(Tree Structure) Hierarchical Model in DBMS
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
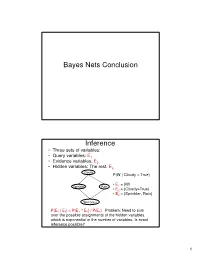
Bayes Nets Conclusion Inference
Bayes Nets Conclusion Inference • Three sets of variables: • Query variables: E1 • Evidence variables: E2 • Hidden variables: The rest, E3 Cloudy P(W | Cloudy = True) • E = {W} Sprinkler Rain 1 • E2 = {Cloudy=True} • E3 = {Sprinkler, Rain} Wet Grass P(E 1 | E 2) = P(E 1 ^ E 2) / P(E 2) Problem: Need to sum over the possible assignments of the hidden variables, which is exponential in the number of variables. Is exact inference possible? 1 A Simple Case A B C D • Suppose that we want to compute P(D = d) from this network. A Simple Case A B C D • Compute P(D = d) by summing the joint probability over all possible values of the remaining variables A, B, and C: P(D === d) === ∑∑∑ P(A === a, B === b,C === c, D === d) a,b,c 2 A Simple Case A B C D • Decompose the joint by using the fact that it is the product of terms of the form: P(X | Parents(X)) P(D === d) === ∑∑∑ P(D === d | C === c)P(C === c | B === b)P(B === b | A === a)P(A === a) a,b,c A Simple Case A B C D • We can avoid computing the sum for all possible triplets ( A,B,C) by distributing the sums inside the product P(D === d) === ∑∑∑ P(D === d | C === c)∑∑∑P(C === c | B === b)∑∑∑P(B === b| A === a)P(A === a) c b a 3 A Simple Case A B C D This term depends only on B and can be written as a 2- valued function fA(b) P(D === d) === ∑∑∑ P(D === d | C === c)∑∑∑P(C === c | B === b)∑∑∑P(B === b| A === a)P(A === a) c b a A Simple Case A B C D This term depends only on c and can be written as a 2- valued function fB(c) === === === === === === P(D d) ∑∑∑ P(D d | C c)∑∑∑P(C c | B b)f A(b) c b …. -

Balanced Trees Part One
Balanced Trees Part One Balanced Trees ● Balanced search trees are among the most useful and versatile data structures. ● Many programming languages ship with a balanced tree library. ● C++: std::map / std::set ● Java: TreeMap / TreeSet ● Many advanced data structures are layered on top of balanced trees. ● We’ll see several later in the quarter! Where We're Going ● B-Trees (Today) ● A simple type of balanced tree developed for block storage. ● Red/Black Trees (Today/Thursday) ● The canonical balanced binary search tree. ● Augmented Search Trees (Thursday) ● Adding extra information to balanced trees to supercharge the data structure. Outline for Today ● BST Review ● Refresher on basic BST concepts and runtimes. ● Overview of Red/Black Trees ● What we're building toward. ● B-Trees and 2-3-4 Trees ● Simple balanced trees, in depth. ● Intuiting Red/Black Trees ● A much better feel for red/black trees. A Quick BST Review Binary Search Trees ● A binary search tree is a binary tree with 9 the following properties: 5 13 ● Each node in the BST stores a key, and 1 6 10 14 optionally, some auxiliary information. 3 7 11 15 ● The key of every node in a BST is strictly greater than all keys 2 4 8 12 to its left and strictly smaller than all keys to its right. Binary Search Trees ● The height of a binary search tree is the 9 length of the longest path from the root to a 5 13 leaf, measured in the number of edges. 1 6 10 14 ● A tree with one node has height 0. -

