Parallel External Memory and Cache Oblivious Algorithms
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Vertex Coloring
Lecture 1 Vertex Coloring 1.1 The Problem Nowadays multi-core computers get more and more processors, and the question is how to handle all this parallelism well. So, here's a basic problem: Consider a doubly linked list that is shared by many processors. It supports insertions and deletions, and there are simple operations like summing up the size of the entries that should be done very fast. We decide to organize the data structure as an array of dynamic length, where each array index may or may not hold an entry. Each entry consists of the array indices of the next entry and the previous entry in the list, some basic information about the entry (e.g. its size), and a pointer to the lion's share of the data, which can be anywhere in the memory. Memory structure Logical structure 1 2 3 4 5 6 7 8 9 1 2 3 4 5 6 7 8 9 next previous size data Figure 1.1: Linked listed after initialization. Blue links are forward pointers, red links backward pointers (these are omitted from now on). We now can quickly determine the total size by reading the array in one go from memory, which is quite fast. However, how can we do insertions and deletions fast? These are local operations affecting only one list entry and the pointers of its \neighbors," i.e., the previous and next list element. We want to be able to do many such operations concurrently, by different processors, while maintaining the link structure! Being careless and letting each processor act independently invites desaster, see Figure 1.3. -

Paralellizing the Data Cube
PARALELLIZING THE DATA CUBE By Todd Eavis SUBMITTED IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF DOCTOR OF PHILOSOPHY AT DALHOUSIE UNIVERSITY HALIFAX, NOVA SCOTIA JUNE 27, 2003 °c Copyright by Todd Eavis, 2003 DALHOUSIE UNIVERSITY DEPARTMENT OF COMPUTER SCIENCE The undersigned hereby certify that they have read and recommend to the Faculty of Graduate Studies for acceptance a thesis entitled “Paralellizing the Data Cube” by Todd Eavis in partial fulfillment of the requirements for the degree of Doctor of Philosophy. Dated: June 27, 2003 External Examiner: Virendra Bhavsar Research Supervisor: Andrew Rau-Chaplin Examing Committee: Qigang Gao Evangelos Milios ii DALHOUSIE UNIVERSITY Date: June 27, 2003 Author: Todd Eavis Title: Paralellizing the Data Cube Department: Computer Science Degree: Ph.D. Convocation: October Year: 2003 Permission is herewith granted to Dalhousie University to circulate and to have copied for non-commercial purposes, at its discretion, the above title upon the request of individuals or institutions. Signature of Author THE AUTHOR RESERVES OTHER PUBLICATION RIGHTS, AND NEITHER THE THESIS NOR EXTENSIVE EXTRACTS FROM IT MAY BE PRINTED OR OTHERWISE REPRODUCED WITHOUT THE AUTHOR’S WRITTEN PERMISSION. THE AUTHOR ATTESTS THAT PERMISSION HAS BEEN OBTAINED FOR THE USE OF ANY COPYRIGHTED MATERIAL APPEARING IN THIS THESIS (OTHER THAN BRIEF EXCERPTS REQUIRING ONLY PROPER ACKNOWLEDGEMENT IN SCHOLARLY WRITING) AND THAT ALL SUCH USE IS CLEARLY ACKNOWLEDGED. iii To the two women in my life: Amber and Bailey. iv Table of Contents Table of Contents v List of Tables x List of Figures xi Abstract i Acknowledgements ii 1 Introduction 1 1.1 Overview of Primary Research . -

