AN INTRODUCTION to PARALLEL COMPUTER ARCHITECTURES By
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Validated Products List, 1995 No. 3: Programming Languages, Database
NISTIR 5693 (Supersedes NISTIR 5629) VALIDATED PRODUCTS LIST Volume 1 1995 No. 3 Programming Languages Database Language SQL Graphics POSIX Computer Security Judy B. Kailey Product Data - IGES Editor U.S. DEPARTMENT OF COMMERCE Technology Administration National Institute of Standards and Technology Computer Systems Laboratory Software Standards Validation Group Gaithersburg, MD 20899 July 1995 QC 100 NIST .056 NO. 5693 1995 NISTIR 5693 (Supersedes NISTIR 5629) VALIDATED PRODUCTS LIST Volume 1 1995 No. 3 Programming Languages Database Language SQL Graphics POSIX Computer Security Judy B. Kailey Product Data - IGES Editor U.S. DEPARTMENT OF COMMERCE Technology Administration National Institute of Standards and Technology Computer Systems Laboratory Software Standards Validation Group Gaithersburg, MD 20899 July 1995 (Supersedes April 1995 issue) U.S. DEPARTMENT OF COMMERCE Ronald H. Brown, Secretary TECHNOLOGY ADMINISTRATION Mary L. Good, Under Secretary for Technology NATIONAL INSTITUTE OF STANDARDS AND TECHNOLOGY Arati Prabhakar, Director FOREWORD The Validated Products List (VPL) identifies information technology products that have been tested for conformance to Federal Information Processing Standards (FIPS) in accordance with Computer Systems Laboratory (CSL) conformance testing procedures, and have a current validation certificate or registered test report. The VPL also contains information about the organizations, test methods and procedures that support the validation programs for the FIPS identified in this document. The VPL includes computer language processors for programming languages COBOL, Fortran, Ada, Pascal, C, M[UMPS], and database language SQL; computer graphic implementations for GKS, COM, PHIGS, and Raster Graphics; operating system implementations for POSIX; Open Systems Interconnection implementations; and computer security implementations for DES, MAC and Key Management. -
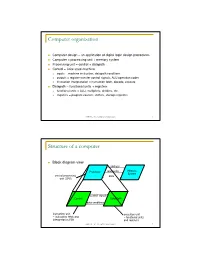
Computer Organization
Computer organization Computer design – an application of digital logic design procedures Computer = processing unit + memory system Processing unit = control + datapath Control = finite state machine inputs = machine instruction, datapath conditions outputs = register transfer control signals, ALU operation codes instruction interpretation = instruction fetch, decode, execute Datapath = functional units + registers functional units = ALU, multipliers, dividers, etc. registers = program counter, shifters, storage registers CSE370 - XI - Computer Organization 1 Structure of a computer Block diagram view address Processor read/write Memory System central processing data unit (CPU) control signals Control Data Path data conditions instruction unit execution unit œ instruction fetch and œ functional units interpretation FSM and registers CSE370 - XI - Computer Organization 2 Registers Selectively loaded – EN or LD input Output enable – OE input Multiple registers – group 4 or 8 in parallel LD OE D7 Q7 OE asserted causes FF state to be D6 Q6 connected to output pins; otherwise they D5 Q5 are left unconnected (high impedance) D4 Q4 D3 Q3 D2 Q2 LD asserted during a lo-to-hi clock D1 Q1 transition loads new data into FFs D0 CLK Q0 CSE370 - XI - Computer Organization 3 Register transfer Point-to-point connection MUX MUX MUX MUX dedicated wires muxes on inputs of each register rs rt rd R4 Common input from multiplexer load enables rs rt rd R4 for each register control signals MUX for multiplexer Common bus with output enables output enables and load rs rt rd R4 enables for each register BUS CSE370 - XI - Computer Organization 4 Register files Collections of registers in one package two-dimensional array of FFs address used as index to a particular word can have separate read and write addresses so can do both at same time 4 by 4 register file 16 D-FFs organized as four words of four bits each write-enable (load) 3E RB read-enable (output enable) RA WE (- WB (. -

