System Z End-To-End Extended Distance Guide
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

IBM System Z Strengths and Values
Front cover IBM System z Strengths and Values Technical presentation of System z hardware and z/OS Enterprise-wide roles for the System z platform Cost of computing considerations Philippe Comte Andrea Corona James Guilianelli Douglas Lin Werner Meiner Michel Plouin Marita Prassolo Kristine Seigworth Eran Yona Linfeng Yu ibm.com/redbooks International Technical Support Organization IBM System z Strengths and Values January 2007 SG24-7333-00 Note: Before using this information and the product it supports, read the information in “Notices” on page ix. First Edition (January 2007) This edition applies to the IBM System z platform and IBM z/OS V1.8. © Copyright International Business Machines Corporation 2007. All rights reserved. Note to U.S. Government Users Restricted Rights -- Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents Notices . ix Trademarks . x Preface . xi The team that wrote this redbook. xi Become a published author . xiii Comments welcome. xiii Chapter 1. A business view . 1 1.1 Business drivers . 2 1.2 Impact on IT . 3 1.3 The System z platform . 7 1.3.1 Using System Z technology to reduce complexity . 7 1.3.2 Business integration and resiliency. 8 1.3.3 Managing the System z platform to meet business goals. 11 1.3.4 Security . 12 1.4 Summary . 13 Chapter 2. System z architecture and hardware platform . 15 2.1 History . 16 2.2 System z architecture . 17 2.2.1 Multiprogramming and multiprocessing . 18 2.2.2 The virtualization concept . 19 2.2.3 PR/SM and logical partitions . -

FICON Native Implementation and Reference Guide
Front cover FICON Native Implementation and Reference Guide Architecture, terminology, and topology concepts Planning, implemention, and migration guidance Realistic examples and scenarios Bill White JongHak Kim Manfred Lindenau Ken Trowell ibm.com/redbooks International Technical Support Organization FICON Native Implementation and Reference Guide October 2002 SG24-6266-01 Note: Before using this information and the product it supports, read the information in “Notices” on page vii. Second Edition (October 2002) This edition applies to FICON channel adaptors installed and running in FICON native (FC) mode in the IBM zSeries procressors (at hardware driver level 3G) and the IBM 9672 Generation 5 and Generation 6 processors (at hardware driver level 26). © Copyright International Business Machines Corporation 2001, 2002. All rights reserved. Note to U.S. Government Users Restricted Rights -- Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents Notices . vii Trademarks . viii Preface . ix The team that wrote this redbook. ix Become a published author . .x Comments welcome. .x Chapter 1. Overview . 1 1.1 How to use this redbook . 2 1.2 Introduction to FICON . 2 1.3 zSeries and S/390 9672 G5/G6 I/O connectivity. 3 1.4 zSeries and S/390 FICON channel benefits . 5 Chapter 2. FICON topology and terminology . 9 2.1 Basic Fibre Channel terminology . 10 2.2 FICON channel topology. 12 2.2.1 Point-to-point configuration . 14 2.2.2 Switched point-to-point configuration . 15 2.2.3 Cascaded FICON Directors configuration. 16 2.3 Access control. 18 2.4 Fibre Channel and FICON terminology. -

8. IBM Z and Hybrid Cloud
The Centers for Medicare and Medicaid Services The role of the IBM Z® in Hybrid Cloud Architecture Paul Giangarra – IBM Distinguished Engineer December 2020 © IBM Corporation 2020 The Centers for Medicare and Medicaid Services The Role of IBM Z in Hybrid Cloud Architecture White Paper, December 2020 1. Foreword ............................................................................................................................................... 3 2. Executive Summary .............................................................................................................................. 4 3. Introduction ........................................................................................................................................... 7 4. IBM Z and NIST’s Five Essential Elements of Cloud Computing ..................................................... 10 5. IBM Z as a Cloud Computing Platform: Core Elements .................................................................... 12 5.1. The IBM Z for Cloud starts with Hardware .............................................................................. 13 5.2. Cross IBM Z Foundation Enables Enterprise Cloud Computing .............................................. 14 5.3. Capacity Provisioning and Capacity on Demand for Usage Metering and Chargeback (Infrastructure-as-a-Service) ................................................................................................................... 17 5.4. Multi-Tenancy and Security (Infrastructure-as-a-Service) ....................................................... -