Easy PRAM-Based High-Performance Parallel Programming with ICE∗
Easy PRAM-based high-performance parallel programming with ICE∗ Fady Ghanim1, Uzi Vishkin1,2, and Rajeev Barua1 1Electrical and Computer Engineering Department 2University of Maryland Institute for Advance Computer Studies University of Maryland - College Park MD, 20742, USA ffghanim,barua,[email protected] Abstract Parallel machines have become more widely used. Unfortunately parallel programming technologies have advanced at a much slower pace except for regular programs. For irregular programs, this advancement is inhibited by high synchronization costs, non-loop parallelism, non-array data structures, recursively expressed parallelism and parallelism that is too fine-grained to be exploitable. We present ICE, a new parallel programming language that is easy-to-program, since: (i) ICE is a synchronous, lock-step language; (ii) for a PRAM algorithm its ICE program amounts to directly transcribing it; and (iii) the PRAM algorithmic theory offers unique wealth of parallel algorithms and techniques. We propose ICE to be a part of an ecosystem consisting of the XMT architecture, the PRAM algorithmic model, and ICE itself, that together deliver on the twin goal of easy programming and efficient parallelization of irregular programs. The XMT architecture, developed at UMD, can exploit fine-grained parallelism in irregular programs. We built the ICE compiler which translates the ICE language into the multithreaded XMTC language; the significance of this is that multi-threading is a feature shared by practically all current scalable parallel programming languages. Our main result is perhaps surprising: The run-time was comparable to XMTC with a 0.48% average gain for ICE across all benchmarks. Also, as an indication of ease of programming, we observed a reduction in code size in 7 out of 11 benchmarks vs. -

Instructor's Manual
Instructor’s Manual Vol. 2: Presentation Material CCC Mesh/Torus Butterfly !*#? Sea Sick Hypercube Pyramid Behrooz Parhami This instructor’s manual is for Introduction to Parallel Processing: Algorithms and Architectures, by Behrooz Parhami, Plenum Series in Computer Science (ISBN 0-306-45970-1, QA76.58.P3798) 1999 Plenum Press, New York (http://www.plenum.com) All rights reserved for the author. No part of this instructor’s manual may be reproduced, stored in a retrieval system, or transmitted in any form or by any means, electronic, mechanical, photocopying, microfilming, recording, or otherwise, without written permission. Contact the author at: ECE Dept., Univ. of California, Santa Barbara, CA 93106-9560, USA ([email protected]) Introduction to Parallel Processing: Algorithms and Architectures Instructor’s Manual, Vol. 2 (4/00), Page iv Preface to the Instructor’s Manual This instructor’s manual consists of two volumes. Volume 1 presents solutions to selected problems and includes additional problems (many with solutions) that did not make the cut for inclusion in the text Introduction to Parallel Processing: Algorithms and Architectures (Plenum Press, 1999) or that were designed after the book went to print. It also contains corrections and additions to the text, as well as other teaching aids. The spring 2000 edition of Volume 1 consists of the following parts (the next edition is planned for spring 2001): Vol. 1: Problem Solutions Part I Selected Solutions and Additional Problems Part II Question Bank, Assignments, and Projects Part III Additions, Corrections, and Other Updates Part IV Sample Course Outline, Calendar, and Forms Volume 2 contains enlarged versions of the figures and tables in the text, in a format suitable for use as transparency masters. -

Lawrence Berkeley National Laboratory Recent Work
Lawrence Berkeley National Laboratory Recent Work Title Parallel algorithms for finding connected components using linear algebra Permalink https://escholarship.org/uc/item/8ms106vm Authors Zhang, Y Azad, A Buluç, A Publication Date 2020-10-01 DOI 10.1016/j.jpdc.2020.04.009 Peer reviewed eScholarship.org Powered by the California Digital Library University of California Parallel Algorithms for Finding Connected Components using Linear Algebra Yongzhe Zhanga, Ariful Azadb, Aydın Buluc¸c aDepartment of Informatics, The Graduate University for Advanced Studies, SOKENDAI, Japan bDepartment of Intelligent Systems Engineering, Indiana University, Bloomington, IN, USA cComputational Research Division, Lawrence Berkeley National Laboratory, Berkeley, CA, USA Abstract Finding connected components is one of the most widely used operations on a graph. Optimal serial algorithms for the problem have been known for half a century, and many competing parallel algorithms have been proposed over the last several decades under various different models of parallel computation. This paper presents a class of parallel connected-component algorithms designed using linear-algebraic primitives. These algorithms are based on a PRAM algorithm by Shiloach and Vishkin and can be designed using standard GraphBLAS operations. We demonstrate two algorithms of this class, one named LACC for Linear Algebraic Connected Components, and the other named FastSV which can be regarded as LACC’s simplification. With the support of the highly-scalable Combinatorial BLAS library, LACC and FastSV outperform the previous state-of-the-art algorithm by a factor of up to 12x for small to medium scale graphs. For large graphs with more than 50B edges, LACC and FastSV scale to 4K nodes (262K cores) of a Cray XC40 supercomputer and outperform previous algorithms by a significant margin. -