Trees: Binary Search Trees
COMP2012H Spring 2014 Dekai Wu Binary Trees & Binary Search Trees (data structures for the dictionary ADT) Outline } Binary tree terminology } Tree traversals: preorder, inorder and postorder } Dictionary and binary search tree } Binary search tree operations } Search } min and max } Successor } Insertion } Deletion } Tree balancing issue COMP2012H (BST) Binary Tree Terminology } Go to the supplementary notes COMP2012H (BST) Linked Representation of Binary Trees } The degree of a node is the number of children it has. The degree of a tree is the maximum of its element degree. } In a binary tree, the tree degree is two data } Each node has two links left right } one to the left child of the node } one to the right child of the node Left child Right child } if no child node exists for a node, the link is set to NULL root 32 32 79 42 79 42 / 13 95 16 13 95 16 / / / / / / COMP2012H (BST) Binary Trees as Recursive Data Structures } A binary tree is either empty … Anchor or } Consists of a node called the root } Root points to two disjoint binary (sub)trees Inductive step left and right (sub)tree r left right subtree subtree COMP2012H (BST) Tree Traversal is Also Recursive (Preorder example) If the binary tree is empty then Anchor do nothing Else N: Visit the root, process data L: Traverse the left subtree Inductive/Recursive step R: Traverse the right subtree COMP2012H (BST) 3 Types of Tree Traversal } If the pointer to the node is not NULL: } Preorder: Node, Left subtree, Right subtree } Inorder: Left subtree, Node, Right subtree Inductive/Recursive step } Postorder: Left subtree, Right subtree, Node template <class T> void BinaryTree<T>::InOrder( void(*Visit)(BinaryTreeNode<T> *u), template<class T> BinaryTreeNode<T> *t) void BinaryTree<T>::PreOrder( {// Inorder traversal. -

Q-Tree: a Multi-Attribute Based Range Query Solution for Tele-Immersive Framework
Q-Tree: A Multi-Attribute Based Range Query Solution for Tele-Immersive Framework Md Ahsan Arefin, Md Yusuf Sarwar Uddin, Indranil Gupta, Klara Nahrstedt Department of Computer Science University of Illinois at Urbana Champaign Illinois, USA {marefin2, mduddin2, indy, klara}@illinois.edu Abstract given in a high level description which are transformed into multi-attribute composite range queries. Some of the Users and administrators of large distributed systems are examples include “which site is highly congested?”, “which frequently in need of monitoring and management of its components are not working properly?” etc. To answer the various components, data items and resources. Though there first one, the query is transformed into a multi-attribute exist several distributed query and aggregation systems, the composite range query with constrains (range of values) on clustered structure of tele-immersive interactive frameworks CPU utilization, memory overhead, stream rate, bandwidth and their time-sensitive nature and application requirements utilization, delay and packet loss rate. The later one can represent a new class of systems which poses different chal- be answered by constructing a multi-attribute range query lenges on this distributed search. Multi-attribute composite with constrains on static and dynamic characteristics of range queries are one of the key features in this class. those components. Queries can also be made by defining Queries are given in high level descriptions and then trans- different multi-attribute ranges explicitly. Another mention- formed into multi-attribute composite range queries. Design- able property of such systems is that the number of site is ing such a query engine with minimum traffic overhead, low limited due to limited display space and limited interactions, service latency, and with static and dynamic nature of large but the number of data items to store and manage can datasets, is a challenging task. -

Tree Structures
Tree Structures Definitions: o A tree is a connected acyclic graph. o A disconnected acyclic graph is called a forest o A tree is a connected digraph with these properties: . There is exactly one node (Root) with in-degree=0 . All other nodes have in-degree=1 . A leaf is a node with out-degree=0 . There is exactly one path from the root to any leaf o The degree of a tree is the maximum out-degree of the nodes in the tree. o If (X,Y) is a path: X is an ancestor of Y, and Y is a descendant of X. Root X Y CSci 1112 – Algorithms and Data Structures, A. Bellaachia Page 1 Level of a node: Level 0 or 1 1 or 2 2 or 3 3 or 4 Height or depth: o The depth of a node is the number of edges from the root to the node. o The root node has depth zero o The height of a node is the number of edges from the node to the deepest leaf. o The height of a tree is a height of the root. o The height of the root is the height of the tree o Leaf nodes have height zero o A tree with only a single node (hence both a root and leaf) has depth and height zero. o An empty tree (tree with no nodes) has depth and height −1. o It is the maximum level of any node in the tree. CSci 1112 – Algorithms and Data Structures, A. -

