Password Cracking Using Probabilistic Context-Free Grammars
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

GPU-Based Password Cracking on the Security of Password Hashing Schemes Regarding Advances in Graphics Processing Units
Radboud University Nijmegen Faculty of Science Kerckhoffs Institute Master of Science Thesis GPU-based Password Cracking On the Security of Password Hashing Schemes regarding Advances in Graphics Processing Units by Martijn Sprengers [email protected] Supervisors: Dr. L. Batina (Radboud University Nijmegen) Ir. S. Hegt (KPMG IT Advisory) Ir. P. Ceelen (KPMG IT Advisory) Thesis number: 646 Final Version Abstract Since users rely on passwords to authenticate themselves to computer systems, ad- versaries attempt to recover those passwords. To prevent such a recovery, various password hashing schemes can be used to store passwords securely. However, recent advances in the graphics processing unit (GPU) hardware challenge the way we have to look at secure password storage. GPU's have proven to be suitable for crypto- graphic operations and provide a significant speedup in performance compared to traditional central processing units (CPU's). This research focuses on the security requirements and properties of prevalent pass- word hashing schemes. Moreover, we present a proof of concept that launches an exhaustive search attack on the MD5-crypt password hashing scheme using modern GPU's. We show that it is possible to achieve a performance of 880 000 hashes per second, using different optimization techniques. Therefore our implementation, executed on a typical GPU, is more than 30 times faster than equally priced CPU hardware. With this performance increase, `complex' passwords with a length of 8 characters are now becoming feasible to crack. In addition, we show that between 50% and 80% of the passwords in a leaked database could be recovered within 2 months of computation time on one Nvidia GeForce 295 GTX. -

Intro to Cryptography 1 Introduction 2 Secure Password Manager
Programming Assignment 1 Winter 2021 CS 255: Intro to Cryptography Prof. Dan Boneh Due Monday, Feb. 8, 11:59pm 1 Introduction In many software systems today, the primary weakness often lies in the user’s password. This is especially apparent in light of recent security breaches that have highlighted some of the weak passwords people commonly use (e.g., 123456 or password). It is very important, then, that users choose strong passwords (or “passphrases”) to secure their accounts, but strong passwords can be long and unwieldy. Even more problematic, the user generally has many different services that use password authentication, and as a result, the user has to recall many different passwords. One way for users to address this problem is to use a password manager, such as LastPass and KeePass. Password managers make it very convenient for users to use a unique, strong password for each service that requires password authentication. However, given the sensitivity of the data contained in the password manager, it takes considerable care to store the information securely. In this assignment, you will be writing a secure and efficient password manager. In your implemen- tation, you will make use of various cryptographic primitives we have discussed in class—notably, authenticated encryption and collision-resistant hash functions. Because it is ill-advised to imple- ment your own primitives in cryptography, you should use an established library: in this case, the Stanford Javascript Crypto Library (SJCL). We will provide starter code that contains a basic tem- plate, which you will be able to fill in to satisfy the functionality and security properties described below. -

Truecrack Bruteforcing Per Volumi Truecrypt
Luca Vaccaro http://code.google.com/p/truecrack/ [email protected] User development guide. TrueCrypt © . software application used for on-the-fly encryption (OTFE). TrueCrack . bruteforce password cracker for TrueCrypt © (Copyrigth) volume files, optimazed with Nvidia Cuda technology. This software is Based on TrueCrypt, freely available athttp://www.truecrypt.org/ Master key . Crypt the volume of data. Generated one time in the volume creation phase from random value. Write inside the header section of the volume file. Header key . Crypt the header section of the volume file. Generated from a user password and a random salt (64 bytes). The salt is write in plain text in the first 64 bytes of volume file. Hard disk encryption: . Standard block cipher: XTS . Hash availables: AES, Serpent, Twofish . Default: AES Key derivation function: . Standard algorithm: PBKDF2 . Hash availables: RIPEMD160, SHA-512, Whirpool . Default: RIPEMD160 Master Header Key Key Plain Cipher Volume data data + file header Opening a TrueCrypt volume means to retrieve the Master Key from the Header section In the Header there are some fields (true, crc32) for checking the success of the decipher operation . If the password is right or wrong Header key User password salt Volume Master file key CUDA or Compute Unified Device Architecture is a parallel computing architecture developed by Nvidia. CUDA gives developers access to the virtual instruction set and memory of the parallel computational elements in CUDA GPUs. Each GPU is a collection of multicores. Each core can run mmore cuda «block», and each block can run a numbers of parallel «thread» 1. Level of parallilism : block 2. -

