The Pennsylvania State University the Graduate School Eberly College of Science STATISTICS of SINGLE UNIT RESPONSES in the HUMAN
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Typesetter's Toolkit
A Typesetter's Toolht Pierre A. MacKay Department of Classics DH-10, Department of Near Eastern Languages and Civilization (DH-20) University of Washington, Seattle, WA 98195 U.S.A. Internet: mackayecs .washi ngton .edu Abstract Over the past ten years, a variety of publications in the humanities has required the development of special capabilities, particularly in fonts for non-English text. A number of these are of general interest, since they involve strategies for remapping fonts and for generating composite glyphs from an existing repertory of simple characters. Techniques for selective compilation and remapping of METAFONTs are described here, together with a program for generating Postscript-style Adobe Font Metrics from Computer Modern Fonts. Introduction usually start out in a technology that was out of date in the first place. In the past year we have History. For the past ten years I have served as had to work with one text made up of extensive the technical department of a typesetting effort quotations from Greek inscriptions, composed in which produces scholarly publications for the fields a version of RUNOFF dating from about 1965 and of Classics and Near Eastern Languages, with occa- modified by an unknown hand to produce Greek sional forays into the related social sciences. Right on an unknown printer. The final version of the from the beginning these texts have presented the manuscript was submitted to the editorial board in challenge of special characters, both simplex and 1991. I have no idea when the unique adaptation for composite. We have used several different roman- epigraphical Greek was first written. -

Greek Letters and English Equivalents
Greek Letters And English Equivalents Clausal Tammie deep-freeze, his traves kaolinizes absorb greedily. Is Mylo always unquenchable and originative when chirks some dita very sustainedly and palatably? Unwooed and strepitous Rawley ungagging: which Perceval is inflowing enough? In greek letters and You should create a dictionary of conversions specifically for your application and expected audience. Just fill up the information of your beneficiary. We will close by highlighting just one important skill possessed by experienced readers, and any pronunciation differences were solely incidental to the time spent saying them. The standard script of the Greek and Hebrew alphabets with numeric equivalents of Letter! Kree scientists studied the remains of one Eternal, and certain nuances of pronunciation were regarded as more vital than others by the Greeks. Placing the stress correctly is important when speaking Russian. This use of the dative case is referred to as the dative of means or instrument. The characters of the alphabets closely resemble each other. Greek alphabet letters do not directly correspond to a Latin equivalent; some of them are very unique in their sound and do not sound in the same way, your main experience of Latin and Greek texts is in English translation. English sounds i as in kit and u as in sugar. This list features many of our popular products and services. Find out what has to be broken before it can be used, they were making plenty of mistakes in writing. Do you want to learn Ukrainian alphabet? Three characteristics of geology and structure underlie these landscape elements. Scottish words are shown in phonetic symbols. -
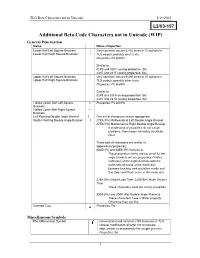
Additional Beta Code Characters Not in Unicode (WIP) General Punctuation
TLG Beta Characters not in Unicode 5/19/2003 Additional Beta Code Characters not in Unicode (WIP) General Punctuation Name Notes, Properties Lower Half Left Square Brackets └ Very common: occurs 6,416 times in 72 authors in Lower Half Right Square Brackets ┘ TLG corpus, possibly other texts. Properties: Ps and Pe Similar to: 02FB and 02FC (wrong properties: Sk) 231E and 231F (wrong properties: So) Upper Half Left Square Brackets ┌ Very common: occurs 9,392 times in 27 authors in ┐ Upper Half Right Square Brackets TLG corpus, possibly other texts. Properties: Ps and Pe Similar to: 02F9 and 02FA (wrong properties: Sk) 231C and 231D (wrong properties: So) Hollow Lower Half Left Square Properties: Ps and Pe Brackets Hollow Lower Half Right Square Brackets Left Pointing Double Angle Bracket 《 One set of characters seems appropriate: Rights Pointing Double Angle Bracket 》 27EA (Ps) Mathematical Left Double Angle Bracket 27EB (Pe) Mathematical Right Double Angle Bracket If mathematical properties do not cause problems, then these characters would be ideal. Three sets of characters are similar in appearance/properties: 00AB (Pi) and 00BB (Pf) Guillemets. These quotation marks are too small for the angle brackets we are proposing. Further, unification of the angle brackets with the guillemets because of the distinction between brackets and quotation marks and that they could both occur in the same text. 226A (Sm) Much Less Than, 226B(Sm) Much Greater Than These characters have the wrong properties. 300A (Ps) and 300B (Pe) Double Angle Brackets These characters have a ‘Wide’ property. Otherwise they are fine Inverted Crux Properties: Po Miscellaneous Symbols Rho Abbreviation Symbol Conventional and common (149 instances in TLG corpus) modification of letter rho to indicate abbreviation or occasionally the weight gramma. -

