Sharknado Social Media Analysis with SAP HANA and Predictive Analysis
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Festive Funnies
December 14 - 20, 2019 Festive Funnies www.southernheatingandac.biz/ Homer from “The Simpsons” $10.00 OFF any service call one per customer. 910-738-70002105-A EAST ELIZABETHTOWN RD CARDINAL HEART AND VASCULAR PLLC Suriya Jayawardena MD. FACC. FSCAI Board Certified Physician Heart Disease, Leg Pain due to poor circulation, Varicose Veins, Obesity, Erectile Dysfunction and Allergy clinic. All insurances accepted. Same week appointments. Friendly Staff. Testing done in the same office. Plan for Healthy Life Style 4380 Fayetteville Rd. • Lumberton, NC 28358 Tele: 919-718-0414 • Fax: 919-718-0280 • Hours of Operation: 8am-5pm Monday-Friday Page 2 — Saturday, December 14, 2019 — The Robesonian ‘The Simpsons,’ ‘Bless the Harts,’ ‘Bob’s Burgers’ and ‘Family Guy’ air Christmas Specials By Breanna Henry “The Simpsons” is known for must be tracked down if there is overall, and having to follow a se- job at a post office. However, Lin- recognize the “Game of Thrones” TV Media its celebrity guest voices (many to be any hope of saving Christ- ries with 672 episodes (and a da discovers an undelivered pack- reference in this episode title, a celebs lend their own voices to a mas. In completely unrelated movie) under its belt might seem age and ends up going a little off- spin on the Stark family slogan uddle up for a festive, fun- storyline that’s making fun of news, this year’s Springfield Mall difficult if it weren’t for how book to ensure it reaches its in- “Winter is Coming.” Cfilled night on Fox, when the them). A special episode is the Santa is none other than famed much heart “Bless the Harts” has tended destination. -

WORST COOKS in AMERICA: CELEBRITY EDITION Contestant Bios
Press Contact: Lauren Sklar Phone: 646-336-3745; Email: [email protected] WORST COOKS IN AMERICA: CELEBRITY EDITION Contestant Bios MINDY COHN Mindy Cohn made her acting debut as the witty, precious Eastland Academy student Natalie Green in the hit comedy series The Facts of Life. She was discovered while attending Westlake School for Girls in Bel Air, California, when actress Charlotte Rae and producer Norman Lear came to the school to authenticate scripts for their new show. Ms. Rae was so taken with the vivacious eighth grader she convinced producers to create a role for her. Mindy remained on the show for all nine seasons, also traveling to Paris and Australia with her co-stars to produce two successful television movies based on the series. Concurrently, with her role in Facts, Mindy played “Rose Jenko” in Fox’s 21 Jump Street. Other notable television appearances included Diff’rent Strokes, Double Trouble, Charles in Charge, Dream On and Suddenly Susan. In 1983, Mindy appeared in her first professional stage performance in Table Settings, written and directed by James Lapine and filmed for HBO Television. The illustrious cast included Eileen Heckart, Stockard Channing, Robert Klein, Peter Riegart, and Dinah Manoff. She went on to make her feature film debut in The Boy Who Could Fly, which co-starred Colleen Dewhurst, Fred Gwynne and Fred Savage. Mindy took a hiatus from her career to attend university, where she earned a Bachelor’s degree in Cultural Anthropology and a Masters in Education. During this time, she studied improvisation and scene work with Gary Austin and Larry Moss. -

Television Sharknados and Twitter Storms
Television Sharknados and Twitter Storms: Cult Film Fan Practices in the Age of Social Media Branding Stephen William Hay A thesis submitted to Victoria University of Wellington in fulfilment of the regulations for the degree of Master of Arts in Media Studies Victoria University of Wellington 2016 Abstract This thesis examines the Syfy channel’s broadcast of the television movie Sharknado and the large number of tweets that were sent about it. Sharknado’s audience engaged in cult film viewing practices that can be understood using paracinema theory. Paracinema engagement with cult films has traditionally taken place in midnight screenings in independent movie theatres and private homes. Syfy’s audience was able to engage in paracinematic activity that included making jokes about Sharknado’s low quality of production and interacting with others who were doing the same through the affordances of Twitter. In an age where branding has become increasingly important, Syfy clearly benefited from all the fan activity around its programming. Critical branding theory argues that the value generated by a business’s brand comes from the labour of consumers. Brand management is mostly about encouraging and managing consumer labour. The online shift of fan practices has created new opportunities for brand managers to subsume the activities of consumers. Cult film audience practices often have an emphasis on creatively and collectively engaging in rituals and activities around a text. These are the precise qualities that brands require from their consumers. Sharknado was produced and marketed by Syfy to invoke the cult film subculture as part of Syfy’s branding strategy. -

