Macro Processing in Object-Oriented Languages
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Application of TRIE Data Structure and Corresponding Associative Algorithms for Process Optimization in GRID Environment
Application of TRIE data structure and corresponding associative algorithms for process optimization in GRID environment V. V. Kashanskya, I. L. Kaftannikovb South Ural State University (National Research University), 76, Lenin prospekt, Chelyabinsk, 454080, Russia E-mail: a [email protected], b [email protected] Growing interest around different BOINC powered projects made volunteer GRID model widely used last years, arranging lots of computational resources in different environments. There are many revealed problems of Big Data and horizontally scalable multiuser systems. This paper provides an analysis of TRIE data structure and possibilities of its application in contemporary volunteer GRID networks, including routing (L3 OSI) and spe- cialized key-value storage engine (L7 OSI). The main goal is to show how TRIE mechanisms can influence de- livery process of the corresponding GRID environment resources and services at different layers of networking abstraction. The relevance of the optimization topic is ensured by the fact that with increasing data flow intensi- ty, the latency of the various linear algorithm based subsystems as well increases. This leads to the general ef- fects, such as unacceptably high transmission time and processing instability. Logically paper can be divided into three parts with summary. The first part provides definition of TRIE and asymptotic estimates of corresponding algorithms (searching, deletion, insertion). The second part is devoted to the problem of routing time reduction by applying TRIE data structure. In particular, we analyze Cisco IOS switching services based on Bitwise TRIE and 256 way TRIE data structures. The third part contains general BOINC architecture review and recommenda- tions for highly-loaded projects. -

A New Macro-Programming Paradigm in Data Collection Sensor Networks
SpaceTime Oriented Programming: A New Macro-Programming Paradigm in Data Collection Sensor Networks Hiroshi Wada and Junichi Suzuki Department of Computer Science University of Massachusetts, Boston Program Insert This paper proposes a new programming paradigm for wireless sensor networks (WSNs). It is designed to significantly reduce the complexity of WSN programming by providing a new high- level programming abstraction to specify spatio-temporal data collections in a WSN from a global viewpoint as a whole rather than sensor nodes as individuals. Abstract SpaceTime Oriented Programming (STOP) is new macro-programming paradigm for wireless sensor networks (WSNs) in that it supports both spatial and temporal aspects of sensor data and it provides a high-level abstraction to express data collections from a global viewpoint for WSNs as a whole rather than sensor nodes as individuals. STOP treats space and time as first-class citizens and combines them as spacetime continuum. A spacetime is a three dimensional object that consists of a two special dimensions and a time playing the role of the third dimension. STOP allows application developers to program data collections to spacetime, and abstracts away the details in WSNs, such as how many nodes are deployed in a WSN, how nodes are connected with each other, and how to route data queries in a WSN. Moreover, STOP provides a uniform means to specify data collections for the past and future. Using the STOP application programming interfaces (APIs), application programs (STOP macro programs) can obtain a “snapshot” space at a given time in a given spatial resolutions (e.g., a space containing data on at least 60% of nodes in a give spacetime at 30 minutes ago.) and a discrete set of spaces that meet specified spatial and temporal resolutions. -

C Programming: Data Structures and Algorithms
C Programming: Data Structures and Algorithms An introduction to elementary programming concepts in C Jack Straub, Instructor Version 2.07 DRAFT C Programming: Data Structures and Algorithms, Version 2.07 DRAFT C Programming: Data Structures and Algorithms Version 2.07 DRAFT Copyright © 1996 through 2006 by Jack Straub ii 08/12/08 C Programming: Data Structures and Algorithms, Version 2.07 DRAFT Table of Contents COURSE OVERVIEW ........................................................................................ IX 1. BASICS.................................................................................................... 13 1.1 Objectives ...................................................................................................................................... 13 1.2 Typedef .......................................................................................................................................... 13 1.2.1 Typedef and Portability ............................................................................................................. 13 1.2.2 Typedef and Structures .............................................................................................................. 14 1.2.3 Typedef and Functions .............................................................................................................. 14 1.3 Pointers and Arrays ..................................................................................................................... 16 1.4 Dynamic Memory Allocation ..................................................................................................... -