Two-Level Main Memory Co-Design: Multi-Threaded Algorithmic Primitives, Analysis, and Simulation
Two-Level Main Memory Co-Design: Multi-Threaded Algorithmic Primitives, Analysis, and Simulation Michael A. Bender∗x Jonathan Berryy Simon D. Hammondy K. Scott Hemmerty Samuel McCauley∗ Branden Moorey Benjamin Moseleyz Cynthia A. Phillipsy David Resnicky and Arun Rodriguesy ∗Stony Brook University, Stony Brook, NY 11794-4400 USA fbender,[email protected] ySandia National Laboratories, Albuquerque, NM 87185 USA fjberry, sdhammo, kshemme, bjmoor, caphill, drresni, [email protected] zWashington University in St. Louis, St. Louis, MO 63130 USA [email protected] xTokutek, Inc. www.tokutek.com Abstract—A fundamental challenge for supercomputer memory close to the processor, there can be a higher architecture is that processors cannot be fed data from number of connections between the memory and caches, DRAM as fast as CPUs can consume it. Therefore, many enabling higher bandwidth than current technologies. applications are memory-bandwidth bound. As the number 1 of cores per chip increases, and traditional DDR DRAM While the term scratchpad is overloaded within the speeds stagnate, the problem is only getting worse. A computer architecture field, we use it throughout this variety of non-DDR 3D memory technologies (Wide I/O 2, paper to describe a high-bandwidth, local memory that HBM) offer higher bandwidth and lower power by stacking can be used as a temporary storage location. DRAM chips on the processor or nearby on a silicon The scratchpad cannot replace DRAM entirely. Due to interposer. However, such a packaging scheme cannot contain sufficient memory capacity for a node. It seems the physical constraints of adding the memory directly likely that future systems will require at least two levels of to the chip, the scratchpad cannot be as large as DRAM, main memory: high-bandwidth, low-power memory near although it will be much larger than cache, having the processor and low-bandwidth high-capacity memory gigabytes of storage capacity. -

Minimizing Writes in Parallel External Memory Search
Proceedings of the Twenty-Third International Joint Conference on Artificial Intelligence Minimizing Writes in Parallel External Memory Search Nathan R. Sturtevant and Matthew J. Rutherford University of Denver Denver, CO, USA fsturtevant, [email protected] Abstract speed in Chinese Checkers, and is 3.5 times faster in Rubik’s Cube. Recent research on external-memory search has shown that disks can be effectively used as sec- WMBFS is motivated by several observations: ondary storage when performing large breadth- first searches. We introduce the Write-Minimizing First, most large-scale BFSs have been performed to ver- Breadth-First Search (WMBFS) algorithm which ify the diameter (the number of unique depths at which states is designed to minimize the number of writes per- can be found) or the width (the maximum number of states at formed in an external-memory BFS. WMBFS is any particular depth) of a state space, after which any com- also designed to store the results of the BFS for puted data is discarded. There are, however, many scenarios later use. We present the results of a BFS on a in which the results of a large BFS can be later used for other single-agent version of Chinese Checkers and the computation. In particular, a breadth-first search is the under- Rubik’s Cube edge cubes, state spaces with about lying technique for building pattern databases (PDBs), which 1 trillion states each. In evaluating against a com- are used as heuristics for search. PDBs require that the depth parable approach, WMBFS reduces the I/O for the of each state in the BFS be stored for later usage. -
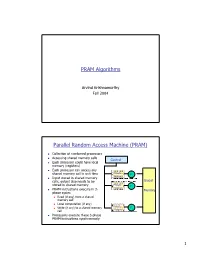
PRAM Algorithms Parallel Random Access Machine
PRAM Algorithms Arvind Krishnamurthy Fall 2004 Parallel Random Access Machine (PRAM) n Collection of numbered processors n Accessing shared memory cells Control n Each processor could have local memory (registers) n Each processor can access any shared memory cell in unit time Private P Memory 1 n Input stored in shared memory cells, output also needs to be Global stored in shared memory Private P Memory 2 n PRAM instructions execute in 3- Memory phase cycles n Read (if any) from a shared memory cell n Local computation (if any) Private n Write (if any) to a shared memory P Memory p cell n Processors execute these 3-phase PRAM instructions synchronously 1 Shared Memory Access Conflicts n Different variations: n Exclusive Read Exclusive Write (EREW) PRAM: no two processors are allowed to read or write the same shared memory cell simultaneously n Concurrent Read Exclusive Write (CREW): simultaneous read allowed, but only one processor can write n Concurrent Read Concurrent Write (CRCW) n Concurrent writes: n Priority CRCW: processors assigned fixed distinct priorities, highest priority wins n Arbitrary CRCW: one randomly chosen write wins n Common CRCW: all processors are allowed to complete write if and only if all the values to be written are equal A Basic PRAM Algorithm n Let there be “n” processors and “2n” inputs n PRAM model: EREW n Construct a tournament where values are compared P0 Processor k is active in step j v if (k % 2j) == 0 At each step: P0 P4 Compare two inputs, Take max of inputs, P0 P2 P4 P6 Write result into shared memory -

