Improving Searcher Models Using Mouse Cursor Activity
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Coloriync J43 Chooser {Antral Strip Limltruli Panels; Date 3; ‘Time I»
US 20120174031Al (19) United States (12) Patent Application Publication (10) Pub. N0.: US 2012/0174031 A1 DONDURUR et a]. (43) Pub. Date: Jul. 5, 2012 (54) CLICKLESS GRAPHICAL USER INTERFACE (52) US. Cl. ...................................................... .. 715/808 (75) Inventors: MEHMET DONDURUR, (57) ABSTRACT DHAHRAN (SA); AHMET Z. SAHIN’ DH AHRAN (SA) The chckless graphical user mterface provldes a pop-up Wm doW When a cursor is moved over designated areas on the (73) Assigneez KING FAHD UNIVERSITY OF screen. The pop-up WindoW includes menu item choices, e. g., PETROLEUM AND MINERALS “double click”, “single click”, “close” that execute ‘When the DH AHRAN (SA) ’ cursor is moved over the item. This procedure eliminates the traditional ‘mouse click’, thereby allowing users to move the cursor over the a lication or ?le and 0 en it b choosin (21) Appl' NO" 12/985’165 among the aforerrrifntioned choices in the? ?le or Zipplicatior'i . bein focused on. The 0 -u WindoW shoWs the navi ation (22) Flled: Jan‘ 5’ 2011 choiges in the form of 1; tgxt,pe.g., yes/no or color, egg, red/ _ _ _ _ blue, or character, such as triangle for ‘yes’ and square for Pubhcatlon Classl?catlon ‘no’. Pop-up WindoW indicator types are virtually unlimited (51) Int, Cl, and canbe changed to any text, color or character. The method G06F 3/048 (200601) is compatible With touch pads and mouses. .5 10a About This Cam pater Appearance 5;‘ Fort Menu ?ptinns System Pm?ler Talk Calculatar Coloriync J43 Chooser {antral Strip limltruli Panels; Date 3; ‘time I» f Favmjltes } Extensions Manager B "Dali?i ?' File Exchange Q Key Caps File Sharing Patent Application Publication Jul. -
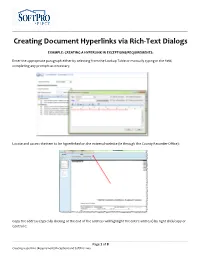
Creating Document Hyperlinks Via Rich-Text Dialogs
__________________________________________________________________________________________________ Creating Document Hyperlinks via Rich-Text Dialogs EXAMPLE: CREATING A HYPERLINK IN EXCEPTIONS/REQUIREMENTS: Enter the appropriate paragraph either by selecting from the Lookup Table or manually typing in the field, completing any prompts as necessary. Locate and access the item to be hyperlinked on the external website (ie through the County Recorder Office): Copy the address (typically clicking at the end of the address will highlight the entire address) by right click/copy or Control C: __________________________________________________________________________________________________ Page 1 of 8 Creating Hyperlinks (Requirements/Exceptions and SoftPro Live) __________________________________________________________________________________________________ In Select, open the Requirement or Exception, highlight the text to hyperlink. Click the Add a Hyperlink icon: __________________________________________________________________________________________________ Page 2 of 8 Creating Hyperlinks (Requirements/Exceptions and SoftPro Live) __________________________________________________________________________________________________ The Add Hyperlink dialog box will open. Paste the link into the Address field (right click/paste or Control V) NOTE: The Text to display (name) field will autopopulate with the text that was highlighted. Click OK. The text will now be underlined indicating a hyperlink. __________________________________________________________________________________________________ -

Welcome to Computer Basics
Computer Basics Instructor's Guide 1 COMPUTER BASICS To the Instructor Because of time constraints and an understanding that the trainees will probably come to the course with widely varying skills levels, the focus of this component is only on the basics. Hence, the course begins with instruction on computer components and peripheral devices, and restricts further instruction to the three most widely used software areas: the windows operating system, word processing and using the Internet. The course uses lectures, interactive activities, and exercises at the computer to assure accomplishment of stated goals and objectives. Because of the complexity of the computer and the initial fear experienced by so many, instructor dedication and patience are vital to the success of the trainee in this course. It is expected that many of the trainees will begin at “ground zero,” but all should have developed a certain level of proficiency in using the computer, by the end of the course. 2 COMPUTER BASICS Overview Computers have become an essential part of today's workplace. Employees must know computer basics to accomplish their daily tasks. This mini course was developed with the beginner in mind and is designed to provide WTP trainees with basic knowledge of computer hardware, some software applications, basic knowledge of how a computer works, and to give them hands-on experience in its use. The course is designed to “answer such basic questions as what personal computers are and what they can do,” and to assist WTP trainees in mastering the basics. The PC Novice dictionary defines a computer as a machine that accepts input, processes it according to specified rules, and produces output. -