Abstract Data Types
Chapter 2 Abstract Data Types The second idea at the core of computer science, along with algorithms, is data. In a modern computer, data consists fundamentally of binary bits, but meaningful data is organized into primitive data types such as integer, real, and boolean and into more complex data structures such as arrays and binary trees. These data types and data structures always come along with associated operations that can be done on the data. For example, the 32-bit int data type is defined both by the fact that a value of type int consists of 32 binary bits but also by the fact that two int values can be added, subtracted, multiplied, compared, and so on. An array is defined both by the fact that it is a sequence of data items of the same basic type, but also by the fact that it is possible to directly access each of the positions in the list based on its numerical index. So the idea of a data type includes a specification of the possible values of that type together with the operations that can be performed on those values. An algorithm is an abstract idea, and a program is an implementation of an algorithm. Similarly, it is useful to be able to work with the abstract idea behind a data type or data structure, without getting bogged down in the implementation details. The abstraction in this case is called an \abstract data type." An abstract data type specifies the values of the type, but not how those values are represented as collections of bits, and it specifies operations on those values in terms of their inputs, outputs, and effects rather than as particular algorithms or program code. -

Data Structures, Buffers, and Interprocess Communication
Data Structures, Buffers, and Interprocess Communication We’ve looked at several examples of interprocess communication involving the transfer of data from one process to another process. We know of three mechanisms that can be used for this transfer: - Files - Shared Memory - Message Passing The act of transferring data involves one process writing or sending a buffer, and another reading or receiving a buffer. Most of you seem to be getting the basic idea of sending and receiving data for IPC… it’s a lot like reading and writing to a file or stdin and stdout. What seems to be a little confusing though is HOW that data gets copied to a buffer for transmission, and HOW data gets copied out of a buffer after transmission. First… let’s look at a piece of data. typedef struct { char ticker[TICKER_SIZE]; double price; } item; . item next; . The data we want to focus on is “next”. “next” is an object of type “item”. “next” occupies memory in the process. What we’d like to do is send “next” from processA to processB via some kind of IPC. IPC Using File Streams If we were going to use good old C++ filestreams as the IPC mechanism, our code would look something like this to write the file: // processA is the sender… ofstream out; out.open(“myipcfile”); item next; strcpy(next.ticker,”ABC”); next.price = 55; out << next.ticker << “ “ << next.price << endl; out.close(); Notice that we didn’t do this: out << next << endl; Why? Because the “<<” operator doesn’t know what to do with an object of type “item”. -

SQL Processing with SAS® Tip Sheet
SQL Processing with SAS® Tip Sheet This tip sheet is associated with the SAS® Certified Professional Prep Guide Advanced Programming Using SAS® 9.4. For more information, visit www.sas.com/certify Basic Queries ModifyingBasic Queries Columns PROC SQL <options>; SELECT col-name SELECT column-1 <, ...column-n> LABEL= LABEL=’column label’ FROM input-table <WHERE expression> SELECT col-name <GROUP BY col-name> FORMAT= FORMAT=format. <HAVING expression> <ORDER BY col-name> <DESC> <,...col-name>; Creating a SELECT col-name AS SQL Query Order of Execution: new column new-col-name Filtering Clause Description WHERE CALCULATED new columns new-col-name SELECT Retrieve data from a table FROM Choose and join tables Modifying Rows WHERE Filter the data GROUP BY Aggregate the data INSERT INTO table SET column-name=value HAVING Filter the aggregate data <, ...column-name=value>; ORDER BY Sort the final data Inserting rows INSERT INTO table <(column-list)> into tables VALUES (value<,...value>); INSERT INTO table <(column-list)> Managing Tables SELECT column-1<,...column-n> FROM input-table; CREATE TABLE table-name Eliminating SELECT DISTINCT CREATE TABLE (column-specification-1<, duplicate rows col-name<,...col-name> ...column-specification-n>); WHERE col-name IN DESCRIBE TABLE table-name-1 DESCRIBE TABLE (value1, value2, ...) <,...table-name-n>; WHERE col-name LIKE “_string%” DROP TABLE table-name-1 DROP TABLE WHERE col-name BETWEEN <,...table-name-n>; Filtering value AND value rows WHERE col-name IS NULL WHERE date-value Managing Views “<01JAN2019>”d WHERE time-value “<14:45:35>”t CREATE VIEW CREATE VIEW table-name AS query; WHERE datetime-value “<01JAN201914:45:35>”dt DESCRIBE VIEW view-name-1 DESCRIBE VIEW <,...view-name-n>; Remerging Summary Statistics DROP VIEW DROP VIEW view-name-1 <,...view-name-n>; SELECT col-name, summary function(argument) FROM input table; Copyright © 2019 SAS Institute Inc. -

