Introduction to Parallel Processing : Algorithms and Architectures
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Vertex Coloring
Lecture 1 Vertex Coloring 1.1 The Problem Nowadays multi-core computers get more and more processors, and the question is how to handle all this parallelism well. So, here's a basic problem: Consider a doubly linked list that is shared by many processors. It supports insertions and deletions, and there are simple operations like summing up the size of the entries that should be done very fast. We decide to organize the data structure as an array of dynamic length, where each array index may or may not hold an entry. Each entry consists of the array indices of the next entry and the previous entry in the list, some basic information about the entry (e.g. its size), and a pointer to the lion's share of the data, which can be anywhere in the memory. Memory structure Logical structure 1 2 3 4 5 6 7 8 9 1 2 3 4 5 6 7 8 9 next previous size data Figure 1.1: Linked listed after initialization. Blue links are forward pointers, red links backward pointers (these are omitted from now on). We now can quickly determine the total size by reading the array in one go from memory, which is quite fast. However, how can we do insertions and deletions fast? These are local operations affecting only one list entry and the pointers of its \neighbors," i.e., the previous and next list element. We want to be able to do many such operations concurrently, by different processors, while maintaining the link structure! Being careless and letting each processor act independently invites desaster, see Figure 1.3. -

Raising the Bar for Using Gpus in Software Packet Processing Anuj Kalia and Dong Zhou, Carnegie Mellon University; Michael Kaminsky, Intel Labs; David G
Raising the Bar for Using GPUs in Software Packet Processing Anuj Kalia and Dong Zhou, Carnegie Mellon University; Michael Kaminsky, Intel Labs; David G. Andersen, Carnegie Mellon University https://www.usenix.org/conference/nsdi15/technical-sessions/presentation/kalia This paper is included in the Proceedings of the 12th USENIX Symposium on Networked Systems Design and Implementation (NSDI ’15). May 4–6, 2015 • Oakland, CA, USA ISBN 978-1-931971-218 Open Access to the Proceedings of the 12th USENIX Symposium on Networked Systems Design and Implementation (NSDI ’15) is sponsored by USENIX Raising the Bar for Using GPUs in Software Packet Processing Anuj Kalia, Dong Zhou, Michael Kaminsky∗, and David G. Andersen Carnegie Mellon University and ∗Intel Labs Abstract based implementations are far easier to experiment with) and in practice (software-based approaches are used for Numerous recent research efforts have explored the use low-speed applications and in cases such as forwarding of Graphics Processing Units (GPUs) as accelerators for within virtual switches [13]). software-based routing and packet handling applications, Our goal in this paper is to advance understanding of typically demonstrating throughput several times higher the advantages of GPU-assisted packet processors com- than using legacy code on the CPU alone. pared to CPU-only designs. In particular, noting that In this paper, we explore a new hypothesis about such several recent efforts have claimed that GPU-based de- designs: For many such applications, the benefits arise signs can be faster even for simple applications such as less from the GPU hardware itself as from the expression IPv4 forwarding [23, 43, 31, 50, 35, 30], we attempt to of the problem in a language such as CUDA or OpenCL identify the reasons for that speedup. -

Easy PRAM-Based High-Performance Parallel Programming with ICE∗
Easy PRAM-based high-performance parallel programming with ICE∗ Fady Ghanim1, Uzi Vishkin1,2, and Rajeev Barua1 1Electrical and Computer Engineering Department 2University of Maryland Institute for Advance Computer Studies University of Maryland - College Park MD, 20742, USA ffghanim,barua,[email protected] Abstract Parallel machines have become more widely used. Unfortunately parallel programming technologies have advanced at a much slower pace except for regular programs. For irregular programs, this advancement is inhibited by high synchronization costs, non-loop parallelism, non-array data structures, recursively expressed parallelism and parallelism that is too fine-grained to be exploitable. We present ICE, a new parallel programming language that is easy-to-program, since: (i) ICE is a synchronous, lock-step language; (ii) for a PRAM algorithm its ICE program amounts to directly transcribing it; and (iii) the PRAM algorithmic theory offers unique wealth of parallel algorithms and techniques. We propose ICE to be a part of an ecosystem consisting of the XMT architecture, the PRAM algorithmic model, and ICE itself, that together deliver on the twin goal of easy programming and efficient parallelization of irregular programs. The XMT architecture, developed at UMD, can exploit fine-grained parallelism in irregular programs. We built the ICE compiler which translates the ICE language into the multithreaded XMTC language; the significance of this is that multi-threading is a feature shared by practically all current scalable parallel programming languages. Our main result is perhaps surprising: The run-time was comparable to XMTC with a 0.48% average gain for ICE across all benchmarks. Also, as an indication of ease of programming, we observed a reduction in code size in 7 out of 11 benchmarks vs. -

