User Authentication and Detection of Malicious Actions
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Webové Diskusní Fórum
MASARYKOVA UNIVERZITA F}w¡¢£¤¥¦§¨ AKULTA INFORMATIKY !"#$%&'()+,-./012345<yA| Webové diskusní fórum BAKALÁRSKÁˇ PRÁCE Martin Bana´s Brno, Jaro 2009 Prohlášení Prohlašuji, že tato bakaláˇrskápráce je mým p ˚uvodnímautorským dílem, které jsem vy- pracoval samostatnˇe.Všechny zdroje, prameny a literaturu, které jsem pˇrivypracování používal nebo z nich ˇcerpal,v práci ˇrádnˇecituji s uvedením úplného odkazu na pˇríslušný zdroj. V Brnˇe,dne . Podpis: . Vedoucí práce: prof. RNDr. JiˇríHˇrebíˇcek,CSc. ii Podˇekování Dˇekujivedoucímu prof. RNDr. JiˇrímuHˇrebíˇckovi,CSc. za správné vedení v pr ˚ubˇehucelé práce a trpˇelivostpˇrikonzutacích. Dále dˇekujicelému kolektivu podílejícímu se na reali- zaci projektu FEED za podnˇetnépˇripomínkya postˇrehy. iii Shrnutí Bakaláˇrskápráce se zabývá analýzou souˇcasnýchdiskusních fór typu open-source a vý- bˇerem nejvhodnˇejšíhodiskusního fóra pro projekt eParticipation FEED. Další ˇcástpráce je zamˇeˇrenána analýzu vybraného fóra, tvorbu ˇceskéhomanuálu, ˇceskélokalizace pro portál a rozšíˇrenípro anotaci pˇríspˇevk˚u. Poslední kapitola je vˇenovánanasazení systému do provozu a testování rozšíˇrení pro anotaci pˇríspˇevk˚u. iv Klíˇcováslova projekt FEED, eParticipation, diskusní fórum, portál, PHP, MySQL, HTML v Obsah 1 Úvod ...........................................3 2 Projekt eParticipation FEED .............................4 2.1 eGovernment ...................................4 2.2 Úˇcastníciprojektu FEED .............................4 2.3 Zamˇeˇreníprojektu FEED .............................5 2.4 Cíl -

What the Floc?
Security Now! Transcript of Episode #811 Page 1 of 30 Transcript of Episode #811 What the FLoC? Description: This week we briefly, I promise, catch up with ProxyLogon news regarding Windows Defender and the Black Kingdom. We look at Firefox's next release which will be changing its Referer header policy for the better. We look at this week's most recent RCE disaster, a critical vulnerability in the open source MyBB forum software, and China's new CAID (China Anonymization ID). We then conclude by taking a good look at Google's plan to replace tracking with explicit recent browsing history profiling, which is probably the best way to understand FLoC (Federated Learning of Cohorts). And as a special bonus we almost certainly figure out why they named it something so awful. High quality (64 kbps) mp3 audio file URL: http://media.GRC.com/sn/SN-811.mp3 Quarter size (16 kbps) mp3 audio file URL: http://media.GRC.com/sn/sn-811-lq.mp3 SHOW TEASE: It's time for Security Now!. Steve Gibson is here. We've got a new fix for the Microsoft Exchange Server flaw. This one's automatic, thanks to Microsoft. We'll also take a look at some nice new features in Firefox 87. You can get it right now. And then, what the FLoC? We'll take a look at Google's proposal for replacing third-party cookies. Is it better? It's all coming up next on Security Now!. Leo Laporte: This is Security Now! with Steve Gibson, Episode 811, recorded Tuesday, March 23rd, 2021: What the FLoC? It's time for Security Now!, the show where we cover your privacy, your security, your safety online with this guy right here, Steve Gibson from GRC.com. -

Appendix a the Ten Commandments for Websites
Appendix A The Ten Commandments for Websites Welcome to the appendixes! At this stage in your learning, you should have all the basic skills you require to build a high-quality website with insightful consideration given to aspects such as accessibility, search engine optimization, usability, and all the other concepts that web designers and developers think about on a daily basis. Hopefully with all the different elements covered in this book, you now have a solid understanding as to what goes into building a website (much more than code!). The main thing you should take from this book is that you don’t need to be an expert at everything but ensuring that you take the time to notice what’s out there and deciding what will best help your site are among the most important elements of the process. As you leave this book and go on to updating your website over time and perhaps learning new skills, always remember to be brave, take risks (through trial and error), and never feel that things are getting too hard. If you choose to learn skills that were only briefly mentioned in this book, like scripting, or to get involved in using content management systems and web software, go at a pace that you feel comfortable with. With that in mind, let’s go over the 10 most important messages I would personally recommend. After that, I’ll give you some useful resources like important websites for people learning to create for the Internet and handy software. Advice is something many professional designers and developers give out in spades after learning some harsh lessons from what their own bitter experiences. -

