Visual Similarity Exacerbates the Moses Illusion for Semantically
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Festive Funnies
December 14 - 20, 2019 Festive Funnies www.southernheatingandac.biz/ Homer from “The Simpsons” $10.00 OFF any service call one per customer. 910-738-70002105-A EAST ELIZABETHTOWN RD CARDINAL HEART AND VASCULAR PLLC Suriya Jayawardena MD. FACC. FSCAI Board Certified Physician Heart Disease, Leg Pain due to poor circulation, Varicose Veins, Obesity, Erectile Dysfunction and Allergy clinic. All insurances accepted. Same week appointments. Friendly Staff. Testing done in the same office. Plan for Healthy Life Style 4380 Fayetteville Rd. • Lumberton, NC 28358 Tele: 919-718-0414 • Fax: 919-718-0280 • Hours of Operation: 8am-5pm Monday-Friday Page 2 — Saturday, December 14, 2019 — The Robesonian ‘The Simpsons,’ ‘Bless the Harts,’ ‘Bob’s Burgers’ and ‘Family Guy’ air Christmas Specials By Breanna Henry “The Simpsons” is known for must be tracked down if there is overall, and having to follow a se- job at a post office. However, Lin- recognize the “Game of Thrones” TV Media its celebrity guest voices (many to be any hope of saving Christ- ries with 672 episodes (and a da discovers an undelivered pack- reference in this episode title, a celebs lend their own voices to a mas. In completely unrelated movie) under its belt might seem age and ends up going a little off- spin on the Stark family slogan uddle up for a festive, fun- storyline that’s making fun of news, this year’s Springfield Mall difficult if it weren’t for how book to ensure it reaches its in- “Winter is Coming.” Cfilled night on Fox, when the them). A special episode is the Santa is none other than famed much heart “Bless the Harts” has tended destination. -

Soiiy Discos to Close Warehouse Nationality, Argues Bolz
`N SYNC'S INDIRECT PATH TO THE TOP (Continued from page 6) (responsible for producing Spears) less where a record was produced, many." million albums sold worldwide are in haven't. We've just had to spend a lot with Kristian Lundin under the within the industry BMG Ariola BMG Ariola's head of internation- the U.S., according to BMG. The of time in the U.S." supervision of BMG A &R exec Munich is the first to admit that in al, Susie Armstrong, says that the group has been busy satisfying U.S. The band's agenda for this year Andreas von Oertzen in Munich. The 1997, a German- produced American climate changed over the time that demand, which has resulted in the will concentrate on the U.S. The label and creative team was a simi- boy band was not necessarily on top 'N Sync was being developed. BMG U.K. label Northwestside hav- group will play arenas there from lar constellation to what led to the of every affiliate's wish list, and it "Five years ago, I would not have ing to wait until May to release the March to May, then visit the U.K. to Backstreet Boys' European success. encountered resistance among col- had a fighting chance with this act" album. launch the album there. June sees The album was originally released leagues. However, the attitudes of key "We've had difficulty bringing the act recording, then a third set of in May 1997: That version has sold For Thomas M. Stein, BMG's executives in the U.S. -

Central Florida Future, Vol. 34 No. 14, November 21, 2001
University of Central Florida STARS Central Florida Future University Archives 11-21-2001 Central Florida Future, Vol. 34 No. 14, November 21, 2001 Part of the Mass Communication Commons, Organizational Communication Commons, Publishing Commons, and the Social Influence and oliticalP Communication Commons Find similar works at: https://stars.library.ucf.edu/centralfloridafuture University of Central Florida Libraries http://library.ucf.edu This Newspaper is brought to you for free and open access by the University Archives at STARS. It has been accepted for inclusion in Central Florida Future by an authorized administrator of STARS. For more information, please contact [email protected]. Recommended Citation "Central Florida Future, Vol. 34 No. 14, November 21, 2001" (2001). Central Florida Future. 1606. https://stars.library.ucf.edu/centralfloridafuture/1606 HAPPY THANKS61VIN6! from The Central THE central florida Florida Future • November 21, 2001 •THE STUDENT NEWSPAPER SERVING UCF SINCE 1968 • www.UCFjuture.com International 0 Hunger Banquet educates Week offered • forums, Study students about poverty Abroad Fair • KRISTA ZILIZI STAFF WRITER PADRA SANCHEZ S'rAfp WRITER • Students got the chance to experience the different social On Nov. 13, UCF held a classes that populate the world series of open forums for students, • at Volunteer UCF's annual faculty and staff about pertinent Hunger Banquet last week. international issues. Held in the "This is a small slice of Student Union's Key West Room, JOE KALEITA I CFF each forum followed a town hall life as it plays out ~ach day in lower class students, who were the world," said Nausheen format, with a panel of guest forced to sit on the floor, had to eat speakers and open microphones Farooqui, Hunger and with "rats". -

