An Update on Phonetic Symbols in Unicode
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Unicode Nearly Plain-Text Encoding of Mathematics Murray Sargent III Office Authoring Services, Microsoft Corporation 4-Apr-06
Unicode Nearly Plain Text Encoding of Mathematics Unicode Nearly Plain-Text Encoding of Mathematics Murray Sargent III Office Authoring Services, Microsoft Corporation 4-Apr-06 1. Introduction ............................................................................................................ 2 2. Encoding Simple Math Expressions ...................................................................... 3 2.1 Fractions .......................................................................................................... 4 2.2 Subscripts and Superscripts........................................................................... 6 2.3 Use of the Blank (Space) Character ............................................................... 7 3. Encoding Other Math Expressions ........................................................................ 8 3.1 Delimiters ........................................................................................................ 8 3.2 Literal Operators ........................................................................................... 10 3.3 Prescripts and Above/Below Scripts........................................................... 11 3.4 n-ary Operators ............................................................................................. 11 3.5 Mathematical Functions ............................................................................... 12 3.6 Square Roots and Radicals ........................................................................... 13 3.7 Enclosures..................................................................................................... -

Typing Vietnamese on Window
TYPING VIETNAMESE WITH UNICODE FONT It is recommended that you use a Vietnamese keyboard or keyboard driver for the task. Despite its name, it is not hardware: it is a small program that sits in your OS and converts your keystrokes into Vietnamese characters. Unikey. Its advantages are: It's free. It's just a download away: for NT/2000/XP, for 95/98/MEor for Linux. Installation is simple: just unzip it and it is ready to go. It sits on the taskbar. This makes it easy to switch between "English" mode and "Vietnamese" mode: just click on the icon on the taskbar. The user interface actually provides for English speakers, which makes it easier to understand. Setup 1. When you start up Unikey, you see the following dialogue: What does it all mean? Fortunately, you can find out what is happening by clicking on the "Mở rộng" button. "Mở rộng" means expand, and that's what you need to do. Uncheck the checkbox with "Vietnamese interface”. The whole interface will turn into English: I recommend you always set the "Character Set" to Unicode - always. A character set is basically how characters like "ư" and "a" are represented as numbers that computers can handle. The Microsoft Office programs are set to handle Unicode by default. Unicode is an international standard, so you can't go much wrong with it. The "Input method" is what keystrokes will form a character like "ư". I prefer TELEX, but I will give instructions for using Unikey with VNI as well. See the next section for instructions. -

Unicode Request for Cyrillic Modifier Letters Superscript Modifiers
Unicode request for Cyrillic modifier letters L2/21-107 Kirk Miller, [email protected] 2021 June 07 This is a request for spacing superscript and subscript Cyrillic characters. It has been favorably reviewed by Sebastian Kempgen (University of Bamberg) and others at the Commission for Computer Supported Processing of Medieval Slavonic Manuscripts and Early Printed Books. Cyrillic-based phonetic transcription uses superscript modifier letters in a manner analogous to the IPA. This convention is widespread, found in both academic publication and standard dictionaries. Transcription of pronunciations into Cyrillic is the norm for monolingual dictionaries, and Cyrillic rather than IPA is often found in linguistic descriptions as well, as seen in the illustrations below for Slavic dialectology, Yugur (Yellow Uyghur) and Evenki. The Great Russian Encyclopedia states that Cyrillic notation is more common in Russian studies than is IPA (‘Transkripcija’, Bol’šaja rossijskaja ènciplopedija, Russian Ministry of Culture, 2005–2019). Unicode currently encodes only three modifier Cyrillic letters: U+A69C ⟨ꚜ⟩ and U+A69D ⟨ꚝ⟩, intended for descriptions of Baltic languages in Latin script but ubiquitous for Slavic languages in Cyrillic script, and U+1D78 ⟨ᵸ⟩, used for nasalized vowels, for example in descriptions of Chechen. The requested spacing modifier letters cannot be substituted by the encoded combining diacritics because (a) some authors contrast them, and (b) they themselves need to be able to take combining diacritics, including diacritics that go under the modifier letter, as in ⟨ᶟ̭̈⟩BA . (See next section and e.g. Figure 18. ) In addition, some linguists make a distinction between spacing superscript letters, used for phonetic detail as in the IPA tradition, and spacing subscript letters, used to denote phonological concepts such as archiphonemes. -

