Multilingual OCR Systems for the Regional Languages in Balochistan
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Archaeology at Ras Muari: Sonari, a Bronze Age Fisher-Gatherers Settlement at the Hab River Mouth (Karachi, Pakistan)
The Antiquaries Journal, , ,pp– © The Society of Antiquaries of London, . This is an Open Access article, distributed under the terms of the Creative Commons Attribution licence (http://creativecommons. org/licenses/by/./), which permits unrestricted re-use, distribution, and reproduction in any medium, provided the original work is properly cited. doi:./S First published online August ARCHAEOLOGY AT RAS MUARI: SONARI, A BRONZE AGE FISHER-GATHERERS SETTLEMENT AT THE HAB RIVER MOUTH (KARACHI, PAKISTAN) Paolo Biagi, Hon FSA, Renato Nisbet, Michela Spataro and Elisabetta Starnini Paolo Biagi, Department of Asian and North African Studies (DSAAM), Ca’ Foscari University, Ca’ Cappello, San Polo 2035, I-30125 Venice, Italy. Email: [email protected] Renato Nisbet, Department of Asian and North African Studies (DSAAM), Ca’ Foscari University, Ca’ Cappello, San Polo 2035, I-30125 Venice, Italy. Email: [email protected] Michela Spataro, Department of Scientific Research, The British Museum, Great Russell Street, London WC1B 3DG, UK. Email: [email protected] Elisabetta Starnini, Department of Civilizations and Forms of Knowledge, Pisa University, Via dei Mille 19, I-56126 Pisa, Italy. Email: [email protected] This paper describes the results of the surveys carried out along Ras Muari (Cape Monze, Karachi, Sindh) by the Italian Archaeological Mission in Lower Sindh and Las Bela in and . The surveyed area coincides with part of the mythical land of the Ichthyophagoi, mentioned by the classical chroniclers. Many archaeological sites, mainly scatters and spots of fragmented marine and mangrove shells, were discovered and AMS dated along the northern part of the cape facing the Hab River mouth. The surveys have shown that fisher and shell gatherer com- munities temporarily settled in different parts of the headland. -

Antiquity Journal
Search Antiquity Go HOME CURRENT ISSUE ANTIQUITY+ ARCHIVE CONTRIBUTE SUBSCRIBE CONTACT Sonari: a Bronze Age fisher-gatherer settlement at the Hab River mouth (Sindh, Pakistan) Paolo Biagi & Renato Nisbet Introduction Click to enlarge The surveys carried out by Professor A.R. Khan in Lower Sindh, Pakistan, during the 1970s led to the discovery of an impressive number of prehistoric sites, some of which are briefly described in Khan’s important monograph on the geomorphology and prehistory of Sindh (Khan 1979a). Strangely, however, he never mentioned the existence of a (still) unique fisher-gatherer settlement at Sonari in spite of earlier visits he paid to the area. The site, located on a limestone terrace facing the Hab River mouth, is not even reported in the distribution maps, on which he marked the discoveries made during his years of fieldwork (Figure 1). Nor does he mention the presence of any prehistoric sites on Cape Monze (Ras Muari) in his paper on the archaeology of the Karachi region (Khan 1979b), though he does describe a single important Bronze Age settlement at Pir Shah Jurio, along the eastern bank of the Hab River (Khan 1979b: 4), and open in browser PRO version Are you a developer? Try out the HTML to PDF API pdfcrowd.com Hab Chauki and Mai Garhi some 30km further north (Khan 1979b: 22). Figure 1. Location of the radiocarbon-dated sites discovered at the mouth of the Hab River. The persent-day Geographical setting village of Sonari is marked, as are SNR-1 (red dot), Pir Shah The Bronze Age site of Sonari (SNR–1) is located at an altitude of 25– Jurio (green dot) and other sites (blue dots) (drawn by P. -

