1 Abstract Data Types, Cost Specifications, and Data Structures
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Application of TRIE Data Structure and Corresponding Associative Algorithms for Process Optimization in GRID Environment
Application of TRIE data structure and corresponding associative algorithms for process optimization in GRID environment V. V. Kashanskya, I. L. Kaftannikovb South Ural State University (National Research University), 76, Lenin prospekt, Chelyabinsk, 454080, Russia E-mail: a [email protected], b [email protected] Growing interest around different BOINC powered projects made volunteer GRID model widely used last years, arranging lots of computational resources in different environments. There are many revealed problems of Big Data and horizontally scalable multiuser systems. This paper provides an analysis of TRIE data structure and possibilities of its application in contemporary volunteer GRID networks, including routing (L3 OSI) and spe- cialized key-value storage engine (L7 OSI). The main goal is to show how TRIE mechanisms can influence de- livery process of the corresponding GRID environment resources and services at different layers of networking abstraction. The relevance of the optimization topic is ensured by the fact that with increasing data flow intensi- ty, the latency of the various linear algorithm based subsystems as well increases. This leads to the general ef- fects, such as unacceptably high transmission time and processing instability. Logically paper can be divided into three parts with summary. The first part provides definition of TRIE and asymptotic estimates of corresponding algorithms (searching, deletion, insertion). The second part is devoted to the problem of routing time reduction by applying TRIE data structure. In particular, we analyze Cisco IOS switching services based on Bitwise TRIE and 256 way TRIE data structures. The third part contains general BOINC architecture review and recommenda- tions for highly-loaded projects. -

C Programming: Data Structures and Algorithms
C Programming: Data Structures and Algorithms An introduction to elementary programming concepts in C Jack Straub, Instructor Version 2.07 DRAFT C Programming: Data Structures and Algorithms, Version 2.07 DRAFT C Programming: Data Structures and Algorithms Version 2.07 DRAFT Copyright © 1996 through 2006 by Jack Straub ii 08/12/08 C Programming: Data Structures and Algorithms, Version 2.07 DRAFT Table of Contents COURSE OVERVIEW ........................................................................................ IX 1. BASICS.................................................................................................... 13 1.1 Objectives ...................................................................................................................................... 13 1.2 Typedef .......................................................................................................................................... 13 1.2.1 Typedef and Portability ............................................................................................................. 13 1.2.2 Typedef and Structures .............................................................................................................. 14 1.2.3 Typedef and Functions .............................................................................................................. 14 1.3 Pointers and Arrays ..................................................................................................................... 16 1.4 Dynamic Memory Allocation ..................................................................................................... -

Abstract Data Types
Chapter 2 Abstract Data Types The second idea at the core of computer science, along with algorithms, is data. In a modern computer, data consists fundamentally of binary bits, but meaningful data is organized into primitive data types such as integer, real, and boolean and into more complex data structures such as arrays and binary trees. These data types and data structures always come along with associated operations that can be done on the data. For example, the 32-bit int data type is defined both by the fact that a value of type int consists of 32 binary bits but also by the fact that two int values can be added, subtracted, multiplied, compared, and so on. An array is defined both by the fact that it is a sequence of data items of the same basic type, but also by the fact that it is possible to directly access each of the positions in the list based on its numerical index. So the idea of a data type includes a specification of the possible values of that type together with the operations that can be performed on those values. An algorithm is an abstract idea, and a program is an implementation of an algorithm. Similarly, it is useful to be able to work with the abstract idea behind a data type or data structure, without getting bogged down in the implementation details. The abstraction in this case is called an \abstract data type." An abstract data type specifies the values of the type, but not how those values are represented as collections of bits, and it specifies operations on those values in terms of their inputs, outputs, and effects rather than as particular algorithms or program code. -

Data Structures, Buffers, and Interprocess Communication
Data Structures, Buffers, and Interprocess Communication We’ve looked at several examples of interprocess communication involving the transfer of data from one process to another process. We know of three mechanisms that can be used for this transfer: - Files - Shared Memory - Message Passing The act of transferring data involves one process writing or sending a buffer, and another reading or receiving a buffer. Most of you seem to be getting the basic idea of sending and receiving data for IPC… it’s a lot like reading and writing to a file or stdin and stdout. What seems to be a little confusing though is HOW that data gets copied to a buffer for transmission, and HOW data gets copied out of a buffer after transmission. First… let’s look at a piece of data. typedef struct { char ticker[TICKER_SIZE]; double price; } item; . item next; . The data we want to focus on is “next”. “next” is an object of type “item”. “next” occupies memory in the process. What we’d like to do is send “next” from processA to processB via some kind of IPC. IPC Using File Streams If we were going to use good old C++ filestreams as the IPC mechanism, our code would look something like this to write the file: // processA is the sender… ofstream out; out.open(“myipcfile”); item next; strcpy(next.ticker,”ABC”); next.price = 55; out << next.ticker << “ “ << next.price << endl; out.close(); Notice that we didn’t do this: out << next << endl; Why? Because the “<<” operator doesn’t know what to do with an object of type “item”. -