Television Academy Awards
2019 Primetime Emmy® Awards Ballot Outstanding Comedy Series A.P. Bio Abby's After Life American Housewife American Vandal Arrested Development Atypical Ballers Barry Better Things The Big Bang Theory The Bisexual Black Monday black-ish Bless This Mess Boomerang Broad City Brockmire Brooklyn Nine-Nine Camping Casual Catastrophe Champaign ILL Cobra Kai The Conners The Cool Kids Corporate Crashing Crazy Ex-Girlfriend Dead To Me Detroiters Easy Fam Fleabag Forever Fresh Off The Boat Friends From College Future Man Get Shorty GLOW The Goldbergs The Good Place Grace And Frankie grown-ish The Guest Book Happy! High Maintenance Huge In France I’m Sorry Insatiable Insecure It's Always Sunny in Philadelphia Jane The Virgin Kidding The Kids Are Alright The Kominsky Method Last Man Standing The Last O.G. Life In Pieces Loudermilk Lunatics Man With A Plan The Marvelous Mrs. Maisel Modern Family Mom Mr Inbetween Murphy Brown The Neighborhood No Activity Now Apocalypse On My Block One Day At A Time The Other Two PEN15 Queen America Ramy The Ranch Rel Russian Doll Sally4Ever Santa Clarita Diet Schitt's Creek Schooled Shameless She's Gotta Have It Shrill Sideswiped Single Parents SMILF Speechless Splitting Up Together Stan Against Evil Superstore Tacoma FD The Tick Trial & Error Turn Up Charlie Unbreakable Kimmy Schmidt Veep Vida Wayne Weird City What We Do in the Shadows Will & Grace You Me Her You're the Worst Young Sheldon Younger End of Category Outstanding Drama Series The Affair All American American Gods American Horror Story: Apocalypse American Soul Arrow Berlin Station Better Call Saul Billions Black Lightning Black Summer The Blacklist Blindspot Blue Bloods Bodyguard The Bold Type Bosch Bull Chambers Charmed The Chi Chicago Fire Chicago Med Chicago P.D. -

275. – Part One
275. – PART ONE 275. Clifford (1994) Okay, here’s the deal: I don’t know you, you don’t know me, but if you are anywhere near a television right now I need you to stop whatever it is that you’re doing and go watch “Clifford” on HBO Max. This is another film that has a 10% score on Rotten Tomatoes which just leads me to believe that all of the critics who were popular in the nineties didn’t have a single shred of humor in any of their non-existent funny bones. I loved this movie when I was seven, and I love it even more when I’m thirty-three. It’s genius. Martin Short (who at the time was forty-four) plays a ten-year-old hyperactive nightmare child from hell. I mean it, this kid might actually be the devil. He is straight up evil, conniving, manipulative and all-told probably causes no less than ten million dollars-worth of property damage. And, again, the plot is so simple – he just wants to go to Dinosaur World. There are so many comedy films with such complicated plots and motivations for their characters, but the simplistic genius of “Clifford” is just this – all this kid wants on the entire planet is to go to Dinosaur World. That’s it. The movie starts with him and his parents on an plane to Hawaii for a business trip, and Clifford knows that Dinosaur Land is in Los Angeles, therefore he causes so much of a ruckus that the plane has to make an emergency landing. -