Instructor's Manual
Instructor’s Manual Vol. 2: Presentation Material CCC Mesh/Torus Butterfly !*#? Sea Sick Hypercube Pyramid Behrooz Parhami This instructor’s manual is for Introduction to Parallel Processing: Algorithms and Architectures, by Behrooz Parhami, Plenum Series in Computer Science (ISBN 0-306-45970-1, QA76.58.P3798) 1999 Plenum Press, New York (http://www.plenum.com) All rights reserved for the author. No part of this instructor’s manual may be reproduced, stored in a retrieval system, or transmitted in any form or by any means, electronic, mechanical, photocopying, microfilming, recording, or otherwise, without written permission. Contact the author at: ECE Dept., Univ. of California, Santa Barbara, CA 93106-9560, USA ([email protected]) Introduction to Parallel Processing: Algorithms and Architectures Instructor’s Manual, Vol. 2 (4/00), Page iv Preface to the Instructor’s Manual This instructor’s manual consists of two volumes. Volume 1 presents solutions to selected problems and includes additional problems (many with solutions) that did not make the cut for inclusion in the text Introduction to Parallel Processing: Algorithms and Architectures (Plenum Press, 1999) or that were designed after the book went to print. It also contains corrections and additions to the text, as well as other teaching aids. The spring 2000 edition of Volume 1 consists of the following parts (the next edition is planned for spring 2001): Vol. 1: Problem Solutions Part I Selected Solutions and Additional Problems Part II Question Bank, Assignments, and Projects Part III Additions, Corrections, and Other Updates Part IV Sample Course Outline, Calendar, and Forms Volume 2 contains enlarged versions of the figures and tables in the text, in a format suitable for use as transparency masters. -

Lawrence Berkeley National Laboratory Recent Work
Lawrence Berkeley National Laboratory Recent Work Title Parallel algorithms for finding connected components using linear algebra Permalink https://escholarship.org/uc/item/8ms106vm Authors Zhang, Y Azad, A Buluç, A Publication Date 2020-10-01 DOI 10.1016/j.jpdc.2020.04.009 Peer reviewed eScholarship.org Powered by the California Digital Library University of California Parallel Algorithms for Finding Connected Components using Linear Algebra Yongzhe Zhanga, Ariful Azadb, Aydın Buluc¸c aDepartment of Informatics, The Graduate University for Advanced Studies, SOKENDAI, Japan bDepartment of Intelligent Systems Engineering, Indiana University, Bloomington, IN, USA cComputational Research Division, Lawrence Berkeley National Laboratory, Berkeley, CA, USA Abstract Finding connected components is one of the most widely used operations on a graph. Optimal serial algorithms for the problem have been known for half a century, and many competing parallel algorithms have been proposed over the last several decades under various different models of parallel computation. This paper presents a class of parallel connected-component algorithms designed using linear-algebraic primitives. These algorithms are based on a PRAM algorithm by Shiloach and Vishkin and can be designed using standard GraphBLAS operations. We demonstrate two algorithms of this class, one named LACC for Linear Algebraic Connected Components, and the other named FastSV which can be regarded as LACC’s simplification. With the support of the highly-scalable Combinatorial BLAS library, LACC and FastSV outperform the previous state-of-the-art algorithm by a factor of up to 12x for small to medium scale graphs. For large graphs with more than 50B edges, LACC and FastSV scale to 4K nodes (262K cores) of a Cray XC40 supercomputer and outperform previous algorithms by a significant margin. -

