Correlation and Dependence 1 Correlation and Dependence
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
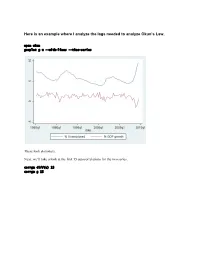
Here Is an Example Where I Analyze the Lags Needed to Analyze Okun's
Here is an example where I analyze the lags needed to analyze Okun’s Law. open okun gnuplot g u --with-lines --time-series These look stationary. Next, we’ll take a look at the first 15 autocorrelations for the two series. corrgm diff(u) 15 corrgm g 15 These are autocorrelated and so are these. I would expect that a simple regression will not be sufficient to model this relationship. Let’s try anyway. Run a simple regression and look at the residuals ols diff(u) const g series ehat=$uhat gnuplot ehat --with-lines --time-series These look positively autocorrelated to me. Notice how the residuals fall below zero for a while, then rise above for a while, and repeat this pattern. Take a look at the correlogram. The first autocorrelation is significant. More lags of D.u or g will probably fix this. LM test of residuals smpl 1985.2 2009.3 ols diff(u) const g modeltab add modtest 1 --autocorr --quiet modtest 2 --autocorr --quiet modtest 3 --autocorr --quiet modtest 4 --autocorr --quiet Breusch-Godfrey test for first-order autocorrelation Alternative statistic: TR^2 = 6.576105, with p-value = P(Chi-square(1) > 6.5761) = 0.0103 Breusch-Godfrey test for autocorrelation up to order 2 Alternative statistic: TR^2 = 7.922218, with p-value = P(Chi-square(2) > 7.92222) = 0.019 Breusch-Godfrey test for autocorrelation up to order 3 Alternative statistic: TR^2 = 11.200978, with p-value = P(Chi-square(3) > 11.201) = 0.0107 Breusch-Godfrey test for autocorrelation up to order 4 Alternative statistic: TR^2 = 11.220956, with p-value = P(Chi-square(4) > 11.221) = 0.0242 Yep, that’s not too good. -

Statistics on Spotlight: World Statistics Day 2015
Statistics on Spotlight: World Statistics Day 2015 Shahjahan Khan Professor of Statistics School of Agricultural, Computational and Environmental Sciences University of Southern Queensland, Toowoomba, Queensland, AUSTRALIA Founding Chief Editor, Journal of Applied Probability and Statistics (JAPS), USA Email: [email protected] Abstract In the age of evidence based decision making and data science, statistics has become an integral part of almost all spheres of modern life. It is being increasingly applied for both private and public benefits including business and trade as well as various public sectors, not to mention its crucial role in research and innovative technologies. No modern government could conduct its normal functions and deliver its services and implement its development agenda without relying on good quality statistics. The key role of statistics is more visible and engraved in the planning and development of every successful nation state. In fact, the use of statistics is not only national but also regional, international and transnational for organisations and agencies that are driving social, economic, environmental, health, poverty elimination, education and other agendas for planned development. Starting from stocktaking of the state of the health of various sectors of the economy of any nation/region to setting development goals, assessment of progress, monitoring programs and undertaking follow-up initiatives depend heavily on relevant statistics. Only statistical methods are capable of determining indicators, comparing them, and help identify the ways to ensure balanced and equitable development. 1 Introduction The goals of the celebration of World Statistics Day 2015 is to highlight the fact that official statistics help decision makers develop informed policies that impact millions of people. -

Alternative Tests for Time Series Dependence Based on Autocorrelation Coefficients
Alternative Tests for Time Series Dependence Based on Autocorrelation Coefficients Richard M. Levich and Rosario C. Rizzo * Current Draft: December 1998 Abstract: When autocorrelation is small, existing statistical techniques may not be powerful enough to reject the hypothesis that a series is free of autocorrelation. We propose two new and simple statistical tests (RHO and PHI) based on the unweighted sum of autocorrelation and partial autocorrelation coefficients. We analyze a set of simulated data to show the higher power of RHO and PHI in comparison to conventional tests for autocorrelation, especially in the presence of small but persistent autocorrelation. We show an application of our tests to data on currency futures to demonstrate their practical use. Finally, we indicate how our methodology could be used for a new class of time series models (the Generalized Autoregressive, or GAR models) that take into account the presence of small but persistent autocorrelation. _______________________________________________________________ An earlier version of this paper was presented at the Symposium on Global Integration and Competition, sponsored by the Center for Japan-U.S. Business and Economic Studies, Stern School of Business, New York University, March 27-28, 1997. We thank Paul Samuelson and the other participants at that conference for useful comments. * Stern School of Business, New York University and Research Department, Bank of Italy, respectively. 1 1. Introduction Economic time series are often characterized by positive -