A Simple Linear-Time Algorithm for Finding Path-Decompostions of Small Width
Introduction Preliminary Definitions Pathwidth Algorithm Summary A Simple Linear-Time Algorithm for Finding Path-Decompostions of Small Width Kevin Cattell Michael J. Dinneen Michael R. Fellows Department of Computer Science University of Victoria Victoria, B.C. Canada V8W 3P6 Information Processing Letters 57 (1996) 197–203 Kevin Cattell, Michael J. Dinneen, Michael R. Fellows Linear-Time Path-Decomposition Algorithm Introduction Preliminary Definitions Pathwidth Algorithm Summary Outline 1 Introduction Motivation History 2 Preliminary Definitions Boundaried graphs Path-decompositions Topological tree obstructions 3 Pathwidth Algorithm Main result Linear-time algorithm Proof of correctness Other results Kevin Cattell, Michael J. Dinneen, Michael R. Fellows Linear-Time Path-Decomposition Algorithm Introduction Preliminary Definitions Motivation Pathwidth Algorithm History Summary Motivation Pathwidth is related to several VLSI layout problems: vertex separation link gate matrix layout edge search number ... Usefullness of bounded treewidth in: study of graph minors (Robertson and Seymour) input restrictions for many NP-complete problems (fixed-parameter complexity) Kevin Cattell, Michael J. Dinneen, Michael R. Fellows Linear-Time Path-Decomposition Algorithm Introduction Preliminary Definitions Motivation Pathwidth Algorithm History Summary History General problem(s) is NP-complete Input: Graph G, integer t Question: Is tree/path-width(G) ≤ t? Algorithmic development (fixed t): O(n2) nonconstructive treewidth algorithm by Robertson and Seymour (1986) O(nt+2) treewidth algorithm due to Arnberg, Corneil and Proskurowski (1987) O(n log n) treewidth algorithm due to Reed (1992) 2 O(2t n) treewidth algorithm due to Bodlaender (1993) O(n log2 n) pathwidth algorithm due to Ellis, Sudborough and Turner (1994) Kevin Cattell, Michael J. Dinneen, Michael R. -
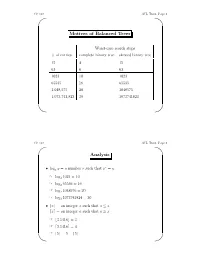
AVL Trees, Page 1 ' $
CS 310 AVL Trees, Page 1 ' $ Motives of Balanced Trees Worst-case search steps #ofentries complete binary tree skewed binary tree 15 4 15 63 6 63 1023 10 1023 65535 16 65535 1,048,575 20 1048575 1,073,741,823 30 1073741823 & % CS 310 AVL Trees, Page 2 ' $ Analysis r • logx y =anumberr such that x = y ☞ log2 1024 = 10 ☞ log2 65536 = 16 ☞ log2 1048576 = 20 ☞ log2 1073741824 = 30 •bxc = an integer a such that a ≤ x dxe = an integer a such that a ≥ x ☞ b3.1416c =3 ☞ d3.1416e =4 ☞ b5c =5=d5e & % CS 310 AVL Trees, Page 3 ' $ • If a binary search tree of N nodes happens to be complete, then a search in the tree requires at most b c log2 N +1 steps. • Big-O notation: We say f(x)=O(g(x)) if f(x)isbounded by c · g(x), where c is a constant, for sufficiently large x. ☞ x2 +11x − 30 = O(x2) (consider c =2,x ≥ 6) ☞ x100 + x50 +2x = O(2x) • If a BST happens to be complete, then a search in the tree requires O(log2 N)steps. • In a linked list of N nodes, a search requires O(N)steps. & % CS 310 AVL Trees, Page 4 ' $ AVL Trees • A balanced binary search tree structure proposed by Adelson, Velksii and Landis in 1962. • In an AVL tree of N nodes, every searching, deletion or insertion operation requires only O(log2 N)steps. • AVL tree searching is exactly the same as that of the binary search tree. & % CS 310 AVL Trees, Page 5 ' $ Definition • An empty tree is balanced. -

