Directly Reflective Meta-Programming
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Document Number Scco24
Stanford University Libraries Dept. of Special Cr*l!«ctkjns &>W Title Box Series I Fol 5C Fo<. Title " LISP/360 REFERENCE MANUAL FOURTH EDITION # CAMPUS COMPUTER FACILITY STANFORD COMPUTATION CENTER STANFORD UNIVERSITY STANFORD, CALIFORNIA DOCUMENT NUMBER SCCO24 " ■ " PREFACE This manual is intended to provide the LISP 1.5 user with a reference manual for the LISP 1.5 interpreter, assembler, and compiler on the Campus Facility 360/67. It assumes that the reader has a working knowledge by of LISP 1.5 as described in the LISP_I.is_Primer Clark Weissman, and that the reader has a general knowledge of the operating environment of OS 360. Beginning users of LISP will find the sections The , Functions, LI SRZIi O_Syst em , Organiz ation_of_St orage tlSP_Job_Set-]i£» and t.tsp/360 System Messages Host helpful in obtaining a basic understanding of the LISP system. Other sections of the manual are intended for users desiring a more extensive knowledge of LISP. The particular implementation to which this reference manual is directed was started by Mr. J. Kent while he was at the University of Waterloo. It is modeled after his implemention of LISP 1.5 for the CDC 3600. Included in this edition is information on the use of the time-shared LISP system available on the 360/67 which was implemented by Mr. Robert Berns of the " Computer staff. Campus Facility " II TABLE OF CONTENTS Section PREFACE " TABLE OF CONTENTS xxx 1. THE LISP/360 SYSTEM 1 2. ORGANIZATION OF STORAGE 3 2.1 Free Cell Storage (FCS) 3 2.1.1 Atoms 5 2.1.2 Numbers 8 2.1.3 Object List 9 2.2 Push-down Stack (PDS) 9 2.3 System Functions 9 2.4 Binary Program Space (BPS) 9 W 2.5 Input/Output Buffers 9 10 3. -

The Evolution of Lisp
1 The Evolution of Lisp Guy L. Steele Jr. Richard P. Gabriel Thinking Machines Corporation Lucid, Inc. 245 First Street 707 Laurel Street Cambridge, Massachusetts 02142 Menlo Park, California 94025 Phone: (617) 234-2860 Phone: (415) 329-8400 FAX: (617) 243-4444 FAX: (415) 329-8480 E-mail: [email protected] E-mail: [email protected] Abstract Lisp is the world’s greatest programming language—or so its proponents think. The structure of Lisp makes it easy to extend the language or even to implement entirely new dialects without starting from scratch. Overall, the evolution of Lisp has been guided more by institutional rivalry, one-upsmanship, and the glee born of technical cleverness that is characteristic of the “hacker culture” than by sober assessments of technical requirements. Nevertheless this process has eventually produced both an industrial- strength programming language, messy but powerful, and a technically pure dialect, small but powerful, that is suitable for use by programming-language theoreticians. We pick up where McCarthy’s paper in the first HOPL conference left off. We trace the development chronologically from the era of the PDP-6, through the heyday of Interlisp and MacLisp, past the ascension and decline of special purpose Lisp machines, to the present era of standardization activities. We then examine the technical evolution of a few representative language features, including both some notable successes and some notable failures, that illuminate design issues that distinguish Lisp from other programming languages. We also discuss the use of Lisp as a laboratory for designing other programming languages. We conclude with some reflections on the forces that have driven the evolution of Lisp. -
Attachment A
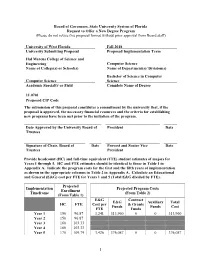
Board of Governors, State University System of Florida Request to Offer a New Degree Program (Please do not revise this proposal format without prior approval from Board staff) University of West Florida Fall 2018 University Submitting Proposal Proposed Implementation Term Hal Marcus College of Science and Engineering Computer Science Name of College(s) or School(s) Name of Department(s)/ Division(s) Bachelor of Science in Computer Computer Science Science Academic Specialty or Field Complete Name of Degree 11.0701 Proposed CIP Code The submission of this proposal constitutes a commitment by the university that, if the proposal is approved, the necessary financial resources and the criteria for establishing new programs have been met prior to the initiation of the program. Date Approved by the University Board of President Date Trustees Signature of