Code Profilers Choosing a Tool for Analyzing Performance
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Global SCRUM GATHERING® Berlin 2014
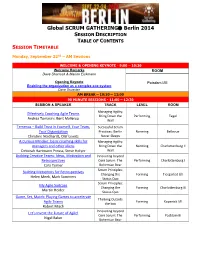
Global SCRUM GATHERING Berlin 2014 SESSION DESCRIPTION TABLE OF CONTENTS SESSION TIMETABLE Monday, September 22nd – AM Sessions WELCOME & OPENING KEYNOTE - 9:00 – 10:30 Welcome Remarks ROOM Dave Sharrock & Marion Eickmann Opening Keynote Potsdam I/III Enabling the organization as a complex eco-system Dave Snowden AM BREAK – 10:30 – 11:00 90 MINUTE SESSIONS - 11:00 – 12:30 SESSION & SPEAKER TRACK LEVEL ROOM Managing Agility: Effectively Coaching Agile Teams Bring Down the Performing Tegel Andrea Tomasini, Bent Myllerup Wall Temenos – Build Trust in Yourself, Your Team, Successful Scrum Your Organization Practices: Berlin Norming Bellevue Christine Neidhardt, Olaf Lewitz Never Sleeps A Curious Mindset: basic coaching skills for Managing Agility: managers and other aliens Bring Down the Norming Charlottenburg II Deborah Hartmann Preuss, Steve Holyer Wall Building Creative Teams: Ideas, Motivation and Innovating beyond Retrospectives Core Scrum: The Performing Charlottenburg I Cara Turner Bohemian Bear Scrum Principles: Building Metaphors for Retrospectives Changing the Forming Tiergarted I/II Helen Meek, Mark Summers Status Quo Scrum Principles: My Agile Suitcase Changing the Forming Charlottenburg III Martin Heider Status Quo Game, Set, Match: Playing Games to accelerate Thinking Outside Agile Teams Forming Kopenick I/II the box Robert Misch Innovating beyond Let's Invent the Future of Agile! Core Scrum: The Performing Postdam III Nigel Baker Bohemian Bear Monday, September 22nd – PM Sessions LUNCH – 12:30 – 13:30 90 MINUTE SESSIONS - 13:30 -

Enabling Devops on Premise Or Cloud with Jenkins
Enabling DevOps on Premise or Cloud with Jenkins Sam Rostam [email protected] Cloud & Enterprise Integration Consultant/Trainer Certified SOA & Cloud Architect Certified Big Data Professional MSc @SFU & PhD Studies – Partial @UBC Topics The Context - Digital Transformation An Agile IT Framework What DevOps bring to Teams? - Disrupting Software Development - Improved Quality, shorten cycles - highly responsive for the business needs What is CI /CD ? Simple Scenario with Jenkins Advanced Jenkins : Plug-ins , APIs & Pipelines Toolchain concept Q/A Digital Transformation – Modernization As stated by a As established enterprises in all industries begin to evolve themselves into the successful Digital Organizations of the future they need to begin with the realization that the road to becoming a Digital Business goes through their IT functions. However, many of these incumbents are saddled with IT that has organizational structures, management models, operational processes, workforces and systems that were built to solve “turn of the century” problems of the past. Many analysts and industry experts have recognized the need for a new model to manage IT in their Businesses and have proposed approaches to understand and manage a hybrid IT environment that includes slower legacy applications and infrastructure in combination with today’s rapidly evolving Digital-first, mobile- first and analytics-enabled applications. http://www.ntti3.com/wp-content/uploads/Agile-IT-v1.3.pdf Digital Transformation requires building an ecosystem • Digital transformation is a strategic approach to IT that treats IT infrastructure and data as a potential product for customers. • Digital transformation requires shifting perspectives and by looking at new ways to use data and data sources and looking at new ways to engage with customers. -