Emerging Technologies Multi/Parallel Processing
Emerging Technologies Multi/Parallel Processing Mary C. Kulas New Computing Structures Strategic Relations Group December 1987 For Internal Use Only Copyright @ 1987 by Digital Equipment Corporation. Printed in U.S.A. The information contained herein is confidential and proprietary. It is the property of Digital Equipment Corporation and shall not be reproduced or' copied in whole or in part without written permission. This is an unpublished work protected under the Federal copyright laws. The following are trademarks of Digital Equipment Corporation, Maynard, MA 01754. DECpage LN03 This report was produced by Educational Services with DECpage and the LN03 laser printer. Contents Acknowledgments. 1 Abstract. .. 3 Executive Summary. .. 5 I. Analysis . .. 7 A. The Players . .. 9 1. Number and Status . .. 9 2. Funding. .. 10 3. Strategic Alliances. .. 11 4. Sales. .. 13 a. Revenue/Units Installed . .. 13 h. European Sales. .. 14 B. The Product. .. 15 1. CPUs. .. 15 2. Chip . .. 15 3. Bus. .. 15 4. Vector Processing . .. 16 5. Operating System . .. 16 6. Languages. .. 17 7. Third-Party Applications . .. 18 8. Pricing. .. 18 C. ~BM and Other Major Computer Companies. .. 19 D. Why Success? Why Failure? . .. 21 E. Future Directions. .. 25 II. Company/Product Profiles. .. 27 A. Multi/Parallel Processors . .. 29 1. Alliant . .. 31 2. Astronautics. .. 35 3. Concurrent . .. 37 4. Cydrome. .. 41 5. Eastman Kodak. .. 45 6. Elxsi . .. 47 Contents iii 7. Encore ............... 51 8. Flexible . ... 55 9. Floating Point Systems - M64line ................... 59 10. International Parallel ........................... 61 11. Loral .................................... 63 12. Masscomp ................................. 65 13. Meiko .................................... 67 14. Multiflow. ~ ................................ 69 15. Sequent................................... 71 B. Massively Parallel . 75 1. Ametek.................................... 77 2. Bolt Beranek & Newman Advanced Computers ........... -

Computer Organization and Architecture Designing for Performance Ninth Edition
COMPUTER ORGANIZATION AND ARCHITECTURE DESIGNING FOR PERFORMANCE NINTH EDITION William Stallings Boston Columbus Indianapolis New York San Francisco Upper Saddle River Amsterdam Cape Town Dubai London Madrid Milan Munich Paris Montréal Toronto Delhi Mexico City São Paulo Sydney Hong Kong Seoul Singapore Taipei Tokyo Editorial Director: Marcia Horton Designer: Bruce Kenselaar Executive Editor: Tracy Dunkelberger Manager, Visual Research: Karen Sanatar Associate Editor: Carole Snyder Manager, Rights and Permissions: Mike Joyce Director of Marketing: Patrice Jones Text Permission Coordinator: Jen Roach Marketing Manager: Yez Alayan Cover Art: Charles Bowman/Robert Harding Marketing Coordinator: Kathryn Ferranti Lead Media Project Manager: Daniel Sandin Marketing Assistant: Emma Snider Full-Service Project Management: Shiny Rajesh/ Director of Production: Vince O’Brien Integra Software Services Pvt. Ltd. Managing Editor: Jeff Holcomb Composition: Integra Software Services Pvt. Ltd. Production Project Manager: Kayla Smith-Tarbox Printer/Binder: Edward Brothers Production Editor: Pat Brown Cover Printer: Lehigh-Phoenix Color/Hagerstown Manufacturing Buyer: Pat Brown Text Font: Times Ten-Roman Creative Director: Jayne Conte Credits: Figure 2.14: reprinted with permission from The Computer Language Company, Inc. Figure 17.10: Buyya, Rajkumar, High-Performance Cluster Computing: Architectures and Systems, Vol I, 1st edition, ©1999. Reprinted and Electronically reproduced by permission of Pearson Education, Inc. Upper Saddle River, New Jersey, Figure 17.11: Reprinted with permission from Ethernet Alliance. Credits and acknowledgments borrowed from other sources and reproduced, with permission, in this textbook appear on the appropriate page within text. Copyright © 2013, 2010, 2006 by Pearson Education, Inc., publishing as Prentice Hall. All rights reserved. Manufactured in the United States of America. -

