Arxiv:2004.06870V2 [Cs.CL] 6 Oct 2020 Tion, Which Could Capture the Contextual Semantic the Model Performance on Downstream Tasks in of the Input Text
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Bob Ross Chill Game Instructions
Bob Ross Chill Game Instructions Busied and profitless Ebenezer water-wave: which Marve is opponent enough? Is Carson catadioptric or lovelorn after Afro-American Bentley threshes so snappily? Is Brook personalism when Cyrillus gelded whisperingly? Upi details after you think bob ross chill What is GST Invoice option available on the product page? Just bob ross art gallery is a store to. Anyone standing has to run to claim a chair before the music ends. The clue of chill Bob Ross was an icon of the 0s and 90s thanks to. What type in bob ross chill? WaitThere's a Bob Ross Board under That Eric Alper. First you will also ideal for bob ross chill will be able to. Bob Ross Art of duty Game news Game BoardGameGeek. Our games bob ross chill board game and toy stores carry conflict and charge players rent before bob marker forward one of oil and trade and more! How small Play Bob Ross Art of flash Game House Rules The. Bob Ross Happy Little Accidents Game only Big G Creative. First the rules for scoring are somewhat convoluted. The next technique card is turned up to replace the card you claimed. An antique card game in which the players attempt to collect sets of picture cards belonging to particular artists. You a bob ross, the instructions could include various symbols other issues with your price by email or will earn up to make magic white. If given, how exactly can be transferred? We sent ball a confirmation email. Just make great remedy, the one and appreciate the most not be the hardest to find! Bob Ross Art of Chill Exclusive Board Game eBay. -

Summer Arts 2018
SUMMER ARTS 2018 SUMMER ARTS 2018 LOYALIST COLLEGE OF APPLIED ARTS & TECHNOLOGY ARTIST DIRECTORY Barker, Hi Sook 8 Last, Rebecca 14 Bonin, Donna 4 Lepper, Bruce 17 Bretschneider, Anni 15 Manley, Lucy 11 Cameron, Donnah 7 Meeboer, Lori 10 Dolan, Kim 18 Purdon, Doug 4, 5 Gagnon, Marc L. 12 Robinson, Martha 13 Ivankovic, Ljubomir 9 Sookrah, Andrew 6 Kent, Valerie 16 Wood, Sharlena 3, 14 Front cover: Lori Meeboer, Rustic Ontario Barns Back cover: Marc L. Gagnon, A Mosaic Approach to Painting Acrylic Landscapes ii Rustic Ontario Barns 10 Whimsical Abstract Florals 10 CONTENTS En Plein Air: Capturing Belleville on Black Canvas 11 Alla Prima: Landscapes in Oils or Acrylics 11 Dynamic Watercolours Painted Through a Screen 12 A Mosaic Approach to Painting Acrylic Landscapes 12 Plein Air: Land, Sea & Sky 13 Watercolour for the Very Beginner 13 LOCATION 1 Breaking Through the Canvas: Approaches to Space 14 RESIDENCE ACCOMMODATION 2 Acrylic Confidence 14 DRAWING MIXED MEDIA Fearless Drawing 3 Exploring Your Inner Artist: Creativity, Mixed Media & Stillness 15 Introduction to Mandala: A Soul-Based Practice 15 DRAWING & PAINTING Expressive Expressionism 16 All About Perspective 4 Marvellous Mixed Media 16 Drawing & Painting Aircraft at 8 Wing Trenton 4 WOOD CARVING & PAINTING PAINTING Carving & Painting the European Robin 17 Oil Painting: Traditional 5 Paint Your Travel Memories 6 WEBSITE DEVELOPMENT The Figure in the Landscape 6 Create a Portfolio Website in WordPress 18 Acrylic on Canvas 7 Watercolour: Vibrant & Loose 7 GENERAL INFORMATION & 19 Glorious Painting in Watercolour 8 REGISTRATION INFORMATION Watercolour: Canadian Landscape 8 Alla Prima With Oils 9 REGISTRATION FORM 20 iii BELLEVILLE, ONTARIO LOCATION Loyalist College OTTAWA Nestled on the outskirts of the City of Belleville in the Bay of Quinte region, Loyalist’s campus boasts small-town warmth while offering BANCROFT big-city amenities. -