WORST COOKS in AMERICA: CELEBRITY EDITION Contestant Bios
Press Contact: Lauren Sklar Phone: 646-336-3745; Email: [email protected] WORST COOKS IN AMERICA: CELEBRITY EDITION Contestant Bios MINDY COHN Mindy Cohn made her acting debut as the witty, precious Eastland Academy student Natalie Green in the hit comedy series The Facts of Life. She was discovered while attending Westlake School for Girls in Bel Air, California, when actress Charlotte Rae and producer Norman Lear came to the school to authenticate scripts for their new show. Ms. Rae was so taken with the vivacious eighth grader she convinced producers to create a role for her. Mindy remained on the show for all nine seasons, also traveling to Paris and Australia with her co-stars to produce two successful television movies based on the series. Concurrently, with her role in Facts, Mindy played “Rose Jenko” in Fox’s 21 Jump Street. Other notable television appearances included Diff’rent Strokes, Double Trouble, Charles in Charge, Dream On and Suddenly Susan. In 1983, Mindy appeared in her first professional stage performance in Table Settings, written and directed by James Lapine and filmed for HBO Television. The illustrious cast included Eileen Heckart, Stockard Channing, Robert Klein, Peter Riegart, and Dinah Manoff. She went on to make her feature film debut in The Boy Who Could Fly, which co-starred Colleen Dewhurst, Fred Gwynne and Fred Savage. Mindy took a hiatus from her career to attend university, where she earned a Bachelor’s degree in Cultural Anthropology and a Masters in Education. During this time, she studied improvisation and scene work with Gary Austin and Larry Moss. -

Authorship and Product Placement in Film Margaret M
Ryerson University Digital Commons @ Ryerson Theses and dissertations 1-1-2009 Will the real auteur please stand up!: authorship and product placement in film Margaret M. Mohr Ryerson University Follow this and additional works at: http://digitalcommons.ryerson.ca/dissertations Part of the Advertising and Promotion Management Commons Recommended Citation Mohr, Margaret M., "Will the real auteur please stand up!: authorship and product placement in film" (2009). Theses and dissertations. Paper 538. This Thesis is brought to you for free and open access by Digital Commons @ Ryerson. It has been accepted for inclusion in Theses and dissertations by an authorized administrator of Digital Commons @ Ryerson. For more information, please contact [email protected]. WILL THE REAL AUTEUR PLEASE STAND UP!: AUTHORSHIP and PRODUCT PLACEMENT in FILM By Margaret M. Mohr Bachelor of Arts University of Toronto 2005 A thesis Presented to Ryerson University and York University In partial fulfillment of the requirements for the degree of Master of Arts In the program of Communication and Culture Toronto, Ontario, Canada, 2009 © Margaret M. Mohr,2009 PROPERTY OF Author's Declaration I hereby declare that I am the sole author of this thesis. I authorize Ryerson University and York University to lend this thesis to other institutions or individuals for the sole purpose of scholarly research. I further authorize Ryerson University and York University to reproduce this thesis by photocopying or by other means, in total or in part, at the request of other institutions or individuals for the purpose of scholarly research. argaret M. Mohr u ABSTRACT Margaret M. Mohr "Will The Real Auteur Please Stand Up!: Authorship and Product Placement In Film" Master of Arts, Communication and Culture, Ryerson University, Toronto 2009 This thesis investigates issues of product placement in Hollywood cinema as seen through the lenses of theories of authorship and cultural economy. -