Integrating the GNU Debugger with Cycle Accurate Models a Case Study Using a Verilator Systemc Model of the Openrisc 1000
Integrating the GNU Debugger with Cycle Accurate Models A Case Study using a Verilator SystemC Model of the OpenRISC 1000 Jeremy Bennett Embecosm Application Note 7. Issue 1 Published March 2009 Legal Notice This work is licensed under the Creative Commons Attribution 2.0 UK: England & Wales License. To view a copy of this license, visit http://creativecommons.org/licenses/by/2.0/uk/ or send a letter to Creative Commons, 171 Second Street, Suite 300, San Francisco, California, 94105, USA. This license means you are free: • to copy, distribute, display, and perform the work • to make derivative works under the following conditions: • Attribution. You must give the original author, Jeremy Bennett of Embecosm (www.embecosm.com), credit; • For any reuse or distribution, you must make clear to others the license terms of this work; • Any of these conditions can be waived if you get permission from the copyright holder, Embecosm; and • Nothing in this license impairs or restricts the author's moral rights. The software for the SystemC cycle accurate model written by Embecosm and used in this document is licensed under the GNU General Public License (GNU General Public License). For detailed licensing information see the file COPYING in the source code. Embecosm is the business name of Embecosm Limited, a private limited company registered in England and Wales. Registration number 6577021. ii Copyright © 2009 Embecosm Limited Table of Contents 1. Introduction ................................................................................................................ 1 1.1. Why Use Cycle Accurate Modeling .................................................................... 1 1.2. Target Audience ................................................................................................ 1 1.3. Open Source ..................................................................................................... 2 1.4. Further Sources of Information ......................................................................... 2 1.4.1. -

Debugging and Profiling with Arm Tools
Debugging and Profiling with Arm Tools [email protected] • Ryan Hulguin © 2018 Arm Limited • 4/21/2018 Agenda • Introduction to Arm Tools • Remote Client Setup • Debugging with Arm DDT • Other Debugging Tools • Break • Examples with DDT • Lunch • Profiling with Arm MAP • Examples with MAP • Obtaining Support 2 © 2018 Arm Limited Introduction to Arm HPC Tools © 2018 Arm Limited Arm Forge An interoperable toolkit for debugging and profiling • The de-facto standard for HPC development • Available on the vast majority of the Top500 machines in the world • Fully supported by Arm on x86, IBM Power, Nvidia GPUs and Arm v8-A. Commercially supported by Arm • State-of-the art debugging and profiling capabilities • Powerful and in-depth error detection mechanisms (including memory debugging) • Sampling-based profiler to identify and understand bottlenecks Fully Scalable • Available at any scale (from serial to petaflopic applications) Easy to use by everyone • Unique capabilities to simplify remote interactive sessions • Innovative approach to present quintessential information to users Very user-friendly 4 © 2018 Arm Limited Arm Performance Reports Characterize and understand the performance of HPC application runs Gathers a rich set of data • Analyses metrics around CPU, memory, IO, hardware counters, etc. • Possibility for users to add their own metrics Commercially supported by Arm • Build a culture of application performance & efficiency awareness Accurate and astute • Analyses data and reports the information that matters to users insight • Provides simple guidance to help improve workloads’ efficiency • Adds value to typical users’ workflows • Define application behaviour and performance expectations Relevant advice • Integrate outputs to various systems for validation (e.g. -