Basics of Social Network Analysis Distribute Or
1 Basics of Social Network Analysis distribute or post, copy, not Do Copyright ©2017 by SAGE Publications, Inc. This work may not be reproduced or distributed in any form or by any means without express written permission of the publisher. Chapter 1 Basics of Social Network Analysis 3 Learning Objectives zz Describe basic concepts in social network analysis (SNA) such as nodes, actors, and ties or relations zz Identify different types of social networks, such as directed or undirected, binary or valued, and bipartite or one-mode zz Assess research designs in social network research, and distinguish sampling units, relational forms and contents, and levels of analysis zz Identify network actors at different levels of analysis (e.g., individuals or aggregate units) when reading social network literature zz Describe bipartite networks, know when to use them, and what their advan- tages are zz Explain the three theoretical assumptions that undergird social networkdistribute studies zz Discuss problems of causality in social network analysis, and suggest methods to establish causality in network studies or 1.1 Introduction The term “social network” entered everyday language with the advent of the Internet. As a result, most people will connect the term with the Internet and social media platforms, but it has in fact a much broaderpost, application, as we will see shortly. Still, pictures like Figure 1.1 are what most people will think of when they hear the word “social network”: thousands of points connected to each other. In this particular case, the points represent political blogs in the United States (grey ones are Republican, and dark grey ones are Democrat), the ties indicating hyperlinks between them. -

7. Hierarchies & Trees Visualizing Topological Relations
7. Hierarchies & Trees Visualizing topological relations Vorlesung „Informationsvisualisierung” Prof. Dr. Andreas Butz, WS 2011/12 Konzept und Basis für Folien: Thorsten Büring LMU München – Medieninformatik – Andreas Butz – Informationsvisualisierung – WS2011/12 Folie 1 Outline • Hierarchical data and tree representations • 2D Node-link diagrams – Hyperbolic Tree Browser – SpaceTree – Cheops – Degree of interest tree – 3D Node-link diagrams • Enclosure – Treemap – Ordererd Treemaps – Various examples – Voronoi treemap – 3D Treemaps • Circular visualizations • Space-filling node-link diagram LMU München – Medieninformatik – Andreas Butz – Informationsvisualisierung – WS2011/12 Folie 2 Hierarchical Data • Card et al. 1999: data repository in which data cases are related to subcases • Many data collections have an inherent hierarchical organization – Organizational Charts – Websites (approximately hierarchical) Yee et al. 2001 – File system – Family tree – OO programming • Hierarchies are usually represented as tree visual structures • Trees tend to be easier to lay out and interpret than networks (e.g. no cycles) • But: as shown in the example, networks may in some cases be visualized as a tree LMU München – Medieninformatik – Andreas Butz – Informationsvisualisierung – WS2011/12 Folie 3 Tree Representations • Two kinds of representations • Node-link diagram (see previous lecture): represent connections as edges between vertices (data cases) http://www.icann.org • Enclosure: space-filling approaches by visually nesting the hierarchy LMU -