A Survey on Content Management System, Software's and Tools
ISSN (Online) 2393-8021 IARJSET ISSN (Print) 2394-1588 International Advanced Research Journal in Science, Engineering and Technology ISO 3297:2007 Certified Vol. 4, Issue 11, November 2017 A Survey on Content Management System, Software's and Tools Madhura K Assistant Professor, Computer Science Department, Presidency University, Bangalore1 Abstract: This paper contains a survey of content management system, content management process, architecture and working. Also contains different types of tools and software. Content Management (CM) is the process for collection, delivery, retrieval, governance and overall management of information in any format. The term is typically used in reference to administration of the digital content lifecycle, from creation to permanent storage or deletion. The content involved may be images, video, audio and multimedia as well as text. A Content Management System (CMS) is a computer application that supports the creation and modification of digital content. It is typically used to support multiple users working in a collaborative environment. A Content Management System (CMS) is a tool for creating and managing digital content such as documents, text, web pages, videos and images.A content management system (CMS) is a software application or set of related programs that are used to create and manage digital content. CMSes are typically used for Enterprise Content Management (ECM) and Web Content Management (WCM). An ECM facilitates collaboration in the workplace by integrating document management, digital asset management and records retention functionalities, and providing end users with role-based access to the organization's digital assets. A WCM facilitates collaborative authoring for websites. ECM software often includes a WCM publishing functionality, but ECM webpages typically remain behind the organization's firewall. -
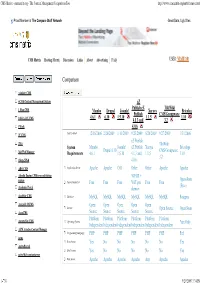
CMS Matrix - Cmsmatrix.Org - the Content Management Comparison Tool
CMS Matrix - cmsmatrix.org - The Content Management Comparison Tool http://www.cmsmatrix.org/matrix/cms-matrix Proud Member of The Compare Stuff Network Great Data, Ugly Sites CMS Matrix Hosting Matrix Discussion Links About Advertising FAQ USER: VISITOR Compare Search Return to Matrix Comparison <sitekit> CMS +CMS Content Management System eZ Publish eZ TikiWiki 1 Man CMS Mambo Drupal Joomla! Xaraya Bricolage Publish CMS/Groupware 4.6.1 6.10 1.5.10 1.1.5 1.10 1024 AJAX CMS 4.1.3 and 3.2 1Work 4.0.6 2F CMS Last Updated 12/16/2006 2/26/2009 1/11/2009 9/23/2009 8/20/2009 9/27/2009 1/31/2006 eZ Publish 2flex TikiWiki System Mambo Joomla! eZ Publish Xaraya Bricolage Drupal 6.10 CMS/Groupware 360 Web Manager Requirements 4.6.1 1.5.10 4.1.3 and 1.1.5 1.10 3.2 4Steps2Web 4.0.6 ABO.CMS Application Server Apache Apache CGI Other Other Apache Apache Absolut Engine CMS/news publishing 30EUR + system Open-Source Approximate Cost Free Free Free VAT per Free Free (Free) Academic Portal domain AccelSite CMS Database MySQL MySQL MySQL MySQL MySQL MySQL Postgres Accessify WCMS Open Open Open Open Open License Open Source Open Source AccuCMS Source Source Source Source Source Platform Platform Platform Platform Platform Platform Accura Site CMS Operating System *nix Only Independent Independent Independent Independent Independent Independent ACM Ariadne Content Manager Programming Language PHP PHP PHP PHP PHP PHP Perl acms Root Access Yes No No No No No Yes ActivePortail Shell Access Yes No No No No No Yes activeWeb contentserver Web Server Apache Apache -