Ready to Innovate?
ReadyThe Visual COBOL 5.0to Azure innovate? DevOps and Serverless Computing Walkthrough June 2019 The Visual COBOL 5.0 Azure DevOps and Serverless Computing Walkthrough 2 Visual COBOL 5.0— blue sky thinking Ready to build your Cloud story? This is primarily a how-to technical guide that enables COBOL and non- COBOL developers to modernize legacy applications using the Cloud— it’s all about bridging the old with the new. New to Visual COBOL? This is your guided tour of everything it can do towards modernizing core COBOL applications. Already on board? This is the update that explains how to take your applications beyond the next level and on to the Cloud. What will you learn? Much of this Guide focuses on the technical, practical aspect of creating next-gen apps from COBOL code. Among other new skills, you will discover how to… • Bring a COBOL application into Visual Studio or Eclipse • Edit, compile and debug COBOL applications using the IDE • Modernize COBOL apps using .NET and C# • Create and deploy a COBOL microservice as a Serverless application in the Cloud • Build, test and publish your application via a DevOps pipeline • Understand the latest native Cloud technologies The Visual COBOL 5.0 Azure DevOps and Serverless Computing Walkthrough 3 What’s new in Visual COBOL 5.0? This latest update of our unrivalled development experience significantly extends Visual COBOL’s capabilities. It brings the Cloud closer, enabling access to DevOps and Serverless computing for COBOL systems. For Micro Focus, Visual COBOL 5.0 is where meet our customers’ need for application modernization using the Cloud. -

Bugs and Debugging
CS50 Bugs and Debugging Overview Key Terms A bug is an error in code which results in a program either failing, or exhibiting a be- • bugs havior that is different from what the programmer expects. Bugs can be frustrating to • debugging deal with, but every programmer encounters them. Debugging is the process of trying • debugger to identify and fix bugs that exist in code. Programmers will often do this by making use of a program called a debugger, which assists in the debugging process. • breakpoint • debug50 Debugging Basics Programs generally perform computations much faster than a human possibly could, which makes it difficult to see what's wrong with a program just by running it all the way through. Debuggers are valuable because they allow a programmer to freeze a program at a particular line, known as a breakpoint, so that the programmer can see what's happening at that point in time. It also allows the programmer to execute the program one line at a time, so that the programmer can follow along with every decision that a program makes. Using debug50 debug50 is a program that we've created that runs a built-in graphical debugger in the CS50 IDE. Before you run debug50, you must set at least one breakpoint. If you have a general sense for where your program seems to be going wrong, it may be wise to set a breakpoint a few lines before there, so that you can see what's happening in your program as it moves into the section that you believe is causing the problem. -

Software Debugging Techniques
Software debugging techniques P. Adragna Queen Mary, University of London Abstract This lecture provides an introduction to debugging, a crucial activity in ev- ery developer's life. After an elementary discussion of some useful debugging concepts, the lecture goes on with a detailed review of general debugging tech- niques, independent of any specific software. The final part of the lecture is dedicated to analysing problems related to the use of C++ , the main program- ming language commonly employed in particle physics nowadays. Introduction According to a popular definition [1], debugging is a methodical process of finding and reducing the number of bugs, or defects, in a computer program. However, most people involved in spotting and removing those defects would define it as an art rather then a method. All bugs stem from a one basic premise: something thought to be right, was in fact wrong. Due to this simple principle, truly bizarre bugs can defy logic, making debugging software challenging. The typical behaviour of many inexperienced programmers is to freeze when unexpected problems arise. Without a definite process to follow, solving problems seems impossible to them. The most obvious reaction to such a situation is to make some random changes to the code, hoping that it will start working again. The issue is simple: the programmers have no idea of how to approach debugging [2]. This lecture is an attempt to review some techniques and tools to assist non-experienced pro- grammers in debugging. It contains both tips to solve problems and suggestions to prevent bugs from manifesting themselves. Finding a bug is a process of confirming what is working until something wrong is found. -