Cisco MDS 9250I Multiservice Fabric Switch for IBM an Optimized Solution for Departmental and Branch-Office Sans As Well As Large-Scale Sans
IBM Systems Data Sheet Cisco MDS 9250i Multiservice Fabric Switch for IBM An optimized solution for departmental and branch-office SANs as well as large-scale SANs Cisco MDS 9250i Multiservice Fabric Switch for IBM® System Highlights Storage® is an optimized platform for deploying high-performance SAN extension solutions, distributed intelligent fabric services and ●● ●●Provide 16 Gbps connectivity in a cost-effective multiprotocol connectivity for both open systems and high-densit y Fibre Channel switch mainframe environments. With a compact form factor and advanced ●● ●●Enable storage area network (SAN) con- capabilities normally available only on director-class switches, solidation with integrated multiprotocol MDS 9250i is an ideal solution for departmental and remote branch- support office SANs as well as large-scale SANs in conjunction with the ●● ●●Deliver high-p erformance Fibre Channel Cisco MDS 9710 Multilayer Director. over IP (FCIP) and fast disaster recovery ●● ●●Support hardware-bas ed virtual fabric MDS 9250i offers up to 40 16 Gbps Fibre Channel ports, two isolation with virtual SANs (VSANs) and 10 Gigabit Ethernet IP storage services ports and eight 10 Gigabit Fibre Channel routing with Inter-V SAN routing (IVR) Ethernet Fibre Channel over Ethernet (FCoE) ports in a fixed, two- rack-unit (2RU) form factor. MDS 9250i connects to existing native Fibre ●● ●●Enable cost- effective, high- performing Channel networks, protecting current investments in storage networks. Fibre Channel and FCIP connectivity for open systems and mainframe environments Main features and benefits ●● ●●Cisco Data Mobility Manager (DMM) as a MDS 9250i provides unique multiservice and multiprotocol functions in distributed fabric service a compact 2RU form factor. -

IBM System Z9 Enterprise Class
The server built to help optimize your resources throughout the enterprise IBM System z9 Enterprise Class A “classic” might just be the best Today’s market finds that business needs are changing, and having a com petitive advantage isn’t always about having more or being bigger, but more about being smarter and responding faster to change and to your clients. Often, being reactive to change has led to infrastructures with mixed technolo gies, spread across an enterprise, that are complex and difficult to control and costly to manage. Integration of appli cations and data is limited and difficult. Using internal information to make insightful decisions for the company Highlights can be difficult because knowing you are using the “best” data—that which is ■ Strengthening the role of the ■ Continued improvement in most current and complete—may not mainframe as the data hub of IBM FICON® performance and be possible. the enterprise throughput In many situations, investments have ■ New versatile capacity settings ■ On demand innovative tech been made in disparate technologies designed to optimize capacity nologies to help meet ever- that may fall short of meeting their and cost changing business demands goals. Merging information from one branch to another may not be possible ■ IBM System z9™ Integrated and so company direction is set with Information Processor (IBM zIIP) is designed to improve resource optimization and lower the cost of eligible work only a portion of the data at hand, and help achieve advanced I/O function and But data management can be a big in a global economy that can really hurt. -