Download Free Chinese Fonts for Mac
1 / 4 Download Free Chinese Fonts For Mac ttc and Songti ttc and include TC fonts Hiragino Sans GB ~ Beginning with OS X 10.. 01[?]KaiTi楷体GB18030simkai ttfv5 01[?]FangSong_GB2312仿宋_GB2312GB2312SIMFANG.. [NEED MORE DETAILS HERE] [DISCUSSION OF WEB FONTS AND CSS3]Arphic [文鼎]Taiwan.. If you want to use this font for both simplified and traditional Chinese, then use Font Book to deactivate BiauKai and activate DFKai-SB instead.. ttf file and select install MacOS X (10 3 or later)Double-click on the ttf file and select install.. West is an IRG participant as a member of the UK delegation, so he is well-informed and up-to-date on the progress of their work, and his fonts reflect that knowledge. In addition, the Microsoft Office XP Proofing Tools (and Chinese editions) include the font Simsun (Founder Extended) [SURSONG.. A long time vendor of Chinese OEM fonts, in 2006 Monotype's new owners [Monotype Imaging] also acquired China Type Design [中國字體設計] in Hong Kong.. For the character sets and weights for each, see the Fonts section for your OS: 10.. If you have downloaded a font that is saved in Free Chinese Fonts Free Chinese Font is all about Chinese fonts that are free to download! This site aims to help you download high quality Chinese fonts in.. FamilyFile nameCharsetOS 910 310 410 510 610 710 810 1010 11PingFang SC PingFang HK PingFang TCPingFang.. Font files had to be converted between Windows and Macintosh Regardless, all TrueType fonts contain 'cmap' tables that map its glyphs to various encodings. chinese fonts chinese fonts, chinese fonts generator, chinese fonts download, chinese fonts copy and paste, chinese fonts google docs, chinese fonts dafont, chinese fonts adobe, chinese fonts in microsoft word, chinese fonts word, chinese fonts calligraphy Arial Unicode MS ~ Beginning with OS X 10 5, Apple includes this basic Monotype Unicode font from Microsoft Office [Arial Unicode. -

The Unicode Cookbook for Linguists: Managing Writing Systems Using Orthography Profiles
Zurich Open Repository and Archive University of Zurich Main Library Strickhofstrasse 39 CH-8057 Zurich www.zora.uzh.ch Year: 2017 The Unicode Cookbook for Linguists: Managing writing systems using orthography profiles Moran, Steven ; Cysouw, Michael DOI: https://doi.org/10.5281/zenodo.290662 Posted at the Zurich Open Repository and Archive, University of Zurich ZORA URL: https://doi.org/10.5167/uzh-135400 Monograph The following work is licensed under a Creative Commons: Attribution 4.0 International (CC BY 4.0) License. Originally published at: Moran, Steven; Cysouw, Michael (2017). The Unicode Cookbook for Linguists: Managing writing systems using orthography profiles. CERN Data Centre: Zenodo. DOI: https://doi.org/10.5281/zenodo.290662 The Unicode Cookbook for Linguists Managing writing systems using orthography profiles Steven Moran & Michael Cysouw Change dedication in localmetadata.tex Preface This text is meant as a practical guide for linguists, and programmers, whowork with data in multilingual computational environments. We introduce the basic concepts needed to understand how writing systems and character encodings function, and how they work together. The intersection of the Unicode Standard and the International Phonetic Al- phabet is often not met without frustration by users. Nevertheless, thetwo standards have provided language researchers with a consistent computational architecture needed to process, publish and analyze data from many different languages. We bring to light common, but not always transparent, pitfalls that researchers face when working with Unicode and IPA. Our research uses quantitative methods to compare languages and uncover and clarify their phylogenetic relations. However, the majority of lexical data available from the world’s languages is in author- or document-specific orthogra- phies. -