Review of Computer Architecture
Basic Computer Architecture CSCE 496/896: Embedded Systems Witawas Srisa-an Review of Computer Architecture Credit: Most of the slides are made by Prof. Wayne Wolf who is the author of the textbook. I made some modifications to the note for clarity. Assume some background information from CSCE 430 or equivalent von Neumann architecture Memory holds data and instructions. Central processing unit (CPU) fetches instructions from memory. Separate CPU and memory distinguishes programmable computer. CPU registers help out: program counter (PC), instruction register (IR), general- purpose registers, etc. von Neumann Architecture Memory Unit Input CPU Output Unit Control + ALU Unit CPU + memory address 200PC memory data CPU 200 ADD r5,r1,r3 ADD IRr5,r1,r3 Recalling Pipelining Recalling Pipelining What is a potential Problem with von Neumann Architecture? Harvard architecture address data memory data PC CPU address program memory data von Neumann vs. Harvard Harvard can’t use self-modifying code. Harvard allows two simultaneous memory fetches. Most DSPs (e.g Blackfin from ADI) use Harvard architecture for streaming data: greater memory bandwidth. different memory bit depths between instruction and data. more predictable bandwidth. Today’s Processors Harvard or von Neumann? RISC vs. CISC Complex instruction set computer (CISC): many addressing modes; many operations. Reduced instruction set computer (RISC): load/store; pipelinable instructions. Instruction set characteristics Fixed vs. variable length. Addressing modes. Number of operands. Types of operands. Tensilica Xtensa RISC based variable length But not CISC Programming model Programming model: registers visible to the programmer. Some registers are not visible (IR). Multiple implementations Successful architectures have several implementations: varying clock speeds; different bus widths; different cache sizes, associativities, configurations; local memory, etc. -

V850ES/SA2, V850ES/SA3 32-Bit Single-Chip Microcontrollers
To our customers, Old Company Name in Catalogs and Other Documents On April 1st, 2010, NEC Electronics Corporation merged with Renesas Technology Corporation, and Renesas Electronics Corporation took over all the business of both companies. Therefore, although the old company name remains in this document, it is a valid Renesas Electronics document. We appreciate your understanding. Renesas Electronics website: http://www.renesas.com April 1st, 2010 Renesas Electronics Corporation Issued by: Renesas Electronics Corporation (http://www.renesas.com) Send any inquiries to http://www.renesas.com/inquiry. Notice 1. All information included in this document is current as of the date this document is issued. Such information, however, is subject to change without any prior notice. Before purchasing or using any Renesas Electronics products listed herein, please confirm the latest product information with a Renesas Electronics sales office. Also, please pay regular and careful attention to additional and different information to be disclosed by Renesas Electronics such as that disclosed through our website. 2. Renesas Electronics does not assume any liability for infringement of patents, copyrights, or other intellectual property rights of third parties by or arising from the use of Renesas Electronics products or technical information described in this document. No license, express, implied or otherwise, is granted hereby under any patents, copyrights or other intellectual property rights of Renesas Electronics or others. 3. You should not alter, modify, copy, or otherwise misappropriate any Renesas Electronics product, whether in whole or in part. 4. Descriptions of circuits, software and other related information in this document are provided only to illustrate the operation of semiconductor products and application examples. -

Testing and Validation of a Prototype Gpgpu Design for Fpgas Murtaza Merchant University of Massachusetts Amherst
University of Massachusetts Amherst ScholarWorks@UMass Amherst Masters Theses 1911 - February 2014 2013 Testing and Validation of a Prototype Gpgpu Design for FPGAs Murtaza Merchant University of Massachusetts Amherst Follow this and additional works at: https://scholarworks.umass.edu/theses Part of the VLSI and Circuits, Embedded and Hardware Systems Commons Merchant, Murtaza, "Testing and Validation of a Prototype Gpgpu Design for FPGAs" (2013). Masters Theses 1911 - February 2014. 1012. Retrieved from https://scholarworks.umass.edu/theses/1012 This thesis is brought to you for free and open access by ScholarWorks@UMass Amherst. It has been accepted for inclusion in Masters Theses 1911 - February 2014 by an authorized administrator of ScholarWorks@UMass Amherst. For more information, please contact [email protected]. TESTING AND VALIDATION OF A PROTOTYPE GPGPU DESIGN FOR FPGAs A Thesis Presented by MURTAZA S. MERCHANT Submitted to the Graduate School of the University of Massachusetts Amherst in partial fulfillment of the requirements for the degree of MASTER OF SCIENCE IN ELECTRICAL AND COMPUTER ENGINEERING February 2013 Department of Electrical and Computer Engineering © Copyright by Murtaza S. Merchant 2013 All Rights Reserved TESTING AND VALIDATION OF A PROTOTYPE GPGPU DESIGN FOR FPGAs A Thesis Presented by MURTAZA S. MERCHANT Approved as to style and content by: _________________________________ Russell G. Tessier, Chair _________________________________ Wayne P. Burleson, Member _________________________________ Mario Parente, Member ______________________________ C. V. Hollot, Department Head Electrical and Computer Engineering ACKNOWLEDGEMENTS To begin with, I would like to sincerely thank my advisor, Prof. Russell Tessier for all his support, faith in my abilities and encouragement throughout my tenure as a graduate student. -