(Karachi) Past: Present and Future
KURRACHEE (KARACHI) PAST: PRESENT AND FUTURE ALEXANDER F. BAILLIE, F.R.G.S., 1890 BIRD'S EYE VIEW OF VICTORIA ROAD CLERK STREET, SADDAR BAZAR KARACHI REPRODUCED BY SANI H. PANHWAR (2019) KUR R A CH EE: PA ST:PRESENT:A ND FUTURE. KUR R A CH EE: (KA R A CH I) PA ST:PRESENT:A ND FUTURE. BY A LEXA NDER F.B A ILLIE,F.R.G.S., A uthor of"A PA RA GUA YA N TREA SURE,"etc. W ith M a ps,Pla ns & Photogra phs 1890. Reproduced by Sa niH .Panhw a r (2019) TO THE RIGHT HONOURABLE SIR MOUNTSTUART ELPHINSTONE GRANT-DUFF, P.C., G.C.S.I., C.I.E., F.R.S., M.R.A.S., PRESIDENT OF THE ROYAL GEOGRAPHICAL SOCIETY, FORMERLY UNDER-SECRETARY OF STATE FOR INDIA, AND GOVERNOR OF THE PROVINCE OF MADRAS, ETC., ETC., THIS ACCOUNT OF KURRACHEE: PAST, PRESENT, AND FUTURE, IS MOST RESPECTFULLY DEDICATED BY HIS OBEDIENT SERVANT, THE AUTHOR. INTRODUCTION. THE main objects that I have had in view in publishing a Treatise on Kurrachee are, in the first place, to submit to the Public a succinct collection of facts relating to that City and Port which, at a future period, it might be difficult to retrieve from the records of the Past ; and secondly, to advocate the construction of a Railway system connecting the GateofCentralAsiaand the Valley of the Indus, with the Native Capital of India. I have elsewhere mentioned the authorities to whom I am indebted, and have gratefully acknowledged the valuable assistance that, from numerous sources, has been afforded to me in the compilation of this Work; but an apology is due to my Readers for the comments and discursions that have been interpolated, and which I find, on revisal, occupy a considerable number of the following pages. -

Ecological Impbalances in the Coastal Areas of Pakistan and Karachi
Pakistan Journal of Marine Sciences, VoL4(2), 159-174, 1995. REVIEW ARTICLE ECOLOGICAL IMBALANCES IN THE COASTAL AREAS OF PAKISTAN AND KARACID HARBOUR Mirza Arshad Ali Beg 136-C, Rafahe Aam Housing Society, Malir Halt, Karachi-75210. ABSTRACT: The marine environment of Pakistan has been described in the context of three main regions : the Indus delta and its creek system, the Karachi coastal region, and the Balochistan coast The creeks, contrary to concerns, do receive adequate discharges of freshwater. On site observations indicate that freshwater continues flowing into them during the lean water periods and dilutes the seawater there. A major factor for the loss of mangrove forests. as well as ecological disturbances in the Indus delta is loss of the silt load resulting in erosion of its mudflats. The ecological disturbance has been aggravated by allowing camels to browse the mangroves. The tree branches and trunks, having been denuded of leaves are felled for firewood. Evidence is presented to show that while indiscriminate removal of its mangrove trees is responsible for the loss oflarge tracts of mangrove forests, overharvesting of fisheries resources has depleted the river of some valuable fishes that were available from the delta area. Municipal and industrial effluents discharged into the Lyari and Malir rivers and responsible for land-based pollution at the Karachi coast and the harbour. The following are the three major areas receiving land-based pollution and whose environmental conditions have been examined in detail: (l) the Manora channel, located on the estuar}r of the Lyari river and serving as the main harbour, has vast areas forming its western and eastern backwaters characterized by mud flats and mangroves. -

Physical Geography of the Las Bela Coastal Plain, West Pakistan. Rodman Eldredge Snead Louisiana State University and Agricultural & Mechanical College
Louisiana State University LSU Digital Commons LSU Historical Dissertations and Theses Graduate School 1963 Physical Geography of the Las Bela Coastal Plain, West Pakistan. Rodman Eldredge Snead Louisiana State University and Agricultural & Mechanical College Follow this and additional works at: https://digitalcommons.lsu.edu/gradschool_disstheses Recommended Citation Snead, Rodman Eldredge, "Physical Geography of the Las Bela Coastal Plain, West Pakistan." (1963). LSU Historical Dissertations and Theses. 857. https://digitalcommons.lsu.edu/gradschool_disstheses/857 This Dissertation is brought to you for free and open access by the Graduate School at LSU Digital Commons. It has been accepted for inclusion in LSU Historical Dissertations and Theses by an authorized administrator of LSU Digital Commons. For more information, please contact [email protected]. This dissertation has been G4—160 microfilmed exactly as received SNEAD, Hodman Eldredge, 1931- PHYSICAL GEOGRAPHY OF THE LAS BELA COASTAL PLAIN, WEST PAKISTAN. Louisiana State University, Ph.D., 1963 G eography University Microfilms, Inc., Ann Arbor, Michigan PHYSICAL GEOGRAPHY OF THE LAS BELA COASTAL PLAIN, WEST PAKISTAN A Dissertation Submitted to the Graduate Faculty of the Louisiana State University and Agricultural and Mechanical College in partial fulfillment of the requirements for the degree of Doctor of Philosophy in The Department of Geography by Rodman Eldredge Snead B.A., University of Virginia, 1953 M.S., Syracuse University, 1955 June, 1963 ACKNOWLEDGMENTS I wish to thank the many people who have aided in the completion of this study. I am particularly grateful to Dr. Richard J. Russell, Dr. William G. Mclntire, Dr. David D. Smith, William P. Agster and the staffs of the Coastal Studies Institute of Louisiana State University, Meteorological Department of the Government of Pakistan, and of the Geogra phy Departments of the University of Karachi and the Univer sity of Sind. -

