1 Introduction 2 How Purify Works
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Rational Purifyplus for UNIX
Develop Fast, Reliable Code Rational PurifyPlus for UNIX Customers and end-users demand that your Automatically Pinpoint code works reliably and offers adequate execu- Hard-To-Find Bugs tion performance. But the reality of your deliv- Reliability problems, such as runtime errors and ery schedule often forces you to sacrifice relia- memory leaks in C/C++, can kill a software bility or performance – sometimes both. And company’s reputation. These errors are hard to without adequate time for testing, you may not find, hard to reproduce, and hardest of all, to even know these issues exist. So you reluctant- explain to customers who discover them. No ly deliver your code before it’s ready, knowing one intentionally relies on their customer as good and well that the integrity of your work their "final QA." But without adequate tools, this may be suspect. is the inevitable outcome. Even the best pro- Rational Software has a solution for ensuring grammers make mistakes in their coding. that your code is both fast and reliable. Rational PurifyPlus for UNIX automatically finds HIGHLIGHTS Rational® PurifyPlus for UNIX combines runtime these reliability errors in C/C++ code that can’t error detection, application performance profil- Automatically finds runtime be found in any other way. It finds the errors ing, and code coverage analysis into a single, errors in C/C++ code even before visible symptoms occur (such as a complete package. Together, these functions system crash or other spurious behavior). And help developers ensure the highest reliability Quickly isolates application it shows you exactly where the error originated, and performance of their software from the very performance bottlenecks regardless of how remote from the visible first release. -

The Developer's Guide to Debugging
The Developer’s Guide to Debugging Thorsten Grotker¨ · Ulrich Holtmann Holger Keding · Markus Wloka The Developer’s Guide to Debugging 123 Thorsten Gr¨otker Ulrich Holtmann Holger Keding Markus Wloka Internet: http://www.debugging-guide.com Email: [email protected] ISBN: 978-1-4020-5539-3 e-ISBN: 978-1-4020-5540-9 Library of Congress Control Number: 2008929566 c 2008 Springer Science+Business Media B.V. No part of this work may be reproduced, stored in a retrieval system, or transmitted in any form or by any means, electronic, mechanical, photocopying, microfilming, recording or otherwise, without written permission from the Publisher, with the exception of any material supplied specifically for the purpose of being entered and executed on a computer system, for exclusive use by the purchaser of the work. Printed on acid-free paper 987654321 springer.com Foreword Of all activities in software development, debugging is probably the one that is hated most. It is guilt-ridden because a technical failure suggests personal fail- ure; because it points the finger at us showing us that we have been wrong. It is time-consuming because we have to rethink every single assumption, every single step from requirements to implementation. Its worst feature though may be that it is unpredictable: You never know how much time it will take you to fix a bug - and whether you’ll be able to fix it at all. Ask a developer for the worst moments in life, and many of them will be related to debugging. It may be 11pm, you’re still working on it, you are just stepping through the program, and that’s when your spouse calls you and asks you when you’ll finally, finally get home, and you try to end the call as soon as possible as you’re losing grip on the carefully memorized observations and deductions. -

Heapmon: a Low Overhead, Automatic, and Programmable Memory Bug Detector ∗
Appears in the Proceedings of the First IBM PAC2 Conference HeapMon: a Low Overhead, Automatic, and Programmable Memory Bug Detector ∗ Rithin Shetty, Mazen Kharbutli, Yan Solihin Milos Prvulovic Dept. of Electrical and Computer Engineering College of Computing North Carolina State University Georgia Institute of Technology frkshetty,mmkharbu,[email protected] [email protected] Abstract memory bug detection tool, improves debugging productiv- ity by a factor of ten, and saves $7,000 in development costs Detection of memory-related bugs is a very important aspect of the per programmer per year [10]. Memory bugs are not easy software development cycle, yet there are not many reliable and ef- to find via code inspection because a memory bug may in- ficient tools available for this purpose. Most of the tools and tech- volve several different code fragments which can even be in niques available have either a high performance overhead or require different files or modules. The compiler is also of little help a high degree of human intervention. This paper presents HeapMon, in finding heap-related memory bugs because it often fails to a novel hardware/software approach to detecting memory bugs, such fully disambiguate pointers [18]. As a result, detection and as reads from uninitialized or unallocated memory locations. This new identification of memory bugs must typically be done at run- approach does not require human intervention and has only minor stor- time [1, 2, 3, 4, 6, 7, 8, 9, 11, 13, 14, 18]. Unfortunately, the age and execution time overheads. effects of a memory bug may become apparent long after the HeapMon relies on a helper thread that runs on a separate processor bug has been triggered. -