Subtyping Recursive Types
ACM Transactions on Programming Languages and Systems, 15(4), pp. 575-631, 1993. Subtyping Recursive Types Roberto M. Amadio1 Luca Cardelli CNRS-CRIN, Nancy DEC, Systems Research Center Abstract We investigate the interactions of subtyping and recursive types, in a simply typed λ-calculus. The two fundamental questions here are whether two (recursive) types are in the subtype relation, and whether a term has a type. To address the first question, we relate various definitions of type equivalence and subtyping that are induced by a model, an ordering on infinite trees, an algorithm, and a set of type rules. We show soundness and completeness between the rules, the algorithm, and the tree semantics. We also prove soundness and a restricted form of completeness for the model. To address the second question, we show that to every pair of types in the subtype relation we can associate a term whose denotation is the uniquely determined coercion map between the two types. Moreover, we derive an algorithm that, when given a term with implicit coercions, can infer its least type whenever possible. 1This author's work has been supported in part by Digital Equipment Corporation and in part by the Stanford-CNR Collaboration Project. Page 1 Contents 1. Introduction 1.1 Types 1.2 Subtypes 1.3 Equality of Recursive Types 1.4 Subtyping of Recursive Types 1.5 Algorithm outline 1.6 Formal development 2. A Simply Typed λ-calculus with Recursive Types 2.1 Types 2.2 Terms 2.3 Equations 3. Tree Ordering 3.1 Subtyping Non-recursive Types 3.2 Folding and Unfolding 3.3 Tree Expansion 3.4 Finite Approximations 4. -

4 Hash Tables and Associative Arrays
4 FREE Hash Tables and Associative Arrays If you want to get a book from the central library of the University of Karlsruhe, you have to order the book in advance. The library personnel fetch the book from the stacks and deliver it to a room with 100 shelves. You find your book on a shelf numbered with the last two digits of your library card. Why the last digits and not the leading digits? Probably because this distributes the books more evenly among the shelves. The library cards are numbered consecutively as students sign up, and the University of Karlsruhe was founded in 1825. Therefore, the students enrolled at the same time are likely to have the same leading digits in their card number, and only a few shelves would be in use if the leadingCOPY digits were used. The subject of this chapter is the robust and efficient implementation of the above “delivery shelf data structure”. In computer science, this data structure is known as a hash1 table. Hash tables are one implementation of associative arrays, or dictio- naries. The other implementation is the tree data structures which we shall study in Chap. 7. An associative array is an array with a potentially infinite or at least very large index set, out of which only a small number of indices are actually in use. For example, the potential indices may be all strings, and the indices in use may be all identifiers used in a particular C++ program.Or the potential indices may be all ways of placing chess pieces on a chess board, and the indices in use may be the place- ments required in the analysis of a particular game. -

CSE 307: Principles of Programming Languages Classes and Inheritance
OOP Introduction Type & Subtype Inheritance Overloading and Overriding CSE 307: Principles of Programming Languages Classes and Inheritance R. Sekar 1 / 52 OOP Introduction Type & Subtype Inheritance Overloading and Overriding Topics 1. OOP Introduction 3. Inheritance 2. Type & Subtype 4. Overloading and Overriding 2 / 52 OOP Introduction Type & Subtype Inheritance Overloading and Overriding Section 1 OOP Introduction 3 / 52 OOP Introduction Type & Subtype Inheritance Overloading and Overriding OOP (Object Oriented Programming) So far the languages that we encountered treat data and computation separately. In OOP, the data and computation are combined into an “object”. 4 / 52 OOP Introduction Type & Subtype Inheritance Overloading and Overriding Benefits of OOP more convenient: collects related information together, rather than distributing it. Example: C++ iostream class collects all I/O related operations together into one central place. Contrast with C I/O library, which consists of many distinct functions such as getchar, printf, scanf, sscanf, etc. centralizes and regulates access to data. If there is an error that corrupts object data, we need to look for the error only within its class Contrast with C programs, where access/modification code is distributed throughout the program 5 / 52 OOP Introduction Type & Subtype Inheritance Overloading and Overriding Benefits of OOP (Continued) Promotes reuse. by separating interface from implementation. We can replace the implementation of an object without changing client code. Contrast with C, where the implementation of a data structure such as a linked list is integrated into the client code by permitting extension of new objects via inheritance. Inheritance allows a new class to reuse the features of an existing class. -

