Designing, Implementing, and Analyzing a System for Virus Detection
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Statistical Structures: Fingerprinting Malware for Classification and Analysis
Statistical Structures: Fingerprinting Malware for Classification and Analysis Daniel Bilar Wellesley College (Wellesley, MA) Colby College (Waterville, ME) bilar <at> alum dot dartmouth dot org Why Structural Fingerprinting? Goal: Identifying and classifying malware Problem: For any single fingerprint, balance between over-fitting (type II error) and under- fitting (type I error) hard to achieve Approach: View binaries simultaneously from different structural perspectives and perform statistical analysis on these ‘structural fingerprints’ Different Perspectives Idea: Multiple perspectives may increase likelihood of correct identification and classification Structural Description Statistical static / Perspective Fingerprint dynamic? Assembly Count different Opcode Primarily instruction instructions frequency static distribution Win 32 API Observe API calls API call vector Primarily call made dynamic System Explore graph- Graph structural Primarily Dependence modeled control and properties static Graph data dependencies Fingerprint: Opcode frequency distribution Synopsis: Statically disassemble the binary, tabulate the opcode frequencies and construct a statistical fingerprint with a subset of said opcodes. Goal: Compare opcode fingerprint across non- malicious software and malware classes for quick identification and classification purposes. Main result: ‘Rare’ opcodes explain more data variation then common ones Goodware: Opcode Distribution 1, 2 ---------.exe Procedure: -------.exe 1. Inventoried PEs (EXE, DLL, ---------.exe etc) on XP box with Advanced Disk Catalog 2. Chose random EXE samples size: 122880 with MS Excel and Index totalopcodes: 10680 3, 4 your Files compiler: MS Visual C++ 6.0 3. Ran IDA with modified class: utility (process) InstructionCounter plugin on sample PEs 0001. 002145 20.08% mov 4. Augmented IDA output files 0002. 001859 17.41% push with PEID results (compiler) 0003. 000760 7.12% call and general ‘functionality 0004. -

A the Hacker
A The Hacker Madame Curie once said “En science, nous devons nous int´eresser aux choses, non aux personnes [In science, we should be interested in things, not in people].” Things, however, have since changed, and today we have to be interested not just in the facts of computer security and crime, but in the people who perpetrate these acts. Hence this discussion of hackers. Over the centuries, the term “hacker” has referred to various activities. We are familiar with usages such as “a carpenter hacking wood with an ax” and “a butcher hacking meat with a cleaver,” but it seems that the modern, computer-related form of this term originated in the many pranks and practi- cal jokes perpetrated by students at MIT in the 1960s. As an example of the many meanings assigned to this term, see [Schneier 04] which, among much other information, explains why Galileo was a hacker but Aristotle wasn’t. A hack is a person lacking talent or ability, as in a “hack writer.” Hack as a verb is used in contexts such as “hack the media,” “hack your brain,” and “hack your reputation.” Recently, it has also come to mean either a kludge, or the opposite of a kludge, as in a clever or elegant solution to a difficult problem. A hack also means a simple but often inelegant solution or technique. The following tentative definitions are quoted from the jargon file ([jargon 04], edited by Eric S. Raymond): 1. A person who enjoys exploring the details of programmable systems and how to stretch their capabilities, as opposed to most users, who prefer to learn only the minimum necessary. -

Synthesizing Near-Optimal Malware Specifications from Suspicious
Synthesizing Near-Optimal Malware Specifications from Suspicious Behaviors Somesh Jha∗, Matthew Fredrikson∗, Mihai Christodoresu†, Reiner Sailer‡, Xifeng Yan§ ∗University of Wisconsin–Madison, †Qualcomm Research Silicon Valley, ‡IBM T.J Watson Research Center, §University of California–Santa Barbara Abstract—Behavior-based detection techniques are a promis- and errors. ing solution to the problem of malware proliferation. However, We make the observation that behavioral specifications they require precise specifications of malicious behavior that do not result in an excessive number of false alarms, while still are best viewed as a form of discriminative specification.A remaining general enough to detect new variants before tradi- discriminative specification describes the unique properties tional signatures can be created and distributed. In this paper, of a given class, in contrast to the properties exhibited by we present an automatic technique for extracting optimally discriminative specifications a second mutually-exclusive class. This paper presents an , which uniquely identify a class automated technique that combines program analysis, graph of programs. Such a discriminative specification can be used by a behavior-based malware detector. Our technique, based mining, and stochastic optimization to synthesize malware on graph mining and stochastic optimization, scales to large behavior specifications. We represent program behaviors as classes of programs. When this work was originally published, graphs that are mined for discriminative patterns. As there the technique yielded favorable results on malware targeted are many ways in which malware can accomplish the same towards workstations (~86% detection rates on new malware). goal, we use these patterns as building blocks for construct- We believe that it can be brought to bear on emerging malware- based threats for new platforms, and discuss several promising ing discriminative specifications that are general across vari- avenues for future work in this direction. -

