Computer Animation Algorithms and Techniques
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Easy As Abc: Categorizing Open Source Licenses
EASY AS ABC: CATEGORIZING OPEN SOURCE LICENSES Andrew T. Pham1, Matthew B. Weinstein2, Jamie L. Ryerson3 With more than 180,000 open source projects available and its more than 1400 unique licenses, the complexity of deciding how to manage open source usage within “closed-source” commercial enterprises have dramatically increased.4 Because of the complexity and risks associated with open source—where source code is made freely available for all to review, edit, and use—many closed-source commercial enterprises discourage or prohibit use of open source; a common and short-sighted practice. With a proper open source management framework, open source can be an invaluable resource, and its risks can be understood, managed and controlled. This article proposes a simple, consistent and effective open source categorization and management system to enable a peaceful coexistence between open source and closed-source codes. Free and open source software (“FOSS” or collectively “open source”) is a valuable tool, but one that must be understood to be used effectively. The litany of risks associated with use of open source include: having to release a derivative product incorporating open source under the same open source license; incorporating code that infringes a patent; violating an open source license’s attribution requirements; and a lack of warranties and indemnities. Given the extensive investment of time, money and resources that goes into product development, it comes as no This article is an edited version of the original, which dealt not only with categorizing open source licenses but also a wider array of issues associated with implementing an open source policy. -

UPA : Redesigning Animation
This document is downloaded from DR‑NTU (https://dr.ntu.edu.sg) Nanyang Technological University, Singapore. UPA : redesigning animation Bottini, Cinzia 2016 Bottini, C. (2016). UPA : redesigning animation. Doctoral thesis, Nanyang Technological University, Singapore. https://hdl.handle.net/10356/69065 https://doi.org/10.32657/10356/69065 Downloaded on 05 Oct 2021 20:18:45 SGT UPA: REDESIGNING ANIMATION CINZIA BOTTINI SCHOOL OF ART, DESIGN AND MEDIA 2016 UPA: REDESIGNING ANIMATION CINZIA BOTTINI School of Art, Design and Media A thesis submitted to the Nanyang Technological University in partial fulfillment of the requirement for the degree of Doctor of Philosophy 2016 “Art does not reproduce the visible; rather, it makes visible.” Paul Klee, “Creative Credo” Acknowledgments When I started my doctoral studies, I could never have imagined what a formative learning experience it would be, both professionally and personally. I owe many people a debt of gratitude for all their help throughout this long journey. I deeply thank my supervisor, Professor Heitor Capuzzo; my cosupervisor, Giannalberto Bendazzi; and Professor Vibeke Sorensen, chair of the School of Art, Design and Media at Nanyang Technological University, Singapore for showing sincere compassion and offering unwavering moral support during a personally difficult stage of this Ph.D. I am also grateful for all their suggestions, critiques and observations that guided me in this research project, as well as their dedication and patience. My gratitude goes to Tee Bosustow, who graciously -

Digital Dialectics: the Paradox of Cinema in a Studio Without Walls', Historical Journal of Film, Radio and Television , Vol
Scott McQuire, ‘Digital dialectics: the paradox of cinema in a studio without walls', Historical Journal of Film, Radio and Television , vol. 19, no. 3 (1999), pp. 379 – 397. This is an electronic, pre-publication version of an article published in Historical Journal of Film, Radio and Television. Historical Journal of Film, Radio and Television is available online at http://www.informaworld.com/smpp/title~content=g713423963~db=all. Digital dialectics: the paradox of cinema in a studio without walls Scott McQuire There’s a scene in Forrest Gump (Robert Zemeckis, Paramount Pictures; USA, 1994) which encapsulates the novel potential of the digital threshold. The scene itself is nothing spectacular. It involves neither exploding spaceships, marauding dinosaurs, nor even the apocalyptic destruction of a postmodern cityscape. Rather, it depends entirely on what has been made invisible within the image. The scene, in which actor Gary Sinise is shown in hospital after having his legs blown off in battle, is noteworthy partly because of the way that director Robert Zemeckis handles it. Sinise has been clearly established as a full-bodied character in earlier scenes. When we first see him in hospital, he is seated on a bed with the stumps of his legs resting at its edge. The assumption made by most spectators, whether consciously or unconsciously, is that the shot is tricked up; that Sinise’s legs are hidden beneath the bed, concealed by a hole cut through the mattress. This would follow a long line of film practice in faking amputations, inaugurated by the famous stop-motion beheading in the Edison Company’s Death of Mary Queen of Scots (aka The Execution of Mary Stuart, Thomas A. -

