Software Debugging and Testing Using the Abstract Diagnosis Theory
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Testing E-Commerce Systems: a Practical Guide - Wing Lam
Testing E-Commerce Systems: A Practical Guide - Wing Lam As e-customers (whether business or consumer), we are unlikely to have confidence in a Web site that suffers frequent downtime, hangs in the middle of a transaction, or has a poor sense of usability. Testing, therefore, has a crucial role in the overall development process. Given unlimited time and resources, you could test a system to exhaustion. However, most projects operate within fixed budgets and time scales, so project managers need a systematic and cost- effective approach to testing that maximizes test confidence. This article provides a quick and practical introduction to testing medium- to large-scale transactional e-commerce systems based on project experiences developing tailored solutions for B2C Web retailing and B2B procurement. Typical of most e-commerce systems, the application architecture includes front-end content delivery and management systems, and back-end transaction processing and legacy integration. Aimed primarily at project and test managers, this article explains how to · establish a systematic test process, and · test e-commerce systems. The Test Process You would normally expect to spend between 25 to 40 percent of total project effort on testing and validation activities. Most seasoned project managers would agree that test planning needs to be carried out early in the project lifecycle. This will ensure the time needed for test preparation (establishing a test environment, finding test personnel, writing test scripts, and so on) before any testing can actually start. The different kinds of testing (unit, system, functional, black-box, and others) are well documented in the literature. -

Interpreting Reliability and Availability Requirements for Network-Centric Systems What MCOTEA Does
Marine Corps Operational Test and Evaluation Activity Interpreting Reliability and Availability Requirements for Network-Centric Systems What MCOTEA Does Planning Testing Reporting Expeditionary, C4ISR & Plan Naval, and IT/Business Amphibious Systems Systems Test Evaluation Plans Evaluation Reports Assessment Plans Assessment Reports Test Plans Test Data Reports Observation Plans Observation Reports Combat Ground Service Combat Support Initial Operational Test Systems Systems Follow-on Operational Test Multi-service Test Quick Reaction Test Test Observations 2 Purpose • To engage test community in a discussion about methods in testing and evaluating RAM for software-intensive systems 3 Software-intensive systems – U.S. military one of the largest users of information technology and software in the world [1] – Dependence on these types of systems is increasing – Software failures have had disastrous consequences Therefore, software must be highly reliable and available to support mission success 4 Interpreting Requirements Excerpts from capabilities documents for software intensive systems: Availability Reliability “The system is capable of achieving “Average duration of 716 hours a threshold operational without experiencing an availability of 95% with an operational mission fault” objective of 98%” “Mission duration of 24 hours” “Operationally Available in its intended operating environment “Completion of its mission in its with at least a 0.90 probability” intended operating environment with at least a 0.90 probability” 5 Defining Reliability & Availability What do we mean reliability and availability for software intensive systems? – One consideration: unlike traditional hardware systems, a highly reliable and maintainable system will not necessarily be highly available - Highly recoverable systems can be less available - A system that restarts quickly after failures can be highly available, but not necessarily reliable - Risk in inflating availability and underestimating reliability if traditional equations are used. -

Software Tools: a Building Block Approach
SOFTWARE TOOLS: A BUILDING BLOCK APPROACH NBS Special Publication 500-14 U.S. DEPARTMENT OF COMMERCE National Bureau of Standards ] NATIONAL BUREAU OF STANDARDS The National Bureau of Standards^ was established by an act of Congress March 3, 1901. The Bureau's overall goal is to strengthen and advance the Nation's science and technology and facilitate their effective application for public benefit. To this end, the Bureau conducts research and provides: (1) a basis for the Nation's physical measurement system, (2) scientific and technological services for industry and government, (3) a technical basis for equity in trade, and (4) technical services to pro- mote public safety. The Bureau consists of the Institute for Basic Standards, the Institute for Materials Research, the Institute for Applied Technology, the Institute for Computer Sciences and Technology, the Office for Information Programs, and the ! Office of Experimental Technology Incentives Program. THE INSTITUTE FOR BASIC STANDARDS provides the central basis within the United States of a complete and consist- ent system of physical measurement; coordinates that system with measurement systems of other nations; and furnishes essen- tial services leading to accurate and uniform physical measurements throughout the Nation's scientific community, industry, and commerce. The Institute consists of the Office of Measurement Services, and the following center and divisions: Applied Mathematics — Electricity — Mechanics — Heat — Optical Physics — Center for Radiation Research — Lab- oratory Astrophysics^ — Cryogenics^ — Electromagnetics^ — Time and Frequency*. THE INSTITUTE FOR MATERIALS RESEARCH conducts materials research leading to improved methods of measure- ment, standards, and data on the properties of well-characterized materials needed by industry, commerce, educational insti- tutions, and Government; provides advisory and research services to other Government agencies; and develops, produces, and distributes standard reference materials. -

