Osiris: Automated Discovery of Microarchitectural Side Channels
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Intel® IA-64 Architecture Software Developer's Manual
Intel® IA-64 Architecture Software Developer’s Manual Volume 1: IA-64 Application Architecture Revision 1.1 July 2000 Document Number: 245317-002 THIS DOCUMENT IS PROVIDED “AS IS” WITH NO WARRANTIES WHATSOEVER, INCLUDING ANY WARRANTY OF MERCHANTABILITY, NONINFRINGEMENT, FITNESS FOR ANY PARTICULAR PURPOSE, OR ANY WARRANTY OTHERWISE ARISING OUT OF ANY PROPOSAL, SPECIFICATION OR SAMPLE. Information in this document is provided in connection with Intel products. No license, express or implied, by estoppel or otherwise, to any intellectual property rights is granted by this document. Except as provided in Intel's Terms and Conditions of Sale for such products, Intel assumes no liability whatsoever, and Intel disclaims any express or implied warranty, relating to sale and/or use of Intel products including liability or warranties relating to fitness for a particular purpose, merchantability, or infringement of any patent, copyright or other intellectual property right. Intel products are not intended for use in medical, life saving, or life sustaining applications. Intel may make changes to specifications and product descriptions at any time, without notice. Designers must not rely on the absence or characteristics of any features or instructions marked "reserved" or "undefined." Intel reserves these for future definition and shall have no responsibility whatsoever for conflicts or incompatibilities arising from future changes to them. Intel® IA-64 processors may contain design defects or errors known as errata which may cause the product to deviate from published specifications. Current characterized errata are available on request. Copies of documents which have an order number and are referenced in this document, or other Intel literature, may be obtained by calling 1-800- 548-4725, or by visiting Intel’s website at http://developer.intel.com/design/litcentr. -

SIMD Extensions
SIMD Extensions PDF generated using the open source mwlib toolkit. See http://code.pediapress.com/ for more information. PDF generated at: Sat, 12 May 2012 17:14:46 UTC Contents Articles SIMD 1 MMX (instruction set) 6 3DNow! 8 Streaming SIMD Extensions 12 SSE2 16 SSE3 18 SSSE3 20 SSE4 22 SSE5 26 Advanced Vector Extensions 28 CVT16 instruction set 31 XOP instruction set 31 References Article Sources and Contributors 33 Image Sources, Licenses and Contributors 34 Article Licenses License 35 SIMD 1 SIMD Single instruction Multiple instruction Single data SISD MISD Multiple data SIMD MIMD Single instruction, multiple data (SIMD), is a class of parallel computers in Flynn's taxonomy. It describes computers with multiple processing elements that perform the same operation on multiple data simultaneously. Thus, such machines exploit data level parallelism. History The first use of SIMD instructions was in vector supercomputers of the early 1970s such as the CDC Star-100 and the Texas Instruments ASC, which could operate on a vector of data with a single instruction. Vector processing was especially popularized by Cray in the 1970s and 1980s. Vector-processing architectures are now considered separate from SIMD machines, based on the fact that vector machines processed the vectors one word at a time through pipelined processors (though still based on a single instruction), whereas modern SIMD machines process all elements of the vector simultaneously.[1] The first era of modern SIMD machines was characterized by massively parallel processing-style supercomputers such as the Thinking Machines CM-1 and CM-2. These machines had many limited-functionality processors that would work in parallel. -