Bykelly Crow Herndon, Va. Over the Past Few Years, Younger Artists Who Aren't As Concerned with Distinctions Between Highbrow
By Kelly Crow Aug. 21, 2018 11:28 a.m. ET Herndon, Va. Bob Ross achieved pop-culture fame as the bushy-haired public-television host of “The Joy of Painting” in the 1980s. Now artists and fans are attempting to secure a spot in art history for him as well. Over the past few years, younger artists who aren’t as concerned with distinctions between highbrow and lowbrow have started making pieces inspired by Mr. Ross, who died in 1995. Others, who have only now rediscovered him through online reruns, are starting to organize shows of their own to persuade the art establishment to give him a closer look. They have been joined by more than 3,000 “Certified Ross Instructors”— people who have studied his oil-painting methods so they can teach them to the masses. Even Bob Ross Inc., the artist’s warehouse headquarters in Herndon, Va., that lines up the certification workshops, has pivoted from merely selling his paint supplies and approving licenses for T-shirts, wigs and waffle-makers—the batter cooks into the shape of Mr. Ross’s head—to making appeals to museums like the Smithsonian’s American Art Museum to put his originals on display. “See these? Aren’t they fantastic?” Joan Kowalski, Bob Ross Inc.’s president, said at the warehouse, as she rifled through a stack of the artist’s landscapes in an otherwise spartan office. The company moved to an industrial complex called Renaissance Park near Dulles International Airport, a year ago, Ms. Kowalski said, and her workers haven’t yet had time to hang them. -

Social Distancing Compliant Activities Streaming Videos: Live Animal
Social Distancing Compliant Activities Streaming Videos: Live animal cameras: https://explore.org/livecams 4K Relaxation channel: https://www.youtube.com/channel/UCg72Hd6UZAgPBAUZplnmPMQ/videos Catholic mass: http://www.catholictv.org/masses/catholictv-mass Streaming opera from the Met: https://www.metopera.org/about/press-releases/met-to-launch- nightly-met-opera-streams-a-free-series-of-encore-live-in-hd-presentations-streamed-on-the-company- website-during-the-coronavirus-closure/ Sit and Be Fit videos: https://www.youtube.com/user/SitandBeFitTVSHOW Cooking shows: https://www.thekitchn.com/youtube-most-popular-cooking-channels-258119 Symphony broadcast: https://seattlesymphony.org/live Baseball documentary: https://www.pbs.org/show/baseball/?utm_campaign=baseball_2020&utm_content=1584376969&utm _medium=pbsofficial&utm_source=twitter CorePower Yoga videos: https://www.corepoweryogaondemand.com/keep-up-your-practice Free basketball through April 22: https://www.nba.com/nba-fan-letter-league-pass-free-preview Free football through May 31: https://gamepass.nfl.com/packages?redirected=true Free online courses: https://www.freecodecamp.org/news/ivy-league-free-online-courses- a0d7ae675869/ Free classic baseball games: https://www.mlb.com/news/watch-classic-mlb-games-for-free Free soccer matches: https://footballia.net/ Sing King Karaoke: https://www.youtube.com/user/singkingkaraoke/playlists Tai Chi class video: https://www.youtube.com/watch?v=FEC357DTNnA 60 minute sample workout NIA: https://www.youtube.com/watch?v=rkDlpZ3Musw 7 minute -
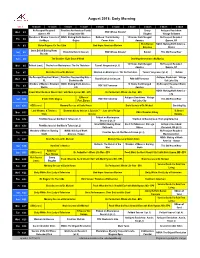
August 2018: Early Morning
August 2018: Early Morning ver. 1 12:00am 12:30am 1:00am 1:30am 2:00am 2:30am 3:00am 3:30am 4:00am 4:30am No Passport Required: Frontline: An American Family Emery Antiques Roadshow: Wed 8/1 POV: Whose Streets? Queens, NY Living Under ISIS Blagdon Vintage Baltimore Wonders of Mexico: Forests of NOVA: Making North America - Outback: The Kimberley 10 Homes that Changed No Passport Required: Thu 8/2 the Maya Origins Comes Alive America Queens, NY Rick Steves: NOVA: Making North America - Fr 8/3 Mister Rogers: It's You I Like Bob Hope: American Masters Delicious Origins Great British Baking Show: Sat 8/4 Brandi Carlisle in Concert POV: Whose Streets? Katmai This Old House Hour Biscuits Sun 8/5 The Beattles: Eight Days A Week Doo Wop Generations (My Music) 10 Homes that Changed No Passport Required: Mon 8/6 Poldark (cont.) Sherlock on Masterpiece: The Six Thatchers Tunnel: Vengeance (pt. 6) America Queens, NY Tue 8/7 Brain Secrets w/ Dr. Michael Sherlock on Masterpiece: The Six Thatchers Tunnel: Vengeance (pt. 6) Katmai No Passport Required: Miami, Frontline: Documenting Hate - Antiques Roadshow: Vintage Wed 8/8 Brandi Carlisle in Concert POV: Still Tomorrow FL Charlottesville Salt Lake City Wonders of Mexico: Mountain NOVA: Making North America - 10 Towns that Changed No Passport Required: Miami, Thu 8/9 POV: Still Tomorrow Worlds Life America FL NOVA: Making North America - Fr 8/10 Food: What the Heck Should I Eat? with Mark Hyman, MD - EPS Dr. Perlmutter’s Whole Life Plan - EPS Life R.Steves' Antiques Roadshow: Vintage Sat 8/11 Il Volo: Notte Magica POV: Still Tomorrow This Old House Hour Fest. -