Chair, Board of Date Provost and Senior Vice Date Trustees President Provide headcount (HC) and full-time equivalent (FTE) student estimates of majors for Years 1 through 5. HC and FTE estimates should be identical to those in Table 1 in Appendix A. Indicate the program costs for the first and the fifth years of implementation as shown in the appropriate columns in Table 2 in Appendix A. Calculate an Educational and General (E&G) cost per FTE for Years 1 and 5 (Total E&G divided by FTE). Projected Implementation Projected Program Costs Enrollment Timeframe (From Table 2) (From Table 1) E&G Contract E&G Auxiliary Total HC FTE Cost per & Grants Funds Funds Cost FTE Funds Year 1 150 96.87 3,241 313,960 0 0 313,960 Year 2 150 96.87 Year 3 160 103.33 Year 4 160 103.33 Year 5 170 109.79 3,426 376,087 0 0 376,087 1 Note: This outline and the questions pertaining to each section must be reproduced within the body of the proposal to ensure that all sections have been satisfactorily addressed. -

The Circle Meta-Model
Document:P2062R0 Revises: (original) Date: 01-11-2020 Audience: SG7 Authors: Wyatt Childers ([email protected]) Andrew Sutton ([email protected]) Faisal Vali ([email protected]) Daveed Vandevoorde ([email protected]) The Circle Meta-model Introduction During the November 2019 meeting in Belfast, some of the SG7 participants enthusiastically mentioned Circle1 as providing a more intuitive compile-time programming model and suggested that SG7 investigate overhauling the de-facto SG7 approach (P1240+P17332) to follow Circle's general approach (to reflection and metaprogramming). This paper describes a framework for understanding metaprogramming systems and provides a high-level overview of some of Circle's main characteristics, contrasting them to P1240's approach augmented with an injection mechanism along the lines of P1717. While we appreciate some of Circle’s powerful capabilities, we also raise some concerns with its underlying model and provide arguments in support of P1240’s choices as being a more suitable fit for C++’s evolution. The Dimensions of Reflective Programming In P0633, we identified three “dimensions” of compile-time reflective metaprogramming: 1. Control: How are compile-time computations effected/interpreted? What are metaprograms? 2. Reflection: How are source constructs are made available as data for use in metaprograms? 3. Synthesis: How can “code” be generated from a programmatic representation? 1 https://www.circle-lang.org/ Circle is an impressive project: Sean Baxter developed a brand new C++17-like front end on top of LLVM, incorporating a variety of new compile-time capabilities that align closely with SG7's goals. For Sean’s motivations, see https://github.com/seanbaxter/circle/blob/master/examples/README.md#why-i-wrote-circle. -

Implementing a Vau-Based Language with Multiple Evaluation Strategies
Implementing a Vau-based Language With Multiple Evaluation Strategies Logan Kearsley Brigham Young University Introduction Vau expressions can be simply defined as functions which do not evaluate their argument expressions when called, but instead provide access to a reification of the calling environment to explicitly evaluate arguments later, and are a form of statically-scoped fexpr (Shutt, 2010). Control over when and if arguments are evaluated allows vau expressions to be used to simulate any evaluation strategy. Additionally, the ability to choose not to evaluate certain arguments to inspect the syntactic structure of unevaluated arguments allows vau expressions to simulate macros at run-time and to replace many syntactic constructs that otherwise have to be built-in to a language implementation. In principle, this allows for significant simplification of the interpreter for vau expressions; compared to McCarthy's original LISP definition (McCarthy, 1960), vau's eval function removes all references to built-in functions or syntactic forms, and alters function calls to skip argument evaluation and add an implicit env parameter (in real implementations, the name of the environment parameter is customizable in a function definition, rather than being a keyword built-in to the language). McCarthy's Eval Function Vau Eval Function (transformed from the original M-expressions into more familiar s-expressions) (define (eval e a) (define (eval e a) (cond (cond ((atom e) (assoc e a)) ((atom e) (assoc e a)) ((atom (car e)) ((atom (car e)) (cond (eval (cons (assoc (car e) a) ((eq (car e) 'quote) (cadr e)) (cdr e)) ((eq (car e) 'atom) (atom (eval (cadr e) a))) a)) ((eq (car e) 'eq) (eq (eval (cadr e) a) ((eq (caar e) 'vau) (eval (caddr e) a))) (eval (caddar e) ((eq (car e) 'car) (car (eval (cadr e) a))) (cons (cons (cadar e) 'env) ((eq (car e) 'cdr) (cdr (eval (cadr e) a))) (append (pair (cadar e) (cdr e)) ((eq (car e) 'cons) (cons (eval (cadr e) a) a)))))) (eval (caddr e) a))) ((eq (car e) 'cond) (evcon. -