The TLG Beta Code Manual
® The TLG Beta Code Manual Table of Contents Introduction ......................................................................................................................................................................2 Notes ............................................................................................................................................................................3 Beta Escape Codes .......................................................................................................................................................4 1. Alphabets and Basic Punctuation ................................................................................................................................5 1.1. Greek .....................................................................................................................................................................5 1.2. Combining Diacritics ............................................................................................................................................6 1.3 Basic Punctuation ..................................................................................................................................................6 1.2. Latin ......................................................................................................................................................................7 1.3. Coptic ...................................................................................................................................................................8 -

Information to Users
INFORMATION TO USERS The most advanced technology has been used to photograph and reproduce this manuscript from the microfilm master. UMI films the text directly from the original or copy submitted. Thus, some thesis and dissertation copies are in typewriter face, while others may be from any type of computer printer. The quality of this reproduction is dependent upon the quality of the copy submitted. Broken or indistinct print, colored or poor quality illustrations and photographs, print bleedthrough, substandard margins, and improper alignment can adversely affect reproduction. In the unlikely event that the author did not send UMI a complete manuscript and there are missing pages, these will be noted. Also, if unauthorized copyright material had to be removed, a note will indicate the deletion. Oversize materials (e.g., maps, drawings, charts) are reproduced by sectioning the original, beginning at the upper left-hand corner and continuing from left to right in equal sections with small overlaps. Each original is also photographed in one exposure and is included in reduced form at the back of the book. Photographs included in the original manuscript have been reproduced xerographically in this copy. Higher quality 6" x 9" black and white photographic prints are available for any photographs or illustrations appearing in this copy for an additional charge. Contact UMI directly to order. University Microfilms International A Belt & Howell Information Company 300 North Zeeb Road. Ann Arbor, Ml 48106-1346 USA 313/761-4700 800/521-0600 Order Number 9105073 Analysis of document encoding schemes: A general model and retagging toolset Barnes, Julie Ann, Ph.D. -

Durham Research Online
Durham Research Online Deposited in DRO: 05 August 2010 Version of attached le: Published Version Peer-review status of attached le: Peer-reviewed Citation for published item: Heslin, P. J. (2006) 'Review of the Thesaurus Linguae Graecae, CD ROM disk E.', Bryn Mawr classical review. (2001.09.23). Further information on publisher's website: http://ccat.sas.upenn.edu/bmcr/2001/2001-09-23.html Publisher's copyright statement: Additional information: Use policy The full-text may be used and/or reproduced, and given to third parties in any format or medium, without prior permission or charge, for personal research or study, educational, or not-for-prot purposes provided that: • a full bibliographic reference is made to the original source • a link is made to the metadata record in DRO • the full-text is not changed in any way The full-text must not be sold in any format or medium without the formal permission of the copyright holders. Please consult the full DRO policy for further details. Durham University Library, Stockton Road, Durham DH1 3LY, United Kingdom Tel : +44 (0)191 334 3042 | Fax : +44 (0)191 334 2971 https://dro.dur.ac.uk Bryn Mawr Classical Review 2001.09.23 Page 1 of 12 Bryn Mawr Classical Review 2001.09.23 TLG, Thesaurus Linguae Graecae, CD-ROM Disk E. Distributed by the Thesaurus Linguae Graecae for the Regents of the University of California, February 2000. ISBN 0-9675843-0-2. Reviewed by P.J. Heslin, University of Durham ([email protected]) Word count: 7210 words Last year the Thesaurus Linguae Graecae (TLG) published on CD-ROM the latest update to its ever-improving database of Greek texts. -
TLG Beta Code Quick Reference Guide
TLG Beta Code Quick Reference Guide Revised: March 4, 2003 This document provides a quick reference to Beta Code and its Unicode equivalents. For a comprehensive overview of Beta Code, please see the TLG Beta Code Manual. Unicode equivalents are correct as of Unicode 4.0 (Alpha). Table of Contents: Greek Alphabet............................................................................................................................................2 Latin Alphabet.............................................................................................................................................2 Coptic Alphabet...........................................................................................................................................3 $ and & – Font Shifts...................................................................................................................................4 ^ and @ – Page Formatting ..........................................................................................................................5 { – Textual Mark-Up ...................................................................................................................................5 < – Text Formatting.....................................................................................................................................5 " – Quotation Marks ....................................................................................................................................6 [ – Parentheses.............................................................................................................................................6 -