275. – Part One
275. – PART ONE 275. Clifford (1994) Okay, here’s the deal: I don’t know you, you don’t know me, but if you are anywhere near a television right now I need you to stop whatever it is that you’re doing and go watch “Clifford” on HBO Max. This is another film that has a 10% score on Rotten Tomatoes which just leads me to believe that all of the critics who were popular in the nineties didn’t have a single shred of humor in any of their non-existent funny bones. I loved this movie when I was seven, and I love it even more when I’m thirty-three. It’s genius. Martin Short (who at the time was forty-four) plays a ten-year-old hyperactive nightmare child from hell. I mean it, this kid might actually be the devil. He is straight up evil, conniving, manipulative and all-told probably causes no less than ten million dollars-worth of property damage. And, again, the plot is so simple – he just wants to go to Dinosaur World. There are so many comedy films with such complicated plots and motivations for their characters, but the simplistic genius of “Clifford” is just this – all this kid wants on the entire planet is to go to Dinosaur World. That’s it. The movie starts with him and his parents on an plane to Hawaii for a business trip, and Clifford knows that Dinosaur Land is in Los Angeles, therefore he causes so much of a ruckus that the plane has to make an emergency landing. -

Sharknado Social Media Analysis with SAP HANA and Predictive Analysis
Sharknado Social Media Analysis with SAP HANA and Predictive Analysis Mining social media data for customer feedback is perhaps one of the greatest untapped opportunities for customer analysis in many organizations today. Social media data is freely available and allows organizations to personally identify and interact directly with customers to resolve any potential dissatisfaction. In today’s blog post, I’ll discuss using SAP Data Services, SAP HANA, and SAP Predictive Analysis to collect, process, visualize, and analyze social media data related to the recent social media phenomenon Sharknado. Collecting Social Media Data with SAP Data Services While I’ll be focusing primarily on the analysis of social media data in this blog post, social media data can be collected from any source with an open API by using Python scripting within a User-Defined Transform. In this example, I’ve collected Twitter data using the basic outline provided by SAP in the Data Services Text Data Processing Blueprints available on the SAP Community Network, updated it for the REST version 1.1 Twitter API. This process consists of 2 dataflows, the first tracks search terms and constructs (Get_Search_Tasks transform) and executes (Search_Twitter transform) a Twitter search query to store the data pictured below. In addition to the raw text of the tweet, some metadata is available, including user name, time, and location information (if the user has made it publicly available). Once the raw tweet data has been collected, I can use either the Text Data Processing transform in SAP Data Services or the Voice of Customer text analysis process in SAP HANA. -

Holiday TV Guide 2020
HolidayTV Better watch out 20th Century Fox Thirty years after premiering in theaters, this movie about a boy who protects his home from burglars at Christmastime is still entertaining viewers young and old. Kevin McCallister (Macaulay Culkin, “My Girl,” 1991) learns to be careful what he wishes for after his mom and dad accidentally leave him behind as they fly to Paris for the holidays in “Home Alone,” airing Thursday, Nov. 26, on Freeform. Holiday TV| Home Alone 30th Anniversary 30 years of holiday high jinx ‘Home Alone’ celebrates big milestone By Kyla Brewer TV Media their extended family scramble to make it to the airport in time to catch their flight. In the ensuing chaos and confusion, parents Kate (Catherine he holidays offer movie fans a treasure O’Hara, “Schitt’s Creek”) and Peter (John Heard, trove of options, old and new. Some are “Cutter’s Way,” 1981) forget young Kevin, who Tfunny, some are heartwarming, some are had been sent to sleep in the attic after causing a inspirational and a precious few are all of those ruckus the night before. The boy awakens to find things combined. One such modern classic is cel- his home deserted and believes that his wish for ebrating a milestone this year, and viewers won’t his family to disappear has come true. want to miss it. At first, Kevin’s new parent-and-sibling-free Macaulay Culkin (“My Girl,” 1991) stars as Kevin existence seems ideal as he jumps on his parents’ McCallister, a boy who is left behind when his fam- bed, raids his big brother’s room, eats ice cream ily goes on vacation during the holidays, in “Home for supper and watches gangster movies. -

