then • 6: Add the edge (ν, νi )to the visibility graph. -

Complex Intersection Bodies
COMPLEX INTERSECTION BODIES A. KOLDOBSKY, G. PAOURIS, AND M. ZYMONOPOULOU Abstract. We introduce complex intersection bodies and show that their properties and applications are similar to those of their real counterparts. In particular, we generalize Busemann's the- orem to the complex case by proving that complex intersection bodies of symmetric complex convex bodies are also convex. Other results include stability in the complex Busemann-Petty problem for arbitrary measures and the corresponding hyperplane inequal- ity for measures of complex intersection bodies. 1. Introduction The concept of an intersection body was introduced by Lutwak [37], as part of his dual Brunn-Minkowski theory. In particular, these bodies played an important role in the solution of the Busemann-Petty prob- lem. Many results on intersection bodies have appeared in recent years (see [10, 22, 34] and references there), but almost all of them apply to the real case. The goal of this paper is to extend the concept of an intersection body to the complex case. Let K and L be origin symmetric star bodies in Rn: Following [37], we say that K is the intersection body of L if the radius of K in every direction is equal to the volume of the central hyperplane section of L perpendicular to this direction, i.e. for every ξ 2 Sn−1; −1 ? kξkK = jL \ ξ j; (1) ? n where kxkK = minfa ≥ 0 : x 2 aKg, ξ = fx 2 R :(x; ξ) = 0g; and j · j stands for volume. By a theorem of Busemann [8] the intersection body of an origin symmetric convex body is also convex. -
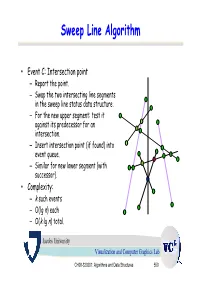
Sweep Line Algorithm
Sweep Line Algorithm • Event C: Intersection point – Report the point. – Swap the two intersecting line segments in the sweep line status data structure. – For the new upper segment: test it against its predecessor for an intersection. – Insert intersection point (if found) into event queue. – Similar for new lower segment (with successor). • Complexity: – k such events – O(lg n) each – O(k lg n) total. Jacobs University Visualization and Computer Graphics Lab CH08-320201: Algorithms and Data Structures 550 Example a3 b4 Sweep Line status: s3 e1 s4 s0, s1, s2, s3 Event Queue: a2 a4 b3 a4, b1, b2, b0, b3, b4 s2 b1 b0 s1 b2 s0 a1 a0 Jacobs University Visualization and Computer Graphics Lab CH08-320201: Algorithms and Data Structures 551 Example a3 b4 Actions: s3 Insert s4 to SLS e1 s4 Test s4-s3 and s4-s2. a2 a4 b3 Add e1 to EQ s2 b1 Sweep Line status: b0 s1 b2 s0, s1, s2, s4, s3 s0 a1 a0 Event Queue: b1, e1, b2, b0, b3, b4 Jacobs University Visualization and Computer Graphics Lab CH08-320201: Algorithms and Data Structures 552 Example a3 b4 Actions: s3 e1 s4 Delete s1 from SLS Test s0-s2. a2 a4 b3 Add e2 to EQ s2 Sweep Line status: e2 b0 b1 s1 b2 s0, s2, s4, s3 s0 a1 a0 Event Queue: e1, e2, b2, b0, b3, b4 Jacobs University Visualization and Computer Graphics Lab CH08-320201: Algorithms and Data Structures 553 Example a3 b4 Actions: s3 e1 s4 Swap s3 and s4 in SLS Test s3-s2. -

Parallel Range, Segment and Rectangle Queries with Augmented Maps
Parallel Range, Segment and Rectangle Queries with Augmented Maps Yihan Sun Guy E. Blelloch Carnegie Mellon University Carnegie Mellon University [email protected] [email protected] Abstract The range, segment and rectangle query problems are fundamental problems in computational geometry, and have extensive applications in many domains. Despite the significant theoretical work on these problems, efficient implementations can be complicated. We know of very few practical implementations of the algorithms in parallel, and most implementations do not have tight theoretical bounds. In this paper, we focus on simple and efficient parallel algorithms and implementations for range, segment and rectangle queries, which have tight worst-case bound in theory and good parallel performance in practice. We propose to use a simple framework (the augmented map) to model the problem. Based on the augmented map interface, we develop both multi-level tree structures and sweepline algorithms supporting range, segment and rectangle queries in two dimensions. For the sweepline algorithms, we also propose a parallel paradigm and show corresponding cost bounds. All of our data structures are work-efficient to build in theory (O(n log n) sequential work) and achieve a low parallel depth (polylogarithmic for the multi-level tree structures, and O(n) for sweepline algorithms). The query time is almost linear to the output size. We have implemented all the data structures described in the paper using a parallel augmented map library. Based on the library each data structure only requires about 100 lines of C++ code. We test their performance on large data sets (up to 108 elements) and a machine with 72-cores (144 hyperthreads). -

Points, Lines, and Planes a Point Is a Position in Space. a Point Has No Length Or Width Or Thickness
Points, Lines, and Planes A Point is a position in space. A point has no length or width or thickness. A point in geometry is represented by a dot. To name a point, we usually use a (capital) letter. A A (straight) line has length but no width or thickness. A line is understood to extend indefinitely to both sides. It does not have a beginning or end. A B C D A line consists of infinitely many points. The four points A, B, C, D are all on the same line. Postulate: Two points determine a line. We name a line by using any two points on the line, so the above line can be named as any of the following: ! ! ! ! ! AB BC AC AD CD Any three or more points that are on the same line are called colinear points. In the above, points A; B; C; D are all colinear. A Ray is part of a line that has a beginning point, and extends indefinitely to one direction. A B C D A ray is named by using its beginning point with another point it contains. −! −! −−! −−! In the above, ray AB is the same ray as AC or AD. But ray BD is not the same −−! ray as AD. A (line) segment is a finite part of a line between two points, called its end points. A segment has a finite length. A B C D B C In the above, segment AD is not the same as segment BC Segment Addition Postulate: In a line segment, if points A; B; C are colinear and point B is between point A and point C, then AB + BC = AC You may look at the plus sign, +, as adding the length of the segments as numbers.