Data Structures Using “C”
DATA STRUCTURES USING “C” DATA STRUCTURES USING “C” LECTURE NOTES Prepared by Dr. Subasish Mohapatra Department of Computer Science and Application College of Engineering and Technology, Bhubaneswar Biju Patnaik University of Technology, Odisha SYLLABUS BE 2106 DATA STRUCTURE (3-0-0) Module – I Introduction to data structures: storage structure for arrays, sparse matrices, Stacks and Queues: representation and application. Linked lists: Single linked lists, linked list representation of stacks and Queues. Operations on polynomials, Double linked list, circular list. Module – II Dynamic storage management-garbage collection and compaction, infix to post fix conversion, postfix expression evaluation. Trees: Tree terminology, Binary tree, Binary search tree, General tree, B+ tree, AVL Tree, Complete Binary Tree representation, Tree traversals, operation on Binary tree-expression Manipulation. Module –III Graphs: Graph terminology, Representation of graphs, path matrix, BFS (breadth first search), DFS (depth first search), topological sorting, Warshall’s algorithm (shortest path algorithm.) Sorting and Searching techniques – Bubble sort, selection sort, Insertion sort, Quick sort, merge sort, Heap sort, Radix sort. Linear and binary search methods, Hashing techniques and hash functions. Text Books: 1. Gilberg and Forouzan: “Data Structure- A Pseudo code approach with C” by Thomson publication 2. “Data structure in C” by Tanenbaum, PHI publication / Pearson publication. 3. Pai: ”Data Structures & Algorithms; Concepts, Techniques & Algorithms -

A Metaobject Protocol for Fault-Tolerant CORBA Applications
A Metaobject Protocol for Fault-Tolerant CORBA Applications Marc-Olivier Killijian*, Jean-Charles Fabre*, Juan-Carlos Ruiz-Garcia*, Shigeru Chiba** *LAAS-CNRS, 7 Avenue du Colonel Roche **Institute of Information Science and 31077 Toulouse cedex, France Electronics, University of Tsukuba, Tennodai, Tsukuba, Ibaraki 305-8573, Japan Abstract The corner stone of a fault-tolerant reflective The use of metalevel architectures for the architecture is the MOP. We thus propose a special implementation of fault-tolerant systems is today very purpose MOP to address the problems of general-purpose appealing. Nevertheless, all such fault-tolerant systems ones. We show that compile-time reflection is a good have used a general-purpose metaobject protocol (MOP) approach for developing a specialized runtime MOP. or are based on restricted reflective features of some The definition and the implementation of an object-oriented language. According to our past appropriate runtime metaobject protocol for implementing experience, we define in this paper a suitable metaobject fault tolerance into CORBA applications is the main protocol, called FT-MOP for building fault-tolerant contribution of the work reported in this paper. This systems. We explain how to realize a specialized runtime MOP, called FT-MOP (Fault Tolerance - MetaObject MOP using compile-time reflection. This MOP is CORBA Protocol), is sufficiently general to be used for other aims compliant: it enables the execution and the state evolution (mobility, adaptability, migration, security). FT-MOP of CORBA objects to be controlled and enables the fault provides a mean to attach dynamically fault tolerance tolerance metalevel to be developed as CORBA software. strategies to CORBA objects as CORBA metaobjects, enabling thus these strategies to be implemented as 1 . -