Download.Cfm?Fileid=1471
International Journal of Multidisciplinary and Current Research ISSN: 2321-3124 Research Article Available at: http://ijmcr.com De-Constructing the problematic Maritime Tourism in Pakistan: Opportunities and Challenges Dr. Sajid Mahmood Shahzad* Vice Chancellor, Minhaj University Lahore, Pakistan Received 02 March 2020, Accepted 02 May 2020, Available online 03 May 2020, Vol.8 (May/June 2020 issue) Abstract Pakistan is blessed with over 1000 Km long coastline with numerous opportunities of tourism. Maritime Tourism is a significant peace contributor with positive effect on economic development and employment around the world. It is additionally an undeniably perspective in the life of individuals, increasingly more of whom are voyaging and travelling, either for business or leisure time. However, the vital role of maritime tourism and its impact on economic development in Pakistan has hardly been realized. The study is qualitative and exploratory in nature. This research is the outcome of detailed review of available material and publications on this subject by the official sources. The official reports, government publications, books, newspapers, websites and many other official sources also used to collect the primary data. The main objective of this research is to review the facilities, opportunities and challenges of maritime tourism in Pakistan, and to develop a link for the economic activity along the coastlines. The reviewed literature depict that the maritime tourism has become a new business hub that forms a considerable component of the rising global tourism business. The security situation, natural disaster, negligible infrastructure and comparatively poor education are the main reasons that tourism could not flourish on coastal area of Pakistan. -

Colonial Encounters, Karachi and Anglo-Indian Dwellings During the Raj
COLONIAL ENCOUNTERS, KARACHI AND ANGLO-INDIAN DWELLINGS DURING THE RAJ A THESIS SUBMITTED TO THE GRADUATE SCHOOL OF SOCIAL SCIENCES OF MIDDLE EAST TECHNICAL UNIVERSITY BY NIDA AHMED IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF MASTER OF ARTS IN THE DEPARTMENT OF HISTORY OF ARCHITECTURE JANUARY 2017 Approval of the Graduate School of Social Sciences Prof. Dr. Tulin GENÇÖZ Director I certify that this thesis satisfies all the requirements as a thesis for the degree of Master of Arts. Prof. Dr. Elvan ALTAN Head of Department This is to certify that we have read this thesis and that in our opinion it is fully adequate, in scope and quality, as a thesis for the degree of Master of Arts. Prof. Dr. Suna GÜVEN Supervisor Examining Committee Members: Prof. Dr. Belgin T. ÖZKAYA (METU, AH) Prof. Dr. Suna GÜVEN (METU, AH) Assoc. Prof. Dr. Namık G. ERKAL (TEDU, Arch.) I hereby declare that all information in this document has been obtained and presented in accordance with academic rules and ethical conduct. I also declare that, as required by these rules and conduct, I have fully cited and referenced all material and results that are not original to this work. Name, Last name: Nida Ahmed Signature : iii ABSTRACT COLONIAL ENCOUNTERS, KARACHI AND ANGLO‐INDIAN DWELLINGS DURING THE RAJ AHMED, Nida M.A., Department of History of Architecture Supervisor: Prof. Dr. Suna Güven January 2017, 156 pages Was British imperialism in India an authoritarian rule or a collaborative one? How did the Indians resist, react, or adapt to the modernity introduced by the British? How did the British respond to their Indian context? Did the colonisers transplant western ideology and institutions without experiencing an exchange of ideas and practices in return? To deal with these questions, the study focuses on the architectural developments in Karachi during the British Raj (1858‐1947) and investigates how the reforms introduced by the Raj transformed and modernised the society and its architecture, particularly the colonial domestic architecture. -