Troubleshooting FICON
Send documentation comments to [email protected] CHAPTER 16 Troubleshooting FICON Fibre Connection (FICON) interface capabilities enhance the Cisco MDS 9000 Family by supporting both open systems and mainframe storage network environments. Inclusion of Control Unit Port (CUP) support further enhances the MDS offering by allowing in-band management of the switch from FICON processors. This chapter includes the following sections: • FICON Overview, page 16-1 • FICON Configuration Requirements, page 16-6 • Initial Troubleshooting Checklist, page 16-7 • FICON Issues, page 16-9 FICON Overview The Cisco MDS 9000 Family supports the Fibre Channel, FICON, iSCSI, and FCIP capabilities within a single, high-availability platform. Fibre Channel and FICON are different FC4 protocols and their traffic are independent of each other. If required, devices using these protocols can be isolated using VSANs. The Cisco SAN-OS FICON feature supports high-availability, scalability, and SAN extension technologies including VSANs, IVR, FCIP, and PortChannels. Tip When you create a mixed environment, place all FICON devices in one VSAN (other than the default VSAN) and segregate the FCP switch ports in a separate VSAN (other than the default VSAN). This isolation ensures proper communication for all connected devices. You can implement FICON on the following switches: • Any switch in the Cisco MDS 9500 Series. • Any switch in the Cisco MDS 9200 Series (including the Cisco MDS 9222i Multiservice Modular Switch). • Cisco MDS 9134 Multilayer Fabric Switch. • MDS 9000 Family 18/4-Port Multiservice Module. Cisco MDS 9000 Family Troubleshooting Guide, Release 3.x OL-9285-05 16-1 Chapter 16 Troubleshooting FICON FICON Overview Send documentation comments to [email protected] Note The FICON feature is not supported on Cisco MDS 9120, 9124 or 9140 switches, the 32-port Fibre Channel switching module, Cisco Fabric Switch for HP c-Class BladeSystem or Cisco Fabric Switch for IBM BladeCenter. -

IBM Z Server Time Protocol Guide
Front cover Draft Document for Review August 3, 2020 1:37 pm SG24-8480-00 IBM Z Server Time Protocol Guide Octavian Lascu Franco Pinto Gatto Gobehi Hans-Peter Eckam Jeremy Koch Martin Söllig Sebastian Zimmermann Steve Guendert Redbooks Draft Document for Review August 3, 2020 7:26 pm 8480edno.fm IBM Redbooks IBM Z Server Time Protocol Guide August 2020 SG24-8480-00 8480edno.fm Draft Document for Review August 3, 2020 7:26 pm Note: Before using this information and the product it supports, read the information in “Notices” on page vii. First Edition (August 2020) This edition applies to IBM Server Time Protocol for IBM Z and covers IBM z15, IBM z14, and IBM z13 server generations. This document was created or updated on August 3, 2020. © Copyright International Business Machines Corporation 2020. All rights reserved. Note to U.S. Government Users Restricted Rights -- Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Draft Document for Review August 3, 2020 8:32 pm 8480TOC.fm Contents Notices . vii Trademarks . viii Preface . ix Authors. ix Comments welcome. .x Stay connected to IBM Redbooks . xi Chapter 1. Introduction to Server Time Protocol . 1 1.1 Introduction to time synchronization . 2 1.1.1 Insertion of leap seconds . 2 1.1.2 Time-of-Day (TOD) Clock . 3 1.1.3 Industry requirements . 4 1.1.4 Time synchronization in a Parallel Sysplex. 6 1.2 Overview of Server Time Protocol (STP) . 7 1.3 STP concepts and terminology . 9 1.3.1 STP facility . 9 1.3.2 TOD clock synchronization . -