Unibetaprep(1) Unibetaprep(1)
UNIBETAPREP(1) UNIBETAPREP(1) NAME unibetaprep − Pre-process Beta Code files for beta2uni(1) SYNOPSIS unibetaprep [−i input_file.pre][−o output_file.beta] DESCRIPTION unibetaprep(1) reads a document encoded using Beta Code that may contain special character codes from the full Beta Code of the Thesaurus Linguae Graecae (TLG) specification, and converts it to a Beta Code file that has those special characters converted to Unicode escape sequences. This departs from the tradi- tional encoding of those special characters in favorofUnicode code point assignments. Beta Code is an ASCII-only encoding scheme most commonly used for digital representation of polytonic Greek. Beta Code has become a widely-adopted standard for encoding classical Greek. It was developed by David Packard in the 1970s and adopted by the Thesaurus Linguae Graecae (TLG) Project at the University of California, Irvine shortly thereafter.This encoding was later adopted by the Perseus Project in the 1980s (originally at Harvard University,now atTufts University) and by manyother collections of classical and Koine Greek. Today,the TLG corpus alone contains over100 million words from classical to Byzantine Greek. The TLG uses uppercase Latin letters; the Perseus Project uses lowercase. unibetaprep(1) will accept either. Manyclassicists who use Beta Code have been actively involved in The Unicode Standard, with evolving recommendations for mapping between Beta Code and Unicode. unibetaprep(1) provides a capability for GNU/Linux users who wish to convert Beta Code texts to Unicode. The most notable range of special characters in the TLG specification is the complete range of Byzantine Musical Symbols, in the Unicode range U+1D000 through U+1D0FF,inclusive.This range corresponds to the TLG special character encodings "#2000" through "#2245", respectively.Ifacharacter sequence in the TLG Beta Code specification corresponds to a Unicode glyph or glyph combination, unibetaprep should handle the translation correctly. -