Comparative Studies of Programming Languages; Course Lecture Notes
Comparative Studies of Programming Languages, COMP6411 Lecture Notes, Revision 1.9 Joey Paquet Serguei A. Mokhov (Eds.) August 5, 2010 arXiv:1007.2123v6 [cs.PL] 4 Aug 2010 2 Preface Lecture notes for the Comparative Studies of Programming Languages course, COMP6411, taught at the Department of Computer Science and Software Engineering, Faculty of Engineering and Computer Science, Concordia University, Montreal, QC, Canada. These notes include a compiled book of primarily related articles from the Wikipedia, the Free Encyclopedia [24], as well as Comparative Programming Languages book [7] and other resources, including our own. The original notes were compiled by Dr. Paquet [14] 3 4 Contents 1 Brief History and Genealogy of Programming Languages 7 1.1 Introduction . 7 1.1.1 Subreferences . 7 1.2 History . 7 1.2.1 Pre-computer era . 7 1.2.2 Subreferences . 8 1.2.3 Early computer era . 8 1.2.4 Subreferences . 8 1.2.5 Modern/Structured programming languages . 9 1.3 References . 19 2 Programming Paradigms 21 2.1 Introduction . 21 2.2 History . 21 2.2.1 Low-level: binary, assembly . 21 2.2.2 Procedural programming . 22 2.2.3 Object-oriented programming . 23 2.2.4 Declarative programming . 27 3 Program Evaluation 33 3.1 Program analysis and translation phases . 33 3.1.1 Front end . 33 3.1.2 Back end . 34 3.2 Compilation vs. interpretation . 34 3.2.1 Compilation . 34 3.2.2 Interpretation . 36 3.2.3 Subreferences . 37 3.3 Type System . 38 3.3.1 Type checking . 38 3.4 Memory management . -

Sub-Method Structural and Behavioral Reflection Marcus Denker
Sub-method Structural and Behavioral Reflection Marcus Denker To cite this version: Marcus Denker. Sub-method Structural and Behavioral Reflection. Computer Science [cs]. Universität Bern, 2008. English. tel-00555937 HAL Id: tel-00555937 https://tel.archives-ouvertes.fr/tel-00555937 Submitted on 14 Jan 2011 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Sub-method Structural and Behavioral Reflection Inauguraldissertation der Philosophisch-naturwissenschaftlichen Fakultät der Universität Bern vorgelegt von Marcus Denker von Deutschland Leiter der Arbeit: Prof. Dr. O. Nierstrasz Institut für Informatik und angewandte Mathematik Von der Philosophisch-naturwissenschaftlichen Fakultät angenommen. Bern, 26.05.2008 Der Dekan: Prof. Dr. P. Messerli This dissertation is available as a free download from http://scg.unibe.ch Copyright © 2008 Marcus Denker. The contents of this dissertation are protected under Creative Commons Attribution-ShareAlike 3.0 Unported license. You are free: to Share — to copy, distribute and transmit the work to Remix — to adapt the work Under the following conditions: Attribution. You must attribute the work in the manner specified by the author or licensor (but not in any way that suggests that they endorse you or your use of the work). -

Obstacles to Compilation of Rebol Programs
Obstacles to Compilation of Rebol Programs Viktor Pavlu TU Wien Institute of Computer Aided Automation, Computer Vision Lab A-1040 Vienna, Favoritenstr. 9/183-2, Austria [email protected] Abstract. Rebol’s syntax has no explicit delimiters around function arguments; all values in Rebol are first-class; Rebol uses fexprs as means of dynamic syntactic abstraction; Rebol thus combines the advantages of syntactic abstraction and a common language concept for both meta-program and object-program. All of the above are convenient attributes from a programmer’s point of view, yet at the same time pose severe challenges when striving to compile Rebol into reasonable code. An approach to compiling Rebol code that is still in its infancy is sketched, expected outcomes are presented. Keywords: first-class macros, dynamic syntactic abstraction, $vau calculus, fexpr, Ker- nel, Rebol 1 Introduction A meta-program is a program that can analyze (read), transform (read/write), or generate (write) another program, called the object-program. Static techniques for syntactic abstraction (macro