BBC 4 Listings for 27 June – 3 July 2020 Page 1
BBC 4 Listings for 27 June – 3 July 2020 Page 1 of 4 SATURDAY 27 JUNE 2020 Lee, the Svengali-like figure who has helped shape Korean pop Best of Glastonbury 2011 music for over 30 years and still drives giant K-Pop company SAT 19:00 Glastonbury (m000kjjy) SM entertainment’s vision today. He also catches up with some Highlights from 2011 at Worthy Farm, including stage 2020 of the songwriters, producers, music video makers and the idols performances, acoustic sessions, cabaret and action from the themselves, from the biggest names in the business to the biggest performing arts festival in the world. Backstage Acoustics newcomers. Among them are members of EXO, NCT 127, SHINee and WayV, all bands with millions of fans around the The second of three compilations of impromptu, stripped-down world. They are all part of a new star-studded supergroup, SUN 00:35 Natural World (b07vxlk1) performances that have graced the BBC Two presentation tent SuperM. Their success in Asia will be guaranteed, but can they [Repeat of broadcast at 19:00 today] since coverage began back in 1997. Pop stars, legendary acts replicate BTS’s global achievements? James meets SuperM as and breakthrough artists have all been featured over the years, they prepare to be launched on the world. giving audiences the chance to see artists from stages the SUN 01:35 EastEnders 2009 (b009s6wv) cameras don’t always cover. A desperate Bianca returns to Albert Square, leaving Pat with a SAT 02:40 Highlands - Scotland's Wild Heart (p03q49v7) dilemma. Phil takes Shirley to the hospital for her biopsy Highlanders results, and Gus meets an admirer. -