Study on Massive-Scale Slow-Hash Recovery Using Unified
S S symmetry Article Study on Massive-Scale Slow-Hash Recovery Using Unified Probabilistic Context-Free Grammar and Symmetrical Collaborative Prioritization with Parallel Machines Tianjun Wu 1,*,†, Yuexiang Yang 1,†, Chi Wang 2,† and Rui Wang 2,† 1 College of Computer, National University of Defense Technology, Changsha 410073, China; [email protected] 2 VeriClouds Co., Seattle, WA 98105, USA; [email protected] (C.W.); [email protected] (R.W.) * Correspondence: [email protected]; Tel.: +86-13-54-864-2846 † The authors contribute equally to this work and are co-first authors. Received: 23 February 2019; Accepted: 26 March 2019; Published: 1 April 2019 Abstract: Slow-hash algorithms are proposed to defend against traditional offline password recovery by making the hash function very slow to compute. In this paper, we study the problem of slow-hash recovery on a large scale. We attack the problem by proposing a novel concurrent model that guesses the target password hash by leveraging known passwords from a largest-ever password corpus. Previously proposed password-reused learning models are specifically designed for targeted online guessing for a single hash and thus cannot be efficiently parallelized for massive-scale offline recovery, which is demanded by modern hash-cracking tasks. In particular, because the size of a probabilistic context-free grammar (PCFG for short) model is non-trivial and keeping track of the next most probable password to guess across all global accounts is difficult, we choose clever data structures and only expand transformations as needed to make the attack computationally tractable. Our adoption of max-min heap, which globally ranks weak accounts for both expanding and guessing according to unified PCFGs and allows for concurrent global ranking, significantly increases the hashes can be recovered within limited time. -

Analysis of Password Cracking Methods & Applications
The University of Akron IdeaExchange@UAkron The Dr. Gary B. and Pamela S. Williams Honors Honors Research Projects College Spring 2015 Analysis of Password Cracking Methods & Applications John A. Chester The University Of Akron, [email protected] Please take a moment to share how this work helps you through this survey. Your feedback will be important as we plan further development of our repository. Follow this and additional works at: http://ideaexchange.uakron.edu/honors_research_projects Part of the Information Security Commons Recommended Citation Chester, John A., "Analysis of Password Cracking Methods & Applications" (2015). Honors Research Projects. 7. http://ideaexchange.uakron.edu/honors_research_projects/7 This Honors Research Project is brought to you for free and open access by The Dr. Gary B. and Pamela S. Williams Honors College at IdeaExchange@UAkron, the institutional repository of The nivU ersity of Akron in Akron, Ohio, USA. It has been accepted for inclusion in Honors Research Projects by an authorized administrator of IdeaExchange@UAkron. For more information, please contact [email protected], [email protected]. Analysis of Password Cracking Methods & Applications John A. Chester The University of Akron Abstract -- This project examines the nature of password cracking and modern applications. Several applications for different platforms are studied. Different methods of cracking are explained, including dictionary attack, brute force, and rainbow tables. Password cracking across different mediums is examined. Hashing and how it affects password cracking is discussed. An implementation of two hash-based password cracking algorithms is developed, along with experimental results of their efficiency. I. Introduction Password cracking is the process of either guessing or recovering a password from stored locations or from a data transmission system [1]. -

Password Cracking Using Cain & Abel
Password Cracking Using Cain & Abel Learning Objectives: This exercise demonstrates how password could be cracked through various methods, specifically regarding MD5 encrypted passwords. Summary: You will use Cain & Abel for this exercise. Deliverables: Submit a lab report by answering the review questions. In some review questions, you may provide screen captures. Dictionary attack Dictionary attack uses a predetermined list of words from a dictionary to generate possible passwords that may match the MD5 encrypted password. This is one of the easiest and quickest way to obtain any given password. 1. Start Cain & Abel via the Desktop Shortcut ‘Cain’ or Start menu. a. (Start > Programs > Cain > Cain). 2. Choose ‘Yes’ to proceed when a ‘User Account Control’ notification pops up regarding software authorization. 3. Once on, select the ‘Cracker’ tab with the key symbol, then click on MD5 Hashes. The result should look like the image below. 1 Collaborative Virtual Computer Lab (CVCLAB) Penn State Berks 4. As you might have noticed we don’t have any passwords to crack, thus for the next few steps we will create our own MD5 encrypted passwords. First, locate the Hash Calculator among a row of icons near the top. Open it. 5. Next, type into ‘Text to Hash’ the word password. It will generate a list of hashes pertaining to different types of hash algorithms. We will be focusing on MD5 hash so copy it. Then exit calculator by clicking ‘Cancel’ (Fun Fact: Hashes are case sensitive so any slight changes to the text will change the hashes generated, try changing a letter or two and you will see. -

