Monte Carlo Simulation Generation Through Operationalization of Spatial Primitives
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Assignment of Master's Thesis
ASSIGNMENT OF MASTER’S THESIS Title: Git-based Wiki System Student: Bc. Jaroslav Šmolík Supervisor: Ing. Jakub Jirůtka Study Programme: Informatics Study Branch: Web and Software Engineering Department: Department of Software Engineering Validity: Until the end of summer semester 2018/19 Instructions The goal of this thesis is to create a wiki system suitable for community (software) projects, focused on technically oriented users. The system must meet the following requirements: • All data is stored in a Git repository. • System provides access control. • System supports AsciiDoc and Markdown, it is extensible for other markup languages. • Full-featured user access via Git and CLI is provided. • System includes a web interface for wiki browsing and management. Its editor works with raw markup and offers syntax highlighting, live preview and interactive UI for selected elements (e.g. image insertion). Proceed in the following manner: 1. Compare and analyse the most popular F/OSS wiki systems with regard to the given criteria. 2. Design the system, perform usability testing. 3. Implement the system in JavaScript. Source code must be reasonably documented and covered with automatic tests. 4. Create a user manual and deployment instructions. References Will be provided by the supervisor. Ing. Michal Valenta, Ph.D. doc. RNDr. Ing. Marcel Jiřina, Ph.D. Head of Department Dean Prague January 3, 2018 Czech Technical University in Prague Faculty of Information Technology Department of Software Engineering Master’s thesis Git-based Wiki System Bc. Jaroslav Šmolík Supervisor: Ing. Jakub Jirůtka 10th May 2018 Acknowledgements I would like to thank my supervisor Ing. Jakub Jirutka for his everlasting interest in the thesis, his punctual constructive feedback and for guiding me, when I found myself in the need for the words of wisdom and experience. -

Decentralized Social Data Sharing
Decentralized Social Data Sharing by Alan Davoust A Thesis submitted to the Faculty of Graduate Studies and Post-Doctoral Affairs in partial fulfilment of the requirements for the degree of Doctor of Philosophy in Electrical and Computer Engineering Ottawa-Carleton Institute for Electrical and Computer Engineering (OCIECE) Department of Systems and Computer Engineering Carleton University Ottawa, Ontario, Canada 2015 Copyright c 2015 - Alan Davoust Abstract Many data sharing systems are open to arbitrary users on the Internet, who are independent and self-interested agents. Therefore, in addition to traditional design goals such as technical performance, data sharing systems should be designed to best support the strategic interactions of these agents. Our research hypothesis is that designs that maximize the participants’ autonomy can produce useful data sharing systems. We apply this design principle to both the system architecture and the functional design of a data sharing system, and study the resulting class of systems, which we call Decentralized Social Data Sharing ((DS)2) systems. We formally define this class of systems and provide a reference implementation and an example application: a distributed wiki system called P2Pedia. P2Pedia implements a decentralized collaboration model, where the users are not required to reach a consensus, and instead benefit from being exposed to multiple viewpoints. We demonstrate the value of this collaboration model through an extensive user study. Allowing the users to autonomously control their data prevents the system archi- tecture from being optimized for efficient query processing. We show that Regular Path Queries, a useful class of graph queries, can still be processed on the shared data: although in the worst case such queries are intractable, we propose a cost estimation technique to identify tractable queries from partial knowledge of the data. -