Holiday TV Guide 2020
HolidayTV Better watch out 20th Century Fox Thirty years after premiering in theaters, this movie about a boy who protects his home from burglars at Christmastime is still entertaining viewers young and old. Kevin McCallister (Macaulay Culkin, “My Girl,” 1991) learns to be careful what he wishes for after his mom and dad accidentally leave him behind as they fly to Paris for the holidays in “Home Alone,” airing Thursday, Nov. 26, on Freeform. Holiday TV| Home Alone 30th Anniversary 30 years of holiday high jinx ‘Home Alone’ celebrates big milestone By Kyla Brewer TV Media their extended family scramble to make it to the airport in time to catch their flight. In the ensuing chaos and confusion, parents Kate (Catherine he holidays offer movie fans a treasure O’Hara, “Schitt’s Creek”) and Peter (John Heard, trove of options, old and new. Some are “Cutter’s Way,” 1981) forget young Kevin, who Tfunny, some are heartwarming, some are had been sent to sleep in the attic after causing a inspirational and a precious few are all of those ruckus the night before. The boy awakens to find things combined. One such modern classic is cel- his home deserted and believes that his wish for ebrating a milestone this year, and viewers won’t his family to disappear has come true. want to miss it. At first, Kevin’s new parent-and-sibling-free Macaulay Culkin (“My Girl,” 1991) stars as Kevin existence seems ideal as he jumps on his parents’ McCallister, a boy who is left behind when his fam- bed, raids his big brother’s room, eats ice cream ily goes on vacation during the holidays, in “Home for supper and watches gangster movies. -

Hailie Sahar Joe Mantello
winter 2020 POSE 'S HAILIE SAHAR BOYS IN THE BAND DIRECTOR JOE MANTELLO PLUS... SINGER TOM GOSS | NPR'S TYLER PRATT PHOTOGRAPHER JAY ARCH | THE WIZARD OF OZ 22 What is Hope? | by Darius Mooring "I am changing my hope from being the light at the end of the tunnel, to the desire to see the light within me illuminate Contents wherever I stand." Actors Fred Stone and David Montgomery who starred in the Wizard of Oz on Broadway. 244 Hailie Sahar: The Genuine Article After working in the business as an out person of trans experience for over fifteen years, trans actress Hailie Sahar has done it all. 288 Out in Central Pennsylvania | Mary C. Foltz A review and interview with "Out in Central Pennsylvania" authors Bill Burton and Barry Loveland. 300 Joe Mantello & Boys in the Band Long time friends Joe Mantello and Bill Sanders reminisce and discuss the Boys in the Band 4 Oz from a Queer Perspective | by Liz Bradbury Forget Hogwarts and Fly Back Over the Rainbow To Meet the Trans, Queer, and Non-Binary Inhabitants of Oz. 7 A Space for Aces | by Scott Peterson The Bradbury-Sullivan LGBT Community Center's asexual and aromantic community group celebrates its second "Aceversary!" 366 Ian Ziering 9 VINCINT Beverley Hills, 90210 and Sharknado star Ian Ziering discusses his Praised by Billboard as a “legend in the making,” pop superstar new role in The CW's Swamp Thing. VINCINT is having the biggest year of his career. 388 Tyler Pratt 100 Photography Jay Arch NPR All Things Considered anchor and reporter Tyler Pratt Jay discusses his work documenting the local LGBTQ+ community. -