Cyber Warfare a “Nuclear Option”?
CYBER WARFARE A “NUCLEAR OPTION”? ANDREW F. KREPINEVICH CYBER WARFARE: A “NUCLEAR OPTION”? BY ANDREW KREPINEVICH 2012 © 2012 Center for Strategic and Budgetary Assessments. All rights reserved. About the Center for Strategic and Budgetary Assessments The Center for Strategic and Budgetary Assessments (CSBA) is an independent, nonpartisan policy research institute established to promote innovative thinking and debate about national security strategy and investment options. CSBA’s goal is to enable policymakers to make informed decisions on matters of strategy, secu- rity policy and resource allocation. CSBA provides timely, impartial, and insight- ful analyses to senior decision makers in the executive and legislative branches, as well as to the media and the broader national security community. CSBA encour- ages thoughtful participation in the development of national security strategy and policy, and in the allocation of scarce human and capital resources. CSBA’s analysis and outreach focus on key questions related to existing and emerging threats to US national security. Meeting these challenges will require transforming the national security establishment, and we are devoted to helping achieve this end. About the Author Dr. Andrew F. Krepinevich, Jr. is the President of the Center for Strategic and Budgetary Assessments, which he joined following a 21-year career in the U.S. Army. He has served in the Department of Defense’s Office of Net Assessment, on the personal staff of three secretaries of defense, the National Defense Panel, the Defense Science Board Task Force on Joint Experimentation, and the Defense Policy Board. He is the author of 7 Deadly Scenarios: A Military Futurist Explores War in the 21st Century and The Army and Vietnam. -

Impact of Viral Marketing in India
www.ijemr.net ISSN (ONLINE): 2250-0758, ISSN (PRINT): 2394-6962 Volume-5, Issue-2, April-2015 International Journal of Engineering and Management Research Page Number: 653-659 Impact of Viral Marketing in India Ruchi Mantri1, Ankit Laddha2, Prachi Rathi3 1Researcher, INDIA 2Assistant Professor, Shri Vaishnav Institute of Management, Indore, INDIA 3Assistant Professor, Gujrati Innovative College of Commerce and Science, Indore, INDIA ABSTRACT the new ‘Mantra’ to open the treasure cave of business Viral marketing is a marketing technique in which success. In the recent past, viral marketing has created a lot an organisation, whether business or non-business of buzz and excitement all over the world including India. organisation, tries to persuade the internet users to forward The concept seems like ‘an ultimate free lunch’- rather a its publicity material in emails usually in the form of video great feast for all the modern marketers who choose small clips, text messages etc. to generate word of mouth. In the number of netizens to plant their new idea about the recent past, viral marketing technique has achieved increasing attention and acceptance all over the world product or activity of the organisation, get it viral and then including India. Zoozoo commercials by Vodafone, Kolaveri watch while it spreads quickly and effortlessly to millions Di song by South Indian actor Dhanush, Gangnam style of people. Zoozoo commercials of Vodafone, Kolaveri Di- dance by PSY, and Ice Bucket Challenge with a twister Rice the promotional song sung by South Indian actor Dhanush, Bucket Challenge created a buzz in Indian society. If certain Gangnam style dance by Korean dancer PSY, election pre-conditions are followed, viral marketing technique can be canvassing by Narendra Modi and Ice Bucket Challenge successfully used by marketers of business organisations. -

The Botnet Chronicles a Journey to Infamy
The Botnet Chronicles A Journey to Infamy Trend Micro, Incorporated Rik Ferguson Senior Security Advisor A Trend Micro White Paper I November 2010 The Botnet Chronicles A Journey to Infamy CONTENTS A Prelude to Evolution ....................................................................................................................4 The Botnet Saga Begins .................................................................................................................5 The Birth of Organized Crime .........................................................................................................7 The Security War Rages On ........................................................................................................... 8 Lost in the White Noise................................................................................................................. 10 Where Do We Go from Here? .......................................................................................................... 11 References ...................................................................................................................................... 12 2 WHITE PAPER I THE BOTNET CHRONICLES: A JOURNEY TO INFAMY The Botnet Chronicles A Journey to Infamy The botnet time line below shows a rundown of the botnets discussed in this white paper. Clicking each botnet’s name in blue will bring you to the page where it is described in more detail. To go back to the time line below from each page, click the ~ at the end of the section. 3 WHITE -