Fuzzy Mouse Cursor Control System for Computer Users with Spinal Cord Injuries
Georgia State University ScholarWorks @ Georgia State University Computer Science Theses Department of Computer Science 8-8-2006 Fuzzy Mouse Cursor Control System for Computer Users with Spinal Cord Injuries Tihomir Surdilovic Follow this and additional works at: https://scholarworks.gsu.edu/cs_theses Part of the Computer Sciences Commons Recommended Citation Surdilovic, Tihomir, "Fuzzy Mouse Cursor Control System for Computer Users with Spinal Cord Injuries." Thesis, Georgia State University, 2006. https://scholarworks.gsu.edu/cs_theses/49 This Thesis is brought to you for free and open access by the Department of Computer Science at ScholarWorks @ Georgia State University. It has been accepted for inclusion in Computer Science Theses by an authorized administrator of ScholarWorks @ Georgia State University. For more information, please contact [email protected]. i Fuzzy Mouse Cursor Control System For Computer Users with Spinal Cord Injuries A Thesis Presented in Partial Fulfillment of Requirements for the Degree of Master of Science in the College of Arts and Sciences Georgia State University 2005 by Tihomir Surdilovic Committee: ____________________________________ Dr. Yan-Qing Zhang, Chair ____________________________________ Dr. Rajshekhar Sunderraman, Member ____________________________________ Dr. Michael Weeks, Member ____________________________________ Dr. Yi Pan, Department Chair Date July 21st 2005 ii Abstract People with severe motor-impairments due to Spinal Cord Injury (SCI) or Spinal Cord Dysfunction (SCD), often experience difficulty with accurate and efficient control of pointing devices (Keates et al., 02). Usually this leads to their limited integration to society as well as limited unassisted control over the environment. The questions “How can someone with severe motor-impairments perform mouse pointer control as accurately and efficiently as an able-bodied person?” and “How can these interactions be advanced through use of Computational Intelligence (CI)?” are the driving forces behind the research described in this paper. -
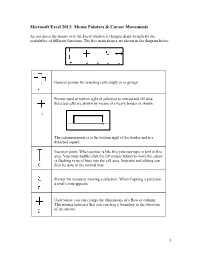
Microsoft Excel 2013: Mouse Pointers & Cursor Movements
Microsoft Excel 2013: Mouse Pointers & Cursor Movements As you move the mouse over the Excel window it changes shape to indicate the availability of different functions. The five main shapes are shown in the diagram below. General pointer for selecting cells singly or in groups Pointer used at bottom right of selection to extend and fill data. Selected cells are shown by means of a heavy border as shown. The extension point is at the bottom right of the border and is a detached square. Insertion point. When pointer is like this you may type in text in this area. You must double click the left mouse button to move the cursor (a flashing vertical line) into the cell area. Insertion and editing can then be done in the normal way. Pointer for menus or moving a selection. When Copying a selection a small cross appears Used where you can change the dimensions of a Row or column. This pointer indicates that you can drag a boundary in the direction of the arrows. 1 What do the different mouse pointer shapes mean in Microsoft Excel? The mouse pointer changes shape in Microsoft Excel depending upon the context. The six shapes are as follows: Used for selecting cells The I-beam which indicates the cursor position when editing a cell entry. The fill handle. Used for copying formula or extending a data series. To select cells on the worksheet. Selects whole row/column when positioned on the number/letter heading label. At borders of column headings. Drag to widen a column. -