Animation: Types
Animation: Animation is a dynamic medium in which images or objects are manipulated to appear as moving images. In traditional animation, images are drawn or painted by hand on transparent celluloid sheets to be photographed and exhibited on film. Today most animations are made with computer generated (CGI). Commonly the effect of animation is achieved by a rapid succession of sequential images that minimally differ from each other. Apart from short films, feature films, animated gifs and other media dedicated to the display moving images, animation is also heavily used for video games, motion graphics and special effects. The history of animation started long before the development of cinematography. Humans have probably attempted to depict motion as far back as the Paleolithic period. Shadow play and the magic lantern offered popular shows with moving images as the result of manipulation by hand and/or some minor mechanics Computer animation has become popular since toy story (1995), the first feature-length animated film completely made using this technique. Types: Traditional animation (also called cel animation or hand-drawn animation) was the process used for most animated films of the 20th century. The individual frames of a traditionally animated film are photographs of drawings, first drawn on paper. To create the illusion of movement, each drawing differs slightly from the one before it. The animators' drawings are traced or photocopied onto transparent acetate sheets called cels which are filled in with paints in assigned colors or tones on the side opposite the line drawings. The completed character cels are photographed one-by-one against a painted background by rostrum camera onto motion picture film. -
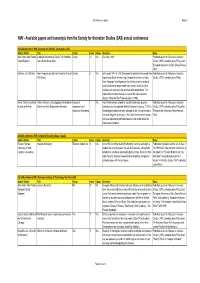
Available Papers and Transcripts from the Society for Animation Studies (SAS) Annual Conferences
SAS Conference papers Pagina 1 NIAf - Available papers and transcripts from the Society for Animation Studies (SAS) annual conferences 1st SAS conference 1989, University of California, Los Angeles, USA Author (Origin) Title Forum Pages Copies Summary Notes Allan, Robin (InterTheatre, European Influences on Disney: The Formative Disney 20 N.A. See: Allan, 1991. Published as part of A Reader in Animation United Kingdom) Years Before Snow White Studies (1997), edited by Jayne Pilling, titled: "European Influences on Early Disney Feature Films". Kaufman, J.B. (Wichita) Norm Ferguson and the Latin American Films of Disney 8 N.A. In the years 1941-43, Walt Disney and his animation team made three Published as part of A Reader in Animation Walt Disney trips through South America, to get inspiration for their next films. Studies (1997), edited by Jayne Pilling. Norm Ferguson, the unit producer for the films, made hundreds of photo's and several people made home video's, thanks to which Kaufman can reconstruct the journey and its complications. The feature films that were made as a result of the trip are Saludos Amigos (1942) and The Three Caballero's (1944). Moritz, William (California Walter Ruttmann, Viking Eggeling: Restoring the Aspects of 7 N.A. Hans Richter always claimed he was the first to make absolute Published as part of A Reader in Animation Institute of the Arts) Esthetics of Early Experimental Animation independent and animations, but he neglected Walther Ruttmann's Opus no. 1 (1921). Studies (1997), edited by Jayne Pilling, titled institutional filmmaking Viking Eggeling had made some attempts as well, that culminated in "Restoring the Aesthetics of Early Abstract the crude Diagonal Symphony in 1923 . -

Overview of History of Irish Animation
Overview of History of Irish Animation i) The history of animation here and the pattern of its development, ii) ii) The contemporary scene, iii) iii) Funding and support, iv) iv) The technological advancement, which can allow filmmakers do more and do it more excitingly, v) v) The educational background. i) History and Development. The history of animation in Ireland is comparable to the history of live action film in Ireland in that in the early years it offered the promise of much to come and stopped really before it got started; indeed in the final analysis animation has even far less to show for itself than its early live action cousin. One outstanding exception is the pioneering work of James Horgan. Horgan became involved in cinema at the end of the 19th century when he acquired a Lumiere camera and established his own moving picture exhibition company for the south show to his audiences - mostly religious events. However soon his eager mind began to turn to the Munster region. As well as projecting regular international shows, Horgan shot local footage to look into cinematography in a scientific way and in fact he made some money by patenting a cog for film traction in the camera, which was widely used. He also experimented with Polaroid film. He then began to dabble in stop frame work - animation - around the year 1909 and considering that the first animation was made in 1906, this is quite significant. His most famous and most popular piece was his dancing Youghal Clock Tower - where the town's best known landmark has to hop into the frame and "manipulate" itself frame by frame into its rightful place in the main street in Youghal. -