Silverstripe
silverstripe #silverstripe 1 1: 2 2 2 Examples 2 2 CMS / 2 2: DataExtensions 4 Examples 4 DataObject 4 DataObject 4 DataExtension 4 3: LeftAndMain 6 6 Examples 6 1. 6 6 6 6 2. HelloWorldLeftAndMain.php 6 7 7 7 3. (HelloWorldLeftAndMain_Content.ss) 8 . 8 8 4: ModelAdmin 9 Examples 9 9 UI DataObject 9 DataObject . 9 DataObject 9 searchable_fields ModelAdmin . 10 GridField 10 ModelAdmin 11 5: ORM 12 Examples 12 DataObject 12 6: 13 13 ? 13 13 Examples 13 13 13 YAML 13 13 7: 15 15 Examples 15 SilverStripe Grid 15 GridField 15 15 15 CMS 16 16 8: 17 17 Examples 17 17 AJAX 17 17 19 20 : 20 9: 22 22 Examples 22 MyClass.php 22 23 You can share this PDF with anyone you feel could benefit from it, downloaded the latest version from: silverstripe It is an unofficial and free silverstripe ebook created for educational purposes. All the content is extracted from Stack Overflow Documentation, which is written by many hardworking individuals at Stack Overflow. It is neither affiliated with Stack Overflow nor official silverstripe. The content is released under Creative Commons BY-SA, and the list of contributors to each chapter are provided in the credits section at the end of this book. Images may be copyright of their respective owners unless otherwise specified. All trademarks and registered trademarks are the property of their respective company owners. Use the content presented in this book at your own risk; it is not guaranteed to be correct nor accurate, please send your feedback and corrections to [email protected] https://riptutorial.com/ko/home 1 1: Silverstripe PHP . -

Emulator for Complex Sensor- Based IT System
Degree project Emulator for complex sensor- based IT system Author: Ruslan Gederin and Viktor Mazepa Supervisor: Rüdiger Lincke External Supervisor: Per-Olov Thorén Date: 2013-09-30 Course code: 5DV00E, 30 credits Level: Master Department of Computer Science Acknowledgments First of all we want to express gratitude to our supervisor, Dr. Rüdiger Lincke for an interesting master thesis topic and for great work experience with him and his company Softwerk. We would also like to thank to: • Per-Olov Thorén and Ingela Stålberg for interesting meetings and for the opportunity to work on a real commercial project. • Maksym Ponomarenko and Viktor Kostov for excellent management of our work at our remote period. • Oryna Podoba and Illia Klimov for good collaborations during development. • Our families, relatives and friends for their support during our studying in Sweden. ii Abstract Developing and testing complex information technology (IT) systems is a difficult task. This is even more difficult if parts of the system, no matter if hard- or software, are not available when needed due to delays or other reasons. The architecture and design cannot be evaluated and existing parts cannot be reliably tested. Thus the whole concept of the system cannot be validated before all parts are in place. To solve this problem in an industrial project, where the development of the server- side should be finished and tested (clear for production) while the hardware sensors where designed but not implemented, we developed an emulator (software) for the hardware sensors meeting the exact specification as well as parts of the server solution. This allowed proceeding with the server-side development, testing, and system validation without the hardware sensors in place. -

Opettajan Arvio Opinnäytetyöstä
Harrison Oriahi CONTENT MANAGEMENT SYSTEMS (CMS) CONTENT MANAGEMENT SYSTEMS (CMS) Harrison Oriahi Bachelor’s thesis Autumn 2014 Degree Programme in Information Technology Oulu University of Applied Sciences ABSTRACT Oulu University of Applied Sciences Degree in Information Technology, Internet Services Author(s): Harrison Oriahi Title of Bachelor’s thesis: Content Management Systems Supervisor(s): Veijo Väisänen Term and year of completion: Autumn 2014 Number of pages: 48 + 3 appendices ABSTRACT: This thesis describes the three most common and widely used content management systems (CMS) used to power several millions of business websites on the internet. Since there are many other content managements systems online, this report provides some helpful guides on each of these three most used systems and the web design projects that each of them maybe most suitable. There are plenty of options when it comes to selecting a content management system for a development project and this thesis focuses on making a detailed comparison between the three most commonly used ones. This comparison will help provide a clear understanding of why a content management system maybe preferred to the other when considering any web design project. To help detect the content management system (CMS) or development platform that an already existing website is built on, some helpful website analyzing tools are also discussed in this report. By reading this report, a reader with no previous experience with content management systems will be able to have a general view on what they are, what the commonly used ones are and what to consider when making a choice of content management system to use. -

3Rd Eye Vision Credentials Summer 2016 Intro
3rd Eye Vision Credentials Summer 2016 Intro Thank you for your interest in 3rd Eye Vision. Contents These are our credentials, they should give you an insight into what we do, what we’re like and how 04 About Us we work. To find out more, give us a call. 05 What We Do 06 Process 08 Who We Are 10 Case Studies 24 Spotlights 28 What Next ? 2 Things you’ll notice: When you start working with us, you’ll see that we’re a bit different to other agencies. Your project will be right first time When you speak, we listen very carefully. Requests are logged so they can’t be missed. We value your time by making sure everything is good to go. Your ideas are heard Okay, so we might be the experts with oodles of technical smarts, but we respect your knowledge of your business and your industry. So we want to hear what you think. Your requirements are met We’re a bunch of reactionaries. That’s right. We react to the changing situation on the ground. And by ground we don’t mean ground at all. If your needs change, we respond. We’re flexible like that. 3 About us Often considered as the London agency by the sea, we are an established digital agency providing strategy, design and development services for our clients. Established in 1998 (yes that We have been interdisciplinary makes us 18 years old!) we since before it became cool, have an agile team of 12. we thrive from our shared We’ve been working on passion for innovative ideas. -