QA and Testing Have Become More of a Concurrent Process
Special Feature: SW Testing “QA and testing have become more of a concurrent process rather than an end of lifecycle process” Manish Tandon, VP & Head– Independent Validation and Testing Solutions, Infosys Interview by: Anil Chopra, PCQuest n an exclusive interview with the PCQuest Editor, Manish talks become a software tester? about the global trends in software testing, skillsets required Software testing has evolved into a very special function and Ito enter the field, how technology has evolved in this area to anybody wanting to enter the domain requires two special provide higher ROI, and much more. An IIT and IIM graduate, skillsets. One is deep functional or domain skills to understand Manish is responsible for formulating and executing the business the functionality. Plus, you need specialized technical skills strategy for Independent Validation and Testing Solutions practice as well because you want to do automation, middleware, and at Infosys. He mentors the unit specifically in meeting business performance testing. It’s a unique combination, and we focus goals and targets. In addition, he manages critical relationships very strongly on both these dimensions. A good software tester with client executives, industry analysts, deal consultants, and should always have an eye for detail. So people who have a slightly anchors the training and development of key personnel. Provided critical eye and are willing to dig deeper always make much better here are his expert comments on the subject. testers than people who want to fly at 30k feet. Q> What are some of the global trends in the software Q> You mentioned that software testing is now required testing business? How do you see the market moving? for front-end applications. -