Assessment of Options for Handling Full Unicode Character Encodings in MARC21 a Study for the Library of Congress
1 Assessment of Options for Handling Full Unicode Character Encodings in MARC21 A Study for the Library of Congress Part 1: New Scripts Jack Cain Senior Consultant Trylus Computing, Toronto 1 Purpose This assessment intends to study the issues and make recommendations on the possible expansion of the character set repertoire for bibliographic records in MARC21 format. 1.1 “Encoding Scheme” vs. “Repertoire” An encoding scheme contains codes by which characters are represented in computer memory. These codes are organized according to a certain methodology called an encoding scheme. The list of all characters so encoded is referred to as the “repertoire” of characters in the given encoding schemes. For example, ASCII is one encoding scheme, perhaps the one best known to the average non-technical person in North America. “A”, “B”, & “C” are three characters in the repertoire of this encoding scheme. These three characters are assigned encodings 41, 42 & 43 in ASCII (expressed here in hexadecimal). 1.2 MARC8 "MARC8" is the term commonly used to refer both to the encoding scheme and its repertoire as used in MARC records up to 1998. The ‘8’ refers to the fact that, unlike Unicode which is a multi-byte per character code set, the MARC8 encoding scheme is principally made up of multiple one byte tables in which each character is encoded using a single 8 bit byte. (It also includes the EACC set which actually uses fixed length 3 bytes per character.) (For details on MARC8 and its specifications see: http://www.loc.gov/marc/.) MARC8 was introduced around 1968 and was initially limited to essentially Latin script only. -

Phonetic Characters, Fonts, and Editors Data and Other Documents Here
Phonetic characters, fonts, and editors Data and other documents here are composed using Times New Roman version 5.01, which includes the major unicode phonetic symbols. If you have problems displaying those characters (some appear as boxes), that probably means that you do not have a current version of TNR. A current version of TNR should be part of your operating system at least since Windows Vista, but an upgrade can be purchased. There are free unicode fonts with phonetic characters which can substitute for this version of TNR. The procedure is to download and install the font, then within your editor (such as Word), select the whole document and change the font to whichever font you just installed. The best choices are (in descending order of design preference): Titus Cyberbit Basic (http://titus.fkidg1.uni-frankfurt.de/unicode/tituut.asp) Doulos SIL (http://scripts.sil.org/cms/scripts/page.php?item_id=DoulosSIL_download#FontsDownload) Charis SIL (http://scripts.sil.org/cms/scripts/page.php?item_id=CharisSIL_download#FontsDownload) Gentium (http://scripts.sil.org/cms/scripts/page.php?item_id=Gentium_basic) Cardo (http://scholarsfonts.net/cardofnt.html) Sporadic problems have been reported using Open Office, in cases where text is cut and pasted from another document and the text contains overstrike diacritics (e.g. [æ ̃]), that some of the text is “double-printed”. This apparently can be overcome by pasting into a new (OO) document, saving, closing, re-opening, and then copying to the intended document. You will have to experiment; if it happens, at least you’ll know that you’re not alone.. -

Katowice 2015
Więcej o książce CENA 28 ZŁ ISSN 0208-6336 (+ VAT) ISBN 978-83-8012-387-8 KATOWICE 2015 NR 3469 KATOWICE 2015 Redaktor serii: Językoznawstwo Polonistyczne Bożena Witosz Recenzentka Piotra Łobacz Wstęp Międzynarodowy alfabet fonetyczny (dalej: IPA) jest powszechnie znanym systemem transkrypcji stosowanym w różnych dziedzinach badań nad mową, lecz bardzo rzadko używanym w obrębie językoznawstwa polskiego, nie tylko w badaniach nad językiem polskim, ale także nad innymi językami słowiań skimi. Co więcej, nie dysponujemy, poza jednym wyjątkiem (Żurawski, red., 2011), polskim opracowaniem zawierającym obecnie obowiązujące symbole alfabetu międzynarodowego. Zestawy symboli opublikowane w pracach Wiktora Jassema (zob. bibliografia), w Słowniku wymowy polskiej PWN (SWP, 1977) oraz Encyklopedii językoznawstwa ogólnego (EJO, 1999), a także w wielu podręcznikach zdezaktualizowały się po 1989 roku. Zresztą nawet w opra cowaniu Język polski. Nauka o języku (Żurawski, red., 2011) nie znajdziemy wszystkich symboli IPA ani bardzo potrzebnych wskazówek dotyczących tego alfabetu (sposobu stawiania symboli oraz opisu ich budowy graficznej). Zadanie omówienia IPA jest bardzo skomplikowane, ponieważ nie wystarczy podać wartości samych symboli (a jest ich bardzo dużo, bo ponad 2501), ale trzeba także wyjaśnić sposób ich użycia (szczególnie ważne jest to w przy padku diakrytów), ich budowę (to z kolei jest istotne w przypadku nietypo wych liter typu <ʒ ɟ>), znaczenie angielskich terminów fonetycznych stoso wanych w opisie symboli IPA (nie ma tutaj pełnej jednoznaczności względem terminów polskich), sposoby konstruowania symboli fonetycznych w edyto rach tekstu (od czcionek komputerowych, tzw. fontów, zawierających sym bole IPA począwszy, na sposobach pozycjonowania znaków diakrytycznych skończywszy). Tak zaprojektowana monografia byłaby jednak niepraktyczna: zawierałaby ogromną ilość informacji, z których przeciętny użytkownik alfa betu fonetycznego nie skorzystałby, a już na pewno nie studiowałby ich po to tylko, by wstawić do swojego tekstu kilka symboli fonetycznych. -