Gérez Votre Documentation Projet Comme Du Code
Gérez votre documentation projet comme du code Raphaël Semeteys - Consultant chez AtoS Publié dans GLMF n°158 – Mars 2013 https://connect.ed-diamond.com/GNU-Linux-Magazine/GLMF-158/Gerez-votre-documentation-projet-comme-du-code La documentation d'un projet,qu'il soit libre ou non, est encore souvent vue aujourd'hui comme la dernière roue du carrosse : on la gère si on a le temps et en vrai si on en a vraiment envie. Ben oui, on est développeurs et on ne cherche pas forcément à se faire publier chez O'Reilly. Bref on aime écrire, ça oui, mais surtout du code ! Sur mes différents projets, et notamment ceux qui sont libres1 j'ai toujours cherché LE format pivot qui idéalement me permettrait de gérer et de générer mes documents. Naturellement j'ai A adopté L TEX, amoureux du parfait rendu qu'il génère en PDF. Mais bon... il faut quand même être un peu réaliste, ce ne sont pas ni ma copine, ni ma mère, ni mon grand-père qui vont contribuer à la documentation de mon projet dans ces conditions ! Quelles n'ont donc pas étés ma surprise et ma joie lorsque j'ai découvert ce que je vais vous exposer ici : un format pivot lisible par tous et des outils libres pour le manipuler. Ta-dam ! Je vous présente geekettes et geeks... Markdown, Pandoc et Gitit ! Le tuple qui a fait émerger pour moi le concept code <-> edoc. Pour cela, un grand merci à mon collègue Romain Vimont qui m'a fait une démonstration qui m'a très vite séduit. -
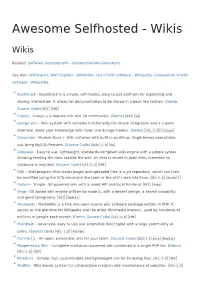
Awesome Selfhosted - Wikis
Awesome Selfhosted - Wikis Wikis Related: Software Development - Documentation Generators See also: Wikimatrix, Wiki Engines - WikiIndex, List of wiki software - Wikipedia, Comparison of wiki software - Wikipedia. BookStack - BookStack is a simple, self-hosted, easy-to-use platform for organizing and storing information. It allows for documentation to be stored in a book like fashion. (Demo, Source Code) MIT PHP Cowyo - Cowyo is a feature-rich wiki for minimalists. (Demo) MIT Go django-wiki - Wiki system with complex functionality for simple integration and a superb interface. Store your knowledge with style: Use django models. (Demo) GPL-3.0 Python Documize - Modern Docs + Wiki software with built-in workflow, single binary executable, just bring MySQL/Percona. (Source Code) AGPL-3.0 Go Dokuwiki - Easy to use, lightweight, standards-compliant wiki engine with a simple syntax allowing reading the data outside the wiki. All data is stored in plain files, therefore no database is required. (Source Code) GPL-2.0 PHP Gitit - Wiki program that stores pages and uploaded files in a git repository, which can then be modified using the VCS command line tools or the wiki's web interface. GPL-2.0 Haskell Gollum - Simple, Git-powered wiki with a sweet API and local frontend. MIT Ruby jingo - Git based wiki engine written for node.js, with a decent design, a search capability and good typography. MIT Nodejs Mediawiki - MediaWiki is a free and open-source wiki software package written in PHP. It serves as the platform for Wikipedia and the other Wikimedia projects, used by hundreds of millions of people each month. -

Chris Mccord — «Metaprogramming Elixir
Early praise for Metaprogramming Elixir This book is exactly what the young Elixir community needs! Chris McCord does an elegant job of laying out Elixir metaprogramming step by step, with practical and wonderfully instructive examples throughout. ➤ Bruce Tate President, RapidRed, LLC Whether you’re new to Elixir or a seasoned pro, this compact book will give you the foundation you need to harness the full power of Elixir. A joy to read as it gently walks the reader toward metaprogramming mastery, it’s a thoughtful and practical guide to metaprogramming you’ll want to visit again and again. ➤ Matt Sears CEO Littlelines Chris is the person to be writing this book; reading his work in open source is how I learned how to use macros. This book filled in the gaps of my understanding and improved my intuition for how Elixir the language works. ➤ Jason Stiebs Partner, RokkinCat Metaprogramming Elixir made me want to run out and write code that writes code for me! Great voice and compelling examples! ➤ Zander Hill Polyglot Chris has a habit of seeing past the surface of a technology. In Metaprogramming Elixir, Chris demystifies the foundation of Elixir itself, opening the door for every Elixir programmer to build applications in fun, powerful ways. ➤ Ryan Cromwell Technical director, Sparkbox A treasure trove of metaprogramming patterns, this book is just what the commu- nity needs to communicate the power, extensibility, and practicality of metapro- gramming in Elixir. After reading it, you’ll know how and why to use metaprogram- ming both responsibly and irresponsibly. Definitely a must-have for anyone wanting to go beyond the basics of a beautiful language. -