Subtyping Recursive Types
ACM Transactions on Programming Languages and Systems, 15(4), pp. 575-631, 1993. Subtyping Recursive Types Roberto M. Amadio1 Luca Cardelli CNRS-CRIN, Nancy DEC, Systems Research Center Abstract We investigate the interactions of subtyping and recursive types, in a simply typed λ-calculus. The two fundamental questions here are whether two (recursive) types are in the subtype relation, and whether a term has a type. To address the first question, we relate various definitions of type equivalence and subtyping that are induced by a model, an ordering on infinite trees, an algorithm, and a set of type rules. We show soundness and completeness between the rules, the algorithm, and the tree semantics. We also prove soundness and a restricted form of completeness for the model. To address the second question, we show that to every pair of types in the subtype relation we can associate a term whose denotation is the uniquely determined coercion map between the two types. Moreover, we derive an algorithm that, when given a term with implicit coercions, can infer its least type whenever possible. 1This author's work has been supported in part by Digital Equipment Corporation and in part by the Stanford-CNR Collaboration Project. Page 1 Contents 1. Introduction 1.1 Types 1.2 Subtypes 1.3 Equality of Recursive Types 1.4 Subtyping of Recursive Types 1.5 Algorithm outline 1.6 Formal development 2. A Simply Typed λ-calculus with Recursive Types 2.1 Types 2.2 Terms 2.3 Equations 3. Tree Ordering 3.1 Subtyping Non-recursive Types 3.2 Folding and Unfolding 3.3 Tree Expansion 3.4 Finite Approximations 4. -
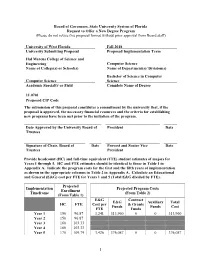
Attachment A
Board of Governors, State University System of Florida Request to Offer a New Degree Program (Please do not revise this proposal format without prior approval from Board staff) University of West Florida Fall 2018 University Submitting Proposal Proposed Implementation Term Hal Marcus College of Science and Engineering Computer Science Name of College(s) or School(s) Name of Department(s)/ Division(s) Bachelor of Science in Computer Computer Science Science Academic Specialty or Field Complete Name of Degree 11.0701 Proposed CIP Code The submission of this proposal constitutes a commitment by the university that, if the proposal is approved, the necessary financial resources and the criteria for establishing new programs have been met prior to the initiation of the program. Date Approved by the University Board of President Date Trustees Signature of Chair, Board of Date Provost and Senior Vice Date Trustees President Provide headcount (HC) and full-time equivalent (FTE) student estimates of majors for Years 1 through 5. HC and FTE estimates should be identical to those in Table 1 in Appendix A. Indicate the program costs for the first and the fifth years of implementation as shown in the appropriate columns in Table 2 in Appendix A. Calculate an Educational and General (E&G) cost per FTE for Years 1 and 5 (Total E&G divided by FTE). Projected Implementation Projected Program Costs Enrollment Timeframe (From Table 2) (From Table 1) E&G Contract E&G Auxiliary Total HC FTE Cost per & Grants Funds Funds Cost FTE Funds Year 1 150 96.87 3,241 313,960 0 0 313,960 Year 2 150 96.87 Year 3 160 103.33 Year 4 160 103.33 Year 5 170 109.79 3,426 376,087 0 0 376,087 1 Note: This outline and the questions pertaining to each section must be reproduced within the body of the proposal to ensure that all sections have been satisfactorily addressed. -

4 Hash Tables and Associative Arrays
4 FREE Hash Tables and Associative Arrays If you want to get a book from the central library of the University of Karlsruhe, you have to order the book in advance. The library personnel fetch the book from the stacks and deliver it to a room with 100 shelves. You find your book on a shelf numbered with the last two digits of your library card. Why the last digits and not the leading digits? Probably because this distributes the books more evenly among the shelves. The library cards are numbered consecutively as students sign up, and the University of Karlsruhe was founded in 1825. Therefore, the students enrolled at the same time are likely to have the same leading digits in their card number, and only a few shelves would be in use if the leadingCOPY digits were used. The subject of this chapter is the robust and efficient implementation of the above “delivery shelf data structure”. In computer science, this data structure is known as a hash1 table. Hash tables are one implementation of associative arrays, or dictio- naries. The other implementation is the tree data structures which we shall study in Chap. 7. An associative array is an array with a potentially infinite or at least very large index set, out of which only a small number of indices are actually in use. For example, the potential indices may be all strings, and the indices in use may be all identifiers used in a particular C++ program.Or the potential indices may be all ways of placing chess pieces on a chess board, and the indices in use may be the place- ments required in the analysis of a particular game. -