User Authentication and Cryptographic Primitives
User Authentication and Cryptographic Primitives Brad Karp UCL Computer Science CS GZ03 / M030 16th November 2016 Outline • Authenticating users – Local users: hashed passwords – Remote users: s/key – Unexpected covert channel: the Tenex password- guessing attack • Symmetric-key-cryptography • Public-key cryptography usage model • RSA algorithm for public-key cryptography – Number theory background – Algorithm definition 2 Dictionary Attack on Hashed Password Databases • Suppose hacker obtains copy of password file (until recently, world-readable on UNIX) • Compute H(x) for 50K common words • String compare resulting hashed words against passwords in file • Learn all users’ passwords that are common English words after only 50K computations of H(x)! • Same hashed dictionary works on all password files in world! 3 Salted Password Hashes • Generate a random string of bytes, r • For user password x, store [H(r,x), r] in password file • Result: same password produces different result on every machine – So must see password file before can hash dictionary – …and single hashed dictionary won’t work for multiple hosts • Modern UNIX: password hashes salted; hashed password database readable only by root 4 Salted Password Hashes • Generate a random string of bytes, r Dictionary• For user password attack still x, store possible [H(r,x after), r] in attacker seespassword password file file! Users• Result: should same pick password passwords produces that different aren’t result close to ondictionary every machine words. – So must see password file -

To Change Your Ud Password(S)
TO CHANGE YOUR UD PASSWORD(S) The MyCampus portal allows the user a single-signon for campus applications. IMPORTANT NOTICE AT BOTTOM OF THESE INSTRUCTIONS !! INITIAL PROCEDURE TO ALLOW YOU TO CHANGE YOUR PASSWORD ON THE UD NETWORK : 1. In your web browser, enter http://mycampus.dbq.edu . If you are logging in for the first time, you will be directed to answer (3) security questions. Also, be sure to answer one of the recovery methods. 2. Once the questions are answered, you will click on SUBMIT and then CONTINUE and then YES. 3. In one location, you will now find MyUD, Campus Portal, Email and UDOnline (Moodle). 4. You can now click on any of these apps and you will be logged in already. The email link will prompt you for the password a second time until we get all accounts set up properly. YOU MUST BE SURE TO LOGOUT OF EACH APPLICATION AFTER YOU’RE DONE USING IT !! TO CHANGE YOUR PASSWORD: 1. After you have logged into the MyCampus.dbq.edu website, you will see your username in the upper- right corner of the screen. 2. Click on your name and then go into My Account. 3. At the bottom, you will click on Change Password and then proceed as directed. 4. You can now logout. You will need to use your new password on your next login. Password must be a minimum of 6 characters and contain 3 of the following 4 categories: - Uppercase character - Lowercase character - Number - Special character You cannot use the previous password You’ll be required to change your password every 180 days. -
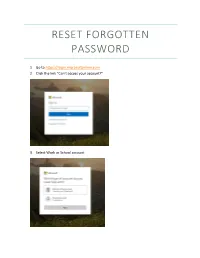
Reset Forgotten Password with Office365
RESET FORGOTTEN PASSWORD 1. Go to https://login.microsoftonline.com 2. Click the link “Can’t access your account?” 3. Select Work or School account 4. Enter in your User ID with the @uamont.edu at the end and then enter the characters as seen in the picture. You can click the refresh button for a different set of letters. 5. You will have 3 options to verify your account and reset your password. This information was set up when you registered with self-service password reset. If you have not registered, please go to https://aka.ms/ssprsetup and enter in your information. A step by step guide on how to do this can be found here. a. Text your mobile phone b. Call your mobile phone c. Answer Security Questions 6. Choose one option and enter the information requested 7. Click Text for text my mobile phone, Call for call my mobile phone, or click Next when you’ve answered all security questions. a. If you have selected Text my mobile phone you will be required to enter in a verification code and click Next b. If you have select Call my mobile phone you will receive a call and will need to enter # to verify. 8. Enter in your new password and click Finish a. Note: If you receive the message, “Unfortunately, your password contains a word, phrase, or pattern that makes it easily guessable. Please try again with a different password.” Please try to create a password that does not use any dictionary words. b. Passwords must meet 3 of the 4 following requirements i. -