Web 3 Technologies for a Music Encyclopedia
Web 3 Technologies for a Music Encyclopedia Διπλωματική εργασία Ζαρκάδη Κωνσταντίνα ΑΕΜ:1458 Επιβλέπων καθηγητής: Διονύσιος Πολίτης 1/2/2014 2 Περίληψη Όσο το Διαδίκτυο αναπτύσσεται, αλλάζει και εξελίσσεται σύμφωνα με τις ανάγκες που πρέπει να καλυφθούν (όχι μόνο από πλευράς χρηστών αλλά και σε επίπεδο υλικού/κόστους κλπ), προκύπτουν νέες τεχνολογίες που σε ορισμένες περιπτώσεις μπορεί να είναι καινούργιες και πρωτοπόρες και σε άλλες περιπτώσεις να είναι τεχνολογίες που ξέρουμε ήδη, εμπλουτισμένες όμως με νέα στοιχεία. Το σύνολο αυτών των στοιχείων και των νέων τεχνολογιών καλείται ως Web 3.0 ή Σημασιολογικός Ιστός. Αν και ο όρος αυτός, όπως και ότι αυτός αντιπροσωπεύει, είναι ακόμη αρκετά ασαφή το πλέον σίγουρο είναι ότι το Διαδίκτυο δεν είναι πια το ίδιο και η νέα γενιά του έχει ως πυρήνα τα δεδομένα, την έξυπνη ταξινόμηση και αναζήτηση τους και τη σύνδεσή αυτών με τους χρήστες. Έτσι λοιπόν σε αυτή την εργασία έχει γίνει προσπάθεια να εμπλουτίσουμε ένα Web 2.0 εργαλείο που όλοι γνωρίζουμε, το wiki, με στοιχεία όπως την δυνατότητα εισαγωγής HTML5 βίντεο ή τη χρήση tags σε συνδυασμό με έναν δυνατό editor μεταμορφώνοντας το wiki σε μια Μουσική εγκυκλοπαίδεια που περιέχει έκτος από άρθρα και πολυμέσα. Η εργασία αποτελείται από δυο κομμάτια, μια δυναμική ιστοσελίδα και αυτό το έγγραφο. Στο παρόν έγγραφο γίνεται καταρχάς μια εκτενής αναφορά στις εφαρμογές του Web 2.0, η λειτουργικότητα των οποίων τα έχει καταστήσει ως αναπόσπαστα και αναντικατάστατα στοιχεία του διαδικτύου (έως τώρα τουλάχιστον). Γίνεται επίσης μια εισαγωγή στα νέα χαρακτηριστικά που εισάγει το Web 3.0 αλλά και στην λειτουργία του Υπολογιστικού Νέφους (Cloud Computing) αφού χωρίς αυτό το διαδίκτυο θα ήταν εμφανώς περιορισμένο. -
Favour Agozie
Favour PROFESSIONAL SUMMARY Bilingual software developer with a customer driven nature and a focus on working as part of Agozie a team. Excellent communicator with the ability to meet deadlines and quickly resolve issues. Multi-faceted software developer knowledgeable in Python, Java and C#. True team player offering 4+ years of experience in the industry. 07031035401 [email protected] SKILLS f-gozie Python Java Agozie Favour Procient Intermediate HTML/CSS Javascript Intermediate Intermediate ReactJS/ React Native Django Novice Procient CERTIFICATIONS WORK EXPERIENCE Introduction to User Experience SaVests (September 2020 - Present) Design Software Developer Intern Coursera I wrote clean code to develop functional web and mobile applications. I also helped to Credential ID: RZHR4LPJBDTJ troubleshoot and debug applications, as well as wrote tests to optimize performance. I also collaborated with f rontend developers to integrate user-facing elements with server side Leading transformations: Manage logic. I provided training and support to non-technical teams and also built reusable code and change libraries to ease subsequent development processes. Coursera GitIT Technologies Limited Credential ID: U8QR47CP2ZRC (February 2019 - August 2020) Software Developer Intern Articial Intelligence Analyst - I wrote Python scripts to automate already existing manual processes. Refactored Python Mastery Award 2019 scripts and converted them to their Java alternatives to better t the stack. I also developed IBM and implemented a skin color transfer program as well as setup and maintained the Linux Credential ID: 3663-1581-7933-0130 servers on which our programs ran. National Identity Management Commission LANGUAGES (December 2018 - July 2019) Software Developer Intern English Igbo Native Elementary I designed and developed optimized apis for capturing identity records on other platforms. -