'Sharknado' Hits California Hard, Internet Even Harder
‘Sharknado’ Hits California Hard, Internet Even Harder Chris Nichols The Exchange July 12, 2013 If something could actually break the social Web because of extreme overexposure -- as the Harlem Shake taught us, it can't -- the "Sharknado" rage of the moment would be a candidate to do it. The Syfy original movie, which aired Thursday night, became a dominant force on the Internet during its airing and afterward, with Twitter and search traffic levels suggesting cancer had been cured or an intelligent alien species found. Image from Sharknado On Twitter itself, there was no escaping #sharknado. According to one report, the peak activity was about 5,000 tweets a minute right before 11 p.m. E.T., when "Sharknado" was concluding. Google Trends also showed quite an interest, with "Sharknado" collecting more than 500,000 searches July 11. Starring Ian Ziering, best known for his 1990s work on "Beverly Hills, 90210," and Tara Reid, of "American Pie" fame, "Sharknado" is the story of a terrible and powerful Pacific Ocean hurricane, one spawning tornadic winds that scooped up sharks by the hundreds and deposited them along the California coast, where naturally they feasted on the residents of greater Los Angeles. The still image from a Syfy clip here shows how serious the matter was. [Related: See the 'Sharknado' Storify experience] Many people were consumed. A Ferris wheel broke loose. Explosives were dropped into the storms to show them who's boss. Ziering used a chainsaw. He later told CBSNews: "When I read the scene where I'm actually chainsawing my way out of the belly of a shark, how could a guy turn that down when that's in the job description?" He couldn't. -