The Microarchitecture of the Pentium 4 Processor
The Microarchitecture of the Pentium 4 Processor Glenn Hinton, Desktop Platforms Group, Intel Corp. Dave Sager, Desktop Platforms Group, Intel Corp. Mike Upton, Desktop Platforms Group, Intel Corp. Darrell Boggs, Desktop Platforms Group, Intel Corp. Doug Carmean, Desktop Platforms Group, Intel Corp. Alan Kyker, Desktop Platforms Group, Intel Corp. Patrice Roussel, Desktop Platforms Group, Intel Corp. Index words: Pentium® 4 processor, NetBurst™ microarchitecture, Trace Cache, double-pumped ALU, deep pipelining provides an in-depth examination of the features and ABSTRACT functions of the Intel NetBurst microarchitecture. This paper describes the Intel® NetBurst™ ® The Pentium 4 processor is designed to deliver microarchitecture of Intel’s new flagship Pentium 4 performance across applications where end users can truly processor. This microarchitecture is the basis of a new appreciate and experience its performance. For example, family of processors from Intel starting with the Pentium it allows a much better user experience in areas such as 4 processor. The Pentium 4 processor provides a Internet audio and streaming video, image processing, substantial performance gain for many key application video content creation, speech recognition, 3D areas where the end user can truly appreciate the applications and games, multi-media, and multi-tasking difference. user environments. The Pentium 4 processor enables real- In this paper we describe the main features and functions time MPEG2 video encoding and near real-time MPEG4 of the NetBurst microarchitecture. We present the front- encoding, allowing efficient video editing and video end of the machine, including its new form of instruction conferencing. It delivers world-class performance on 3D cache called the Execution Trace Cache. -

6Th Gen Intel® Core™ Processors
6th Generation Intel® Processor Family Specification Update Supporting the Intel® Pentium® Processor Family based on the U-Processor Supporting the 6th Generation Intel® Core™ Processor Family based on the Y-Processor September 2015 Version 1.0 Order Number: 332994-001EN Preface You may not use or facilitate the use of this document in connection with any infringement or other legal analysis concerning Intel products described herein. You agree to grant Intel a non-exclusive, royalty-free license to any patent claim thereafter drafted which includes subject matter disclosed herein. No license (express or implied, by estoppel or otherwise) to any intellectual property rights is granted by this document. Intel technologies’ features and benefits depend on system configuration and may require enabled hardware, software or service activation. Performance varies depending on system configuration. No computer system can be absolutely secure. Check with your system manufacturer or retailer or learn more at intel.com. Intel technologies may require enabled hardware, specific software, or services activation. Check with your system manufacturer or retailer. The products described may contain design defects or errors known as errata which may cause the product to deviate from published specifications. Current characterized errata are available on request. Intel disclaims all express and implied warranties, including without limitation, the implied warranties of merchantability, fitness for a particular purpose, and non-infringement, as well as any warranty arising from course of performance, course of dealing, or usage in trade. All information provided here is subject to change without notice. Contact your Intel representative to obtain the latest Intel product specifications and roadmaps Copies of documents which have an order number and are referenced in this document may be obtained by calling 1-800-548-4725 or visit www.intel.com/design/literature.htm. -

Floating-Point on X86-64
Floating-Point on x86-64 Sixteen registers: %xmm0 through %xmm15 • float or double arguments in %xmm0 – %xmm7 • float or double result in %xmm0 • %xmm8 – %xmm15 are temporaries (caller-saved) Two operand sizes: • single-precision = 32 bits = float • double-precision = 64 bits = double ��� Arithmetic Instructions addsx source, dest subsx source, dest mulsx source, dest divsx source, dest x is either s or d Add doubles addsd %xmm0, %xmm1 Multiply floats mulss %xmm0, %xmm1 3 Conversion cvtsx2sx source, dest cvttsx2sx source, dest x is either s, d, or i With i, add an extra extension for l or q Convert a long to a double cvtsi2sdq %rdi, %xmm0 Convert a float to a int cvttss2sil %xmm0, %eax 4 Example Floating-Point Compilation double scale(double a, int b) { return b * a; } cvtsi2sdl %edi, %xmm1 mulsd %xmm1, %xmm0 ret 5 SIMD Instructions addpx source, dest subpx source, dest mulpx source, dest divpx source, dest Combine pairs of doubles or floats ... because registers are actually 128 bits wide Add two pairs of doubles addpd %xmm0, %xmm1 Multiply four pairs of floats mulps %xmm0, %xmm1 6 Auto-Vectorization void mult_all(double a[4], double b[4]) { a[0] = a[0] * b[0]; a[1] = a[1] * b[1]; a[2] = a[2] * b[2]; a[3] = a[3] * b[3]; } • What if a and b are alises? • What if a or b is not 16-byte aligned? ��� Auto-Vectorization void mult_all(double * __restrict__ ai, double * __restrict__ bi) { double *a = __builtin_assume_aligned(ai, 16); double *b = __builtin_assume_aligned(bi, 16); a[0] = a[0] * b[0]; a[1] = a[1] * b[1]; a[2] = a[2] * b[2]; a[3] = a[3] * b[3]; } movapd 16(%rdi), %xmm0 movapd (%rdi), %xmm1 mulpd 16(%rsi), %xmm0 -O3 mulpd (%rsi), %xmm1 movapd %xmm0, 16(%rdi) gcc movapd %xmm1, (%rdi) ret ���� History: Floating-Point Support in x86 8086 • No foating-point hardware • Software can implement IEEE arithmatic by manipulating bits, but that’s slow 8087 (a.k.a. -