Debugging and Tuning Linux for EDA
Debugging and Tuning Linux for EDA Fabio Somenzi [email protected] University of Colorado at Boulder Outline Compiling gcc icc/ecc Debugging valgrind purify ddd Profiling gcov, gprof quantify vtl valgrind Compiling Compiler options related to static checks debugging optimization Profiling-driven optimization Compiling with GCC gcc -Wall -O3 -g reports most uses of potentially uninitialized variables -O3 (or -O6) necessary to trigger dataflow analysis can be fooled by if (cond) x = VALUE; ... if (cond) y = x; Uninitialized variables not considered for register allocation may escape Achieving -Wall-clean code is not too painful and highly desirable Compiling C code with g++ is more painful, but has its rewards Compiling with GCC gcc -mcpu=pentium4 -malign-double -mcpu=pentium4 optimizes for the Pentium 4, but produces code that runs on any x86 -march=pentium4 uses Pentium 4-specific instructions -malign-double forces alignment of double’s to double-word boundary Use either for all files or for none gcc -mfpmath=sse Controls the use of SSE instructions for floating point For complete listing, check gcc’s info page under Invoking gcc ! Submodel Options Compiling with ICC ICC is the Intel compiler for IA-32 systems. http://www.intel.com/software/products/ icc -O3 -g -ansi -w2 -Wall Aggressive optimization Retain debugging info Strict ANSI conformance Display remarks, warnings, and errors Enable all warnings Remarks tend to be a bit overwhelming Fine grain control over diagnostic: see man page Compiling with ICC icc -tpp7 Optimize instruction scheduling -

IBM Rational Purifyplus for AIX Helps Developers and Testers Deliver Applications Faster and with Fewer Errors
IBM Europe, Middle East, and Africa Software Announcement ZP09-0129, dated May 12, 2009 IBM Rational PurifyPlus for AIX helps developers and testers deliver applications faster and with fewer errors Table of contents 1 At a glance 4 Publications 1 Overview 4 Technical information 2 Key prerequisites 5 Ordering information 2 Planned availability dates 7 Terms and conditions 2 Product positioning 9 IBM Electronic Services 3 Program number 10 Prices 3 Offering Information 10 Announcement countries At a glance tm IBM® Rational® PurifyPlus for AIX® is the newest member of an award-winning family of products that provide a dynamic analysis solution designed to help developers write faster, more reliable code. It includes four basic capabilities: • Memory debugging: Pinpoints hard to find memory errors such as uninitialized memory access, buffer overflow, and improper freeing of memory. • Memory leak detection: Identifies memory blocks that no longer have a valid pointer. • Application performance profiling: Highlights application performance bottlenecks and improves application understanding with a graphical representation of function calls. • Code coverage analysis: Identifies untested code with line-level precision. Overview IBM Rational PurifyPlus for AIX is a set of dynamic analysis tools designed for improving application reliability and performance on the IBM System p® platform. The PurifyPlus software combines the following capabilities into a single, complete package: • Memory debugging • Memory leak detection • Application performance profiling • Code coverage analysis Together, these capabilities help developers and testers to realize high reliability and performance of their software from its very first release. IBM Rational PurifyPlus for AIX allows developers and testers to monitor an entire application or just a subset of an application's modules. -

Survey of Protections from Buffer-Overflow Attacks
Survey of Protections from Buffer-Overflow Attacks Krerk Piromsopa1,* and Richard J. Enbody2 1 Department of Industrial Engineering, Faculty of Engineering, Chulalongkorn University Bangkok 10330 Thailand 2 Department of Computer Science and Engineering, Michigan State University East Lansing, MI 48824-1226 USA E-mail: [email protected],* and [email protected] Abstract. Buffer-overflow attacks began two decades ago and persist today. Over that time, a number of researchers have proposed many solutions. Their targets were either to prevent or to protect against buffer-overflow attacks. As defenses improved, attacks adapted and became more complicated. Given the maturity of field and the fact that some solutions now exist that can prevent most buffer-overflow attacks, it is time to examine these schemes and their critical issues. In this survey, approaches were categorized into three board categories to provide a basis for understanding buffer- overflow protection schemes. Keywords: Buffer overflow, buffer-overflow attacks, function-pointer attacks, intrusion detection, intrusion prevention. ENGINEERING JOURNAL Volume 15 Issue 2 Received 1 June 2010 Accepted 5 February 2011 Published 1 April 2011 Online at http://www.ej.eng.chula.ac.th/eng/ DOI:10.4186/ej.2011.15.2.31 DOI:10.4186/ej.2011.15.2.31 1. Introduction Though dated back to the 1988 infamous MORRIS worm [1], buffer-overflow attacks are still widely found. In 2007, buffer overflows made up the majority of the vulnerabilities listed by CERT [2] which allowed execution of arbitrary code, i.e. the most serious vulnerabilities. Though skilled programmers should write code that does not allow buffer overflows, current practice does not guarantee programs that are free from vulnerabilities. -