Availability Digest
the Availability Digest Parallel Sysplex – Fault Tolerance from IBM April 2008 IBM’s Parallel Sysplex, HP’s NonStop server, and Stratus’ ftServer are today the primary industry fault-tolerant offerings that can tolerate any single failure, thus leading to very high levels of availability. The Stratus line of fault-tolerant computers is aimed at seamlessly protecting industry- standard servers running operating systems such as Windows, Unix, and Linux. As a result, ftServer does not compete with the other two systems, Parallel Sysplex and NonStop servers, which do compete instead in the large enterprise marketplace. In this article, we will explore IBM’s Parallel Sysplex and its features that address high availability. IBM’s Parallel Sysplex IBM’s Parallel Sysplex systems are multiprocessor clusters that can support from two to thirty-two mainframe nodes (typically S/390 or zSeries systems).1 A Parallel Sysplex system is nearly linearly scalable up to its 32-processor limit. A node may be a separate system or a logical partition (LPAR) within a system. The nodes do not have to be identical. They can be a mix of any servers that support the Parallel Sysplex environment. The nodes in a Parallel Sysplex system interact as an active/active architecture. The system allows direct, concurrent read/write access to shared data from all processing nodes without sacrificing data integrity. Furthermore, work requests associated with a single transaction or database query can be dynamically distributed for parallel execution based on available processor capacity of the nodes in the Parallel Sysplex cluster. Parallel Sysplex Architecture All nodes in a Parallel Sysplex cluster connect to a shared disk subsystem. -

IBM Z Connectivity Handbook
Front cover IBM Z Connectivity Handbook Octavian Lascu John Troy Anna Shugol Frank Packheiser Kazuhiro Nakajima Paul Schouten Hervey Kamga Jannie Houlbjerg Bo XU Redbooks IBM Redbooks IBM Z Connectivity Handbook August 2020 SG24-5444-20 Note: Before using this information and the product it supports, read the information in “Notices” on page vii. Twentyfirst Edition (August 2020) This edition applies to connectivity options available on the IBM z15 (M/T 8561), IBM z15 (M/T 8562), IBM z14 (M/T 3906), IBM z14 Model ZR1 (M/T 3907), IBM z13, and IBM z13s. © Copyright International Business Machines Corporation 2020. All rights reserved. Note to U.S. Government Users Restricted Rights -- Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents Notices . vii Trademarks . viii Preface . ix Authors. ix Now you can become a published author, too! . xi Comments welcome. xi Stay connected to IBM Redbooks . xi Chapter 1. Introduction. 1 1.1 I/O channel overview. 2 1.1.1 I/O hardware infrastructure . 2 1.1.2 I/O connectivity features . 3 1.2 FICON Express . 4 1.3 zHyperLink Express . 5 1.4 Open Systems Adapter-Express. 6 1.5 HiperSockets. 7 1.6 Parallel Sysplex and coupling links . 8 1.7 Shared Memory Communications. 9 1.8 I/O feature support . 10 1.9 Special-purpose feature support . 12 1.9.1 Crypto Express features . 12 1.9.2 Flash Express feature . 12 1.9.3 zEDC Express feature . 13 Chapter 2. Channel subsystem overview . 15 2.1 CSS description . 16 2.1.1 CSS elements . -