The Fontspec Package Font Selection for XƎLATEX and Lualatex
The fontspec package Font selection for XƎLATEX and LuaLATEX Will Robertson and Khaled Hosny [email protected] 2013/05/12 v2.3b Contents 7.5 Different features for dif- ferent font sizes . 14 1 History 3 8 Font independent options 15 2 Introduction 3 8.1 Colour . 15 2.1 About this manual . 3 8.2 Scale . 16 2.2 Acknowledgements . 3 8.3 Interword space . 17 8.4 Post-punctuation space . 17 3 Package loading and options 4 8.5 The hyphenation character 18 3.1 Maths fonts adjustments . 4 8.6 Optical font sizes . 18 3.2 Configuration . 5 3.3 Warnings .......... 5 II OpenType 19 I General font selection 5 9 Introduction 19 9.1 How to select font features 19 4 Font selection 5 4.1 By font name . 5 10 Complete listing of OpenType 4.2 By file name . 6 font features 20 10.1 Ligatures . 20 5 Default font families 7 10.2 Letters . 20 6 New commands to select font 10.3 Numbers . 21 families 7 10.4 Contextuals . 22 6.1 More control over font 10.5 Vertical Position . 22 shape selection . 8 10.6 Fractions . 24 6.2 Math(s) fonts . 10 10.7 Stylistic Set variations . 25 6.3 Miscellaneous font select- 10.8 Character Variants . 25 ing details . 11 10.9 Alternates . 25 10.10 Style . 27 7 Selecting font features 11 10.11 Diacritics . 29 7.1 Default settings . 11 10.12 Kerning . 29 7.2 Changing the currently se- 10.13 Font transformations . 30 lected features . -

