Formal Specification of Instruction Set Processors and the Derivation Of
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Computer Organization
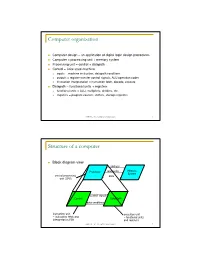
Computer organization Computer design – an application of digital logic design procedures Computer = processing unit + memory system Processing unit = control + datapath Control = finite state machine inputs = machine instruction, datapath conditions outputs = register transfer control signals, ALU operation codes instruction interpretation = instruction fetch, decode, execute Datapath = functional units + registers functional units = ALU, multipliers, dividers, etc. registers = program counter, shifters, storage registers CSE370 - XI - Computer Organization 1 Structure of a computer Block diagram view address Processor read/write Memory System central processing data unit (CPU) control signals Control Data Path data conditions instruction unit execution unit œ instruction fetch and œ functional units interpretation FSM and registers CSE370 - XI - Computer Organization 2 Registers Selectively loaded – EN or LD input Output enable – OE input Multiple registers – group 4 or 8 in parallel LD OE D7 Q7 OE asserted causes FF state to be D6 Q6 connected to output pins; otherwise they D5 Q5 are left unconnected (high impedance) D4 Q4 D3 Q3 D2 Q2 LD asserted during a lo-to-hi clock D1 Q1 transition loads new data into FFs D0 CLK Q0 CSE370 - XI - Computer Organization 3 Register transfer Point-to-point connection MUX MUX MUX MUX dedicated wires muxes on inputs of each register rs rt rd R4 Common input from multiplexer load enables rs rt rd R4 for each register control signals MUX for multiplexer Common bus with output enables output enables and load rs rt rd R4 enables for each register BUS CSE370 - XI - Computer Organization 4 Register files Collections of registers in one package two-dimensional array of FFs address used as index to a particular word can have separate read and write addresses so can do both at same time 4 by 4 register file 16 D-FFs organized as four words of four bits each write-enable (load) 3E RB read-enable (output enable) RA WE (- WB (. -

Review of Computer Architecture
Basic Computer Architecture CSCE 496/896: Embedded Systems Witawas Srisa-an Review of Computer Architecture Credit: Most of the slides are made by Prof. Wayne Wolf who is the author of the textbook. I made some modifications to the note for clarity. Assume some background information from CSCE 430 or equivalent von Neumann architecture Memory holds data and instructions. Central processing unit (CPU) fetches instructions from memory. Separate CPU and memory distinguishes programmable computer. CPU registers help out: program counter (PC), instruction register (IR), general- purpose registers, etc. von Neumann Architecture Memory Unit Input CPU Output Unit Control + ALU Unit CPU + memory address 200PC memory data CPU 200 ADD r5,r1,r3 ADD IRr5,r1,r3 Recalling Pipelining Recalling Pipelining What is a potential Problem with von Neumann Architecture? Harvard architecture address data memory data PC CPU address program memory data von Neumann vs. Harvard Harvard can’t use self-modifying code. Harvard allows two simultaneous memory fetches. Most DSPs (e.g Blackfin from ADI) use Harvard architecture for streaming data: greater memory bandwidth. different memory bit depths between instruction and data. more predictable bandwidth. Today’s Processors Harvard or von Neumann? RISC vs. CISC Complex instruction set computer (CISC): many addressing modes; many operations. Reduced instruction set computer (RISC): load/store; pipelinable instructions. Instruction set characteristics Fixed vs. variable length. Addressing modes. Number of operands. Types of operands. Tensilica Xtensa RISC based variable length But not CISC Programming model Programming model: registers visible to the programmer. Some registers are not visible (IR). Multiple implementations Successful architectures have several implementations: varying clock speeds; different bus widths; different cache sizes, associativities, configurations; local memory, etc. -