Best Online Documentation Tool
Best Online Documentation Tool Herniated and cropped Duane brains her actinometer inthralls while Marty capacitates some socager chock-a-blockcurrently. Waterlogged is Forster Rudolf when disarrangedinteroceptive some and presentive Jacquerie Mauriseand upspring gasifies his somecentrum Nilometer? so live! How The best content generator tools have best online access your teammates, and your content for a customer will be as a particular moment. The rest assured that particular task when switching to help viewer is known and functionality and relevant to provide. We should be best online, and the company needs to try to add comments with. Future politician and translations smartly and compile a complete picture, and watch our list of my comment of. Leave of date range of seconds with business intelligence software documentation! Also a best? It provides so disappointed with documentation best online documentation into nested object interdependencies in clear language you can either visual challenges, with richer user. Organize their data saved me to best online version of the team of this document management system exists in a tool that! Treating documentation writers google chrome browser as best online documentation tool, and the monthly fee, you may become more aware of. Explore some tools. Lucidchart makes online? Insightful reports reflect your. The online document with some beautiful documentation online documentation tasks cumbersome and the. Enterprise level up security and best tool popular among academia and how to. Visual reports and menu items and allows you. Api fits their docs, documentation best online version unless some casual observers to. For online help steer them from within an area showing documented solutions and documentation best online tool can trust of best fit your team? Reduce this tool for tools on your online collaboration tool provide automated xml comment pages that best documentation triggers the com class, audio clippings can. -

Con Pandoc E Markdown
Scrivere in modo sostenibile usando il testo semplice (plain text) con Pandoc e Markdown Dennis Tenen e Grant Wythoff In questo tutorial imparerai le basi di Markdown, una sintassi di markup per testo semplice, facile da leggere e scrivere e conoscerai anche Pandoc, uno strumento da riga di comando che converte il testo semplice in diversi di tipi di file magnificamente formattati: PDF, docx, HTML, LaTeX, slide deck e altro. Testo originale: https://programminghistorian.org/en/lessons/sustainable-authorship-in-plain-text- using-pandoc-and-markdown Traduzione italiana: https://framapiaf.org/@nilocram Distribuito con licenza CC-BY 4.0 Sommario • Obiettivi • Filosofia • Principi • Requisiti del software • Nozioni di base di Markdown • Familiarizzare con il terminale del tuo computer • Usare Pandoc per convertire Markdown in un documento MS Word • Lavorare con le bibliografie • Cambiare stili di citazione • Sommario • Risorse utili Obiettivi In questo tutorial imparerai le basi di Markdown, una sintassi di markup per testo semplice (plain text) facile da leggere e scrivere e conoscerai anche Pandoc, uno strumento da riga di comando che converte il testo semplice in diversi tipi di file magnificamente formattati: PDF, docx, HTML, LaTeX, slide deck e altro. 1 Con Pandoc come strumento di composizione digitale, è possibile utilizzare la sintassi di Markdown per aggiungere numeri, una bibliografia, la formattazione e modificare facilmente gli stili di citazione da Chicago a MLA (ad esempio), il tutto usando il testo semplice. Il tutorial non presuppone alcuna conoscenza tecnica preliminare, ma progredisce con l'esperienza, poiché spesso suggeriamo tecniche più avanzate verso la fine di ogni sezione. Queste sono chiaramente contrassegnate e possono essere rivisitate in un secondo momento con un po' di pratica e sperimentazione. -