systems, preprocessors) resolve all abstraction during compilation, so the expansion of abstractions incurs no cost at run-time. Static techniques are, however, conceptionally burdensome as they lead to staged systems with phases that are isolated from each other. In systems where different syntax is used for the phases (e. g., C++), it results in a multitude of programming languages following different sets of rules. In systems where the same syntax is shared between phases (e. g., Lisp), the separa- tion is even more unnatural: two syntactically largely identical-looking pieces of code cannot interact with each other as they are assigned to different execution stages. -
![[Lirmm-00862477, V1] Bridging the Gap Between Component-Based Design and Implementation with a Reflective Programming Language](https://docslib.b-cdn.net/cover/8348/lirmm-00862477-v1-bridging-the-gap-between-component-based-design-and-implementation-with-a-reflective-programming-language-1008348.webp)
[Lirmm-00862477, V1] Bridging the Gap Between Component-Based Design and Implementation with a Reflective Programming Language
Design and Implementation of a reflective Component-based programming and modeling language Bridging the Gap between Component-based Design and Implementation with a Reflective Programming Language Petr Spacek Christophe Dony Luc Fabresse Chouki Tibermacine Universite´ Lille Nord de France LIRMM, CNRS and Montpellier II University Ecole des Mines de Douai 161, rue Ada 941 rue Charles Bourseul 34392 Montpellier Cedex 5 France 59508 DOUAI Cedex France spacek,dony,tibermacin @lirmm.fr [email protected] { } Abstract General Terms Languages, Reflection, Metamodeling Component-based Software Engineering studies the design, Keywords Component, Programming, Modeling, Archi- development and maintenance of software constructed upon tecture, Reflection, Reflexive, Meta-model, Constraints, sets of connected components. Existing component-based Transformations models are frequently transformed into non-component- based programs, most of the time object-oriented, for run- time execution and then many component-related concepts, 1. Introduction e.g. explicit architecture, vanish at the implementation stage. Research works on component-based software engineering The main reason why is that with objects the component- (CBSE) have brought many advances on how to achieve related concepts are treated implicitly and therefore the orig- complex software development by reusing and assembling inal intentions and qualities of the component-based design components. The current trend is to explicitly express ar- are hidden. This paper presents a reflective component-based chitectures of software solutions, to reason about them, to programming and modeling language, which proposes the verify them and to transform them. However it appears following original contributions: 1) Components are seen that component-orientation has been more studied at de- as objects in which requirements, architecture descriptions, sign stage, with modeling languages and ADLs [10, 16, 22] connection points, etc. -

Open Programming Language Interpreters
Open Programming Language Interpreters Walter Cazzolaa and Albert Shaqiria a Università degli Studi di Milano, Italy Abstract Context: This paper presents the concept of open programming language interpreters, a model to support them and a prototype implementation in the Neverlang framework for modular development of programming languages. Inquiry: We address the problem of dynamic interpreter adaptation to tailor the interpreter’s behaviour on the task to be solved and to introduce new features to fulfil unforeseen requirements. Many languages provide a meta-object protocol (MOP) that to some degree supports reflection. However, MOPs are typically language-specific, their reflective functionality is often restricted, and the adaptation and application logic are often mixed which hardens the understanding and maintenance of the source code. Our system overcomes these limitations. Approach: We designed a model and implemented a prototype system to support open programming language interpreters. The implementation is integrated in the Neverlang framework which now exposes the structure, behaviour and the runtime state of any Neverlang-based interpreter with the ability to modify it. Knowledge: Our system provides a complete control over interpreter’s structure, behaviour and its runtime state. The approach is applicable to every Neverlang-based interpreter. Adaptation code can potentially be reused across different language implementations. Grounding: Having a prototype implementation we focused on feasibility evaluation. The paper shows that our approach well addresses problems commonly found in the research literature. We have a demon- strative video and examples that illustrate our approach on dynamic software adaptation, aspect-oriented programming, debugging and context-aware interpreters. Importance: Our paper presents the first reflective approach targeting a general framework for language development. -