Holidaytv | National Lampoon’S Christmas Vacation a Griswold Anniversary Celebrate 30 Years of ‘National Lampoon’S Christmas Vacation’
Kreitzer Funeral Home OH-70157806 Funeral Directors David Fellers HeatingBOLYARD & Cooling, Inc. Matthew Fellers olidayTV Financing 204 N. Main St. Arcanum, Ohio 45304 H 548-6772 Available (937) 692-5145 OH-70157812 [email protected] MERRY CHRISTMAS!!! A special supplement to Warner Bros. Warner The hap-hap- happiest Christmas This year marks the 30th anniversary of “National Lampoon’s Christmas Vacation” (1989), a film touted as a modern holiday classic. Chevy Chase (“Saturday Night Live”) stars as Clark, the hapless patriarch of the Griswold family who is determined to have a quiet, picture-perfect family Christmas. Unfortunately, fate has other plans for poor Clark. Juliette Lewis (“Natural Born Killers,” 1994), Beverly D’Angelo (“Coal Miner’s Daughter,” 1980) and Johnny Galecki (“The Big Bang Theory”) also star. OH-70157837 2 Friday, November 22, 2019 HOLIDAY TV GUIDE The Daily Advocate HolidayTV | National Lampoon’s Christmas Vacation A Griswold anniversary Celebrate 30 years of ‘National Lampoon’s Christmas Vacation’ By Kyla Brewer “Maybe he was a genius, and God bless him if TV Media he was. There are so few of us,” he quipped. The first two “Vacation” films followed the or so many of us, the holidays are all Griswolds on ill-fated, epic family vacations. In about family, and one close-knit clan has “Christmas Vacation,” Clark is determined to have Fbeen bringing Christmas cheer — and a a picture-perfect family Christmas at home. But, lot of laughs — for 30 years. as usual, just about everything goes wrong. After The Griswolds have been worming their way spending hours stringing lights all over his house, into the hearts of holiday revelers for three he can’t get them to work. -
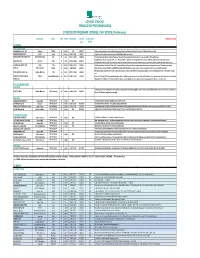
2020 Syndicated Program Guide.Xlsx
CONTENT STRATEGY SYNDICATED PROGRAM GUIDE SYNDICATED PROGRAM LISTINGS / M-F STRIPS (Preliminary) Distributor Genre Time Terms Barter Split Renewed Syndication UPDATED 1/28/20 thru Debut FUTURES FALL 2020 STRIPS CARBONARO EFFECT, THE Trifecta Reality 30 Barter TBA 2020-21 Hidden-camera prank series hosted by magician and prankster Michael Carbonaro. From truTV. Weekly offering as well. COMMON KNOWLEDGE Sony TV Game 30 Barter 3:00N / 5:00L 2020-21 Family friendly, multiple choice quiz game off GSN, hosted by Joey Fatone. DREW BARRYMORE SHOW, THE CBS TV Distribution Talk 60 Cash+ 4:00N / 10:30L 2021-22 Entertainment talk show hosted by Producer, Actress & TV personality Drew Barrymore. 2 runs available. CBS launch group. Food/Lifestyle talk show spin-off of Dr. Oz's "The Dish on Oz" segment", hosted by Daphne Oz, Vanessa Williams, Gail Simmons(Top Chef), Jamika GOOD DISH, THE Sony TV Talk 60 Cash+ 4:00N / 10:30L 2021-22 Pessoa(Next Food Star). DR. OZ production team. For stations includes sponsorable vignettes, local content integrations, unique digital & social content. LAUREN LAKE SHOW, THE MGM Talk 30 Barter 4:00N / 4:00L 2020-21 Conflict resolution "old-shool" talker with "a new attitude" and Lauren Lake's signature take-aways and action items for guests. 10 episodes per week. LOCK-UP NBC Universal Reality 60 Barter 8:00N/8:00L 2020-21 An inside look at prison life. Ran on MSNBC from 2005-2017. Flexibility, can be used as a strip, a weekly or both, 10 runs available, 5 eps/wk. Live-to-tape daily daytime talker featuring host Nick Cannon's take on the "latest in trending pop culture stories and celeb interviews." FOX launch. -

It's a Family Affair As Nickelodeon's Hit Game Show Brainsurge Returns As Family Brainsurge, Beginning Monday, July 18, at 8 P.M
It's a Family Affair as Nickelodeon's Hit Game Show BrainSurge Returns as Family BrainSurge, Beginning Monday, July 18, at 8 P.M. (ET/PT) Host Jeff Sutphen Returns for Hit Game Show's Third Season with All-New Brain Twisters Now for the Entire Family; Episodes Featuring Celebrities and Their Families Include Larry King, Vanessa Williams, Nicole Eggert, Jennie Garth and Joey Fatone Casts of Nickelodeon's Own Live-Action Hits iCarly, Victorious and Others also Team Up with Regular Families and Join in the Fun LOS ANGELES, July 12, 2011 /PRNewswire via COMTEX/ -- Nickelodeon makes room for the entire family as Family BrainSurge kicks off on Monday, July 18, with a week of all-new episodes premiering at 8:00 p.m. (ET/PT) on Nick at Nite. Jeff Sutphen returns to host the third season featuring celebrity guests playing with their families, including Larry King, Vanessa Williams, Joey Fatone, Jennie Garth, Nicole Eggert, Candace Cameron Bure, Anthony Anderson, Terry Crews and WWE Superstars. Also, several Nick stars from iCarly, Victorious, Bucket & Skinner, Supah Ninjas and House of Anubis partner with regular parent and kid teams. Produced by 310 Entertainment and Stone & Company, Family BrainSurge will continue to offer viewers even more brain twisters, signature slime and the fun of families playing together while competing for prizes. (Photo: http://photos.prnewswire.com/prnh/20110712/NY33913-a ) (Photo: http://photos.prnewswire.com/prnh/20110712/NY33913-b ) "We know that our viewers are playing along with BrainSurge at home with their own families," said Marjorie Cohn, Nickelodeon's President, Original Programming and Development.