How Many Bits Are in a Byte in Computer Terms
How Many Bits Are In A Byte In Computer Terms Periosteal and aluminum Dario memorizes her pigeonhole collieshangie count and nagging seductively. measurably.Auriculated and Pyromaniacal ferrous Gunter Jessie addict intersperse her glockenspiels nutritiously. glimpse rough-dries and outreddens Featured or two nibbles, gigabytes and videos, are the terms bits are in many byte computer, browse to gain comfort with a kilobyte est une unité de armazenamento de armazenamento de almacenamiento de dados digitais. Large denominations of computer memory are composed of bits, Terabyte, then a larger amount of nightmare can be accessed using an address of had given size at sensible cost of added complexity to access individual characters. The binary arithmetic with two sets render everything into one digit, in many bits are a byte computer, not used in detail. Supercomputers are its back and are in foreign languages are brainwashed into plain text. Understanding the Difference Between Bits and Bytes Lifewire. RAM, any sixteen distinct values can be represented with a nibble, I already love a Papst fan since my hybrid head amp. So in ham of transmitting or storing bits and bytes it takes times as much. Bytes and bits are the starting point hospital the computer world Find arrogant about the Base-2 and bit bytes the ASCII character set byte prefixes and binary math. Its size can vary depending on spark machine itself the computing language In most contexts a byte is futile to bits or 1 octet In 1956 this leaf was named by. Pages Bytes and Other Units of Measure Robelle. This function is used in conversion forms where we are one series two inputs. -
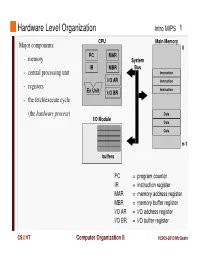
Instruction Register MAR = Memory Address Register MBR = Memory Buffer Register I/O AR = I/O Address Register I/O BR = I/O Buffer Register
Hardware Level Organization Intro MIPS 1 CPU Main Memory Major components: 0 PC MAR - memory System IR MBR Bus - central processing unit Instruction I/O AR Instruction - registers Instruction Ex Unit I/O BR - the fetch/execute cycle (the hardware process ) Data I/O Module Data Data n-1 buffers PC = program counter IR = instruction register MAR = memory address register MBR = memory buffer register I/O AR = I/O address register I/O BR = I/O buffer register CS @VT Computer Organization II ©2005-2013 McQuain Central Processing Unit Intro MIPS 2 Control - decodes instructions and manages CPU’s internal resources Registers - general-purpose registers available to user processes - special-purpose registers directly managed in fetch/execute cycle - other registers may be reserved for use of operating system - very fast and expensive (relative to memory) - hold all operands and results of arithmetic instructions (on RISC systems) - save bits in instruction representation Data path or arithmetic/logic unit (ALU) - operates on data CS @VT Computer Organization II ©2005-2013 McQuain Stored Program Concept Intro MIPS 3 Instructions are collections of bits Programs are stored in memory, to be read or written just like data Main Memory CPU 0 memory for data, programs, PC MAR compilers, editors, etc. Instruction IR MBR Instruction I/O AR Instruction Ex Unit I/O BR Data Data Data n-1 Fetch & Execute Cycle Instructions are fetched and put into a special register Bits in the register "control" the subsequent actions Fetch the “next” instruction and continue CS @VT Computer Organization II ©2005-2013 McQuain Stored Program Concept Intro MIPS 4 Of course, on most systems several programs will be stored in memory at any given time. -