Floating Point Peak Performance? © Markus Püschel Computer Science Floating Point Peak Performance?
How to Write Fast Numerical Code Spring 2012 Lecture 3 Instructor: Markus Püschel TA: Georg Ofenbeck © Markus Püschel Computer Science Technicalities Research project: Let me know . if you know with whom you will work . if you have already a project idea . current status: on the web . Deadline: March 7th Finding partner: [email protected] . Recipients: TA Georg + all students that have no partner yet Email for questions: [email protected] . use for all technical questions . received by me and the TAs = ensures timely answer © Markus Püschel Computer Science Last Time Asymptotic analysis versus cost analysis /* Multiply n x n matrices a and b */ void mmm(double *a, double *b, double *c, int n) { int i, j, k; for (i = 0; i < n; i++) for (j = 0; j < n; j++) for (k = 0; k < n; k++) c[i*n+j] += a[i*n + k]*b[k*n + j]; } Asymptotic runtime: O(n3) Cost: (adds, mults) = (n3, n3) Cost: flops = 2n3 Cost analysis enables performance plots © Markus Püschel Computer Science Today Architecture/Microarchitecture Crucial microarchitectural parameters Peak performance © Markus Püschel Computer Science Definitions Architecture: (also instruction set architecture = ISA) The parts of a processor design that one needs to understand to write assembly code. Examples: instruction set specification, registers Counterexamples: cache sizes and core frequency Example ISAs . x86 . ia . MIPS . POWER . SPARC . ARM © Markus Püschel MMX: Computer Science Multimedia extension SSE: Intel x86 Processors Streaming SIMD extension x86-16 8086 AVX: Advanced vector extensions 286 x86-32 386 486 Pentium MMX Pentium MMX SSE Pentium III time SSE2 Pentium 4 SSE3 Pentium 4E x86-64 / em64t Pentium 4F Core 2 Duo SSE4 Penryn Core i7 (Nehalem) AVX Sandybridge © Markus Püschel Computer Science ISA SIMD (Single Instruction Multiple Data) Vector Extensions What is it? . -

Intel® Architecture Instruction Set Extensions and Future Features
Intel® Architecture Instruction Set Extensions and Future Features Programming Reference May 2021 319433-044 Intel technologies may require enabled hardware, software or service activation. No product or component can be absolutely secure. Your costs and results may vary. You may not use or facilitate the use of this document in connection with any infringement or other legal analysis concerning Intel products described herein. You agree to grant Intel a non-exclusive, royalty-free license to any patent claim thereafter drafted which includes subject matter disclosed herein. No license (express or implied, by estoppel or otherwise) to any intellectual property rights is granted by this document. All product plans and roadmaps are subject to change without notice. The products described may contain design defects or errors known as errata which may cause the product to deviate from published specifications. Current characterized errata are available on request. Intel disclaims all express and implied warranties, including without limitation, the implied warranties of merchantability, fitness for a particular purpose, and non-infringement, as well as any warranty arising from course of performance, course of dealing, or usage in trade. Code names are used by Intel to identify products, technologies, or services that are in development and not publicly available. These are not “commercial” names and not intended to function as trademarks. Copies of documents which have an order number and are referenced in this document, or other Intel literature, may be ob- tained by calling 1-800-548-4725, or by visiting http://www.intel.com/design/literature.htm. Copyright © 2021, Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. -