Vista Wait Cursor Gif
Vista Wait Cursor Gif 1 / 4 Vista Wait Cursor Gif 2 / 4 3 / 4 С Vista Transformation Pack можете да промените изгледа на Windows XP и да го направите като Windows Vista. Пакета ... vista transformation pack .gif С Vista ... Updated Vista Rainbar's launcher for constant waiting cursor activity issue. On October 31, 2013, claimed that the 's counterpart, a, was more recognized than Windows Vista's wait cursor due to the cultural impact that .... So the blue circle animation that pops up next to the mouse pointer that shows ... and closing running programs in the tray, and the waiting animation ... a problem by performing a clean boot in Windows Vista or in Windows 7.. In your jQuery use: $("body").css("cursor", "progress");. and then back to normal again $("body").css("cursor", "default");.. N. ▻ Non- animated throbbers (1 C, 3 F) ... Ajax loader metal 512.gif 512 × 512; 45 KB ... Cursor Windows Vista.gif 32 × 32; 9 KB ... Wait.gif 40 × 40; 4 KB.. Download GIF Viewer for free. Windows 7/8/10-compatible animated .gif player. A C# program used to visualize and extract frames from .GIF files. (you need .. In this topic you'll learn more about static and animated cursors. ... in different context (Normal Select, Help Select, Working in background, Busy. ... colors, smooth transparency (alpha channel) - Supported by Windows XP, Vista and superior only ... which can be saved using various file formats (BMP, PSD, GIF, JPEG, WMF.. Windows Vista's "busy" cursor? Reply ... This always makes me forget my troubles. http://upload.wikimedia.org/wikipedia/en/3/3d/WaitCursor-300p.gif. -
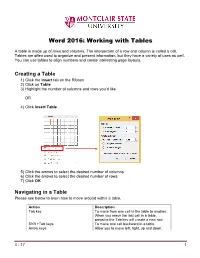
Word 2016: Working with Tables
Word 2016: Working with Tables A table is made up of rows and columns. The intersection of a row and column is called a cell. Tables are often used to organize and present information, but they have a variety of uses as well. You can use tables to align numbers and create interesting page layouts. Creating a Table 1) Click the Insert tab on the Ribbon 2) Click on Table 3) Highlight the number of columns and rows you’d like OR 4) Click Insert Table 5) Click the arrows to select the desired number of columns 6) Click the arrows to select the desired number of rows 7) Click OK Navigating in a Table Please see below to learn how to move around within a table. Action Description Tab key To move from one cell in the table to another. When you reach the last cell in a table, pressing the Tab key will create a new row. Shift +Tab keys To move one cell backward in a table. Arrow keys Allow you to move left, right, up and down. 4 - 17 1 Selecting All or Part of a Table There are times you want to select a single cell, an entire row or column, multiple rows or columns, or an entire table. Selecting an Individual Cell To select an individual cell, move the mouse to the left side of the cell until you see it turn into a black arrow that points up and to the right. Click in the cell at that point to select it. Selecting Rows and Columns To select a row in a table, move the cursor to the left of the row until it turns into a white arrow pointing up and to the right, as shown below. -

Cursor Utilities 8
CHAPTER 8 Cursor Utilities 8 This chapter describes the utilities that your application uses to draw and manipulate the cursor on the screen. You should read this chapter to find out how to implement cursors in your application. For example, you should change the arrow cursor to an I-beam cursor when it’s over text and to an animated cursor when a medium-length process is under way. Cursors are defined in resources; the routines in this chapter automatically call the Resource Manager as necessary. For more information about resources, see the chapter “Resource Manager” in Inside Macintosh: More Macintosh Toolbox. Color cursors are 8 defined in resources as well, though they use Color QuickDraw. For information about Color QuickDraw, see the chapter “Color QuickDraw” in this book. Cursor Utilities This chapter describes how to ■ create and display black-and-white and color cursors ■ change the cursor’s shape over different areas on the screen ■ display an animated cursor About the Cursor 8 A cursor is a 256-pixel, black-and-white image in a 16-by-16 pixel square usually defined by an application in a cursor ('CURS') resource. The cursor is an integral part of the Macintosh user interface. The user manipulates the cursor with the mouse to select objects or areas on the screen. (It appears only on the screen and never in an offscreen graphics port.) The user moves the cursor across the screen by moving the mouse. Most actions take place only when the user positions the cursor over an object on the screen, then clicks (presses and releases the mouse button). -

Microtemporality: at the Time When Loading-In-Progress
Microtemporality: At The Time When Loading-in-progress Winnie Soon School of Communication and Culture, Aarhus University [email protected] Abstract which data processing and code inter-actions are Loading images and webpages, waiting for social media feeds operated in real-time. The notion of inter-actions mainly and streaming videos and multimedia contents have become a draws references from the notion of "interaction" from mundane activity in contemporary culture. In many situations Computer Science and the notion of "intra-actions" from nowadays, users encounter a distinctive spinning icon during Philosophy. [3][4][5] The term code inter-actions the loading, waiting and streaming of data content. A highlights the operational process of things happen graphically animated logo called throbber tells users something within, and across, machines through different technical is loading-in-progress, but nothing more. This article substrates, and hence produce agency. investigates the process of data buffering that takes place behind a running throbber. Through artistic practice, an experimental project calls The Spinning Wheel of Life explores This article is informed by artistic practice, including the temporal and computational complexity of buffering. The close reading of a throbber and its operational logics of article draws upon Wolfgang Ernst’s concept of data buffering, as well as making and coding of a “microtemporality,” in which microscopic temporality is throbber. These approaches, following the tradition of expressed through operational micro events. [1] artistic research, allow the artist/researcher to think in, Microtemporality relates to the nature of signals and through and with art. [7] Such mode of inquiry questions communications, mathematics, digital computation and the invisibility of computational culture. -