Krishnan Correlation CUSB.Pdf
SELF INSTRUCTIONAL STUDY MATERIAL PROGRAMME: M.A. DEVELOPMENT STUDIES COURSE: STATISTICAL METHODS FOR DEVELOPMENT RESEARCH (MADVS2005C04) UNIT III-PART A CORRELATION PROF.(Dr). KRISHNAN CHALIL 25, APRIL 2020 1 U N I T – 3 :C O R R E L A T I O N After reading this material, the learners are expected to : . Understand the meaning of correlation and regression . Learn the different types of correlation . Understand various measures of correlation., and, . Explain the regression line and equation 3.1. Introduction By now we have a clear idea about the behavior of single variables using different measures of Central tendency and dispersion. Here the data concerned with one variable is called ‗univariate data‘ and this type of analysis is called ‗univariate analysis‘. But, in nature, some variables are related. For example, there exists some relationships between height of father and height of son, price of a commodity and amount demanded, the yield of a plant and manure added, cost of living and wages etc. This is a a case of ‗bivariate data‘ and such analysis is called as ‗bivariate data analysis. Correlation is one type of bivariate statistics. Correlation is the relationship between two variables in which the changes in the values of one variable are followed by changes in the values of the other variable. 3.2. Some Definitions 1. ―When the relationship is of a quantitative nature, the approximate statistical tool for discovering and measuring the relationship and expressing it in a brief formula is known as correlation‖—(Craxton and Cowden) 2. ‗correlation is an analysis of the co-variation between two or more variables‖—(A.M Tuttle) 3. -

3 Autocorrelation
3 Autocorrelation Autocorrelation refers to the correlation of a time series with its own past and future values. Autocorrelation is also sometimes called “lagged correlation” or “serial correlation”, which refers to the correlation between members of a series of numbers arranged in time. Positive autocorrelation might be considered a specific form of “persistence”, a tendency for a system to remain in the same state from one observation to the next. For example, the likelihood of tomorrow being rainy is greater if today is rainy than if today is dry. Geophysical time series are frequently autocorrelated because of inertia or carryover processes in the physical system. For example, the slowly evolving and moving low pressure systems in the atmosphere might impart persistence to daily rainfall. Or the slow drainage of groundwater reserves might impart correlation to successive annual flows of a river. Or stored photosynthates might impart correlation to successive annual values of tree-ring indices. Autocorrelation complicates the application of statistical tests by reducing the effective sample size. Autocorrelation can also complicate the identification of significant covariance or correlation between time series (e.g., precipitation with a tree-ring series). Autocorrelation implies that a time series is predictable, probabilistically, as future values are correlated with current and past values. Three tools for assessing the autocorrelation of a time series are (1) the time series plot, (2) the lagged scatterplot, and (3) the autocorrelation function. 3.1 Time series plot Positively autocorrelated series are sometimes referred to as persistent because positive departures from the mean tend to be followed by positive depatures from the mean, and negative departures from the mean tend to be followed by negative departures (Figure 3.1). -

ED441031.Pdf
DOCUMENT RESUME ED 441 031 TM 030 830 AUTHOR Fahoome, Gail; Sawilowsky, Shlomo S. TITLE Review of Twenty Nonparametric Statistics and Their Large Sample Approximations. PUB DATE 2000-04-00 NOTE 42p.; Paper presented at the Annual Meeting of the American Educational Research Association (New Orleans, LA, April 24-28, 2000). PUB TYPE Information Analyses (070)-- Numerical/Quantitative Data (110) Speeches/Meeting Papers (150) EDRS PRICE MF01/PCO2 Plus Postage. DESCRIPTORS Monte Carlo Methods; *Nonparametric Statistics; *Sample Size; *Statistical Distributions ABSTRACT Nonparametric procedures are often more powerful than classical tests for real world data, which are rarely normally distributed. However, there are difficulties in using these tests. Computational formulas are scattered tnrous-hout the literature, and there is a lack of avalialalicy of tables of critical values. This paper brings together the computational formulas for 20 commonly used nonparametric tests that have large-sample approximations for the critical value. Because there is no generally agreed upon lower limit for the sample size, Monte Carlo methods have been used to determine the smallest sample size that can be used with the large-sample approximations. The statistics reviewed include single-population tests, comparisons of two populations, comparisons of several populations, and tests of association. (Contains 4 tables and 59 references.)(Author/SLD) Reproductions supplied by EDRS are the best that can be made from the original document. Review of Twenty Nonparametric Statistics and Their Large Sample Approximations Gail Fahoome Shlomo S. Sawilowsky U.S. DEPARTMENT OF EDUCATION Mice of Educational Research and Improvement PERMISSION TO REPRODUCE AND UCATIONAL RESOURCES INFORMATION DISSEMINATE THIS MATERIAL HAS f BEEN GRANTED BY CENTER (ERIC) This document has been reproduced as received from the person or organization originating it. -