Intel Architecture Software Developer's Manual
Intel Architecture Software Developer’s Manual Volume 2: Instruction Set Reference NOTE: The Intel Architecture Software Developer’s Manual consists of three volumes: Basic Architecture, Order Number 243190; Instruction Set Reference, Order Number 243191; and the System Programming Guide, Order Number 243192. Please refer to all three volumes when evaluating your design needs. 1999 Information in this document is provided in connection with Intel products. No license, express or implied, by estoppel or otherwise, to any intellectual property rights is granted by this document. Except as provided in Intel's Terms and Conditions of Sale for such products, Intel assumes no liability whatsoever, and Intel disclaims any express or implied warranty, relating to sale and/or use of Intel products including liability or warranties relating to fitness for a particular purpose, merchantability, or infringement of any patent, copyright or other intellectual property right. Intel products are not intended for use in medical, life saving, or life sustaining applications. Intel may make changes to specifications and product descriptions at any time, without notice. Designers must not rely on the absence or characteristics of any features or instructions marked “reserved” or “undefined.” Intel reserves these for future definition and shall have no responsibility whatsoever for conflicts or incompatibilities arising from future changes to them. Intel’s Intel Architecture processors (e.g., Pentium®, Pentium® II, Pentium® III, and Pentium® Pro processors) may contain design defects or errors known as errata which may cause the product to deviate from published specifications. Current characterized errata are available on request. Contact your local Intel sales office or your distributor to obtain the latest specifications and before placing your product order. -

Chapter 3 Basic Execution Environment
CHAPTER 3 BASIC EXECUTION ENVIRONMENT This chapter describes the basic execution environment of an Intel 64 or IA-32 processor as seen by assembly- language programmers. It describes how the processor executes instructions and how it stores and manipulates data. The execution environment described here includes memory (the address space), general-purpose data registers, segment registers, the flag register, and the instruction pointer register. 3.1 MODES OF OPERATION The IA-32 architecture supports three basic operating modes: protected mode, real-address mode, and system management mode. The operating mode determines which instructions and architectural features are accessible: • Protected mode — This mode is the native state of the processor. Among the capabilities of protected mode is the ability to directly execute “real-address mode” 8086 software in a protected, multi-tasking environment. This feature is called virtual-8086 mode, although it is not actually a processor mode. Virtual-8086 mode is actually a protected mode attribute that can be enabled for any task. • Real-address mode — This mode implements the programming environment of the Intel 8086 processor with extensions (such as the ability to switch to protected or system management mode). The processor is placed in real-address mode following power-up or a reset. • System management mode (SMM) — This mode provides an operating system or executive with a transparent mechanism for implementing platform-specific functions such as power management and system security. The processor enters SMM when the external SMM interrupt pin (SMI#) is activated or an SMI is received from the advanced programmable interrupt controller (API C). In SMM, the processor switches to a separate address space while saving the basic context of the currently running program or task. -

How to Write Fast Numerical Code Spring 2013 Lecture: Architecture/Microarchitecture and Intel Core
How to Write Fast Numerical Code Spring 2013 Lecture: Architecture/Microarchitecture and Intel Core Instructor: Markus Püschel TA: Georg Ofenbeck & Daniele Spampinato Technicalities Research project: . Let us know once you have a partner . Three in a team is fine, but not one . If you have a project idea, talk to me after class or this week Tues 10:30, Wed 15:00, Fr 10:00 (1 hour each) . Some clarifications from my side . Deadline: March 7th Finding partner: [email protected] . Recipients: TA Georg + all students that have no partner yet 2 © Markus Püschel How to write fast numerical code Computer Science Spring 2013 Today Architecture/Microarchitecture In detail: Core 2/Core i7 Crucial microarchitectural parameters Peak performance Operational intensity 3 Definitions Architecture (also instruction set architecture = ISA): The parts of a processor design that one needs to understand to write assembly code Examples: instruction set specification, registers Counterexamples: cache sizes and core frequency Example ISAs . x86 . ia . MIPS . POWER . SPARC . ARM 4 © Markus Püschel How to write fast numerical code Computer Science Spring 2013 MMX: Multimedia extension SSE: Intel x86 Processors Streaming SIMD extension x86-16 8086 AVX: Advanced vector extensions 286 x86-32 386 486 Pentium MMX Pentium MMX SSE Pentium III time SSE2 Pentium 4 SSE3 Pentium 4E x86-64 / em64t Pentium 4F Core 2 Duo SSE4 Penryn Core i7 (Nehalem) AVX Sandy Bridge 5 ISA SIMD (Single Instruction Multiple Data) Vector Extensions What is it? . Extension of the ISA. Data types and instructions for the parallel computation on short (length 2-8) vectors of integers or floats + x 4-way . -