Recurbot: Learn to Auto-Complete GUI Tasks from Human Demonstrations
RecurBot: Learn to Auto-complete GUI Tasks From Human Demonstrations Thanapong Intharah Abstract University College London On the surface, task-completion should be easy in graphical Gower Street, London, UK user interface (GUI) settings. In practice however, different [email protected] actions look alike and applications run in operating-system silos. Our aim within GUI action recognition and prediction Michael Firman is to help the user, at least in completing the tedious tasks University College London Gower Street, London, UK that are largely repetitive. We propose a method that learns m.fi[email protected] from a few user-performed demonstrations, and then predicts and finally performs the remaining actions in the Gabriel J. Brostow task. For example, a user can send customized SMS University College London messages to the first three contacts in a school’s Gower Street, London, UK spreadsheet of parents; then our system loops the process, [email protected] iterating through the remaining parents. First, our analysis system segments the demonstration into Acknowledgments: The authors were supported by the Royal Thai discrete loops, where each iteration usually included both Government Scholarship, and NERC NE/P019013/1. intentional and accidental variations. Our technical innovation approach is a solution to the standing motif-finding optimization problem, but we also find visual patterns in those intentional variations. The second Permission to make digital or hard copies of part or all of this work for personal or challenge is to predict subsequent GUI actions, classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation extrapolating the patterns to allow our system to predict and on the first page. -

Quick Guide for Accessible Powerpoint Presentations
Quick Guide for Accessible PowerPoint Presentations Accessible PowerPoint Presentations 1. On the Home tab, in the Drawing group, Add Alternative Text for Images and click the Arrange menu. Graphics Source: http://office.microsoft.com/en- 2. Click Selection Pane. Note: Alt text should be added for pictures, clip 001/powerpoint-help/creating-accessible- art, charts, tables, shapes, and SmartArt 3. Click the eye icon next to the text box to powerpoint-presentations- graphics. HA102013555.aspx?CTT=1 toggle its visibility. Add alt text by doing the following: Use Built-In Layout and Styling Features Review Outline View 1. Right click the image or object, and then click Format. Using pre-defined layouts and templates will The outline pane shows the reading order and 2. Click Alt Text. ensure help that your presentations have structure of the text in your presentation. 3. Type a description of the image or properly structured headings, lists, and proper • From Normal View, click on the outline object into the Description text box. reading order. tab to display the text outline for your The image description should focus on To apply “true layout” to a slide or an existing presentation. Go through the outline to the purpose and/or content of the image slide see if any information is missing. in the document. 1. Go to menu item: Home Set a Logical Tab Order TIP Use clear, but concise descriptions. 2. In the Slides section, select the Layout For example, “a red Ferrari” tells the button To check the order in which your slide content reader more about the image than “a 3. -

Acme: a User Interface for Programmers Rob Pike AT&T Bell Laboratories Murray Hill, New Jersey 07974
Acme: A User Interface for Programmers Rob Pike AT&T Bell Laboratories Murray Hill, New Jersey 07974 ABSTRACT A hybrid of window system, shell, and editor, Acme gives text-oriented applications a clean, expressive, and consistent style of interaction. Traditional window systems support inter- active client programs and offer libraries of pre-defined operations such as pop-up menus and buttons to promote a consistent user interface among the clients. Acme instead provides its clients with a fixed user interface and simple conventions to encourage its uniform use. Clients access the facilities of Acme through a file system interface; Acme is in part a file server that exports device-like files that may be manipulated to access and control the contents of its win- dows. Written in a concurrent programming language, Acme is structured as a set of communi- cating processes that neatly subdivide the various aspects of its tasks: display management, input, file server, and so on. Acme attaches distinct functions to the three mouse buttons: the left selects text; the mid- dle executes textual commands; and the right combines context search and file opening functions to integrate the various applications and files in the system. Acme works well enough to have developed a community that uses it exclusively. Although Acme discourages the traditional style of interaction based on typescript windows— teletypes—its users find Acme’s other services render typescripts obsolete. History and motivation The usual typescript style of interaction with Unix and its relatives is an old one. The typescript—an inter- mingling of textual commands and their output—originates with the scrolls of paper on teletypes.