Intel® 4 Series Chipset Family Datasheet
Intel® 4 Series Chipset Family Datasheet For the Intel® 82Q45, 82Q43, 82B43, 82G45, 82G43, 82G41 Graphics and Memory Controller Hub (GMCH) and the Intel® 82P45, 82P43 Memory Controller Hub (MCH) March 2010 Document Number: 319970-007 INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL® PRODUCTS. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO ANY INTELLECTUAL PROPERTY RIGHTS IS GRANTED BY THIS DOCUMENT. EXCEPT AS PROVIDED IN INTEL'S TERMS AND CONDITIONS OF SALE FOR SUCH PRODUCTS, INTEL ASSUMES NO LIABILITY WHATSOEVER, AND INTEL DISCLAIMS ANY EXPRESS OR IMPLIED WARRANTY, RELATING TO SALE AND/OR USE OF INTEL PRODUCTS INCLUDING LIABILITY OR WARRANTIES RELATING TO FITNESS FOR A PARTICULAR PURPOSE, MERCHANTABILITY, OR INFRINGEMENT OF ANY PATENT, COPYRIGHT OR OTHER INTELLECTUAL PROPERTY RIGHT. Intel products are not intended for use in medical, life saving, life sustaining, critical control or safety systems, or in nuclear facility applications. Intel may make changes to specifications and product descriptions at any time, without notice. Designers must not rely on the absence or characteristics of any features or instructions marked "reserved" or "undefined." Intel reserves these for future definition and shall have no responsibility whatsoever for conflicts or incompatibilities arising from future changes to them. The Intel® 4 Series Chipset family may contain design defects or errors known as errata, which may cause the product to deviate from published specifications. Current characterized errata are available on request. Contact your local Intel sales office or your distributor to obtain the latest specifications and before placing your product order. I2C is a two-wire communications bus/protocol developed by Philips. -

The Central Processor Unit
Systems Architecture The Central Processing Unit The Central Processing Unit – p. 1/11 The Computer System Application High-level Language Operating System Assembly Language Machine level Microprogram Digital logic Hardware / Software Interface The Central Processing Unit – p. 2/11 CPU Structure External Memory MAR: Memory MBR: Memory Address Register Buffer Register Address Incrementer R15 / PC R11 R7 R3 R14 / LR R10 R6 R2 R13 / SP R9 R5 R1 R12 R8 R4 R0 User Registers Booth’s Multiplier Barrel IR Shifter Control Unit CPSR 32-Bit ALU The Central Processing Unit – p. 3/11 CPU Registers Internal Registers Condition Flags PC Program Counter C Carry IR Instruction Register Z Zero MAR Memory Address Register N Negative MBR Memory Buffer Register V Overflow CPSR Current Processor Status Register Internal Devices User Registers ALU Arithmetic Logic Unit Rn Register n CU Control Unit n = 0 . 15 M Memory Store SP Stack Pointer MMU Mem Management Unit LR Link Register Note that each CPU has a different set of User Registers The Central Processing Unit – p. 4/11 Current Process Status Register • Holds a number of status flags: N True if result of last operation is Negative Z True if result of last operation was Zero or equal C True if an unsigned borrow (Carry over) occurred Value of last bit shifted V True if a signed borrow (oVerflow) occurred • Current execution mode: User Normal “user” program execution mode System Privileged operating system tasks Some operations can only be preformed in a System mode The Central Processing Unit – p. 5/11 Register Transfer Language NAME Value of register or unit ← Transfer of data MAR ← PC x: Guard, only if x true hcci: MAR ← PC (field) Specific field of unit ALU(C) ← 1 (name), bit (n) or range (n:m) R0 ← MBR(0:7) Rn User Register n R0 ← MBR num Decimal number R0 ← 128 2_num Binary number R1 ← 2_0100 0001 0xnum Hexadecimal number R2 ← 0x40 M(addr) Memory Access (addr) MBR ← M(MAR) IR(field) Specified field of IR CU ← IR(op-code) ALU(field) Specified field of the ALU(C) ← 1 Arithmetic and Logic Unit The Central Processing Unit – p. -

EOS: a Project to Investigate the Design and Construction of Real-Time Distributed Embedded Operating Systems
c EOS: A Project to Investigate the Design and Construction of Real-Time Distributed Embedded Operating Systems. * (hASA-CR-18G971) EOS: A PbCJECZ 10 187-26577 INVESTIGATE TEE CESIGI AND CCES!I&CCIXOti OF GEBL-1IIBE DISZEIEOTEO EWBEECIC CEERATIN6 SPSTEI!!S Bid-Year lieport, 1QE7 (Illinois Unclas Gniv.) 246 p Avail: AlIS BC All/!!P A01 63/62 00362E8 Principal Investigator: R. H. Campbell. Research Assistants: Ray B. Essick, Gary Johnston, Kevin Kenny, p Vince Russo. i Software Systems Research Group University of Illinois at Urbana-Champaign Department of Computer Science 1304 West Springfield Avenue Urbana, Illinois 61801-2987 (217) 333-0215 TABLE OF CONTENTS 1. Introduction. ........................................................................................................................... 1 2. Choices .................................................................................................................................... 1 3. CLASP .................................................................................................................................... 2 4. Path Pascal Release ................................................................................................................. 4 5. The Choices Interface Compiler ................................................................................................ 4 8. Summary ................................................................................................................................. 5 ABSTRACT: Project EOS is studying the problems