FAA Software Verification Tools Assessment Study
DOT/FAA/AR-06/54 Software Verification Tools Air Traffic Organization Operations Planning Assessment Study Office of Aviation Research and Development Washington, DC 20591 June 2007 Final Report This document is available to the U.S. public through the National Technical Information Service (NTIS), Springfield, Virginia 22161. U.S. Department of Transportation Federal Aviation Administration NOTICE This document is disseminated under the sponsorship of the U.S. Department of Transportation in the interest of information exchange. The United States Government assumes no liability for the contents or use thereof. The United States Government does not endorse products or manufacturers. Trade or manufacturer's names appear herein solely because they are considered essential to the objective of this report. This document does not constitute FAA certification policy. Consult your local FAA aircraft certification office as to its use. This report is available at the Federal Aviation Administration William J. Hughes Technical Center’s Full-Text Technical Reports page: actlibrary.tc.faa.gov in Adobe Acrobat portable document format (PDF). Technical Report Documentation Page 1. Report No. 2. Government Accession No. 3. Recipient's Catalog No. DOT/FAA/AR-06/54 4. Title and Subtitle 5. Report Date SOFTWARE VERIFICATION TOOLS ASSESSMENT STUDY June 2007 6. Performing Organization Code 7. Author(s) 8. Performing Organization Report No. Viswa Santhanam, John Joseph Chilenski, Raymond Waldrop, Thomas Leavitt, and Kelly J. Hayhurst 9. Performing Organization Name and Address 10. Work Unit No. (TRAIS) NASA Langley Research Center Hampton, VA 23681-2199 11. Contract or Grant No. DTFA03-96-X-90001 NAS1-00106 task order 1008 NAS1-00079 12. -
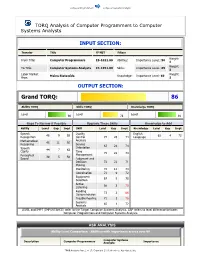
Computer Systems Analysts
Computer Programmers Computer Systems Analysts TORQ Analysis of Computer Programmers to Computer Systems Analysts INPUT SECTION: Transfer Title O*NET Filters Weight: From Title: Computer Programmers 15-1021.00 Abilities: Importance LeveL: 50 1 Weight: To Title: Computer Systems Analysts 15-1051.00 Skills: Importance LeveL: 69 1 Labor Market Weight: Maine Statewide Knowledge: Importance Level: 69 Area: 1 OUTPUT SECTION: Grand TORQ: 86 Ability TORQ Skills TORQ Knowledge TORQ Level Level Level 90 78 91 Gaps To Narrow if Possible Upgrade These Skills Knowledge to Add Ability Level Gap Impt Skill Level Gap Impt Knowledge Level Gap Impt Speech Quality English 46 9 65 62 4 72 Recognition Control 74 26 74 Language Mathematical Analysis 46 11 50 Reasoning Service 67 24 74 Speech Orientation 44 7 62 Clarity Time 75 22 74 Perceptual Management 39 5 50 Speed Judgment and Decision 72 22 71 Making Monitoring 72 12 74 Coordination 71 9 72 Equipment 67 5 70 Selection Active 68 3 79 Listening Reading 73 2 86 Comprehension Troubleshooting 71 1 76 Systems 65 1 72 Analysis LEVEL and IMPT (IMPORTANCE) refer to the Target Computer Systems Analysts. GAP refers to level difference between Computer Programmers and Computer Systems Analysts. ASK ANALYSIS Ability Level Comparison - Abilities with importance scores over 50 Computer Systems Description Computer Programmers Analysts Importance TORQ Analysis Page 1 of 17. Copyright 2009. Workforce Associates, Inc. Computer Programmers Computer Systems Analysts Oral Comprehension 66 57 75 Problem Sensitivity 51 51 75 -