Flow-Level Traffic Analysis of the Blaster and Sobig Worm Outbreaks in an Internet Backbone
Flow-Level Traffic Analysis of the Blaster and Sobig Worm Outbreaks in an Internet Backbone Thomas Dübendorfer, Arno Wagner, Theus Hossmann, Bernhard Plattner ETH Zurich, Switzerland [email protected] DIMVA 2005, Wien, Austria Agenda 1) Introduction 2) Flow-Level Backbone Traffic 3) Network Worm Blaster.A 4) E-Mail Worm Sobig.F 5) Conclusions and Outlook © T. Dübendorfer (2005), TIK/CSG, ETH Zurich -2- 1) Introduction Authors Prof. Dr. Bernhard Plattner Professor, ETH Zurich (since 1988) Head of the Communication Systems Group at the Computer Engineering and Networks Laboratory TIK Prorector of education at ETH Zurich (since 2005) Thomas Dübendorfer Dipl. Informatik-Ing., ETH Zurich, Switzerland (2001) ISC2 CISSP (Certified Information System Security Professional) (2003) PhD student at TIK, ETH Zurich (since 2001) Network security research in the context of the DDoSVax project at ETH Further authors: Arno Wagner, Theus Hossmann © T. Dübendorfer (2005), TIK/CSG, ETH Zurich -3- 1) Introduction Worm Analysis Why analyse Internet worms? • basis for research and development of: • worm detection methods • effective countermeasures • understand network impact of worms Wasn‘t this already done by anti-virus software vendors? • Anti-virus software works with host-centric signatures Research method used 1. Execute worm code in an Internet-like testbed and observe infections 2. Measure packet-level traffic and determine network-centric worm signatures on flow-level 3. Extensive analysis of flow-level traffic of the actual worm outbreaks captured in a Swiss backbone © T. Dübendorfer (2005), TIK/CSG, ETH Zurich -4- 1) Introduction Related Work Internet backbone worm analyses: • Many theoretical worm spreading models and simulations exist (e.g. -
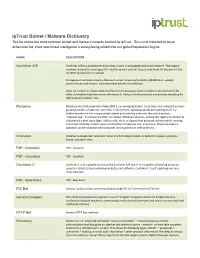
Iptrust Botnet / Malware Dictionary This List Shows the Most Common Botnet and Malware Variants Tracked by Iptrust
ipTrust Botnet / Malware Dictionary This list shows the most common botnet and malware variants tracked by ipTrust. This is not intended to be an exhaustive list, since new threat intelligence is always being added into our global Reputation Engine. NAME DESCRIPTION Conficker A/B Conficker A/B is a downloader worm that is used to propagate additional malware. The original malware it was after was rogue AV - but the army's current focus is undefined. At this point it has no other purpose but to spread. Propagation methods include a Microsoft server service vulnerability (MS08-067) - weakly protected network shares - and removable devices like USB keys. Once on a machine, it will attach itself to current processes such as explorer.exe and search for other vulnerable machines across the network. Using a list of passwords and actively searching for legitimate usernames - the ... Mariposa Mariposa was first observed in May 2009 as an emerging botnet. Since then it has infected an ever- growing number of systems; currently, in the millions. Mariposa works by installing itself in a hidden location on the compromised system and injecting code into the critical process ͞ĞdžƉůŽƌĞƌ͘ĞdžĞ͘͟/ƚŝƐknown to affect all modern Windows versions, editing the registry to allow it to automatically start upon login. Additionally, there is a guard that prevents deletion while running, and it automatically restarts upon crash/restart of explorer.exe. In essence, Mariposa opens a backdoor on the compromised computer, which grants full shell access to ... Unknown A botnet is designated 'unknown' when it is first being tracked, or before it is given a publicly- known common name. -

Common Threats to Cyber Security Part 1 of 2
Common Threats to Cyber Security Part 1 of 2 Table of Contents Malware .......................................................................................................................................... 2 Viruses ............................................................................................................................................. 3 Worms ............................................................................................................................................. 4 Downloaders ................................................................................................................................... 6 Attack Scripts .................................................................................................................................. 8 Botnet ........................................................................................................................................... 10 IRCBotnet Example ....................................................................................................................... 12 Trojans (Backdoor) ........................................................................................................................ 14 Denial of Service ........................................................................................................................... 18 Rootkits ......................................................................................................................................... 20 Notices ......................................................................................................................................... -