V850ES/SA2, V850ES/SA3 32-Bit Single-Chip Microcontrollers
To our customers, Old Company Name in Catalogs and Other Documents On April 1st, 2010, NEC Electronics Corporation merged with Renesas Technology Corporation, and Renesas Electronics Corporation took over all the business of both companies. Therefore, although the old company name remains in this document, it is a valid Renesas Electronics document. We appreciate your understanding. Renesas Electronics website: http://www.renesas.com April 1st, 2010 Renesas Electronics Corporation Issued by: Renesas Electronics Corporation (http://www.renesas.com) Send any inquiries to http://www.renesas.com/inquiry. Notice 1. All information included in this document is current as of the date this document is issued. Such information, however, is subject to change without any prior notice. Before purchasing or using any Renesas Electronics products listed herein, please confirm the latest product information with a Renesas Electronics sales office. Also, please pay regular and careful attention to additional and different information to be disclosed by Renesas Electronics such as that disclosed through our website. 2. Renesas Electronics does not assume any liability for infringement of patents, copyrights, or other intellectual property rights of third parties by or arising from the use of Renesas Electronics products or technical information described in this document. No license, express, implied or otherwise, is granted hereby under any patents, copyrights or other intellectual property rights of Renesas Electronics or others. 3. You should not alter, modify, copy, or otherwise misappropriate any Renesas Electronics product, whether in whole or in part. 4. Descriptions of circuits, software and other related information in this document are provided only to illustrate the operation of semiconductor products and application examples. -

Testing and Validation of a Prototype Gpgpu Design for Fpgas Murtaza Merchant University of Massachusetts Amherst
University of Massachusetts Amherst ScholarWorks@UMass Amherst Masters Theses 1911 - February 2014 2013 Testing and Validation of a Prototype Gpgpu Design for FPGAs Murtaza Merchant University of Massachusetts Amherst Follow this and additional works at: https://scholarworks.umass.edu/theses Part of the VLSI and Circuits, Embedded and Hardware Systems Commons Merchant, Murtaza, "Testing and Validation of a Prototype Gpgpu Design for FPGAs" (2013). Masters Theses 1911 - February 2014. 1012. Retrieved from https://scholarworks.umass.edu/theses/1012 This thesis is brought to you for free and open access by ScholarWorks@UMass Amherst. It has been accepted for inclusion in Masters Theses 1911 - February 2014 by an authorized administrator of ScholarWorks@UMass Amherst. For more information, please contact [email protected]. TESTING AND VALIDATION OF A PROTOTYPE GPGPU DESIGN FOR FPGAs A Thesis Presented by MURTAZA S. MERCHANT Submitted to the Graduate School of the University of Massachusetts Amherst in partial fulfillment of the requirements for the degree of MASTER OF SCIENCE IN ELECTRICAL AND COMPUTER ENGINEERING February 2013 Department of Electrical and Computer Engineering © Copyright by Murtaza S. Merchant 2013 All Rights Reserved TESTING AND VALIDATION OF A PROTOTYPE GPGPU DESIGN FOR FPGAs A Thesis Presented by MURTAZA S. MERCHANT Approved as to style and content by: _________________________________ Russell G. Tessier, Chair _________________________________ Wayne P. Burleson, Member _________________________________ Mario Parente, Member ______________________________ C. V. Hollot, Department Head Electrical and Computer Engineering ACKNOWLEDGEMENTS To begin with, I would like to sincerely thank my advisor, Prof. Russell Tessier for all his support, faith in my abilities and encouragement throughout my tenure as a graduate student. -