Computer Architecture: Parallel Processing Basics
Computer Architecture: Parallel Processing Basics Onur Mutlu & Seth Copen Goldstein Carnegie Mellon University 9/9/13 Today What is Parallel Processing? Why? Kinds of Parallel Processing Multiprocessing and Multithreading Measuring success Speedup Amdhal’s Law Bottlenecks to parallelism 2 Concurrent Systems Embedded-Physical Distributed Sensor Claytronics Networks Concurrent Systems Embedded-Physical Distributed Sensor Claytronics Networks Geographically Distributed Power Internet Grid Concurrent Systems Embedded-Physical Distributed Sensor Claytronics Networks Geographically Distributed Power Internet Grid Cloud Computing EC2 Tashi PDL'09 © 2007-9 Goldstein5 Concurrent Systems Embedded-Physical Distributed Sensor Claytronics Networks Geographically Distributed Power Internet Grid Cloud Computing EC2 Tashi Parallel PDL'09 © 2007-9 Goldstein6 Concurrent Systems Physical Geographical Cloud Parallel Geophysical +++ ++ --- --- location Relative +++ +++ + - location Faults ++++ +++ ++++ -- Number of +++ +++ + - Processors + Network varies varies fixed fixed structure Network --- --- + + connectivity 7 Concurrent System Challenge: Programming The old joke: How long does it take to write a parallel program? One Graduate Student Year 8 Parallel Programming Again?? Increased demand (multicore) Increased scale (cloud) Improved compute/communicate Change in Application focus Irregular Recursive data structures PDL'09 © 2007-9 Goldstein9 Why Parallel Computers? Parallelism: Doing multiple things at a time Things: instructions, -
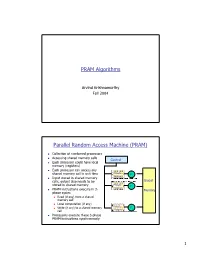
PRAM Algorithms Parallel Random Access Machine
PRAM Algorithms Arvind Krishnamurthy Fall 2004 Parallel Random Access Machine (PRAM) n Collection of numbered processors n Accessing shared memory cells Control n Each processor could have local memory (registers) n Each processor can access any shared memory cell in unit time Private P Memory 1 n Input stored in shared memory cells, output also needs to be Global stored in shared memory Private P Memory 2 n PRAM instructions execute in 3- Memory phase cycles n Read (if any) from a shared memory cell n Local computation (if any) Private n Write (if any) to a shared memory P Memory p cell n Processors execute these 3-phase PRAM instructions synchronously 1 Shared Memory Access Conflicts n Different variations: n Exclusive Read Exclusive Write (EREW) PRAM: no two processors are allowed to read or write the same shared memory cell simultaneously n Concurrent Read Exclusive Write (CREW): simultaneous read allowed, but only one processor can write n Concurrent Read Concurrent Write (CRCW) n Concurrent writes: n Priority CRCW: processors assigned fixed distinct priorities, highest priority wins n Arbitrary CRCW: one randomly chosen write wins n Common CRCW: all processors are allowed to complete write if and only if all the values to be written are equal A Basic PRAM Algorithm n Let there be “n” processors and “2n” inputs n PRAM model: EREW n Construct a tournament where values are compared P0 Processor k is active in step j v if (k % 2j) == 0 At each step: P0 P4 Compare two inputs, Take max of inputs, P0 P2 P4 P6 Write result into shared memory -

DISTRIBUTED COMPUTING ENVIRONMENT ABSTRACT The
DISTRIBUTED COMPUTING ENVIRONMENT ABSTRACT The high volume of networked computers, workstations, LANs has prompted users to move from a simple end user computing to a complex distributed computing environment. This transition is not just networking the computers, but also involves the issues of scalability, security etc. A Distributed Computing Environment herein referred to, as DCE is essentially an integration of all the services necessary to develop, support and manage a distributed computing environment. This term paper discusses the three important issues addressed by DCE in detail, Remote Procedure Calls [IRPC], Distributed File Systems [IDFS][OSF91] and Security [Isec][OSF92]. 1 INTRODUCTION The present day computing industry depends on the efficient usage of resources. So instead of duplicating the resources at every node of computing, a remote method of accessing the resources is more efficient and saves costs. This gave rise to the field of distributed computing, where not only physical resources, but also processing power was distributed. Distributed computing was driven by the following factors. a) Desire to share data and resources b) Minimize duplication of functionality c) Increase cost efficiency d) Increase reliability and availability of resources. The Open Source Foundation’s DCE (OSF DCE) has become the De facto standard for DCE applications and has the backing of IBM, COMPAQ, HP and the likes [OSFInter92]. 1.1 Why DCE? When an organization migrates from networked computing to distributed computing a lot of factors are to be taken into consideration. For example replication of files gives rise to consistency problems, clock synchronization becomes important, and security is a bigger consideration. -

Cost Optimization Pillar AWS Well-Architected Framework
Cost Optimization Pillar AWS Well-Architected Framework July 2020 This paper has been archived. The latest version is now available at: https://docs.aws.amazon.com/wellarchitected/latest/cost-optimization-pillar/welcome.htmlArchived Notices Customers are responsible for making their own independent assessment of the information in this document. This document: (a) is for informational purposes only, (b) represents current AWS product offerings and practices, which are subject to change without notice, and (c) does not create any commitments or assurances from AWS and its affiliates, suppliers or licensors. AWS products or services are provided “as is” without warranties, representations, or conditions of any kind, whether express or implied. The responsibilities and liabilities of AWS to its customers are controlled by AWS agreements, and this document is not part of, nor does it modify, any agreement between AWS and its customers. © 2020 Amazon Web Services, Inc. or its affiliates. All rights reserved. Archived Contents Introduction .......................................................................................................................... 1 Cost Optimization ................................................................................................................ 2 Design Principles.............................................................................................................. 2 Definition .......................................................................................................................... -