Society of American Archivists Council Meeting August 25, 2008 San Francisco, California
Agenda Item II.O. Society of American Archivists Council Meeting August 25, 2008 San Francisco, California Report: Website Working Group (Prepared by Brian Doyle, Chair) WORKING GROUP MEMBERS Brian Doyle, Chair Gregory Colati Christine Di Bella Chatham Ewing Jeanne Kramer-Smyth Mark Matienzo Aprille McKay Christopher Prom Seth Shaw Bruce Ambacher, Council Liaison BACKGROUND For several years, there has been a keen and growing interest among SAA’s members in the deployment of a robust content management system (CMS) featuring state-of-the-art Web 2.0 applications—wikis, blogs, RSS feeds, etc. While these types of programs are often associated with social networking, a comprehensive CMS would also redress a number of important organizational challenges that SAA faces: • How can SAA’s component groups (e.g., boards, committees, task forces, etc.) collaborate more effectively in an online environment? • How can official documents (e.g., minutes, reports, newsletters, etc.) be more easily published to the Web by SAA’s component groups, described and accessed via appropriate metadata, and scheduled for retention? • How can SAA enhance its online publishing capabilities and ensure that the necessary tools are available for authorized subject experts to edit and update such official electronic publications as Richard Pearce-Moses’ Glossary of Archival and Records Management Terminology , DACS Online, and the EAD Help Pages, as well as such important resources as an SAA standards portal or the Technology Best Practices Task Force working document? Report: Website Working Group Page 1 of 17 0808-1-WebWG-IIO SAA’s existing Web technology does not adequately fulfill these needs. -

Preventing Input Validation Vulnerabilities in Web Applications Through Automated Type Analysis
Preventing Input Validation Vulnerabilities in Web Applications through Automated Type Analysis Theodoor Scholte William Robertson SAP Research, Sophia Antipolis, France Northeastern University, Boston, USA [email protected] [email protected] Davide Balzarotti Engin Kirda Institut Eurecom, Sophia Antipolis, France Northeastern University, Boston, USA [email protected] [email protected] Abstract—Web applications have become an integral part dangerous HTML elements, typically including malicious of the daily lives of millions of users. Unfortunately, web client-side code that executes in the security context of a applications are also frequently targeted by attackers, and trusted web origin. In the latter case, a SQL injection injec- criticial vulnerabilities such as XSS and SQL injection are still common. As a consequence, much effort in the past decade has tion vulnerability allows an attacker to modify an existing been spent on mitigating web application vulnerabilities. database query — or, in some cases, to inject a completely Current techniques focus mainly on sanitization: either on new one — in such a way that violates the web application’s automated sanitization, the detection of missing sanitizers, desired data integrity or confidentiality policies. the correctness of sanitizers, or the correct placement of One particularly promising approach to preventing the sanitizers. However, these techniques are either not able to prevent new forms of input validation vulnerabilities such as exploitation of these vulnerabilities is robust, automated HTTP Parameter Pollution, come with large runtime overhead, sanitization of untrusted input. In this approach, filters, lack precision, or require significant modifications to the client or sanitizers, are automatically applied to user data such and/or server infrastructure. -

Evaluation of Password Hashing Schemes in Open Source Web
Evaluation of Password Hashing Schemes in Open Source Web Platforms Christoforos Ntantogian, Stefanos Malliaros, Christos Xenakis Department of Digital Systems, University of Piraeus, Piraeus, Greece {dadoyan, stefmal, xenakis}@unipi.gr Abstract: Nowadays, the majority of web platforms in the Internet originate either from CMS to easily deploy websites or by web applications frameworks that allow developers to design and implement web applications. Considering the fact that CMS are intended to be plug and play solutions and their main aim is to allow even non-developers to deploy websites, we argue that the default hashing schemes are not modified when deployed in the Internet. Also, recent studies suggest that even developers do not use appropriate hash functions to protect passwords, since they may not have adequate security expertise. Therefore, the default settings of CMS and web applications frameworks play an important role in the security of password storage. This paper evaluates the default hashing schemes of popular CMS and web application frameworks. First, we formulate the cost time of password guessing attacks and next we investigate the default hashing schemes of popular CMS and web applications frameworks. We also apply our framework to perform a comparative analysis of the cost time between the various CMS and web application frameworks. Finally, considering that intensive hash functions consume computational resources, we analyze hashing schemes from a different perspective. That is, we investigate if it is feasible and under what conditions to perform slow rate denial of service attacks from concurrent login attempts. Through our study we have derived a set of critical observations.