Computerising 2D Animation and the Cleanup Power of Snakes
Computerising 2D Animation and the Cleanup Power of Snakes. Fionnuala Johnson Submitted for the degree of Master of Science University of Glasgow, The Department of Computing Science. January 1998 ProQuest Number: 13818622 All rights reserved INFORMATION TO ALL USERS The quality of this reproduction is dependent upon the quality of the copy submitted. In the unlikely event that the author did not send a com plete manuscript and there are missing pages, these will be noted. Also, if material had to be removed, a note will indicate the deletion. uest ProQuest 13818622 Published by ProQuest LLC(2018). Copyright of the Dissertation is held by the Author. All rights reserved. This work is protected against unauthorized copying under Title 17, United States C ode Microform Edition © ProQuest LLC. ProQuest LLC. 789 East Eisenhower Parkway P.O. Box 1346 Ann Arbor, Ml 48106- 1346 GLASGOW UNIVERSITY LIBRARY U3 ^coji^ \ Abstract Traditional 2D animation remains largely a hand drawn process. Computer-assisted animation systems do exists. Unfortunately the overheads these systems incur have prevented them from being introduced into the traditional studio. One such prob lem area involves the transferral of the animator’s line drawings into the computer system. The systems, which are presently available, require the images to be over- cleaned prior to scanning. The resulting raster images are of unacceptable quality. Therefore the question this thesis examines is; given a sketchy raster image is it possible to extract a cleaned-up vector image? Current solutions fail to extract the true line from the sketch because they possess no knowledge of the problem area. -

An Introduction to Software Licensing
An Introduction to Software Licensing James Willenbring Software Engineering and Research Department Center for Computing Research Sandia National Laboratories David Bernholdt Oak Ridge National Laboratory Please open the Q&A Google Doc so that I can ask you Michael Heroux some questions! Sandia National Laboratories http://bit.ly/IDEAS-licensing ATPESC 2019 Q Center, St. Charles, IL (USA) (And you’re welcome to ask See slide 2 for 8 August 2019 license details me questions too) exascaleproject.org Disclaimers, license, citation, and acknowledgements Disclaimers • This is not legal advice (TINLA). Consult with true experts before making any consequential decisions • Copyright laws differ by country. Some info may be US-centric License and Citation • This work is licensed under a Creative Commons Attribution 4.0 International License (CC BY 4.0). • Requested citation: James Willenbring, David Bernholdt and Michael Heroux, An Introduction to Software Licensing, tutorial, in Argonne Training Program on Extreme-Scale Computing (ATPESC) 2019. • An earlier presentation is archived at https://ideas-productivity.org/events/hpc-best-practices-webinars/#webinar024 Acknowledgements • This work was supported by the U.S. Department of Energy Office of Science, Office of Advanced Scientific Computing Research (ASCR), and by the Exascale Computing Project (17-SC-20-SC), a collaborative effort of the U.S. Department of Energy Office of Science and the National Nuclear Security Administration. • This work was performed in part at the Oak Ridge National Laboratory, which is managed by UT-Battelle, LLC for the U.S. Department of Energy under Contract No. DE-AC05-00OR22725. • This work was performed in part at Sandia National Laboratories. -

The University of Chicago Looking at Cartoons
THE UNIVERSITY OF CHICAGO LOOKING AT CARTOONS: THE ART, LABOR, AND TECHNOLOGY OF AMERICAN CEL ANIMATION A DISSERTATION SUBMITTED TO THE FACULTY OF THE DIVISION OF THE HUMANITIES IN CANDIDACY FOR THE DEGREE OF DOCTOR OF PHILOSOPHY DEPARTMENT OF CINEMA AND MEDIA STUDIES BY HANNAH MAITLAND FRANK CHICAGO, ILLINOIS AUGUST 2016 FOR MY FAMILY IN MEMORY OF MY FATHER Apparently he had examined them patiently picture by picture and imagined that they would be screened in the same way, failing at that time to grasp the principle of the cinematograph. —Flann O’Brien CONTENTS LIST OF FIGURES...............................................................................................................................v ABSTRACT.......................................................................................................................................vii ACKNOWLEDGMENTS....................................................................................................................viii INTRODUCTION LOOKING AT LABOR......................................................................................1 CHAPTER 1 ANIMATION AND MONTAGE; or, Photographic Records of Documents...................................................22 CHAPTER 2 A VIEW OF THE WORLD Toward a Photographic Theory of Cel Animation ...................................72 CHAPTER 3 PARS PRO TOTO Character Animation and the Work of the Anonymous Artist................121 CHAPTER 4 THE MULTIPLICATION OF TRACES Xerographic Reproduction and One Hundred and One Dalmatians.......174 -