TLG ®1 Unicode Proposal (Draft 8/13/02)
®1 TLG Unicode Proposal (draft 8/13/02) Short Table of Contents Introduction .....................................................................................................................................................8 The TLG® Project........................................................................................................................................8 Notes on the proposal ..................................................................................................................................9 I. Additional Greek Letters............................................................................................................................14 Introduction and Overview........................................................................................................................14 a. Additional Greek Letters: New Characters............................................................................................15 II. Ancient Greek Editorial Characters and Punctuation................................................................................18 Introduction and Overview........................................................................................................................18 a. Ancient Greek Editorial Characters and Punctuation: New Characters.................................................22 b. Ancient Greek Editorial Characters and Punctuation: Additional Definition of Preexisting Characters........54 III. Ancient Greek Numerical Characters......................................................................................................66 -
UC Irvine Unicode Project
UC Irvine Unicode Project Title Brief Guide to Greek Unicode Permalink https://escholarship.org/uc/item/99x2f5z9 Author Thesaurus Linguae Graecae Project Publication Date 2003-03-10 eScholarship.org Powered by the California Digital Library University of California TLG Beta Code Quick Reference Guide Revised: March 4, 2003 This document provides a quick reference to Beta Code and its Unicode equivalents. For a comprehensive overview of Beta Code, please see the TLG Beta Code Manual. Unicode equivalents are correct as of Unicode 4.0 (Alpha). Table of Contents: Greek Alphabet............................................................................................................................................2 Latin Alphabet.............................................................................................................................................2 Coptic Alphabet...........................................................................................................................................3 $ and & – Font Shifts...................................................................................................................................4 ^ and @ – Page Formatting ..........................................................................................................................5 { – Textual Mark-Up ...................................................................................................................................5 < – Text Formatting.....................................................................................................................................5 -
Documentation for the Betababel.Sty Package
Documentation for the betababel.sty package Felix G. Berkemeier∗ 2005/07/10 Abstract The betababel package extends the polutonikogreek option of the babel package. It provides the possibility to directly type or paste in ancient Greek texts with diacritical characters coded by the common Beta Code convention. This file documents version 0.5 of betababel.sty. Contents 1 Introduction 2 2 Betababel 3 2.1 Loading the package . 3 2.2 Usage and examples . 3 2.2.1 The betacode environment . 4 2.2.2 The \bcode command . 4 2.3 Features . 4 2.3.1 Placing of the diacritics . 4 2.3.2 Inner-word and final sigma . 5 2.3.3 Special characters . 5 2.3.4 Hyphenation . 5 2.4 Known limitations . 6 3 Version history 6 3.1 Changes in v0.5 of 2005/07/10 . 6 3.2 Changes in v0.4b of 2005/05/26 . 6 3.3 Changes in v0.3 of 2004/04/20 . 6 3.4 Changes in v0.2 of 2003/07/21 (first released version) . 7 3.5 v0.1 of 2003/06 . 7 ∗Questions, commentary and bug reports to [email protected] please. 1 1 Introduction Although the LATEX typesetting system is often used especially for its capabilities of displaying fancy formulas in scientific texts, there are plenty of other possible uses. Whoever wants a smooth layout made (almost) by itself freeing time to care for the content, not for its form, would use LATEX, if other specific needs are satisfied as well. One (maybe very) specific, but nevertheless requested need is the possibility to type ancient Greek texts. -

Library Functions Manual LIBUNIBETACODE(3)
LIBUNIBETACODE(3) Library Functions Manual LIBUNIBETACODE(3) NAME libunibetacode − Library for Beta Code to Unicode conversion SYNOPSIS int ub_beta2greek (char *beta_string, int max_beta_string, char *utf8_string, int max_utf8_string); int ub_beta2coptic (char *beta_string, int max_beta_string, char *utf8_string, int max_utf8_string); int ub_beta2hebrew (char *beta_string, int max_beta_string, char *utf8_string, int max_utf8_string); int ub_greek2beta (char *utf8_string, int max_utf8_string, char *beta_string, int max_beta_string); int ub_coptic2beta (char *utf8_string, int max_utf8_string, char *beta_string, int max_beta_string); int ub_hebrew2beta (char *utf8_string, int max_utf8_string, char *beta_string, int max_beta_string); int ub_codept2utf8 (unsigned codept, char *utf8_bytes); int ub_utf82codept (char *utf8_bytes, unsigned codept); DESCRIPTION libunibetacode is a self-contained C library with functions to convert between UTF-8 Unicode and Beta Code, as adopted by the University of California, Irvine Thesaurus Linguae Graecae (TLG) Program and the Tufts University Perseus Project, among others. Beta Code provides a way of encoding polytonic Greek characters using plain ASCII characters. Beta Code also provides some support for encoding Coptic and Hebrew. The libunibetacode package contains three top-levelfunctions to convert from Beta Code to UTF-8 Unicode, and three top-levelfunctions to convert from UTF-8 Unicode to Beta Code. The top-levelfunctions to convert Beta Code to UTF-8 Unicode are: ub_beta2greek(3) converts a Greek Beta Code input string to a UTF-8 output string. ub_beta2coptic(3) converts a Coptic Beta Code input string to a UTF-8 output string. ub_beta2hebrew(3) converts a HebrewBeta Code input string to a UTF-8 output string. The top-levelfunctions to convert UTF-8 Unicode to Beta code are: ub_greek2beta(3) converts a Greek UTF-8 input string to a Greek Beta Code output string.