The Design of a Debugger Unit for a RISC Processor Core
Rochester Institute of Technology RIT Scholar Works Theses 3-2018 The Design of a Debugger Unit for a RISC Processor Core Nikhil Velguenkar [email protected] Follow this and additional works at: https://scholarworks.rit.edu/theses Recommended Citation Velguenkar, Nikhil, "The Design of a Debugger Unit for a RISC Processor Core" (2018). Thesis. Rochester Institute of Technology. Accessed from This Master's Project is brought to you for free and open access by RIT Scholar Works. It has been accepted for inclusion in Theses by an authorized administrator of RIT Scholar Works. For more information, please contact [email protected]. The Design of a Debugger Unit for a RISC Processor Core by Nikhil Velguenkar Graduate Paper Submitted in partial fulfillment of the requirements for the degree of Master of Science in Electrical Engineering Approved by: Mr. Mark A. Indovina, Lecturer Graduate Research Advisor, Department of Electrical and Microelectronic Engineering Dr. Sohail A. Dianat, Professor Department Head, Department of Electrical and Microelectronic Engineering Department of Electrical and Microelectronic Engineering Kate Gleason College of Engineering Rochester Institute of Technology Rochester, New York March 2018 To my family and friends, for all of their endless love, support, and encouragement throughout my career at Rochester Institute of Technology Abstract Recently, there has been a significant increase in design complexity for Embedded Sys- tems often referred to as Hardware Software Co-Design. Complexity in design is due to both hardware and firmware closely coupled together in-order to achieve features forlow power, high performance and low area. Due to these demands, embedded systems consist of multiple interconnected hardware IPs with complex firmware algorithms running on the device. -

Global SCRUM GATHERING® Berlin 2014
Global SCRUM GATHERING Berlin 2014 SESSION DESCRIPTION TABLE OF CONTENTS SESSION TIMETABLE Monday, September 22nd – AM Sessions WELCOME & OPENING KEYNOTE - 9:00 – 10:30 Welcome Remarks ROOM Dave Sharrock & Marion Eickmann Opening Keynote Potsdam I/III Enabling the organization as a complex eco-system Dave Snowden AM BREAK – 10:30 – 11:00 90 MINUTE SESSIONS - 11:00 – 12:30 SESSION & SPEAKER TRACK LEVEL ROOM Managing Agility: Effectively Coaching Agile Teams Bring Down the Performing Tegel Andrea Tomasini, Bent Myllerup Wall Temenos – Build Trust in Yourself, Your Team, Successful Scrum Your Organisation Practices: Berlin Norming Bellevue Christine Neidhardt, Olaf Lewitz Never Sleeps A Curious Mindset: basic coaching skills for Managing Agility: managers and other aliens Bring Down the Norming Charlottenburg II Deborah Hartmann Preuss, Steve Holyer Wall Building Creative Teams: Ideas, Motivation and Innovating beyond Retrospectives Core Scrum: The Performing Charlottenburg I Cara Turner Bohemian Bear Scrum Principles: Building Metaphors for Retrospectives Changing the Forming Tiergarted I/II Helen Meek, Mark Summers Status Quo Scrum Principles: My Agile Suitcase Changing the Forming Charlottenburg III Martin Heider Status Quo Game, Set, Match: Playing Games to accelerate Thinking Outside Agile Teams Forming Kopenick I/II the box Robert Misch Innovating beyond Let's Invent the Future of Agile! Core Scrum: The Performing Postdam III Nigel Baker Bohemian Bear Monday, September 22nd – PM Sessions LUNCH – 12:30 – 13:30 90 MINUTE SESSIONS - 13:30 -

Software Debugging Using the Debugger SAM4E Xplained Pro
Faculty of Technology and Society Computer Engineering Bachelor’s thesis 15 credits Software debugging using the debugger SAM4E Xplained Pro Mjukvarufelsökning med användning av felsökningsverktyget SAM4E Xplained Pro Hamoud Abdullah Nadia Manoh Exam: Bachelor of Science in Engineering Examiner: Ulrik Ekedahl Area: Computer Engineering Supervisor: Magnus Krampell Date of final seminar: 2018-08-21 Abstract Embedded systems are found in almost every device used in our daily lives, including cell phones, refrigerators, and cars. Some devices may be significantly more sensitive than others, meaning a bug appearing in a system could cause harm, even loss of human lives or cause no harm at all. To reduce bugs in a system, software testing and software debugging are performed. The Computer Science program at Malmö University does not focus on teaching software debugging using a debugger. Thus, this thesis presents a debugging lab created for Computer Science students, considered to help them gain knowledge in how to use the debugger SAM4E Xplained Pro to locate bugs. As a result, four students performed the debugging lab of which 75 percent of the bugs were found and remedied. Keywords: embedded system, software testing, software debugging, software failure, software bugs debugging techniques Sammanfattning Inbyggda system finns i nästan alla enheter som används i vårt dagliga liv, som exempelvis mobiltelefoner, kylskåp och bilar. En del enheter kan vara betydligt känsligare än andra, vilket innebär att en bugg som existerar i ett system kan orsaka skada, till och med förlust av människoliv, eller orsakar ingen skada alls. Mjukvarutestning och mjukvarufelsökning genomförs för att reducera buggar i ett system. -