The Circle Meta-Model
Document:P2062R0 Revises: (original) Date: 01-11-2020 Audience: SG7 Authors: Wyatt Childers ([email protected]) Andrew Sutton ([email protected]) Faisal Vali ([email protected]) Daveed Vandevoorde ([email protected]) The Circle Meta-model Introduction During the November 2019 meeting in Belfast, some of the SG7 participants enthusiastically mentioned Circle1 as providing a more intuitive compile-time programming model and suggested that SG7 investigate overhauling the de-facto SG7 approach (P1240+P17332) to follow Circle's general approach (to reflection and metaprogramming). This paper describes a framework for understanding metaprogramming systems and provides a high-level overview of some of Circle's main characteristics, contrasting them to P1240's approach augmented with an injection mechanism along the lines of P1717. While we appreciate some of Circle’s powerful capabilities, we also raise some concerns with its underlying model and provide arguments in support of P1240’s choices as being a more suitable fit for C++’s evolution. The Dimensions of Reflective Programming In P0633, we identified three “dimensions” of compile-time reflective metaprogramming: 1. Control: How are compile-time computations effected/interpreted? What are metaprograms? 2. Reflection: How are source constructs are made available as data for use in metaprograms? 3. Synthesis: How can “code” be generated from a programmatic representation? 1 https://www.circle-lang.org/ Circle is an impressive project: Sean Baxter developed a brand new C++17-like front end on top of LLVM, incorporating a variety of new compile-time capabilities that align closely with SG7's goals. For Sean’s motivations, see https://github.com/seanbaxter/circle/blob/master/examples/README.md#why-i-wrote-circle. -

Comparative Studies of Programming Languages; Course Lecture Notes
Comparative Studies of Programming Languages, COMP6411 Lecture Notes, Revision 1.9 Joey Paquet Serguei A. Mokhov (Eds.) August 5, 2010 arXiv:1007.2123v6 [cs.PL] 4 Aug 2010 2 Preface Lecture notes for the Comparative Studies of Programming Languages course, COMP6411, taught at the Department of Computer Science and Software Engineering, Faculty of Engineering and Computer Science, Concordia University, Montreal, QC, Canada. These notes include a compiled book of primarily related articles from the Wikipedia, the Free Encyclopedia [24], as well as Comparative Programming Languages book [7] and other resources, including our own. The original notes were compiled by Dr. Paquet [14] 3 4 Contents 1 Brief History and Genealogy of Programming Languages 7 1.1 Introduction . 7 1.1.1 Subreferences . 7 1.2 History . 7 1.2.1 Pre-computer era . 7 1.2.2 Subreferences . 8 1.2.3 Early computer era . 8 1.2.4 Subreferences . 8 1.2.5 Modern/Structured programming languages . 9 1.3 References . 19 2 Programming Paradigms 21 2.1 Introduction . 21 2.2 History . 21 2.2.1 Low-level: binary, assembly . 21 2.2.2 Procedural programming . 22 2.2.3 Object-oriented programming . 23 2.2.4 Declarative programming . 27 3 Program Evaluation 33 3.1 Program analysis and translation phases . 33 3.1.1 Front end . 33 3.1.2 Back end . 34 3.2 Compilation vs. interpretation . 34 3.2.1 Compilation . 34 3.2.2 Interpretation . 36 3.2.3 Subreferences . 37 3.3 Type System . 38 3.3.1 Type checking . 38 3.4 Memory management . -

CSE 307: Principles of Programming Languages Classes and Inheritance
OOP Introduction Type & Subtype Inheritance Overloading and Overriding CSE 307: Principles of Programming Languages Classes and Inheritance R. Sekar 1 / 52 OOP Introduction Type & Subtype Inheritance Overloading and Overriding Topics 1. OOP Introduction 3. Inheritance 2. Type & Subtype 4. Overloading and Overriding 2 / 52 OOP Introduction Type & Subtype Inheritance Overloading and Overriding Section 1 OOP Introduction 3 / 52 OOP Introduction Type & Subtype Inheritance Overloading and Overriding OOP (Object Oriented Programming) So far the languages that we encountered treat data and computation separately. In OOP, the data and computation are combined into an “object”. 4 / 52 OOP Introduction Type & Subtype Inheritance Overloading and Overriding Benefits of OOP more convenient: collects related information together, rather than distributing it. Example: C++ iostream class collects all I/O related operations together into one central place. Contrast with C I/O library, which consists of many distinct functions such as getchar, printf, scanf, sscanf, etc. centralizes and regulates access to data. If there is an error that corrupts object data, we need to look for the error only within its class Contrast with C programs, where access/modification code is distributed throughout the program 5 / 52 OOP Introduction Type & Subtype Inheritance Overloading and Overriding Benefits of OOP (Continued) Promotes reuse. by separating interface from implementation. We can replace the implementation of an object without changing client code. Contrast with C, where the implementation of a data structure such as a linked list is integrated into the client code by permitting extension of new objects via inheritance. Inheritance allows a new class to reuse the features of an existing class.