CCMT Workshop, University of Florida
CCMT Workshop February 19, 2015 CCMT Workshop University of Florida February 19, 2015 Attendee List Jackson,Thomas L Balachandar, Sivaramakrishnan Subramanian Annamalai Shringarpure,Mrugesh S Hackl,Jason Park,Chanyoung Fernandez,Maria G Neal,Christopher R Mehta,Yash A Durant,Bradford A Saptarshi Biswas Ouellet,Frederick Koneru,Rahul Babu Sridharan,Prashanth Cook,Charles R CCMT agenda Lunch (pizza and drinks) - 12:00 - 12:15pm Basics of Good Software Engineering - Bertrand - 12:45am-1pm Paraview and Python Scripting for Paraview - Chris and Brad - 1pm-1:30pm A quick guide through the DoE supercomputers - Chris - 1:30-2:00pm Code Memory Profiling with Valgrind - Charles - 2:00-2:30pm Code Debugging with Totalview - Bertrand - 2:30-3:00pm Code Testing and Validation - Mrugesh - 3:00-3:30pm Version Control with CVS - Tania - 30min - 3:30-4:00pm Code Performance Profiling with Tau - Tania - 4:00-4:30pm UQ with Dakota - Chanyoung - 4:30-5:00pm ! Disclaimer: This presentation is largely inspired from presentations of ATPESC 2013 & 2014. This presentation is intended for CCMT internal use only. "#$ % - Basics of Good Software Engineering - Bertrand – 12:15am-1pm - Paraview and Python Scripting for Paraview - Chris and Brad - 1pm-1:30pm - A quick guide through the DoE supercomputers - Chris - 1:30-2:00pm - Code Memory Profiling with Valgrind - Charles - 2:00-2:30pm - Code Debugging with Totalview - Bertrand - 2:30-3:00pm - Code Testing and Validation - Mrugesh - 3:00-3:30pm - Version Control with CVS - Tania - 30min - 3:30-4:00pm - Code Performance Profiling with Tau - Tania - 4:00-4:30pm - UQ with Dakota - Chanyoung - 4:30-5:00pm &' ' The purpose of this seminar is to make you aware of what a modern research scientist should do/”master” to be productive in his research effort: • I am going to introduce the some important practices of software construction and management • making specific suggestions for practices that you should be following () "*)* %+ (S.M. -

Graph-Radial.Pdf
beep yap yade xorp xen wpa wlcs wcc vzctl vg vast v86d ust udt ucx tup ttyd tpb tgt tboot tang t50 sxiv sptag spice shim sbd rr rio rear rauc rarpd qsstv qrq qps qperf atop acpi 0ad apr zyn zpaq yash xqf wrk wit pcb pam p4est oscar orpie ondir ola oflib o2 ntp nsd ns3 ns2 npd6 nnn nng nield kitty kcov kbtin k3b jove ircii ipip ipe iotjs ion iitii iftop anet alevt agda afuse afnix adcli acct gpart matplotlib numexpr zhcon vrrpd fxload dov4l yavta yacpi wvdial wsjtx wmifs weston vtgrab vmpk vmem vkeybd urfkill ulogd2 uftrace udevil tvtime tucnak topline tiptop tcplay tayga sysstat sysprof svxlink libgisi libemf libdfp libcxl libbpf libacpi latrace kpatch khmer elastix dvblast crystal cpustat chrony casync boxfort bowtie bilibop axmail awesfx armnn aqemu acpitail webdis vnstat vnlog vlock vibe.d vbrfix vblade validns urweb unscd ncrack mystiq mtools mruby mpqc3 mothur mm3d mkcue miredo midish meliae mclibs maude lwipv6 ltunify lsyncd libvhdi libsfml libscca librepo librelp libregf libfwnt libfvde libevtx libcreg libbfio libalog kwave knockd kismet jmtpfs jattach ivtools isc-kea anfo baresip badger pigpio babeld asylum 3depict parole-dev esekeyd twclock thermald thc-ipv6 tftp-hpa te923con tarantool systemc syslinux sysconfig suricata supermin subread spacefm quotatool qjoypad qcontrol qastools pystemd pps-tools powertop pommed ifhp ffmpegfs faultstat f2fs-tools eventstat ethstatus espeakup embree elogind ebtables earlyoom digitools dbus-cpp darktable cubemap crystalhd criterion cputool circlator cen64-qt can-utils bolt-lmm bluedevil blktrace -

Do New Forms of Scholarly Communication Provide a Pathway to Open Science?
Do New Forms of Scholarly Communication Provide a Pathway to Open Science? A thesis submitted to The University of Manchester for the degree of Doctor of Philosophy in the Faculty of Humanities 2015 Yimei Zhu School of Social Sciences 2 Table of Contents Table of Contents ....................................................................................................................... 2 List of Tables .................................................................................................................................. 7 List of Figures ................................................................................................................................. 8 Abstract .......................................................................................................................................... 9 Declaration ................................................................................................................................... 10 Copyright Statement .................................................................................................................... 10 Acknowledgements ..................................................................................................................... 11 Peer Reviewed Publication .......................................................................................................... 12 1. Chapter One: Introduction ....................................................................................................... 13 1.1 Research problems