Tries and String Matching
Tries and String Matching Where We've Been ● Fundamental Data Structures ● Red/black trees, B-trees, RMQ, etc. ● Isometries ● Red/black trees ≡ 2-3-4 trees, binomial heaps ≡ binary numbers, etc. ● Amortized Analysis ● Aggregate, banker's, and potential methods. Where We're Going ● String Data Structures ● Data structures for storing and manipulating text. ● Randomized Data Structures ● Using randomness as a building block. ● Integer Data Structures ● Breaking the Ω(n log n) sorting barrier. ● Dynamic Connectivity ● Maintaining connectivity in an changing world. String Data Structures Text Processing ● String processing shows up everywhere: ● Computational biology: Manipulating DNA sequences. ● NLP: Storing and organizing huge text databases. ● Computer security: Building antivirus databases. ● Many problems have polynomial-time solutions. ● Goal: Design theoretically and practically efficient algorithms that outperform brute-force approaches. Outline for Today ● Tries ● A fundamental building block in string processing algorithms. ● Aho-Corasick String Matching ● A fast and elegant algorithm for searching large texts for known substrings. Tries Ordered Dictionaries ● Suppose we want to store a set of elements supporting the following operations: ● Insertion of new elements. ● Deletion of old elements. ● Membership queries. ● Successor queries. ● Predecessor queries. ● Min/max queries. ● Can use a standard red/black tree or splay tree to get (worst-case or expected) O(log n) implementations of each. A Catch ● Suppose we want to store a set of strings. ● Comparing two strings of lengths r and s takes time O(min{r, s}). ● Operations on a balanced BST or splay tree now take time O(M log n), where M is the length of the longest string in the tree. -

Space-Efficient Data Structures for String Searching and Retrieval
Louisiana State University LSU Digital Commons LSU Doctoral Dissertations Graduate School 2014 Space-efficient data structures for string searching and retrieval Sharma Valliyil Thankachan Louisiana State University and Agricultural and Mechanical College, [email protected] Follow this and additional works at: https://digitalcommons.lsu.edu/gradschool_dissertations Part of the Computer Sciences Commons Recommended Citation Valliyil Thankachan, Sharma, "Space-efficient data structures for string searching and retrieval" (2014). LSU Doctoral Dissertations. 2848. https://digitalcommons.lsu.edu/gradschool_dissertations/2848 This Dissertation is brought to you for free and open access by the Graduate School at LSU Digital Commons. It has been accepted for inclusion in LSU Doctoral Dissertations by an authorized graduate school editor of LSU Digital Commons. For more information, please [email protected]. SPACE-EFFICIENT DATA STRUCTURES FOR STRING SEARCHING AND RETRIEVAL A Dissertation Submitted to the Graduate Faculty of the Louisiana State University and Agricultural and Mechanical College in partial fulfillment of the requirements for the degree of Doctor of Philosophy in The Department of Computer Science by Sharma Valliyil Thankachan B.Tech., National Institute of Technology Calicut, 2006 May 2014 Dedicated to the memory of my Grandfather. ii Acknowledgments This thesis would not have been possible without the time and effort of few people, who believed in me, instilled in me the courage to move forward and lent a supportive shoulder in times of uncertainty. I would like to express here how much it all meant to me. First and foremost, I would like to extend my sincerest gratitude to my advisor Dr. Rahul Shah. I would have hardly imagined that a fortuitous encounter in an online puzzle forum with Rahul, would set the stage for a career in theoretical computer science. -
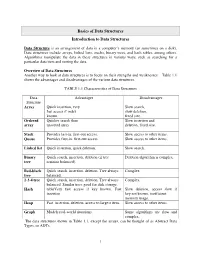
Basics of Data Structures Introduction to Data Structures
Basics of Data Structures Introduction to Data Structures Data Structure is an arrangement of data in a computer’s memory (or sometimes on a disk). Data structures include arrays, linked lists, stacks, binary trees, and hash tables, among others. Algorithms manipulate the data in these structures in various ways, such as searching for a particular data item and sorting the data. Overview of Data Structures Another way to look at data structures is to focus on their strengths and weaknesses. Table 1.1 shows the advantages and disadvantages of the various data structures. TABLE 1.1 Characteristics of Data Structures Data Advantages Disadvantages Structure Array Quick insertion, very Slow search, fast access if index slow deletion, known. fixed size. Ordered Quicker search than Slow insertion and array unsorted array deletion, fixed size. Stack Provides last-in, first-out access. Slow access to other items. Queue Provides first-in, first-out access. Slow access to other items. Linked list Quick insertion, quick deletion. Slow search. Binary Quick search, insertion, deletion (if tree Deletion algorithm is complex. tree remains balanced). Red-black Quick search, insertion, deletion. Tree always Complex. tree balanced. 2-3-4 tree Quick search, insertion, deletion. Tree always Complex. balanced. Similar trees good for disk storage. Hash tableVery fast access if key known. Fast Slow deletion, access slow if insertion key not known, inefficient memory usage. Heap Fast insertion, deletion, access to largest item. Slow access to other items. Graph Models real-world situations. Some algorithms are slow and complex. The data structures shown in Table 1.1, except the arrays, can be thought of as Abstract Data Types, or ADTs.