Employee Management System
School of Mathematics and Systems Engineering Reports from MSI - Rapporter från MSI Employee Management System Kancho Dimitrov Kanchev Dec MSI Report 06170 2006 Växjö University ISSN 1650-2647 SE-351 95 VÄXJÖ ISRN VXU/MSI/DA/E/--06170/--SE Abstract This report includes a development presentation of an information system for managing the staff data within a small company or organization. The system as such as it has been developed is called Employee Management System. It consists of functionally related GUI (application program) and database. The choice of the programming tools is individual and particular. Keywords Information system, Database system, DBMS, parent table, child table, table fields, primary key, foreign key, relationship, sql queries, objects, classes, controls. - 2 - Contents 1. Introduction…………………………………………………………4 1.1 Background……………………………………………………....................4 1.2 Problem statement ...…………………………………………………….....5 1.3 Problem discussion………………………………………………………....5 1.4 Report Overview…………………………………………………………...5 2. Problem’s solution……………………………………………….....6 2.1 Method...…………………………………………………………………...6 2.2 Programming environments………………………………………………..7 2.3 Database analyzing, design and implementation…………………………10 2.4 Program’s structure analyzing and GUI constructing…………………….12 2.5 Database connections and code implementation………………………….14 2.5.1 Retrieving data from the database………………………………....19 2.5.2 Saving data into the database……………………………………...22 2.5.3 Updating records into the database………………………………..24 2.5.4 Deleting data from the database…………………………………...26 3. Conclusion………………………………………………………....27 4. References………………………………………………………...28 Appendix A: Programming environments and database content….29 Appendix B: Program’s structure and code Implementation……...35 Appendix C: Test Performance…………………………………....56 - 3 - 1. Introduction This chapter gives a brief theoretical preview upon the database information systems and goes through the essence of the problem that should be resolved. -
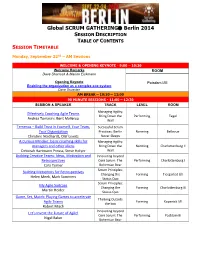
Global SCRUM GATHERING® Berlin 2014
Global SCRUM GATHERING Berlin 2014 SESSION DESCRIPTION TABLE OF CONTENTS SESSION TIMETABLE Monday, September 22nd – AM Sessions WELCOME & OPENING KEYNOTE - 9:00 – 10:30 Welcome Remarks ROOM Dave Sharrock & Marion Eickmann Opening Keynote Potsdam I/III Enabling the organization as a complex eco-system Dave Snowden AM BREAK – 10:30 – 11:00 90 MINUTE SESSIONS - 11:00 – 12:30 SESSION & SPEAKER TRACK LEVEL ROOM Managing Agility: Effectively Coaching Agile Teams Bring Down the Performing Tegel Andrea Tomasini, Bent Myllerup Wall Temenos – Build Trust in Yourself, Your Team, Successful Scrum Your Organization Practices: Berlin Norming Bellevue Christine Neidhardt, Olaf Lewitz Never Sleeps A Curious Mindset: basic coaching skills for Managing Agility: managers and other aliens Bring Down the Norming Charlottenburg II Deborah Hartmann Preuss, Steve Holyer Wall Building Creative Teams: Ideas, Motivation and Innovating beyond Retrospectives Core Scrum: The Performing Charlottenburg I Cara Turner Bohemian Bear Scrum Principles: Building Metaphors for Retrospectives Changing the Forming Tiergarted I/II Helen Meek, Mark Summers Status Quo Scrum Principles: My Agile Suitcase Changing the Forming Charlottenburg III Martin Heider Status Quo Game, Set, Match: Playing Games to accelerate Thinking Outside Agile Teams Forming Kopenick I/II the box Robert Misch Innovating beyond Let's Invent the Future of Agile! Core Scrum: The Performing Postdam III Nigel Baker Bohemian Bear Monday, September 22nd – PM Sessions LUNCH – 12:30 – 13:30 90 MINUTE SESSIONS - 13:30 -

Software Requirements Specification to Distribute Manufacturing Data
NIST Advanced Manufacturing Series 300-2 Software Requirements Specification to Distribute Manufacturing Data Thomas Hedberg, Jr. Moneer Helu Marcus Newrock This publication is available free of charge from: https://doi.org/10.6028/NIST.AMS.300-2 NIST Advanced Manufacturing Series 300-2 Software Requirements Specification to Distribute Manufacturing Data Thomas Hedberg, Jr. Moneer Helu Systems Integration Division Engineering Laboratory Marcus Newrock Office of Data and Informatics Material Measurement Laboratory This publication is available free of charge from: https://doi.org/10.6028/NIST.AMS.300-2 December 2017 U.S. Department of Commerce Wilbur L. Ross, Jr., Secretary National Institute of Standards and Technology Walter Copan, NIST Director and Under Secretary of Commerce for Standards and Technology SRS to Distribute Manufacturing Data Hedberg, Helu, and Newrock ______________________________________________________________________________________________________ Contents 1 Introduction 1 1.1 Purpose ...................................... 1 1.2 Disclaimer ..................................... 1 This publication is available free of charge from: https://doi.org/10.6028/NIST.AMS.300-2 1.3 Scope ....................................... 1 1.4 Acronyms and abbreviations ........................... 1 1.5 Verbal Forms ................................... 3 1.5.1 Must .................................... 3 1.5.2 Should ................................... 3 1.5.3 May .................................... 3 1.6 References .................................... -