With Alexander in India and Central Asia
With Alexander in India and Central Asia © Oxbow Books 2017 Oxford & Philadelphia www.oxbowbooks.com AN OFFPRINT FROM With Alexander in India and Central Asia Moving East and Back to West edited by Claudia Antonetti and Paolo Biagi Paperback Edition: ISBN 978-1-78570-584-7 Digital Edition: ISBN 978-1-78570-585-4 (epub) © Oxbow Books 2017 Oxford & Philadelphia www.oxbowbooks.com Published in the United Kingdom in 2017 by OXBOW BOOKS The Old Music Hall, 106–108 Cowley Road, Oxford OX4 1JE and in the United States by OXBOW BOOKS 1950 Lawrence Road, Havertown, PA 19083 © Oxbow Books and the individual contributors 2017 Paperback Edition: ISBN 978-1-78570-584-7 Digital Edition: ISBN 978-1-78570-585-4 (epub) A CIP record for this book is available from the British Library and the Library of Congress All rights reserved. No part of this book may be reproduced or transmitted in any form or by any means, electronic or mechanical including photocopying, recording or by any information storage and retrieval system, without permission from the publisher in writing. Printed in Malta by Melita Press For a complete list of Oxbow titles, please contact: UNITED KINGDOM UNITED STATES OF AMERICA Oxbow Books Oxbow Books Telephone (01865) 241249, Fax (01865) 794449 Telephone (800) 791-9354, Fax (610) 853-9146 Email: [email protected] Email: [email protected] www.oxbowbooks.com www.casemateacademic.com/oxbow Oxbow Books is part of the Casemate Group Front cover: The mangrove swamp of Miāni Hor, Las Bela, Balochistan, close to the place where Nearchus landed. -
Exploiting Mangroves and Rushing Back Home
Giornata dell’archeologia: scavi e ricerche del Dipartimento di Studi Umanistici a cura di Luigi Sperti Exploiting Mangroves and Rushing Back Home Fifteen Years of Research Along the Northern Coast of the Arabian Sea, Pakistan Paolo Biagi (Università Ca’ Foscari Venezia, Italia) Renato Nisbet (Università Ca’ Foscari Venezia, Italia) Tiziano Fantuzzi (Università Ca’ Foscari Venezia, Italia) Abstract The research carried out between 2000 and 2014 along the northern coast of the Arabian Sea in Lower Sindh and Las Bela (Balochistan, Pakistan) has shown that the two regions started to be settled during the last two centuries of the 8th millennium BP. The sites consist of shell middens, shell scatters and fishermen villages, many of which were sampled for conventional and AMS radiocarbon dating from mangrove and marine shells. So far 95 sites have been AMS (GrA-) or conventionally (GrN-) radiocarbon- dated. This paper describes the results obtained from three well-defined macro areas (Lake Siranda, the coastline between Cape Gadani and the Hab River mouth, and the Indus Delta) where the aforementioned research methodology has been applied. The results contribute to the interpretation of the archaeology of the coastal area of Pakistan and the Arabian Sea, the definition of the sea-level variations since the mid-Atlantic period, the presence/absence and exploitation of ancient mangroves, the dynamic of the Indus Delta advance, and the chronology of the early navigation along the northern coast of the Indian Ocean. Summary 1 Preface. – 2 A Radiocarbon Dating Programme. – 3 The Study Regions. – 3.1 Siranda Palaeo-Lagoon (Las Bela, Balochistan). – 3.2 The Coast Between Cape Gadani and the Hab River Mouth (Las Bela, Balochistan). -

Pakistan Heritage
VOLUME 10, 2018 ISSN 2073-641X PAKISTAN HERITAGE Editors Shakirullah and Ruth Young Research Journal of the Department of Archaeology Hazara University Mansehra-Pakistan Pakistan Heritage is an internationally peer reviewed, HEC recognised research journal, published annually by the Department of Archaeology, Hazara University Mansehra, Pakistan with the approval of the Vice Chancellor. It is indexed with International Scientific Indexing (ISI), Al-Manhal and Arts and Archaeology Technical Abstracts (A & ATA). It is also enlisted with many national and international agencies like Library of Congress, Ulrich, etc. No part in of the material contained in this journal should be reproduced in any form without prior permission of the editor (s). Price: PKR 1500/- US$ 20/- All correspondence related to the journal should be addressed to: The Editors/Asst. Editor Pakistan Heritage Department of Archaeology Hazara University Mansehra, Pakistan [email protected] [email protected] Printed at: M Z Graphics, Peshawar, Pakistan Ph: +92-91-2592294 Email: [email protected] Editors Dr. Shakirullah Head of the Department of Archaeology Hazara University Mansehra, Pakistan Dr. Ruth Young Senior Lecturer and Director Distance Learning Strategies School of Archaeology and Ancient History University of Leicester, Leicester LE1 7RH United Kingdom Assistant Editor Dr. Abdul Hameed Assistant Professor, Department of Archaeology Hazara University Mansehra, Pakistan Board of Editorial Advisors Pakistan Heritage, Volume 10 (2018) Professor Jonathan -