IBM System Z9 109 Technical Introduction
Front cover IBM System z9 109 Technical Introduction Hardware description Software support Key functions Bill Ogden Jose Fadel Bill White ibm.com/redbooks International Technical Support Organization IBM System z9 109 Technical Introduction July 2005 SG24-6669-00 Note: Before using this information and the product it supports, read the information in “Notices” on page vii. First Edition (July 2005) This edition applies to the initial announcement of the IBM System z9 109. © Copyright International Business Machines Corporation 2005. All rights reserved. Note to U.S. Government Users Restricted Rights -- Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents Notices . vii Trademarks . viii Preface . ix The authors . ix Become a published author . ix Comments welcome. .x Chapter 1. Introduction. 1 1.1 Evolution . 2 1.2 z9-109 server highlights . 3 1.3 zSeries comparisons. 4 1.4 z9-109 server models and processor units . 6 1.5 Upgrades. 6 1.6 Considerations . 7 Chapter 2. Hardware overview . 9 2.1 System frames . 10 2.2 Books . 10 2.3 MCM . 12 2.4 Processor units . 13 2.4.1 PU characterizations. 14 2.5 Memory . 14 2.6 I/O interfaces. 15 2.7 I/O cages and features . 16 2.7.1 Physical I/O connections. 18 2.7.2 Coupling connections . 20 2.7.3 Cryptographic functions . 20 2.8 Time functions. 21 2.8.1 Sysplex Timer . 21 2.8.2 Server Time Protocol (STP) . 22 2.9 Hardware Storage Area . 22 2.10 System control . 22 2.11 HMC and SE . -
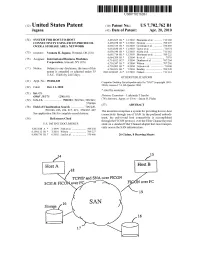
TCP/IP and SNA Over FICON SCSI & Ficonover FC FICON Over FC 19
USOO7702762B1 (12) United States Patent (10) Patent No.: US 7,702,762 B1 Jagana (45) Date of Patent: Apr. 20, 2010 (54) SYSTEM FOR HOST TO-HOST 6,493.825 B1* 12/2002 Blumenau et al. ........... T13,168 CONNECTIVITY USING FICON PROTOCOL 6,499,058 B1* 12/2002 Hozumi ............... ... TO9,225 OVER A STORAGE AREANETWORK 6,636,529 B1 * 10/2003 Goodman et al. ... 370/469 6,654,830 B1 * 1 1/2003 Taylor et al. .................. 71 Of 74 (75)75 Inventor: Venkata R. Jagana, Portland, OR (US) 6,665,7146,658,540 B1* 12/2003 SicolaBlumenau et al. et al....... ........... ... 709/222711,162 (73) Assignee: states insists 6,714,9526,684,209 B2*B1 3/20041/2004 Ito(Shane et al. ........................ at O'707:01 707/9 s s 6,718,347 B1 * 4/2004 Wilson .......... ... TO7,201 c - 6,728,803 B1 * 4/2004 Nelson et al. ................. T10/60 (*) Notice: Subject to any disclaimer, the term of this 6,769,021 B1* 7/2004 Bradley ......... ... TO9.220 patent is extended or adjusted under 35 2003/0236945 A1 12/2003 Nahum ....................... 711 114 U.S.C. 154(b) by 2415 days. OTHER PUBLICATIONS (21) Appl. No.: 09/686,049 Computer Desktop Encyclopedia entry for "SAN” (copyright 1981 (22) Filed1C Oct.cl. 11,1 2000 2004), version 174, 4th Quarter 2004. * cited by examiner (51) Int. Cl. G06F 5/73 (2006.01) E. Early line Pich (52) U.S. Cl. ....................... 709:23.700,246.700,249 (74) Attorney, Agent, or Firm Jason O. Piche 37Of 466 57 ABSTRACT (58) Field of Classification Search ................ -

Brocade Fabric OS FICON Administrator's Guide
53-1003517-04 09 February 2016 Brocade Fabric OS FICON Administrator's Guide Supporting Fabric OS v7.4.0, Fabric OS 7.4.1 © 2016, Brocade Communications Systems, Inc. All Rights Reserved. Brocade, Brocade Assurance, the B-wing symbol, ClearLink, DCX, Fabric OS, HyperEdge, ICX, MLX, MyBrocade, OpenScript, VCS, VDX, Vplane, and Vyatta are registered trademarks, and Fabric Vision is a trademark of Brocade Communications Systems, Inc., in the United States and/or in other countries. Other brands, products, or service names mentioned may be trademarks of others. Notice: This document is for informational purposes only and does not set forth any warranty, expressed or implied, concerning any equipment, equipment feature, or service offered or to be offered by Brocade. Brocade reserves the right to make changes to this document at any time, without notice, and assumes no responsibility for its use. This informational document describes features that may not be currently available. Contact a Brocade sales office for information on feature and product availability. Export of technical data contained in this document may require an export license from the United States government. The authors and Brocade Communications Systems, Inc. assume no liability or responsibility to any person or entity with respect to the accuracy of this document or any loss, cost, liability, or damages arising from the information contained herein or the computer programs that accompany it. The product described by this document may contain open source software covered by the GNU General Public License or other open source license agreements. To find out which open source software is included in Brocade products, view the licensing terms applicable to the open source software, and obtain a copy of the programming source code, please visit http://www.brocade.com/support/oscd.