CSE 4351/5351 Notes 9: PRAM and Other Theoretical Model S
CSE 4351/5351 Notes 9: PRAM and Other Theoretical Model s Shared Memory Model Traditional Sequential Algorithm Model RAM (Random Access Machine) Uniform access time to memory Arithmetic operations performed in O(1) time (simplification, really O(lg n)) Generalization of RAM to Parallel Computation PRAM (Parallel Random Access Machine) SHARED MEMORY P0 P1 P2 P3 . Pn FAMILY of models - different concurrency assumptions imply DRASTIC differences in hardware/software support or may be impossible to physically realize. MAJOR THEORETICAL ISSUE: What is the penalty for modifying an algorithm in a flexible model to satisfy a restrictive model? MAJOR PRACTICAL ISSUES: Adequacy for mapping to popular topologies. Developing topologies/algorithms to support models with minimum penalty. Other models: Valiant's BSP (bulk-synchronous parallel), CACM 33 (8), August 1990 "Large" supersteps Bulk communication/routing between supersteps Syncronization to determine superstep completion Karp's LogP, ACM Symp. on Parallel Algorithms and Architectures, 1993 Processors can be: Operational: Computing, receiving, submitting a message Stalling: Delay in message being accepted by communication medium Parameters: L: Maximum time for message to arrive o: Overhead for preparing each message g: Time units between consecutive communication handling steps P: Maximum processor computation time PRAM algorithms are usually described in a SIMD fashion 2 Highly synchronized by constructs in programming notation Instructions are modified based on the processor id Algorithms are simplified by letting processors do useless work Lends to data parallel implementation - PROGRAMMER MUST REDUCE SYNCHRONIZATION OVERHEAD Example PRAM Models EREW (Exclusive Read, Exclusive Write) - Processors must access different memory cells. Most restrictive. CREW (Concurrent Read, Exclusive Write) - Either multiple reads or a single writer may access a cell ERCW (Exclusive Read, Concurrent Write) - Not popular CRCW (Concurrent Read, Concurrent Write) - Most flexible. -