Implementation and Performance Analysis of PBKDF2, Bcrypt, Scrypt Algorithms
Implementation and Performance Analysis of PBKDF2, Bcrypt, Scrypt Algorithms Levent Ertaul, Manpreet Kaur, Venkata Arun Kumar R Gudise CSU East Bay, Hayward, CA, USA. [email protected], [email protected], [email protected] Abstract- With the increase in mobile wireless or data lookup. Whereas, Cryptographic hash functions are technologies, security breaches are also increasing. It has used for building blocks for HMACs which provides become critical to safeguard our sensitive information message authentication. They ensure integrity of the data from the wrongdoers. So, having strong password is that is transmitted. Collision free hash function is the one pivotal. As almost every website needs you to login and which can never have same hashes of different output. If a create a password, it’s tempting to use same password and b are inputs such that H (a) =H (b), and a ≠ b. for numerous websites like banks, shopping and social User chosen passwords shall not be used directly as networking websites. This way we are making our cryptographic keys as they have low entropy and information easily accessible to hackers. Hence, we need randomness properties [2].Password is the secret value from a strong application for password security and which the cryptographic key can be generated. Figure 1 management. In this paper, we are going to compare the shows the statics of increasing cybercrime every year. Hence performance of 3 key derivation algorithms, namely, there is a need for strong key generation algorithms which PBKDF2 (Password Based Key Derivation Function), can generate the keys which are nearly impossible for the Bcrypt and Scrypt. -

Hash Crack: Password Cracking Manual
Hash Crack. Copyright © 2017 Netmux LLC All rights reserved. Without limiting the rights under the copyright reserved above, no part of this publication may be reproduced, stored in, or introduced into a retrieval system, or transmitted in any form or by any means (electronic, mechanical, photocopying, recording, or otherwise) without prior written permission. ISBN-10: 1975924584 ISBN-13: 978-1975924584 Netmux and the Netmux logo are registered trademarks of Netmux, LLC. Other product and company names mentioned herein may be the trademarks of their respective owners. Rather than use a trademark symbol with every occurrence of a trademarked name, we are using the names only in an editorial fashion and to the benefit of the trademark owner, with no intention of infringement of the trademark. The information in this book is distributed on an “As Is” basis, without warranty. While every precaution has been taken in the preparation of this work, neither the author nor Netmux LLC, shall have any liability to any person or entity with respect to any loss or damage caused or alleged to be caused directly or indirectly by the information contained in it. While every effort has been made to ensure the accuracy and legitimacy of the references, referrals, and links (collectively “Links”) presented in this book/ebook, Netmux is not responsible or liable for broken Links or missing or fallacious information at the Links. Any Links in this book to a specific product, process, website, or service do not constitute or imply an endorsement by Netmux of same, or its producer or provider. The views and opinions contained at any Links do not necessarily express or reflect those of Netmux. -

Optimizing a Password Hashing Function with Hardware-Accelerated Symmetric Encryption
S S symmetry Article Optimizing a Password Hashing Function with Hardware-Accelerated Symmetric Encryption Rafael Álvarez 1,* , Alicia Andrade 2 and Antonio Zamora 3 1 Departamento de Ciencia de la Computación e Inteligencia Artificial (DCCIA), Universidad de Alicante, 03690 Alicante, Spain 2 Fac. Ingeniería, Ciencias Físicas y Matemática, Universidad Central, Quito 170129, Ecuador; [email protected] 3 Departamento de Ciencia de la Computación e Inteligencia Artificial (DCCIA), Universidad de Alicante, 03690 Alicante, Spain; [email protected] * Correspondence: [email protected] Received: 2 November 2018; Accepted: 22 November 2018; Published: 3 December 2018 Abstract: Password-based key derivation functions (PBKDFs) are commonly used to transform user passwords into keys for symmetric encryption, as well as for user authentication, password hashing, and preventing attacks based on custom hardware. We propose two optimized alternatives that enhance the performance of a previously published PBKDF. This design is based on (1) employing a symmetric cipher, the Advanced Encryption Standard (AES), as a pseudo-random generator and (2) taking advantage of the support for the hardware acceleration for AES that is available on many common platforms in order to mitigate common attacks to password-based user authentication systems. We also analyze their security characteristics, establishing that they are equivalent to the security of the core primitive (AES), and we compare their performance with well-known PBKDF algorithms, such as Scrypt and Argon2, with favorable results. Keywords: symmetric; encryption; password; hash; cryptography; PBKDF 1. Introduction Key derivation functions are employed to obtain one or more keys from a master secret. This is especially useful in the case of user passwords, which can be of arbitrary length and are unsuitable to be used directly as fixed-size cipher keys, so, there must be a process for converting passwords into secret keys.