Software Testing Strategies and Methods CONTENTS
Software Engineering Software Testing Strategies and Methods CONTENTS I. Software Testing Fundamentals 1. Definition of Software Testing II. Characteristics of Testing Strategies III. Software Verification and Validation (V&V) IV. Testing Strategies 1. Unit Testing 2. Integration Testing V. Alpha and Beta Testing ( Concept and differences) VI. System Testing 1. Concept of System Testing VII. Concept of White-box and Black-Box Testing VIII. Debugging 1. Concept and need of Debugging 2. Characteristics of bugs IX. Debugging Strategies 1. Concept of Brute Force, Back Tracking, Induction, Deduction Anuradha Bhatia Software Engineering I. Software Testing Fundamentals 1. Definition of Software Testing i. Software testing is a method of assessing the functionality of a software program. ii. There are many different types of software testing but the two main categories are dynamic testing and static testing. II. Characteristics of Testing Strategies Figure 1: Software Testing Software Testing Myths and Facts: Just as every field has its myths, so does the field of Software Testing. Software testing myths have arisen primarily due to the following: i. Lack of authoritative facts. ii. Evolving nature of the industry. iii. General flaws in human logic. Some of the myths are explained below, along with their related facts: 1. MYTH: Quality Control = Testing. FACT: Testing is just one component of software quality control. Quality Control includes other activities such as Reviews. Anuradha Bhatia Software Engineering 2. MYTH: The objective of Testing is to ensure a 100% defect- free product. FACT: The objective of testing is to uncover as many defects as possible. Identifying all defects and getting rid of them is impossible. -

OZCODE PRODUCTION DEBUGGER. a New Paradigm for Cloud-Native Debugging
OZCODE PRODUCTION DEBUGGER. A New Paradigm for Cloud-Native Debugging White Paper © 2020 Ozcode. All Rights Reserved Contents Executive Summary 1 The downfall of traditional 11 debugging Cloud is simple, agile, and scalable, but hard to debug Logs Common enterprise tools have their place Application Performance but fall short in production debugging Management (APM) tools The Ozcode production debugging Error monitoring tools paradigm The new debugging paradigm with 13 Introduction 3 Ozcode Production Debugger Production errors are inevitable Autonomous exception capture Production errors are very, very expensive The Ozcode Production Debugger Cloud computing has become Mainstream Dashboard Radical observability Production debugging is hard 6 Time-travel debugging Production debugging in the cloud 6 A new debugging paradigm for a new 15 is even harder era of software Many concurrent users Microservices Serverless code Working with Queues Security and privacy requirements Accelerated deployments © 2020 Ozcode. All Rights Reserved Executive Summary Common enterprise tools have their place but fall short in Production errors have been happening since the production debugging dawn of computing and continue to this day. At any time, you can check DownDetector.com to see The tool stack available to developers in an when services from leading companies go down. enterprise usually consists of any or all of Log Production errors are also very costly to fix, up to 30 Analyzers, Application Performance Monitors times what it costs to fix an error detected during (APMs), or Error Monitors. While these tools help the requirements analysis or design phase of an solve different issues that arise in production application. The reason is that it is very complicated systems, none of them are very effective in helping to debug production errors.