Computer Security Fundamentals Third Edition
Computer Security Fundamentals Third Edition Chuck Easttom 800 East 96th Street, Indianapolis, Indiana 46240 USA Computer Security Fundamentals, Third Edition Executive Editor Brett Bartow Copyright © 2016 by Pearson Education, Inc. All rights reserved. No part of this book shall be reproduced, stored in a retrieval system, or Acquisitions Editor transmitted by any means, electronic, mechanical, photocopying, recording, or otherwise, Betsy Brown without written permission from the publisher. No patent liability is assumed with respect Development Editor to the use of the information contained herein. Although every precaution has been taken in Christopher Cleveland the preparation of this book, the publisher and author assume no responsibility for errors or omissions. Nor is any liability assumed for damages resulting from the use of the information Managing Editor contained herein. Sandra Schroeder ISBN-13: 978-0-7897-5746-3 ISBN-10: 0-7897-5746-X Senior Project Editor Tonya Simpson Library of Congress control number: 2016940227 Copy Editor Printed in the United States of America Gill Editorial Services First Printing: May 2016 Indexer Brad Herriman Trademarks All terms mentioned in this book that are known to be trademarks or service marks have Proofreader been appropriately capitalized. Pearson IT Certification cannot attest to the accuracy of this Paula Lowell information. Use of a term in this book should not be regarded as affecting the validity of any trademark or service mark. Technical Editor Dr. Louay Karadsheh Warning and Disclaimer Publishing Coordinator Every effort has been made to make this book as complete and as accurate as possible, but Vanessa Evans no warranty or fitness is implied. -

Emerging Threats and Attack Trends
Emerging Threats and Attack Trends Paul Oxman Cisco Security Research and Operations PSIRT_2009 © 2009 Cisco Systems, Inc. All rights reserved. Cisco Public 1 Agenda What? Where? Why? Trends 2008/2009 - Year in Review Case Studies Threats on the Horizon Threat Containment PSIRT_2009 © 2009 Cisco Systems, Inc. All rights reserved. Cisco Public 2 What? Where? Why? PSIRT_2009 © 2009 Cisco Systems, Inc. All rights reserved. Cisco Public 3 What? Where? Why? What is a Threat? A warning sign of possible trouble Where are Threats? Everywhere you can, and more importantly cannot, think of Why are there Threats? The almighty dollar (or euro, etc.), the underground cyber crime industry is growing with each year PSIRT_2009 © 2009 Cisco Systems, Inc. All rights reserved. Cisco Public 4 Examples of Threats Targeted Hacking Vulnerability Exploitation Malware Outbreaks Economic Espionage Intellectual Property Theft or Loss Network Access Abuse Theft of IT Resources PSIRT_2009 © 2009 Cisco Systems, Inc. All rights reserved. Cisco Public 5 Areas of Opportunity Users Applications Network Services Operating Systems PSIRT_2009 © 2009 Cisco Systems, Inc. All rights reserved. Cisco Public 6 Why? Fame Not so much anymore (more on this with Trends) Money The root of all evil… (more on this with the Year in Review) War A battlefront just as real as the air, land, and sea PSIRT_2009 © 2009 Cisco Systems, Inc. All rights reserved. Cisco Public 7 Operational Evolution of Threats Emerging Threat Nuisance Threat Threat Evolution Unresolved Threat Policy and Process Reactive Process Socialized Process Formalized Process Definition Reaction Mitigation Technology Manual Process Human “In the Automated Loop” Response Evolution Burden Operational End-User “Help-Desk” Aware—Know End-User No End-User Increasingly Self- Awareness Knowledge Enough to Call Burden Reliant Support PSIRT_2009 © 2009 Cisco Systems, Inc. -

Computer Viruses, in Order to Detect Them
Behaviour-based Virus Analysis and Detection PhD Thesis Sulaiman Amro Al amro This thesis is submitted in partial fulfilment of the requirements for the degree of Doctor of Philosophy Software Technology Research Laboratory Faculty of Technology De Montfort University May 2013 DEDICATION To my beloved parents This thesis is dedicated to my Father who has been my supportive, motivated, inspired guide throughout my life, and who has spent every minute of his life teaching and guiding me and my brothers and sisters how to live and be successful. To my Mother for her support and endless love, daily prayers, and for her encouragement and everything she has sacrificed for us. To my Sisters and Brothers for their support, prayers and encouragements throughout my entire life. To my beloved Family, My Wife for her support and patience throughout my PhD, and my little boy Amro who has changed my life and relieves my tiredness and stress every single day. I | P a g e ABSTRACT Every day, the growing number of viruses causes major damage to computer systems, which many antivirus products have been developed to protect. Regrettably, existing antivirus products do not provide a full solution to the problems associated with viruses. One of the main reasons for this is that these products typically use signature-based detection, so that the rapid growth in the number of viruses means that many signatures have to be added to their signature databases each day. These signatures then have to be stored in the computer system, where they consume increasing memory space. Moreover, the large database will also affect the speed of searching for signatures, and, hence, affect the performance of the system.