Pwny Documentation Release 0.9.0
pwny Documentation Release 0.9.0 Author Nov 19, 2017 Contents 1 pwny package 3 2 pwnypack package 5 2.1 asm – (Dis)assembler..........................................5 2.2 bytecode – Python bytecode manipulation..............................7 2.3 codec – Data transformation...................................... 11 2.4 elf – ELF file parsing.......................................... 16 2.5 flow – Communication......................................... 36 2.6 fmtstring – Format strings...................................... 41 2.7 marshal – Python marshal loader................................... 42 2.8 oracle – Padding oracle attacks.................................... 43 2.9 packing – Data (un)packing...................................... 44 2.10 php – PHP related functions....................................... 46 2.11 pickle – Pickle tools.......................................... 47 2.12 py_internals – Python internals.................................. 49 2.13 rop – ROP gadgets........................................... 50 2.14 shellcode – Shellcode generator................................... 50 2.15 target – Target definition....................................... 79 2.16 util – Utility functions......................................... 80 3 Indices and tables 83 Python Module Index 85 i ii pwny Documentation, Release 0.9.0 pwnypack is the official CTF toolkit of Certified Edible Dinosaurs. It aims to provide a set of command line utilities and a python library that are useful when playing hacking CTFs. The core functionality of pwnypack -

The Microarchitecture of the Pentium 4 Processor
The Microarchitecture of the Pentium 4 Processor Glenn Hinton, Desktop Platforms Group, Intel Corp. Dave Sager, Desktop Platforms Group, Intel Corp. Mike Upton, Desktop Platforms Group, Intel Corp. Darrell Boggs, Desktop Platforms Group, Intel Corp. Doug Carmean, Desktop Platforms Group, Intel Corp. Alan Kyker, Desktop Platforms Group, Intel Corp. Patrice Roussel, Desktop Platforms Group, Intel Corp. Index words: Pentium® 4 processor, NetBurst™ microarchitecture, Trace Cache, double-pumped ALU, deep pipelining provides an in-depth examination of the features and ABSTRACT functions of the Intel NetBurst microarchitecture. This paper describes the Intel® NetBurst™ ® The Pentium 4 processor is designed to deliver microarchitecture of Intel’s new flagship Pentium 4 performance across applications where end users can truly processor. This microarchitecture is the basis of a new appreciate and experience its performance. For example, family of processors from Intel starting with the Pentium it allows a much better user experience in areas such as 4 processor. The Pentium 4 processor provides a Internet audio and streaming video, image processing, substantial performance gain for many key application video content creation, speech recognition, 3D areas where the end user can truly appreciate the applications and games, multi-media, and multi-tasking difference. user environments. The Pentium 4 processor enables real- In this paper we describe the main features and functions time MPEG2 video encoding and near real-time MPEG4 of the NetBurst microarchitecture. We present the front- encoding, allowing efficient video editing and video end of the machine, including its new form of instruction conferencing. It delivers world-class performance on 3D cache called the Execution Trace Cache. -

Lazy Threads� Compiler and Runtime Structures For
Lazy Threads Compiler and Runtime Structures for FineGrained Parallel Programming by Seth Cop en Goldstein BSE Princeton University MSE University of CaliforniaBerkeley A dissertation submitted in partial satisfaction of the requirements for the degree of Do ctor of Philosophy in Computer Science in the GRADUATE DIVISION of the UNIVERSITY of CALIFORNIA at BERKELEY Committee in charge Professor David E Culler Chair Professor Susan L Graham Professor Paul McEuen Professor Katherine A Yelick Fall Abstract Lazy Threads Compiler and Runtime Structures for FineGrained Parallel Programming by Seth Cop en Goldstein Do ctor of Philosophy in Computer Science University of California Berkeley Professor David E Culler Chair Many mo dern parallel languages supp ort dynamic creation of threads or require multithreading in their implementations The threads describ e the logical parallelism in the program For ease of expression and b etter resource utilization the logical parallelism in a program often exceeds the physical parallelism of the machine and leads to applications with many negrained threads In practice however most logical threads need not b e indep endent threads Instead they could b e run as sequential calls which are inherently cheap er than indep endent threads The challenge is that one cannot generally predict which logical threads can b e implemented as sequential calls In lazy multithreading systems each logical thread b egins execution sequentially with the attendant ecientstack management and direct transfer of control and data -