Usage of Prototyping in Software Testing
Multi-Knowledge Electronic Comprehensive Journal For Education And Science Publications (MECSJ) ISSUE (14), Nov (2018) www.mescj.com USAGE OF PROTOTYPING IN SOFTWARE TESTING 1st Khansaa Azeez Obayes Al-Husseini Babylon Technical Insitute , Al-Furat Al-Awsat Technical University,51015 Babylon,Iraq. 1st [email protected] 2nd Ali Hamzah Obaid Babylon Technical Insitute , Al-Furat Al-Awsat Technical University,51015 Babylon,Iraq. 2nd [email protected] Abstract: Prototyping process is an important part of software development. This article describes usage of prototyping using Question – and – Answer memory and visual prototype diesign to realize Prototyping software development model. It also includes review of different models of software lifecycle with comparison them with Prototyping model. Key word: Question – and – Answer , Prototype, Software Development, RAD model. 1. Introduction One of the most important parts of software development is project design. Software project designing as a process of project creation can be divided in two large parts (very conditional): design of the functionality and design of user interface. To design the functionality, tools such as UML and IDEF0 are used, which have already become industry standards for software development. In the design of the graphical user interface there are no established standards, there are separate recommendations, techniques, design features, traditions, operating conditions for software, etc. At the same time, an important, but not always properly performed, part of this process is prototyping, i.e. the creation of a prototype or prototype of a future system. Prototypes can be different: paper, presentation, imitation, etc., up to exact correspondence to the future program. Most of the modern integrated development environments for software (IDE) allows to create something similar to prototypes, but it is connected with specific knowledge of IDE and programming language. -

Lecturer: Ting Wang (王挺)
Lecturer: Ting Wang (王挺) 利物浦大学计算机博士 清华大学计算机博士后 电子信息技术高级工程师 上海外国语大学网络与新媒体副教授 浙江清华长三角研究院海纳认知与智能研究中心主任 New Media Product DevelopmentDesign and Dr. Ting WANG School of Journalism and Communication Haina Cognition and Intelligence Research Center Shanghai International Studies University Yangtze Delta Region Institute of Tsinghua University, Zhejiang An overview to Part 01 software testing Testing in the software development Project Manager (Requirement Analyzer) System Analysis Release Structure Designer System Analysis Quality Assurance Engineer Requirement Analyzer Structure Design Testing Structure Design Programmer Structure Designer V-model Coding Coding Programmer Waterfall model Testing Quality Assurance Engineer Release Project Manager What is software testing? Software Testing Definition according to ANSI/IEEE 1059 standard -- A process of analyzing a software item to detect the differences between existing and required conditions (i.e., defects) and to evaluate the features of the software item. https://www.softwaretestingmaterial.com/software-testing/ “Testing shows the presence, not the absence of bugs.” —Edsger W. Dijkstra Edsger W. Dijkstra (May 11, 1930 - Aug 06, 2002) was a Dutch systems scientist, programmer, software engineer, science essayist, and pioneer in computing science. Bug Fault (also called “defect” or “bug”) is an erroneous hardware or software element of a system that can cause the system to fail. Reasons why software has bugs human mistakes in software design and coding. The longer a software bug exists throughout the product life-cycle, the more it costs. In 2002, software bugs cost the United States economy approximately $59.5 billion. In 2016, that number jumped to $1.1 trillion. https://dzone.com/articles/api-testing-best-practices 20 reasons for software bugs Reasons in development Reasons in testing #1) Miscommunication or No Communication #11) Not having a proper test setup (test environment) for testing all requirements. -

Enabling Devops on Premise Or Cloud with Jenkins
Enabling DevOps on Premise or Cloud with Jenkins Sam Rostam [email protected] Cloud & Enterprise Integration Consultant/Trainer Certified SOA & Cloud Architect Certified Big Data Professional MSc @SFU & PhD Studies – Partial @UBC Topics The Context - Digital Transformation An Agile IT Framework What DevOps bring to Teams? - Disrupting Software Development - Improved Quality, shorten cycles - highly responsive for the business needs What is CI /CD ? Simple Scenario with Jenkins Advanced Jenkins : Plug-ins , APIs & Pipelines Toolchain concept Q/A Digital Transformation – Modernization As stated by a As established enterprises in all industries begin to evolve themselves into the successful Digital Organizations of the future they need to begin with the realization that the road to becoming a Digital Business goes through their IT functions. However, many of these incumbents are saddled with IT that has organizational structures, management models, operational processes, workforces and systems that were built to solve “turn of the century” problems of the past. Many analysts and industry experts have recognized the need for a new model to manage IT in their Businesses and have proposed approaches to understand and manage a hybrid IT environment that includes slower legacy applications and infrastructure in combination with today’s rapidly evolving Digital-first, mobile- first and analytics-enabled applications. http://www.ntti3.com/wp-content/uploads/Agile-IT-v1.3.pdf Digital Transformation requires building an ecosystem • Digital transformation is a strategic approach to IT that treats IT infrastructure and data as a potential product for customers. • Digital transformation requires shifting perspectives and by looking at new ways to use data and data sources and looking at new ways to engage with customers. -