Detecting Trends Using Spearman's Rank Correlation Coefficient
Environmental Forensics 2001) 2, 359±362 doi:10.1006/enfo.2001.0061, available online at http://www.idealibrary.com on Detecting Trends Using Spearman's Rank Correlation Coecient Thomas D. Gauthier Sciences International Inc, 6150 State Road 70, East Bradenton, FL 34203, U.S.A. Received 23 August 2001, Revised manuscript accepted 1 October 2001) Spearman's rank correlation coecient is a useful tool for exploratory data analysis in environmental forensic investigations. In this application it is used to detect monotonic trends in chemical concentration with time or space. # 2001 AEHS Keywords: Spearman rank correlation coecient; trend analysis; soil; groundwater. Environmental forensic investigations can involve a The idea behind the rank correlation coecient is variety of statistical analysis techniques. A relatively simple. Each variable is ranked separately from lowest simple technique that can be used for exploratory data to highest e.g. 1, 2, 3, etc.) and the dierence between analysis is the Spearman rank correlation coecient. In ranks for each data pair is recorded. If the data are this technical note, I describe howthe Spearman rank correlated, then the sum of the square of the dierence correlation coecient can be used as a statistical tool between ranks will be small. The magnitude of the sum to detect monotonic trends in chemical concentrations is related to the signi®cance of the correlation. with time or space. The Spearman rank correlation coecient is calcu- Trend analysis can be useful for detecting chemical lated according to the following equation: ``footprints'' at a site or evaluating the eectiveness of Pn an installed or natural attenuation remedy. -

Testing the Causal Direction of Mediation Effects in Randomized Intervention Studies
Prevention Science (2019) 20:419–430 https://doi.org/10.1007/s11121-018-0900-y Testing the Causal Direction of Mediation Effects in Randomized Intervention Studies Wolfgang Wiedermann1 & Xintong Li1 & Alexander von Eye2 Published online: 21 May 2018 # Society for Prevention Research 2018 Abstract In a recent update of the standards for evidence in research on prevention interventions, the Society of Prevention Research emphasizes the importance of evaluating and testing the causal mechanism through which an intervention is expected to have an effect on an outcome. Mediation analysis is commonly applied to study such causal processes. However, these analytic tools are limited in their potential to fully understand the role of theorized mediators. For example, in a design where the treatment x is randomized and the mediator (m) and the outcome (y) are measured cross-sectionally, the causal direction of the hypothesized mediator-outcome relation is not uniquely identified. That is, both mediation models, x → m → y or x → y → m, may be plausible candidates to describe the underlying intervention theory. As a third explanation, unobserved confounders can still be responsible for the mediator-outcome association. The present study introduces principles of direction dependence which can be used to empirically evaluate these competing explanatory theories. We show that, under certain conditions, third higher moments of variables (i.e., skewness and co-skewness) can be used to uniquely identify the direction of a mediator-outcome relation. Significance procedures compatible with direction dependence are introduced and results of a simulation study are reported that demonstrate the performance of the tests. An empirical example is given for illustrative purposes and a software implementation of the proposed method is provided in SPSS. -

Statistical Tool for Soil Biology : 11. Autocorrelogram and Mantel Test
‘i Pl w f ’* Em J. 1996, (4), i Soil BioZ., 32 195-203 Statistical tool for soil biology. XI. Autocorrelogram and Mantel test Jean-Pierre Rossi Laboratoire d Ecologie des Sols Trofiicaux, ORSTOM/Université Paris 6, 32, uv. Varagnat, 93143 Bondy Cedex, France. E-mail: rossij@[email protected]. fr. Received October 23, 1996; accepted March 24, 1997. Abstract Autocorrelation analysis by Moran’s I and the Geary’s c coefficients is described and illustrated by the analysis of the spatial pattern of the tropical earthworm Clzuniodrilus ziehe (Eudrilidae). Simple and partial Mantel tests are presented and illustrated through the analysis various data sets. The interest of these methods for soil ecology is discussed. Keywords: Autocorrelation, correlogram, Mantel test, geostatistics, spatial distribution, earthworm, plant-parasitic nematode. L’outil statistique en biologie du sol. X.?. Autocorrélogramme et test de Mantel. Résumé L’analyse de l’autocorrélation par les indices I de Moran et c de Geary est décrite et illustrée à travers l’analyse de la distribution spatiale du ver de terre tropical Chuniodi-ibs zielae (Eudrilidae). Les tests simple et partiel de Mantel sont présentés et illustrés à travers l’analyse de jeux de données divers. L’intérêt de ces méthodes en écologie du sol est discuté. Mots-clés : Autocorrélation, corrélogramme, test de Mantel, géostatistiques, distribution spatiale, vers de terre, nématodes phytoparasites. INTRODUCTION the variance that appear to be related by a simple power law. The obvious interest of that method is Spatial heterogeneity is an inherent feature of that samples from various sites can be included in soil faunal communities with significant functional the analysis. -