India and the Bay of Bengal
PUB. 173 SAILING DIRECTIONS (ENROUTE) ★ INDIA AND THE BAY OF BENGAL ★ Prepared and published by the NATIONAL GEOSPATIAL-INTELLIGENCE AGENCY Bethesda, Maryland © COPYRIGHT 2005 BY THE UNITED STATES GOVERNMENT NO COPYRIGHT CLAIMED UNDER TITLE 17 U.S.C. 2005 EIGHTH EDITION For sale by the Superintendent of Documents, U.S. Government Printing Office Internet: http://bookstore.gpo.gov Phone: toll free (866) 512-1800; DC area (202) 512-1800 Fax: (202) 512-2250 Mail Stop: SSOP, Washington, DC 20402-0001 Preface 0.0 Pub. 173, Sailing Directions (Enroute) India and the Bay of and navigate so that the designated course is continuously Bengal, Eighth Edition, 2005, is issued for use in conjunction being made good. with Pub. 160, Sailing Directions (Planning Guide) South At- 0.0 Currents.—Current directions are the true directions toward lantic Ocean and Indian Ocean. The companion volumes are which currents set. Pubs. 171, 172, 174, and 175. 0.0 Dangers.—As a rule outer dangers are fully described, but inner dangers which are well-charted are, for the most part, 0.0 This publication has been corrected to 13 August 2005, in- omitted. Numerous offshore dangers, grouped together, are cluding Notice to Mariners No. 33 of 2005. mentioned only in general terms. Dangers adjacent to a coastal passage or fairway are described. Explanatory Remarks 0.0 Distances.—Distances are expressed in nautical miles of 1 minute of latitude. Distances of less than 1 mile are expressed 0.0 Sailing Directions are published by the National Geospatial- in meters, or tenths of miles. Intelligence Agency (NGA), under the authority of Department 0.0 Geographic Names.—Geographic names are generally of Defense Directive 5105.40, dated 12 December 1988, and those used by the nation having sovereignty. -
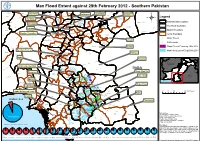
India Max Flood Extent Against 29Th February 2012
Max Flood Extent against 29th February 2012 - Southern Pakistan R R R R R R Nuttal Shahpur Derawar Fort Sanni Bhag R Rajhan Shaikh Salar Bhag Chattar R Garhi Ikhtiar Khan R Kalat R Mamatawa Asreli Chauki R Nasirabad Gandawa Gandava R SuiJacobabad R SuiJaffarabad R Shori Data De- Excluded Area Rajanpur Rojhan Kashmore R Khanpur (Rahim Yar Khan) Kharan Zehri Dera murad jamali Shahwali Surab Sohbatpur R R Tamboo Rahim Yar Khan Legend Garruk Kashmore R JhalGazan Magsi Abad R Rahim Yar Khan R R Baba kot R Khan Jhatpat R R Khangarh Jhat Pat R Toba R R Anjira Jaccobabad Kashmore Yazman Nawa Kot Surab Jhal Magsi R R . International boundary Jacobabad R R Thul Sadiqabad Khanpur R Kandhkot Sadiqabad Kandi R Thul R ShikarpurR Tangwani Jacobabad Mirpur Jhal Magsi Jaffarabad R Ubauro R Ghauspur UbauroR Usta Muhammad R Provincial boundary Alat Hatachi Liaquatpur R R Bijnot Garhi Khairo Kanhdkot R Gandakha R Shikarpur Mirpur Mathelo Larkana Khanpur (Shikarpur) R Garhi Khairo Ghotki Besima Shikarpur District boundary R Shahdadkot Kakiwala Toba Pariko Garhi Yasin R R Tebri R Sandh R Pano Aqil R Khuzdar Shahdadkot Garhi Yasin Lakhi Khanpur Islamgarh Qambar Shadadkot R Pano Aqil R R R Shireza Khuzdar Qubo Saeed Khan Raiodero R R R Daharki Tehsil boundary Karkh R Miro Khan Sukkur Dabar Wahan Mirpur Mathelo Sukkur Zidi R Nai R R Rohri R R Ratodero R Major Towns Sangrar Ghaibi Dero Qambar Shahdad Kot R Nandewaro Kambar Ali Khan R R Kingri Rohri R Larkana Ghotki R Khairpur Larkana R !( Khairpur Mithrau R Settlements Gambat Khangarh Mamro Warah Nasirabad R Haji