Evaluation of X32 ABI for Virtualization and Cloud
Evaluation of X32 ABI for Virtualization and Cloud Jun Nakajima Intel Corporation 1 Wednesday, August 29, 12 1 Agenda • What is X32 ABI? • Benefits for Virtualization & Cloud • Evaluation of X32 • Summary 2 Wednesday, August 29, 12 2 x32 ABI Basics • x86-64 ABI but with 32-bit longs and pointers • 64-bit arithmetic • Fully utilize modern x86 • 8 additional integer registers (16 total) • 8 additional SSE registers • SSE for FP math • 64-bit kernel is required - Linux kernel 3.4 has support for x32 Same memory footprint as x86 with advantages of x86-64. No hardware changes are required. 3 Wednesday, August 29, 12 3 ABI Comparison i386 x86-64 x32 Integer registers 6 15 15 FP registers 8 16 16 Pointers 4 bytes 8 bytes 4 bytes 64-bit arithmetic No Yes Yes Floating point x87 SSE SSE Calling convention Memory Registers Registers PIC prologue 2-3 insn None None 4 Wednesday, August 29, 12 4 The x32 Performance Advantage • In the order of Expected Contribution: - Efficient Position Independent Code - Efficient Function Parameter Passing - Efficient 64-bit Arithmetic - Efficient Floating Point Operations X32 is expected to give a 10-20% performance boost for C, C++ 5 Wednesday, August 29, 12 5 Efficient Position Independent Code extern int x, y, z; void foo () { z = x * y; } i386 psABI x32 psABI call __i686.get_pc_thunk.cx movl x@GOTPCREL(%rip), %edx addl $_GLOBAL_OFFSET_TABLE_, %ecx movl y@GOTPCREL(%rip), %eax movl!y@GOT(%ecx), %eax movl (%rax), %rax movl!x@GOT(%ecx), %edx imull (%rdx), %rax movl!(%eax), %eax movl z@GOTPCREL(%rip), %edx imull!(%edx), -
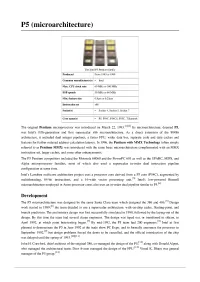
P5 (Microarchitecture)
P5 (microarchitecture) The Intel P5 Pentium family Produced From 1993 to 1999 Common manufacturer(s) • Intel Max. CPU clock rate 60 MHz to 300 MHz FSB speeds 50 MHz to 66 MHz Min. feature size 0.8pm to 0.25pm Instruction set x86 Socket(s) • Socket 4, Socket 5, Socket 7 Core name(s) P5. P54C, P54CS, P55C, Tillamook The original Pentium microprocessor was introduced on March 22, 1993.^^ Its microarchitecture, deemed P5, was Intel's fifth-generation and first superscalar x86 microarchitecture. As a direct extension of the 80486 architecture, it included dual integer pipelines, a faster FPU, wider data bus, separate code and data caches and features for further reduced address calculation latency. In 1996, the Pentium with MMX Technology (often simply referred to as Pentium MMX) was introduced with the same basic microarchitecture complemented with an MMX instruction set, larger caches, and some other enhancements. The P5 Pentium competitors included the Motorola 68060 and the PowerPC 601 as well as the SPARC, MIPS, and Alpha microprocessor families, most of which also used a superscalar in-order dual instruction pipeline configuration at some time. Intel's Larrabee multicore architecture project uses a processor core derived from a P5 core (P54C), augmented by multithreading, 64-bit instructions, and a 16-wide vector processing unit. T31 Intel's low-powered Bonnell [4i microarchitecture employed in Atom processor cores also uses an in-order dual pipeline similar to P5. Development The P5 microarchitecture was designed by the same Santa Clara team which designed the 386 and 486.^ Design work started in 1989;^ the team decided to use a superscalar architecture, with on-chip cache, floating-point, and branch prediction.