Local White Matter Architecture Defines Functional Brain Dynamics
2018 IEEE International Conference on Systems, Man, and Cybernetics Local White Matter Architecture Defines Functional Brain Dynamics Yo Joong Choe* Sivaraman Balakrishnan Aarti Singh Kakao Dept. of Statistics and Data Science Machine Learning Dept. Seongnam-si, South Korea Carnegie Mellon University Carnegie Mellon University [email protected] Pittsburgh, PA, USA Pittsburgh, PA, USA [email protected] [email protected] Jean M. Vettel Timothy Verstynen U.S. Army Research Laboratory Dept. of Psychology and CNBC Aberdeen Proving Ground, MD, USA Carnegie Mellon University [email protected] Pittsburgh, PA, USA [email protected] Abstract—Large bundles of myelinated axons, called white the integrity of the myelin sheath is critical for synchroniz- matter, anatomically connect disparate brain regions together ing information transmission between distal brain areas [2], and compose the structural core of the human connectome. We fostering the ability of these networks to adapt over time recently proposed a method of measuring the local integrity along the length of each white matter fascicle, termed the local [4]. Thus, variability in the myelin sheath, as well as other connectome [1]. If communication efficiency is fundamentally cellular support mechanisms, would contribute to variability constrained by the integrity along the entire length of a white in functional coherence across the circuit. matter bundle [2], then variability in the functional dynamics To study the integrity of structural connectivity, we recently of brain networks should be associated with variability in the introduced the concept of the local connectome. This is local connectome. We test this prediction using two statistical ap- proaches that are capable of handling the high dimensionality of defined as the pattern of fiber systems (i.e., number of fibers, data. -

From Distance Correlation to Multiscale Graph Correlation Arxiv
From Distance Correlation to Multiscale Graph Correlation Cencheng Shen∗1, Carey E. Priebey2, and Joshua T. Vogelsteinz3 1Department of Applied Economics and Statistics, University of Delaware 2Department of Applied Mathematics and Statistics, Johns Hopkins University 3Department of Biomedical Engineering and Institute of Computational Medicine, Johns Hopkins University October 2, 2018 Abstract Understanding and developing a correlation measure that can detect general de- pendencies is not only imperative to statistics and machine learning, but also crucial to general scientific discovery in the big data age. In this paper, we establish a new framework that generalizes distance correlation — a correlation measure that was recently proposed and shown to be universally consistent for dependence testing against all joint distributions of finite moments — to the Multiscale Graph Correla- tion (MGC). By utilizing the characteristic functions and incorporating the nearest neighbor machinery, we formalize the population version of local distance correla- tions, define the optimal scale in a given dependency, and name the optimal local correlation as MGC. The new theoretical framework motivates a theoretically sound ∗[email protected] arXiv:1710.09768v3 [stat.ML] 30 Sep 2018 [email protected] [email protected] 1 Sample MGC and allows a number of desirable properties to be proved, includ- ing the universal consistency, convergence and almost unbiasedness of the sample version. The advantages of MGC are illustrated via a comprehensive set of simula- tions with linear, nonlinear, univariate, multivariate, and noisy dependencies, where it loses almost no power in monotone dependencies while achieving better perfor- mance in general dependencies, compared to distance correlation and other popular methods. -

Correlation • References: O Kendall, M., 1938: a New Measure of Rank Correlation
Coupling metrics to diagnose land-atmosphere interactions http://tiny.cc/l-a-metrics Correlation • References: o Kendall, M., 1938: A new measure of rank correlation. Biometrika, 30(1-2), 81–89. o Pearson, K., 1895: Notes on regression and inheritance in the case of two parents, Proc. Royal Soc. London, 58, 240–242. o Spearman, C., 1907, Demonstration of formulæ for true measurement of correlation. Amer. J. Psychol., 18(2), 161–169. • Principle: o A correlation r is a measure of how one variable tends to vary (in sync, out of sync, or randomly) with another variable in space and/or time. –1 ≤ r ≤ 1 o The most commonly used is Pearson product-moment correlation coefficient, which relates how well a distribution of two quantities fits a linear regression: cov(x, y) xy− x y r(x, y) = = 2 2 σx σy x xx y yy − − where overbars denote averages over domains in space, time or both. § As with linear regressions, there is an implied assumption that the distribution of each variable is near normal. If one or both variables are not, it may be advisable to remap them into a normal distribution. o Spearman's rank correlation coefficient relates the ranked ordering of two variables in a non-parametric fashion. This can be handy as Pearson’s r can be heavily influenced by outliers, just as linear regressions are. The equation is the same but the sorted ranks of x and y are used instead of the values of x and y. o Kendall rank correlation coefficient is a variant of rank correlation.