English Knowledge Base Category Hierarchy
J English Knowledge Base Category Hierarchy This document provides a list of all the concepts in the knowledge base that serve as categories. This document divided into six sections, corresponding to the six main branches of the knowledge base: ■ Branch 1: science and technology ■ Branch 2: business and economics ■ Branch 3: government and military ■ Branch 4: social environment ■ Branch 5: geography ■ Branch 6: abstract ideas and concepts The categories are presented in an inverted-tree hierarchy and within each category, sub-categories are listed in alphabetical order. Note: This document does not contain all the concepts found in the knowledge base. It only contains those concepts that serve as categories (meaning they are parent nodes in the hierarchy). English Knowledge Base Category Hierarchy J-1 Branch 1: science and technology Branch 1: science and technology [1] communications [2] journalism [3] broadcast journalism [3] photojournalism [3] print journalism [4] newspapers [2] public speaking [2] publishing industry [3] desktop publishing [3] periodicals [4] business publications [3] printing [2] telecommunications industry [3] computer networking [4] Internet technology [5] Internet providers [5] Web browsers [5] search engines [3] data transmission [3] fiber optics [3] telephone service [1] formal education [2] colleges and universities [3] academic degrees [3] business education [2] curricula and methods [2] library science [2] reference books [2] schools [2] teachers and students [1] hard sciences [2] aerospace industry [3] -

Lowest Common Ancestors in Trees and Directed Acyclic Graphs1
Lowest Common Ancestors in Trees and Directed Acyclic Graphs1 Michael A. Bender2 3 Martín Farach-Colton4 Giridhar Pemmasani2 Steven Skiena2 5 Pavel Sumazin6 Version: We study the problem of finding lowest common ancestors (LCA) in trees and directed acyclic graphs (DAGs). Specifically, we extend the LCA problem to DAGs and study the LCA variants that arise in this general setting. We begin with a clear exposition of Berkman and Vishkin’s simple optimal algorithm for LCA in trees. The ideas presented are not novel theoretical contributions, but they lay the foundation for our work on LCA problems in DAGs. We present an algorithm that finds all-pairs-representative : LCA in DAGs in O~(n2 688 ) operations, provide a transitive-closure lower bound for the all-pairs-representative-LCA problem, and develop an LCA-existence algorithm that preprocesses the DAG in transitive-closure time. We also present a suboptimal but practical O(n3) algorithm for all-pairs-representative LCA in DAGs that uses ideas from the optimal algorithms in trees and DAGs. Our results reveal a close relationship between the LCA, all-pairs-shortest-path, and transitive-closure problems. We conclude the paper with a short experimental study of LCA algorithms in trees and DAGs. Our experiments and source code demonstrate the elegance of the preprocessing-query algorithms for LCA in trees. We show that for most trees the suboptimal Θ(n log n)-preprocessing Θ(1)-query algorithm should be preferred, and demonstrate that our proposed O(n3) algorithm for all- pairs-representative LCA in DAGs performs well in both low and high density DAGs. -

Mechanistic Hierarchy Realism and Function Perspectivalism
1 Mechanistic Hierarchy Realism and Function Perspectivalism Abstract Mechanistic explanation involves the attribution of functions to both mechanisms and their component parts, and function attribution plays a central role in the individuation of mechanisms. Our aim in this paper is to investigate the impact of a perspectival view of function attribution for the broader mechanist project, and specifically for realism about mechanistic hierarchies. We argue that, contrary to the claims of function perspectivalists such as Craver, one cannot endorse both function perspectivalism and mechanistic hierarchy realism: if functions are perspectival, then so are the levels of a mechanistic hierarchy. We illustrate this argument with an example from recent neuroscience, where the mechanism responsible for the phenomenon of ephaptic coupling cross-cuts (in a hierarchical sense) the more familiar mechanism for synaptic firing. Finally, we consider what kind of structure there is left to be realist about for the function perspectivalist. 1. Introduction Mechanistic explanation has emerged as the dominant account of explanation across much of philosophy of science, especially for cognitive neuroscience, biology, and chemistry. This account suggests that to explain a phenomenon is to offer a mechanism that produces it. Crucially, for many mechanists, mechanisms differ from models and other idealized, counterfactual, or instrumental constructs of science, in that mechanisms are actual parts of the world. Models, diagrams, simulations, or other descriptions may represent a mechanism, but the mechanism itself comprises a real structure, independent of our aims and interests, and this real structure plays an explanatory role (either constitutively, for ontic mechanists, or 2 by reference, for epistemic mechanists – we will return to this point later).