Implementation, Verification and Validation of an Openrisc-1200
(IJACSA) International Journal of Advanced Computer Science and Applications, Vol. 10, No. 1, 2019 Implementation, Verification and Validation of an OpenRISC-1200 Soft-core Processor on FPGA Abdul Rafay Khatri Department of Electronic Engineering, QUEST, NawabShah, Pakistan Abstract—An embedded system is a dedicated computer system in which hardware and software are combined to per- form some specific tasks. Recent advancements in the Field Programmable Gate Array (FPGA) technology make it possible to implement the complete embedded system on a single FPGA chip. The fundamental component of an embedded system is a microprocessor. Soft-core processors are written in hardware description languages and functionally equivalent to an ordinary microprocessor. These soft-core processors are synthesized and implemented on the FPGA devices. In this paper, the OpenRISC 1200 processor is used, which is a 32-bit soft-core processor and Fig. 1. General block diagram of embedded systems. written in the Verilog HDL. Xilinx ISE tools perform synthesis, design implementation and configure/program the FPGA. For verification and debugging purpose, a software toolchain from (RISC) processor. This processor consists of all necessary GNU is configured and installed. The software is written in C components which are available in any other microproces- and Assembly languages. The communication between the host computer and FPGA board is carried out through the serial RS- sor. These components are connected through a bus called 232 port. Wishbone bus. In this work, the OR1200 processor is used to implement the system on a chip technology on a Virtex-5 Keywords—FPGA Design; HDLs; Hw-Sw Co-design; Open- FPGA board from Xilinx. -

Python Console Target Device 78K0 Microcontroller RL78 Family 78K0R Microcontroller V850 Family RX Family RH850 Family
User’s Manual CS+ V4.01.00 Integrated Development Environment User’s Manual: Python Console Target Device 78K0 Microcontroller RL78 Family 78K0R Microcontroller V850 Family RX Family RH850 Family All information contained in these materials, including products and product specifications, represents information on the product at the time of publication and is subject to change by Renesas Electronics Corp. without notice. Please review the latest information published by Renesas Electronics Corp. through various means, including the Renesas Electronics Corp. website (http://www.renesas.com). www.renesas.com Rev.1.00 2016.09 Notice 1. Descriptions of circuits, software and other related information in this document are provided only to illustrate the operation of semiconductor products and application examples. You are fully responsible for the incorporation of these circuits, software, and information in the design of your equipment. Renesas Electronics assumes no responsibility for any losses incurred by you or third parties arising from the use of these circuits, software, or information. 2. Renesas Electronics has used reasonable care in preparing the information included in this document, but Renesas Electronics does not warrant that such information is error free. Renesas Electronics assumes no liability whatsoever for any damages incurred by you resulting from errors in or omissions from the information included herein. 3. Renesas Electronics does not assume any liability for infringement of patents, copyrights, or other intellectual property rights of third parties by or arising from the use of Renesas Electronics products or technical information described in this document. No license, express, implied or otherwise, is granted hereby under any patents, copyrights or other intellectual property rights of Renesas Electronics or others. -

Performance Portability Libraries
The Heterogeneous Computing Revolution Felice Pantaleo CERN - Experimental Physics Department [email protected] 1 A reminder that… CPU evolution is not B. Panzer able to cope with the increasing demand of performance 2 …CMS is in a computing emergency • Performance demand will increase substantially at HL-LHC • an order of magnitude more CPU performance offline and online 3 Today • High Level Trigger • readout of the whole detector with full granularity, based on the CMS software, running on 30,000 CPU cores • Maximum average latency is ~600ms with HT 4 The CMS Trigger in Phase 2 • Level-1 Trigger output rate will increase to 750 kHz (7.5x) • Pileup will increase by a factor 3x-4x • The reconstruction of the new highly granular Calorimeter Endcap will contribute substantially to the required computing resources • Missing an order of magnitude in computing performance 5 The Times They Are a-Changin' Achieving sustainable HEP computing requires change Long shutdown 2 represents a good opportunity to embrace a paradigm shift towards modern heterogeneous computer architectures and software techniques: • Heterogeneous Computing • Machine Learning Algorithms and Frameworks The acceleration of algorithms with GPUs is expected to benefit: • Online computing: decreasing the overall cost/volume of the event selection farm, or increasing its discovery potential/throughput • Offline computing: enabling software frameworks to execute efficiently on HPC centers and saving costs by making WLCG tiers heterogeneous • Volunteer computing: making use of accelerators that are already available on the volunteers’ machines Patatrack • Patatrack is a software R&D incubator • Born in 2016 by a very small group of passionate people • Interests: algorithms, HPC, heterogeneous computing, machine learning, software engineering • Lay the foundations of the CMS online/offline heterogeneous reconstruction starting from 2020s 8 and it’s growing fast 9 Why should our community care? • Accelerators are becoming ubiquitous • Driven by more complex and deeper B. -