The Parallel Persistent Memory Model
The Parallel Persistent Memory Model Guy E. Blelloch∗ Phillip B. Gibbons∗ Yan Gu∗ Charles McGuffey∗ Julian Shuny ∗Carnegie Mellon University yMIT CSAIL ABSTRACT 1 INTRODUCTION We consider a parallel computational model, the Parallel Persistent In this paper, we consider a parallel computational model, the Par- Memory model, comprised of P processors, each with a fast local allel Persistent Memory (Parallel-PM) model, that consists of P pro- ephemeral memory of limited size, and sharing a large persistent cessors, each with a fast local ephemeral memory of limited size M, memory. The model allows for each processor to fault at any time and sharing a large slower persistent memory. As in the external (with bounded probability), and possibly restart. When a processor memory model [4, 5], each processor runs a standard instruction set faults, all of its state and local ephemeral memory is lost, but the from its ephemeral memory and has instructions for transferring persistent memory remains. This model is motivated by upcoming blocks of size B to and from the persistent memory. The cost of an non-volatile memories that are nearly as fast as existing random algorithm is calculated based on the number of such transfers. A access memory, are accessible at the granularity of cache lines, key difference, however, is that the model allows for individual pro- and have the capability of surviving power outages. It is further cessors to fault at any time. If a processor faults, all of its processor motivated by the observation that in large parallel systems, failure state and local ephemeral memory is lost, but the persistent mem- of processors and their caches is not unusual. -

Implementing Operational Intelligence Using In-Memory Computing
Implementing Operational Intelligence Using In-Memory Computing William L. Bain ([email protected]) June 29, 2015 Agenda • What is Operational Intelligence? • Example: Tracking Set-Top Boxes • Using an In-Memory Data Grid (IMDG) for Operational Intelligence • Tracking and analyzing live data • Comparison to Spark • Implementing OI Using Data-Parallel Computing in an IMDG • A Detailed OI Example in Financial Services • Code Samples in Java • Implementing MapReduce on an IMDG • Optimizing MapReduce for OI • Integrating Operational and Business Intelligence © ScaleOut Software, Inc. 2 About ScaleOut Software • Develops and markets In-Memory Data Grids, software middleware for: • Scaling application performance and • Providing operational intelligence using • In-memory data storage and computing • Dr. William Bain, Founder & CEO • Career focused on parallel computing – Bell Labs, Intel, Microsoft • 3 prior start-ups, last acquired by Microsoft and product now ships as Network Load Balancing in Windows Server • Ten years in the market; 400+ customers, 10,000+ servers • Sample customers: ScaleOut Software’s Product Portfolio ® • ScaleOut StateServer (SOSS) ScaleOut StateServer In-Memory Data Grid • In-Memory Data Grid for Windows and Linux Grid Grid Grid Grid • Scales application performance Service Service Service Service • Industry-leading performance and ease of use • ScaleOut ComputeServer™ adds • Operational intelligence for “live” data • Comprehensive management tools • ScaleOut hServer® • Full Hadoop Map/Reduce engine (>40X faster*) -

Towards a Spatial Model Checker on GPU⋆
Towards a spatial model checker on GPU? Laura Bussi1, Vincenzo Ciancia2, and Fabio Gadducci1 1 Dipartimento di Informatica, Universit`adi Pisa 2 Istituto di Scienza e Tecnologie dell'Informazione, CNR Abstract. The tool VoxLogicA merges the state-of-the-art library of computational imaging algorithms ITK with the combination of declara- tive specification and optimised execution provided by spatial logic model checking. The analysis of an existing benchmark for segmentation of brain tumours via a simple logical specification reached very high accu- racy. We introduce a new, GPU-based version of VoxLogicA and present preliminary results on its implementation, scalability, and applications. Keywords: Spatial logics · Model Checking · GPU computation 1 Introduction and background Spatial and Spatio-temporal model checking have gained an increasing interest in recent years in various application domains, including collective adaptive [12, 11] and networked systems [5], runtime monitoring [17, 15, 4], modelling of cyber- physical systems [20] and medical imaging [13, 3]. Introduced in [7], VoxLogicA (Voxel-based Logical Analyser)3 caters for a declarative approach to (medical) image segmentation, supported by spatial model checking. A spatial logic is defined, tailored to high-level imaging features, such as regions, contact, texture, proximity, distance. Spatial operators are mostly derived from the Spatial Logic of Closure Spaces (SLCS, see Figure 1). Models of the spatial logic are (pixels of) images, with atomic propositions given by imaging features (e.g. colour, intensity), and spatial structure obtained via adjacency of pixels. SLCS features a modal operator near, denoting adjacency of pixels, and a reachability operator ρ φ1[φ2], holding at pixel x whenever there is a path from x to a pixel y satisfying φ1, with all intermediate points, except the extremes, satisfying φ2.