1. with Examples of Different Programming Languages Show How Programming Languages Are Organized Along the Given Rubrics: I
AGBOOLA ABIOLA CSC302 17/SCI01/007 COMPUTER SCIENCE ASSIGNMENT 1. With examples of different programming languages show how programming languages are organized along the given rubrics: i. Unstructured, structured, modular, object oriented, aspect oriented, activity oriented and event oriented programming requirement. ii. Based on domain requirements. iii. Based on requirements i and ii above. 2. Give brief preview of the evolution of programming languages in a chronological order. 3. Vividly distinguish between modular programming paradigm and object oriented programming paradigm. Answer 1i). UNSTRUCTURED LANGUAGE DEVELOPER DATE Assembly Language 1949 FORTRAN John Backus 1957 COBOL CODASYL, ANSI, ISO 1959 JOSS Cliff Shaw, RAND 1963 BASIC John G. Kemeny, Thomas E. Kurtz 1964 TELCOMP BBN 1965 MUMPS Neil Pappalardo 1966 FOCAL Richard Merrill, DEC 1968 STRUCTURED LANGUAGE DEVELOPER DATE ALGOL 58 Friedrich L. Bauer, and co. 1958 ALGOL 60 Backus, Bauer and co. 1960 ABC CWI 1980 Ada United States Department of Defence 1980 Accent R NIS 1980 Action! Optimized Systems Software 1983 Alef Phil Winterbottom 1992 DASL Sun Micro-systems Laboratories 1999-2003 MODULAR LANGUAGE DEVELOPER DATE ALGOL W Niklaus Wirth, Tony Hoare 1966 APL Larry Breed, Dick Lathwell and co. 1966 ALGOL 68 A. Van Wijngaarden and co. 1968 AMOS BASIC FranÇois Lionet anConstantin Stiropoulos 1990 Alice ML Saarland University 2000 Agda Ulf Norell;Catarina coquand(1.0) 2007 Arc Paul Graham, Robert Morris and co. 2008 Bosque Mark Marron 2019 OBJECT-ORIENTED LANGUAGE DEVELOPER DATE C* Thinking Machine 1987 Actor Charles Duff 1988 Aldor Thomas J. Watson Research Center 1990 Amiga E Wouter van Oortmerssen 1993 Action Script Macromedia 1998 BeanShell JCP 1999 AngelScript Andreas Jönsson 2003 Boo Rodrigo B. -
![CONS Y X)))) Which Sets Z to Cdr[X] If Cdr[X] Is Not NIL (Without Recomputing the Value As Woirld Be Necessary in LISP 1.5](https://docslib.b-cdn.net/cover/9802/cons-y-x-which-sets-z-to-cdr-x-if-cdr-x-is-not-nil-without-recomputing-the-value-as-woirld-be-necessary-in-lisp-1-5-1149802.webp)
CONS Y X)))) Which Sets Z to Cdr[X] If Cdr[X] Is Not NIL (Without Recomputing the Value As Woirld Be Necessary in LISP 1.5
NO. 1 This first (long delayed) LISP Bulletin contains samples of most of those types of items which the editor feels are relevant to this publication. These include announcements of new (i.e. not previously announced here) implementations of LISP !or closely re- lated) systems; quick tricks in LISP; abstracts o. LISP related papers; short writeups and listings of useful programs; and longer articles on problems of general interest to the entire LISP com- munity. Printing- of these last articles in the Bulletin does not interfere with later publications in formal journals or books. Short write-ups of new features added to LISP are of interest, preferably upward compatible with LISP 1.5, especially if they are illustrated by programming examples. -A NEW LISP FEATURE Bobrow, Daniel G., Bolt Beranek and Newman Inc., 50 oulton Street, Cambridge, Massachusetts 02138. An extension of ro 2, called progn is very useful. Tht ralue of progn[el;e ; ,..;e Y- is the value of e . In BBN-LISP on t .e SDS 940 we ha6e extenaed -cond to include $n implicit progn in each clause, putting It In the general form (COND (ell e ) . (e21 . e 2n2) (ekl e )) In1 ... ... kn,_ where nl -> 1. This form is identical to the LISP 1.5 form if n ni = 2. If n > 2 then each expression e in a clause is evaluated (in order) whh e is the first true (nohkN1~)predicate found. The value of the &And Is the value of the last clause evaluated. This is directly Gapolated to the case where n, = 1, bxre the value of the cond is the value of this first non-~ILprewcate.