Integrating the GNU Debugger with Cycle Accurate Models a Case Study Using a Verilator Systemc Model of the Openrisc 1000
Integrating the GNU Debugger with Cycle Accurate Models A Case Study using a Verilator SystemC Model of the OpenRISC 1000 Jeremy Bennett Embecosm Application Note 7. Issue 1 Published March 2009 Legal Notice This work is licensed under the Creative Commons Attribution 2.0 UK: England & Wales License. To view a copy of this license, visit http://creativecommons.org/licenses/by/2.0/uk/ or send a letter to Creative Commons, 171 Second Street, Suite 300, San Francisco, California, 94105, USA. This license means you are free: • to copy, distribute, display, and perform the work • to make derivative works under the following conditions: • Attribution. You must give the original author, Jeremy Bennett of Embecosm (www.embecosm.com), credit; • For any reuse or distribution, you must make clear to others the license terms of this work; • Any of these conditions can be waived if you get permission from the copyright holder, Embecosm; and • Nothing in this license impairs or restricts the author's moral rights. The software for the SystemC cycle accurate model written by Embecosm and used in this document is licensed under the GNU General Public License (GNU General Public License). For detailed licensing information see the file COPYING in the source code. Embecosm is the business name of Embecosm Limited, a private limited company registered in England and Wales. Registration number 6577021. ii Copyright © 2009 Embecosm Limited Table of Contents 1. Introduction ................................................................................................................ 1 1.1. Why Use Cycle Accurate Modeling .................................................................... 1 1.2. Target Audience ................................................................................................ 1 1.3. Open Source ..................................................................................................... 2 1.4. Further Sources of Information ......................................................................... 2 1.4.1. -

Automated Testing of Firmware Installation and Update Scenarios for Peripheral Devices
DEGREE PROJECT IN COMPUTER SCIENCE AND ENGINEERING, SECOND CYCLE, 30 CREDITS STOCKHOLM, SWEDEN 2019 Automated testing of firmware installation and update scenarios for peripheral devices DAG REUTERSKIÖLD KTH ROYAL INSTITUTE OF TECHNOLOGY SCHOOL OF ELECTRICAL ENGINEERING AND COMPUTER SCIENCE Automated testing of firmware installation and update scenarios for peripheral devices DAG REUTERSKIÖLD Master in Computer Science Date: August 12, 2019 Supervisor: Hamid Faragardi Examiner: Elena Troubitsyna School of Electrical Engineering and Computer Science Host company: Tobii AB Swedish title: Automatisering av enhetsinstallation, uppdatering och testning med hjälp av virtuella maskiner iii Abstract This research presents an approach to transition from manual to automated testing of hardware specific firmware. The manual approach for firmware test- ing can be repetitive and time consuming. A significant proportion of the time is spent on cleaning and re-installing operating systems so that old firmware does not interfere with the newer firmware that is being tested. The approach in this research utilizes virtual machines and presents an automation framework. One component of the automation framework is an application to imitate con- nected peripheral devices to bypass hardware dependencies of firmware in- stallers. The framework also consists of automation and pipeline scripts with the objective to execute firmware installers and detect errors and abnormalities in the installation and updating processes. The framework can run on locally hosted virtual machines, but is most applicable using cloud hosted virtual ma- chines, where it is part of a continuous integration that builds, downloads, installs, updates and tests new firmware versions, in a completely automated manner. The framework is evaluated by measuring and comparing execution times with manually conducted installation and updating tests, and the result shows that the framework complete tests much faster than the manual approach.