The Parallel Programming Landscape
THE STATE OF Parallel Programming The Parallel Programming Landscape Multicore has gone mainstream — but are developers ready? An Exclusive Research Report arallel computing is the primary way that processor The proliferation of multicore processors means manufacturers are dealing with the physical limits that software developers must incorporate P of transistor-based processor technology. Multiple parallelism into their programming in order processors — or cores — are joined together on a single inte- to achieve increased application performance. grated circuit to provide increased performance and better But many programmers are ill-equipped for energy efficiency than using a single processor. Multicore parallel programming, lacking the requisite technology is now standard in desktop and laptop computers. training and often relying on primitive devel- Mobile computing devices like smartphones and tablets are opment tools. The research shows that better also incorporating multicore processors into their designs. and simpler tools and libraries are needed to The problem with multicore computing is that help programmers parallelize their code and software applications no longer automatically benefit from to debug the complex concurrency bugs that improvements in processor performance the way they did parallelism exposes. in the past. Those benefits can only be realized by writing applications that expect and take advantage of parallelism. Sponsored by The State of Parallel Programming In 2006, Saman Amarasinghe, now a computer science Figure 2. How important is parallel programming to your work? professor at MIT, described this as a “looming software Not sure 1 crisis” for software developers who write code on platforms Critical – our software would not Not important – our 8% that abstract away processor architecture and who therefore software would not work without parallelism benefit from parallelism don’t know how to benefit from parallelism. -

Program Analysis with Valgrind
Memory Analysis tools PURIFYThe Necessity TOOL • Application behaviour: – Crashes intermittently – Uses too much memory – Runs too slowly – Isn’t well tested – Is about to ship • You need something – See what your code is really doing – Help spend less time finding bugs – Develop fast, reliable code Type of Memory Errors • ABR/ABW – Array bounds read/write • FMR/FMW – Freed memory read/write • UMR – Uninitialized memory read • MSE – Memory Segment Error • MLK – Memory Leak • NPR/NRW – Null Pointer Read • FMM – Freeing Mismatched Memory Software Quality Management • IBM-Rational Products: – A set of runtime analysis tools – Increase code quality • Purify – Detecting Runtime Errors – Automatically pinpoints hard-to-find bugs – Profiling .NET Managed Code (Memory Profiling) • Quantify – Application profiler – Highlights performance bottlenecks • PureCoverage – Source code coverage analysis – Helps avoid shipping untested code Features and benefits • Who can use it? – For everybody – Unix, Windows, C, C++, Java, .NET – Developers and testers • Source Code required? – Monitors components with no source code • Interesting Features: – Rich command line interface and batch mode for automation – Integrations with Rational Robot, Rational ClearQuest, Rational ClearCase, and Microsoft Visual Studio.NET Current Version: PurifyPlus What about static analysis tools • Static analysis tools are a great complement to Purify – Find errors that you don’t exercise in test cases – Find richer semantic errors, e.g. type safety – Find potential errors if calling -

Valgrind for OSE
Valgrind for OSE Lifei Tang 8/18/2012 Supervisor: Moris Behnam Supervisor: Mathias Engan Examiner: Thomas Nolte Supervisor: Daniel Forsgren Abstract For programmers, it is always painful and hard to identify non-fatal errors like memory leaks, out of boundary errors or data race condition with traditional debug tools e.g. GDB. Today, there are many tools available to help the programmers to find these problems. The collection of Valgrind tools is a good example. Valgrind itself is an open source framework for debugging and profiling. It is today available for Linux, Darwin and Android, on hardware platforms such as ARM, x86 and PPC. Valgrind virtualizes the user mode environment and depends on the host OS environment. This thesis explores how Valgrind could be adapted to support an OSE (a real-time operation system product from ENEA software AB) target in a Linux host environment. 1 | P a g e Acknowledgement I would like to thank many people, without their support this work would not have been possible. I am really grateful to my supervisor at ENEA Software AB, Mathias Engan, who offers tons of help for solving all kinds of issues from the technical problem to my the daily company life; and Daniel Forsgren, my special technical advisor at ENEA, who kindly and patiently helps me to harming the technical problems on a weekly basis and provide me lots of valuable ideas, without his helps, I won’t even know how to start the whole thing. I’d like to thank Dr. Moris Behnam and Prof. Thomas Nolte, my thesis supervisor and examiner at Mälardalen University, who provide me constructive advices on my thesis. -

Testing J2EE Applications with Rational Purifyplus
TP612 Testing J2EE Applications with IBM Rational PurifyPlus Goran Begik Table of Contents Introduction.............................................................................................................................................. 1 About Jakarta Tomcat.............................................................................................................................. 1 About IBM Rational PurifyPlus .............................................................................................................. 1 About Servlets and JavaServerPages ....................................................................................................... 1 Preparing Java Servlets and JavaServerPages for Testing with Rational PurifyPlus............................ 2 Preparing the Windows Environment for Testing JavaServerPages and Java Servlets with Rational PurifyPlus. ........................................................................................................................................... 2 Preparing the Java Application Server Environment for Running with Rational PurifyPlus............... 3 Preparing PurifyPlus for Collecting Data from Java Applications Running in Apache Tomcat ......... 3 The Demo Application............................................................................................................................. 6 Run-Time Testing of Java Servlets and JavaServerPages in Rational PurifyPlus ................................... 6 Profiling Application Execution Times with Rational Quantify.............................................................