Cost Optimization Pillar AWS Well-Architected Framework Cost Optimization Pillar AWS Well-Architected Framework
Cost Optimization Pillar AWS Well-Architected Framework Cost Optimization Pillar AWS Well-Architected Framework Cost Optimization Pillar: AWS Well-Architected Framework Copyright © Amazon Web Services, Inc. and/or its affiliates. All rights reserved. Amazon's trademarks and trade dress may not be used in connection with any product or service that is not Amazon's, in any manner that is likely to cause confusion among customers, or in any manner that disparages or discredits Amazon. All other trademarks not owned by Amazon are the property of their respective owners, who may or may not be affiliated with, connected to, or sponsored by Amazon. Cost Optimization Pillar AWS Well-Architected Framework Table of Contents Abstract and Introduction ................................................................................................................... 1 Abstract .................................................................................................................................... 1 Introduction .............................................................................................................................. 1 Cost Optimization .............................................................................................................................. 3 Design Principles ........................................................................................................................ 3 Definition ................................................................................................................................. -

GPU Nodes for GROMACS Biomolecular Simulations
Best bang for your buck: GPU nodes for GROMACS biomolecular simulations Carsten Kutzner,∗,† Szilárd Páll,‡ Martin Fechner,† Ansgar Esztermann,† Bert L. de Groot,† and Helmut Grubmüller† Theoretical and Computational Biophysics, Max Planck Institute for Biophysical Chemistry, Am Fassberg 11, 37077 Göttingen, Germany, and Theoretical and Computational Biophysics, KTH Royal Institute of Technology, 17121 Stockholm, Sweden E-mail: [email protected] Abstract The molecular dynamics simulation package GROMACS runs efficiently on a wide vari- ety of hardware from commodity workstations to high performance computing clusters. Hard- ware features are well exploited with a combination of SIMD, multi-threading, and MPI-based SPMD / MPMD parallelism, while GPUs can be used as accelerators to compute interactions offloaded from the CPU. Here we evaluate which hardware produces trajectories with GRO- arXiv:1507.00898v1 [cs.DC] 3 Jul 2015 MACS 4.6 or 5.0 in the most economical way. We have assembled and benchmarked com- pute nodes with various CPU / GPU combinations to identify optimal compositions in terms of raw trajectory production rate, performance-to-price ratio, energy efficiency, and several other criteria. Though hardware prices are naturally subject to trends and fluctuations, general ten- dencies are clearly visible. Adding any type of GPU significantly boosts a node’s simulation ∗To whom correspondence should be addressed †Theoretical and Computational Biophysics, Max Planck Institute for Biophysical Chemistry, Am Fassberg 11, 37077 Göttingen, Germany ‡Theoretical and Computational Biophysics, KTH Royal Institute of Technology, 17121 Stockholm, Sweden 1 performance. For inexpensive consumer-class GPUs this improvement equally reflects in the performance-to-price ratio. Although memory issues in consumer-class GPUs could pass un- noticed since these cards do not support ECC memory, unreliable GPUs can be sorted out with memory checking tools. -

PC Hardware Contents
PC Hardware Contents 1 Computer hardware 1 1.1 Von Neumann architecture ...................................... 1 1.2 Sales .................................................. 1 1.3 Different systems ........................................... 2 1.3.1 Personal computer ...................................... 2 1.3.2 Mainframe computer ..................................... 3 1.3.3 Departmental computing ................................... 4 1.3.4 Supercomputer ........................................ 4 1.4 See also ................................................ 4 1.5 References ............................................... 4 1.6 External links ............................................. 4 2 Central processing unit 5 2.1 History ................................................. 5 2.1.1 Transistor and integrated circuit CPUs ............................ 6 2.1.2 Microprocessors ....................................... 7 2.2 Operation ............................................... 8 2.2.1 Fetch ............................................. 8 2.2.2 Decode ............................................ 8 2.2.3 Execute ............................................ 9 2.3 Design and implementation ...................................... 9 2.3.1 Control unit .......................................... 9 2.3.2 Arithmetic logic unit ..................................... 9 2.3.3 Integer range ......................................... 10 2.3.4 Clock rate ........................................... 10 2.3.5 Parallelism .........................................