'Sharknado' Hits California Hard, Internet Even Harder
‘Sharknado’ Hits California Hard, Internet Even Harder Chris Nichols The Exchange July 12, 2013 If something could actually break the social Web because of extreme overexposure -- as the Harlem Shake taught us, it can't -- the "Sharknado" rage of the moment would be a candidate to do it. The Syfy original movie, which aired Thursday night, became a dominant force on the Internet during its airing and afterward, with Twitter and search traffic levels suggesting cancer had been cured or an intelligent alien species found. Image from Sharknado On Twitter itself, there was no escaping #sharknado. According to one report, the peak activity was about 5,000 tweets a minute right before 11 p.m. E.T., when "Sharknado" was concluding. Google Trends also showed quite an interest, with "Sharknado" collecting more than 500,000 searches July 11. Starring Ian Ziering, best known for his 1990s work on "Beverly Hills, 90210," and Tara Reid, of "American Pie" fame, "Sharknado" is the story of a terrible and powerful Pacific Ocean hurricane, one spawning tornadic winds that scooped up sharks by the hundreds and deposited them along the California coast, where naturally they feasted on the residents of greater Los Angeles. The still image from a Syfy clip here shows how serious the matter was. [Related: See the 'Sharknado' Storify experience] Many people were consumed. A Ferris wheel broke loose. Explosives were dropped into the storms to show them who's boss. Ziering used a chainsaw. He later told CBSNews: "When I read the scene where I'm actually chainsawing my way out of the belly of a shark, how could a guy turn that down when that's in the job description?" He couldn't. -
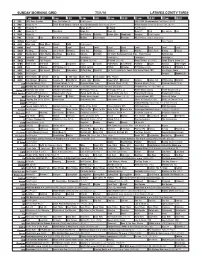
Sunday Morning Grid 7/31/16 Latimes.Com/Tv Times
SUNDAY MORNING GRID 7/31/16 LATIMES.COM/TV TIMES 7 am 7:30 8 am 8:30 9 am 9:30 10 am 10:30 11 am 11:30 12 pm 12:30 2 CBS CBS News Sunday Face the Nation (N) Paid Program 2016 PGA Championship Final Round. (N) Å 4 NBC News (N) Å 2016 Ricoh Women’s British Open Championship Final Round. (N) Å Action Sports From Long Beach, Calif. (N) Å 5 CW News (N) Å News (N) Å In Touch Paid Program 7 ABC News (N) Å This Week News (N) News (N) News Å Paid Eye on L.A. Paid 9 KCAL News (N) Joel Osteen Schuller Pastor Mike Woodlands Amazing Paid Program 11 FOX In Touch Paid Fox News Sunday Midday Paid Program Pregame MLS Soccer: Timbers at Sporting 13 MyNet Paid Program Paid Program 18 KSCI Man Land Mom Mkver Church Faith Paid Program 22 KWHY Local Local Local Local Local Local Local Local Local Local Local Local 24 KVCR Painting Painting Joy of Paint Wyland’s Paint This Painting Kitchen Mexico Martha Ellie’s Real Baking Project 28 KCET Wunderkind 1001 Nights Bug Bites Bug Bites Edisons Biz Kid$ Ed Slott’s Retirement Road Map... From Forever Eat Dirt-Axe 30 ION Jeremiah Youssef In Touch Leverage Å Leverage Å Leverage Å Leverage Å 34 KMEX Conexión Paid Program El Chavo (N) (TVG) Al Punto (N) (TVG) Netas Divinas (N) (TV14) Como Dice el Dicho (N) 40 KTBN Walk in the Win Walk Prince Carpenter Jesse In Touch PowerPoint It Is Written Pathway Super Kelinda John Hagee 46 KFTR Paid Choques El Príncipe (TV14) Fútbol Central Fútbol Choques El Príncipe (TV14) Fórmula 1 Fórmula 1 50 KOCE Odd Squad Odd Squad Martha Cyberchase Clifford-Dog WordGirl On the Psychiatrist’s Couch With Daniel Amen, MD San Diego: Above 52 KVEA Paid Program Enfoque Haywire (R) 56 KDOC Perry Stone In Search Lift Up J. -
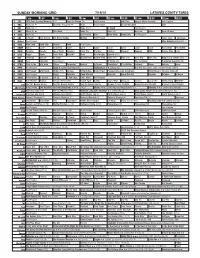
Sunday Morning Grid 7/19/15 Latimes.Com/Tv Times
SUNDAY MORNING GRID 7/19/15 LATIMES.COM/TV TIMES 7 am 7:30 8 am 8:30 9 am 9:30 10 am 10:30 11 am 11:30 12 pm 12:30 2 CBS CBS News Sunday Morning (N) Å Face the Nation (N) Paid Program Golf Res. Gospel Music Presents Paid Program 4 NBC News (N) Å Meet the Press (N) Å News Paid Program Beach Volleyball Golf 5 CW News (N) Å News (N) Å In Touch Paid Program 7 ABC News (N) Å This Week News (N) News (N) News Å Explore Open Champ. 9 KCAL News (N) Joel Osteen Hour Mike Webb Woodlands Paid Program 11 FOX In Touch Joel Osteen Fox News Sunday Midday Paid Program I Love Lucy I Love Lucy 13 MyNet Paid Program Miss Nobody (2010) (R) 18 KSCI Man Land Rock Star Church Faith Paid Program 22 KWHY Cosas Local Jesucristo Local Local Gebel Local Local Local Local RescueBot RescueBot 24 KVCR Painting Dowdle Joy of Paint Wyland’s Paint This Painting Kitchen Mexican Cooking BBQ Simply Ming Lidia 28 KCET Raggs Space Travel-Kids Biz Kid$ News Asia Insight Special (TVG) 30 ION Jeremiah Youssef In Touch Bucket-Dino Bucket-Dino Doki (TVY) Doki (TVY) Dive, Olly Dive, Olly Rudy ››› (1993) (PG) 34 KMEX Paid Conexión Paid Program Al Punto (N) Tras la Verdad República Deportiva (N) 40 KTBN Walk in the Win Walk Prince Carpenter Hour of In Touch PowerPoint It Is Written Pathway Super Kelinda Jesse 46 KFTR Paid Program Zoom › (2006) Tim Allen. (PG) Chimpanzee ›› (2012) (G) Ben Hur Un príncipe judío enfrenta traición. -