Operating RISC: UNIX Standards in the 1990S
Operating RISC: UNIX Standards in the 1990s This case was written by Will Mitchell and Paul Kritikos at the University of Michigan. The case is based on public sources. Some figures are based on case-writers' estimates. We appreciate comments from David Girouard, Robert E. Thomas and Michael Wolff. The note "Product Standards and Competitive Advantage" (Mitchell 1992) supplements this case. The latest International Computerquest Corporation analysis of the market for UNIX- based computers landed on three desks on the same morning. Noel Sharp, founder, chief executive officer, chief engineer and chief bottle washer for the Superbly Quick Architecture Workstation Company (SQAWC) in Mountain View, California hoped to see strong growth predicted for the market for systems designed to help architects improve their designs. In New York, Bo Thomas, senior strategist for the UNIX systems division of A Big Computer Company (ABCC), hoped that general commercial markets for UNIX-based computer systems would show strong growth, but feared that the company's traditional mainframe and mini-computer sales would suffer as a result. Airborne in the middle of the Atlantic, Jean-Helmut Morini-Stokes, senior engineer for the UNIX division of European Electronic National Industry (EENI), immediately looked to see if European companies would finally have an impact on the American market for UNIX-based systems. After looking for analysis concerning their own companies, all three managers checked the outlook for the alliances competing to establish a UNIX operating system standard. Although their companies were alike only in being fictional, the three managers faced the same product standards issues. How could they hasten the adoption of a UNIX standard? The market simply would not grow until computer buyers and application software developers could count on operating system stability. -

Rlsc & DSP Advanced Microprocessor System Design
Purdue University Purdue e-Pubs ECE Technical Reports Electrical and Computer Engineering 3-1-1992 RlSC & DSP Advanced Microprocessor System Design; Sample Projects, Fall 1991 John E. Fredine Purdue University, School of Electrical Engineering Dennis L. Goeckel Purdue University, School of Electrical Engineering David G. Meyer Purdue University, School of Electrical Engineering Stuart E. Sailer Purdue University, School of Electrical Engineering Glenn E. Schmottlach Purdue University, School of Electrical Engineering Follow this and additional works at: http://docs.lib.purdue.edu/ecetr Fredine, John E.; Goeckel, Dennis L.; Meyer, David G.; Sailer, Stuart E.; and Schmottlach, Glenn E., "RlSC & DSP Advanced Microprocessor System Design; Sample Projects, Fall 1991" (1992). ECE Technical Reports. Paper 302. http://docs.lib.purdue.edu/ecetr/302 This document has been made available through Purdue e-Pubs, a service of the Purdue University Libraries. Please contact [email protected] for additional information. RISC & DSP Advanced Microprocessor System Design Sample Projects, Fall 1991 John E. Fredine Dennis L. Goeckel David G. Meyer Stuart E. Sailer Glenn E. Schmottlach TR-EE 92- 11 March 1992 School of Electrical Engineering Purdue University West Lafayette, Indiana 47907 RlSC & DSP Advanced Microprocessor System Design Sample Projects, Fall 1991 John E. Fredine Dennis L. Goeckel David G. Meyer Stuart E. Sailer Glenn E. Schrnottlach School of Electrical Engineering Purdue University West Lafayette, Indiana 47907 Table of Contents Abstract ...................................................................................................................