Applications and Innovations in Typeface Design for North American Indigenous Languages Julia Schillo, Mark Turin
Applications and innovations in typeface design for North American Indigenous languages Julia Schillo, Mark Turin To cite this version: Julia Schillo, Mark Turin. Applications and innovations in typeface design for North American Indige- nous languages. Book 2.0, Intellect Ltd, 2020, 10 (1), pp.71-98. 10.1386/btwo_00021_1. halshs- 03083476 HAL Id: halshs-03083476 https://halshs.archives-ouvertes.fr/halshs-03083476 Submitted on 22 Jan 2021 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. BTWO 10 (1) pp. 71–98 Intellect Limited 2020 Book 2.0 Volume 10 Number 1 btwo © 2020 Intellect Ltd Article. English language. https://doi.org/10.1386/btwo_00021_1 Received 15 September 2019; Accepted 7 February 2020 Book 2.0 Intellect https://doi.org/10.1386/btwo_00021_1 10 JULIA SCHILLO AND MARK TURIN University of British Columbia 1 71 Applications and 98 innovations in typeface © 2020 Intellect Ltd design for North American 2020 Indigenous languages ARTICLES ABSTRACT KEYWORDS In this contribution, we draw attention to prevailing issues that many speakers orthography of Indigenous North American languages face when typing their languages, and typeface design identify examples of typefaces that have been developed and harnessed by histor- Indigenous ically marginalized language communities. -
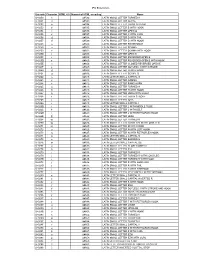
IPA Extensions
IPA Extensions Unicode Character HTML 4.0 Numerical HTML encoding Name U+0250 ɐ ɐ LATIN SMALL LETTER TURNED A U+0251 ɑ ɑ LATIN SMALL LETTER ALPHA U+0252 ɒ ɒ LATIN SMALL LETTER TURNED ALPHA U+0253 ɓ ɓ LATIN SMALL LETTER B WITH HOOK U+0254 ɔ ɔ LATIN SMALL LETTER OPEN O U+0255 ɕ ɕ LATIN SMALL LETTER C WITH CURL U+0256 ɖ ɖ LATIN SMALL LETTER D WITH TAIL U+0257 ɗ ɗ LATIN SMALL LETTER D WITH HOOK U+0258 ɘ ɘ LATIN SMALL LETTER REVERSED E U+0259 ə ə LATIN SMALL LETTER SCHWA U+025A ɚ ɚ LATIN SMALL LETTER SCHWA WITH HOOK U+025B ɛ ɛ LATIN SMALL LETTER OPEN E U+025C ɜ ɜ LATIN SMALL LETTER REVERSED OPEN E U+025D ɝ ɝ LATIN SMALL LETTER REVERSED OPEN E WITH HOOK U+025E ɞ ɞ LATIN SMALL LETTER CLOSED REVERSED OPEN E U+025F ɟ ɟ LATIN SMALL LETTER DOTLESS J WITH STROKE U+0260 ɠ ɠ LATIN SMALL LETTER G WITH HOOK U+0261 ɡ ɡ LATIN SMALL LETTER SCRIPT G U+0262 ɢ ɢ LATIN LETTER SMALL CAPITAL G U+0263 ɣ ɣ LATIN SMALL LETTER GAMMA U+0264 ɤ ɤ LATIN SMALL LETTER RAMS HORN U+0265 ɥ ɥ LATIN SMALL LETTER TURNED H U+0266 ɦ ɦ LATIN SMALL LETTER H WITH HOOK U+0267 ɧ ɧ LATIN SMALL LETTER HENG WITH HOOK U+0268 ɨ ɨ LATIN SMALL LETTER I WITH STROKE U+0269 ɩ ɩ LATIN SMALL LETTER IOTA U+026A ɪ ɪ LATIN LETTER SMALL CAPITAL I U+026B ɫ ɫ LATIN SMALL LETTER L WITH MIDDLE TILDE U+026C ɬ ɬ LATIN SMALL LETTER L WITH BELT U+026D ɭ ɭ LATIN SMALL LETTER L WITH RETROFLEX HOOK U+026E ɮ ɮ LATIN SMALL LETTER LEZH U+026F ɯ ɯ LATIN SMALL -

African Fonts and Open Source
African fonts and Open Source Denis Moyogo Jacquerye September 17th 2008 ATypI ‘o8 Conference St. Petersburg, Russia, September 2008 1 African fonts and Open Source Denis Moyogo Jacquerye African fonts and Open Source This talk is about: ● African Orthographies (relevance, groups, requirements) ● Technologies for them (Unicode, OpenType) ● Implementation ● Raise awareness and interest ● Case for Open Source ATypI ‘o8 Conference St. Petersburg, Russia, September 2008 2 African fonts and Open Source Denis Moyogo Jacquerye Speaker Denis Moyogo Jacquerye ● Computer Scientist and Linguist ● Africanization consultant ● DejaVu Fonts co-leader ● African Network for Localization (ANLoc) ATypI ‘o8 Conference St. Petersburg, Russia, September 2008 3 African fonts and Open Source Denis Moyogo Jacquerye ANLoc African fonts work part of ANLoc project ● Facilitate localization ● Empowering through ICT ● Network of experts ● Sub-projects: Locales, Keyboards, Fonts, Spell checkers, Terminology, Training, Localization software, Policy. ATypI ‘o8 Conference St. Petersburg, Russia, September 2008 4 African fonts and Open Source Denis Moyogo Jacquerye African languages ● Lots of African languages (over 2000) ● 25 spoken by about half ● 80% don't have orthographies ● 20% do! ● Can emulate! ATypI ‘o8 Conference St. Petersburg, Russia, September 2008 5 African fonts and Open Source Denis Moyogo Jacquerye African languages ● Used every day by most ● Education is mostly in European language ● Used in spoken media ● Interest is rising ATypI ‘o8 Conference St. Petersburg,