Holidaytv | National Lampoon’S Christmas Vacation a Griswold Anniversary Celebrate 30 Years of ‘National Lampoon’S Christmas Vacation’
Kreitzer Funeral Home OH-70157806 Funeral Directors David Fellers HeatingBOLYARD & Cooling, Inc. Matthew Fellers olidayTV Financing 204 N. Main St. Arcanum, Ohio 45304 H 548-6772 Available (937) 692-5145 OH-70157812 [email protected] MERRY CHRISTMAS!!! A special supplement to Warner Bros. Warner The hap-hap- happiest Christmas This year marks the 30th anniversary of “National Lampoon’s Christmas Vacation” (1989), a film touted as a modern holiday classic. Chevy Chase (“Saturday Night Live”) stars as Clark, the hapless patriarch of the Griswold family who is determined to have a quiet, picture-perfect family Christmas. Unfortunately, fate has other plans for poor Clark. Juliette Lewis (“Natural Born Killers,” 1994), Beverly D’Angelo (“Coal Miner’s Daughter,” 1980) and Johnny Galecki (“The Big Bang Theory”) also star. OH-70157837 2 Friday, November 22, 2019 HOLIDAY TV GUIDE The Daily Advocate HolidayTV | National Lampoon’s Christmas Vacation A Griswold anniversary Celebrate 30 years of ‘National Lampoon’s Christmas Vacation’ By Kyla Brewer “Maybe he was a genius, and God bless him if TV Media he was. There are so few of us,” he quipped. The first two “Vacation” films followed the or so many of us, the holidays are all Griswolds on ill-fated, epic family vacations. In about family, and one close-knit clan has “Christmas Vacation,” Clark is determined to have Fbeen bringing Christmas cheer — and a a picture-perfect family Christmas at home. But, lot of laughs — for 30 years. as usual, just about everything goes wrong. After The Griswolds have been worming their way spending hours stringing lights all over his house, into the hearts of holiday revelers for three he can’t get them to work. -

O Cinema Trash E a Reciclagem Da Indústria Cultural Coleção E.Books
JULIANO FERREIRA GONÇALVES O CINEMA TRASH E A RECICLAGEM DA INDÚSTRIA CULTURAL COLEÇÃO E.BOOKS RÁDIO, TV E INTERNET O CINEMA TRASH E A RECICLAGEM DA INDÚSTRIA CULTURAL JULIANO FERREIRA GONÇALVES O CINEMA TRASH E A RECICLAGEM DA INDÚSTRIA CULTURAL Coleção E.books FAPCOM A Coleção E.books FAPCOM é fruto do trabalho de alunos de graduação da Faculdade Paulus de Tecnologia e Comunicação. Os conteúdos e temas publicados concentram-se em três grandes áreas do saber: filosofia, comunicação e tecnologias. Entendemos que a sociedade contemporânea é transformada em todas as suas dimensões por inovações tecnológicas, consolida-se imersa numa cultura comunicacional, e a filosofia, face a esta conjuntura, nos ocorre como essencial para compreendermos estes fenômenos. A união destas três grandes áreas, portanto, nos prepara para pensar a vida social. A Coleção E.books FAPCOM consolida a produ- ção do saber e a torna pública,a fim de fomentar, nos mais diversos ambientes sociais, a reflexão e a crítica. Conselho Científico Antonio Iraildo Alves de Brito Claudenir Modolo Alves Claudiano Avelino dos Santos Jakson Ferreira de Alencar Márcia Regina Carvalho da Silva Valdir José de Castro Livros da Coleção E.books FAPCOM A COMUNICAÇÃO NA IGREJA CATÓLICA LATINO-AMERICANA Paulinele José Teixeira ASCENSÃO DIALÉTICA NO BANQUETE Iorlando Rodrigues Fernandes COMUNICAÇÃO E AMBIENTE DIGITAL Cinzia Giancinti A ONTOLOGIA DA ALMA EM SÃO TOMÁS DE AQUINO Moacir Ferreira Filho PARA REFLETIR O QUE A GENTE ESQUECIA: ANÁLISE DE VIDEOCLIPES DA BANDA O RAPPA Talita Barauna