The Uses of Animation 1
The Uses of Animation 1 1 The Uses of Animation ANIMATION Animation is the process of making the illusion of motion and change by means of the rapid display of a sequence of static images that minimally differ from each other. The illusion—as in motion pictures in general—is thought to rely on the phi phenomenon. Animators are artists who specialize in the creation of animation. Animation can be recorded with either analogue media, a flip book, motion picture film, video tape,digital media, including formats with animated GIF, Flash animation and digital video. To display animation, a digital camera, computer, or projector are used along with new technologies that are produced. Animation creation methods include the traditional animation creation method and those involving stop motion animation of two and three-dimensional objects, paper cutouts, puppets and clay figures. Images are displayed in a rapid succession, usually 24, 25, 30, or 60 frames per second. THE MOST COMMON USES OF ANIMATION Cartoons The most common use of animation, and perhaps the origin of it, is cartoons. Cartoons appear all the time on television and the cinema and can be used for entertainment, advertising, 2 Aspects of Animation: Steps to Learn Animated Cartoons presentations and many more applications that are only limited by the imagination of the designer. The most important factor about making cartoons on a computer is reusability and flexibility. The system that will actually do the animation needs to be such that all the actions that are going to be performed can be repeated easily, without much fuss from the side of the animator. -

Downloaded Off Washington on Wednesday
THE TU TS DAILY miereYou Read It First Friday, January 29,1999 Volume XXXVIII, Number 4 1 Dr. King service brings the Endowment fund created in honor of Joseph Gonzalez . Year of Non-violence to end A bly BROOKE MENSCHEL of the First Unitaridn by DANIEL BARBARlSI be marked with a special plaque Daily Editorial Board Universalist Parish in Daily Editorial Board on the inside cover, in memory of The University-wide Year of Cambridge. He is also The memory and legacy of Gonzalez. an active member of Non-vio1ence;which began last Tufts student Joseph Gonzalez, Michael Juliano, one of the National Asso- Martin Luther King Day, ended who passed away suddenly last Gonzalez’ closest friends, de- ciation for the Ad- this Wednesday night with “A year, will be commemorated at scribed the fund as a palpable, vancement of Col- Pilgrimage to Nonviolence,” a Tufts through the creation of an concrete method of preserving ored Persons commemorative service for King. endowment in his honor. The en- Gonzalez’memory. The service, which was held in (NAACP), a visiting dowment, given to the Tisch Li- “Therearea lotofthingsabout lecturer at Harvard’s Goddard Chapel, used King’s own brary for the purpose ofpurchas- Joey you can remember, butthis Divinity school, and words as well as the words of ing additional literature, was ini- book fund is a tangible legacy ... the co-founder and many others to commemorate both tiated through a $10,000 dona- thisone youcan actuallypickup co-director of the theyear and the man. The campus tion by Gonzalez’ parents, Jo- and take in your hand,” Juliano Tuckman Coalition, a chaplains Rev. -

Stop-Motion Animation an Introduction What Is Animation?
Stop-motion Animation An Introduction What is Animation? In its simplest form, animation is essentially making something that doesn’t move (inanimate) look like it is moving (animate). This can be done through repeated drawings or paintings (traditional 2D), using puppets or clay (stop-motion) and using computer programmes and software (CG and 3D). All of these methods have one aim in mind: to create ‘the illusion of life’. Key Resource: The Evolution of Animation The following video shows how animation has evolved from it’s very first days using contraptions like the ‘Zoetrope’. Whilst you watch these clips, think about the different types of animation used. How many of these films do you recognise? The Evolution of Animation 1833-2017 https://www.youtube.com/watch?v=z6TOQzCDO7Y Many older animations are available to watch on Youtube, such as ‘Gertie the Dinosaur’ and ‘Felix the Cat’, and it’s important to appreciate these as being the roots of modern animation. Younger Animators might also get a kick out of watching some classic ‘Looney Tunes’ cartoons. What is movement? A movement is when something goes from point A to point B in a certain amount of time. The amount of time it takes dictates how fast that movement is. In other words, if something goes from point A to B in a short amount of time then it is a fast movement, and if it takes a long time then it is a slow movement. Experiment: Try out some actions like waving, spinning in a circle and walking all at different speeds.