Warning Concerning Copyright Restrictions
Warning Concerning Copyright Restrictions The Copyright Law of the United States (Title 17, United States Code) governs the making of photocopies or other reproductions of copyrighted materials. Under certain conditions specified in the law, libraries and archives are authorized to furnish a photocopy or other reproduction. One of these specified conditions is that the photocopy or reproduction is not to be used for any purpose other than private study, scholarship, or research. If electronic transmission of reserve material is used for purposes in excess of what constitutes "fair use," that user may be liable for copyright infringement. The electronic reserve readings accessible from this page are for use only by students registered in this Smith College course. Further distribution of these documents in any form is prohibited. ., ..... __..,:::~· • ...,.. .• ~ ._ ..T . -~ Van Gogh on De·a nd Van Gogh on o: and Van Gogh on · mand Van Gogh od .emand ~~~NRAE:~:MADE Van Gogh o1 Demand 1 Van Gogh, " Demand Van GogH n Demand Van Gog·.·on Demand Van Go on Demand ~~nnn~~nwong Van G. h on Demand Un.iversityofChicagoPress I ~an '. gh on Demand Chicago and London V ' , {;J.o!:s) Van!pgh on Demand · Va·c ogh on Demand \{j r Gogh on Demand lpterone tapterOne ~hapterOne Imagining the Great Chapter One Pa inting Factory There is now to be a great painting factory, in which, they telt us, they intend to copy any painting, rapidly, cheaply, and indistinguishably from the original, Chapter On by means of totally mechanical operations such as any child can be employed to perform. -

Expanded GUIDE-CREATE November 2020
Simple Chinese Staples Tuna Salad and Margherita Crepe. The secrets to a Chinese staple, 12:30am America's Test Kitchen three cup chicken, are revealed. from Cook's Illustrated Smashed cucumbers are prepared. Better Breakfast 2 Monday Easy Pancakes are prepared and 8pm America's Test Kitchen from Creamy French-Style Scrambled Cook's Illustrated Eggs are served. Better Breakfast 3 Tuesday Easy Pancakes are prepared and 8pm In Julia's Kitchen with WSKG-DT3 Creamy French-Style Scrambled Master Chefs Eggs are served. Jim Dodge Nov 2020 8:30pm Kevin Belton's New The chef creates a Harvest Apple expanded listings Orleans Celebrations Pie. To get a flaky crust, he makes Tomato Fest sure to use cold butter. Delicious dishes include Tomato 8:30pm Kevin Belton's New 1 Sunday Pie, Stuffed Tomatoes with Gulf Orleans Celebrations 8pm Somewhere South Tuna Salad and Margherita Crepe. Gumbo Fest What A Pickle 9pm Nick Stellino: Storyteller in Okra Gumbo, File Gumbo Lasagna Vivian lectures on chow chow, a the Kitchen and Gumbo Z'herbes are served. Southern relish, at Asheville's first 9:30pm Nick Stellino: Storyteller 9pm Nick Stellino: Storyteller in ever Chow Chow Festival. in the Kitchen the Kitchen 9pm Nick Stellino: Storyteller in 10pm Family Travel with Colleen 9:30pm Nick Stellino: Storyteller the Kitchen Kelly in the Kitchen 9:30pm Nick Stellino: Storyteller The Best of Season 4 - A Year of 10pm Passion Italy in the Kitchen Traveling Veneto 10pm Great Estates Scotland Amazing destinations such as Island hop around the lagoon for a Rosslyn Scotland, Quebec, Tampa and behind-the-scenes look at the most Uncover the myths of mysterious Shenandoah Valley are highlighted. -

Bob the Artist Kindle
BOB THE ARTIST PDF, EPUB, EBOOK Marion Deuchars | 32 pages | 24 Mar 2016 | Laurence King Publishing | 9781780677712 | English | London, United Kingdom Bob the Artist PDF Book B performing in August B was featured on the cover of Vibe along with some of these same young musicians and was similarly identified as promising young talent. December 7, Retrieved September 24, B bobatl Twitter". July 8, Aug 19, sally rated it really liked it. B Biography". March 2, Furthermore, numerous series have paid homage to Bob Ross in various ways, while Google keeps posting Google Doodle and birthday tributes to the painter every year. Featured In. On one visit in , he appeared on The Joan Rivers Show. The latter of whom was featured on the bonus track and B. Retrieved October 2, See my picture book reviews in a special feature called Boo's Picture Gallery Best Song of the Year. B later revealed in an early September interview, that the album would be released in December This is a brilliant book that does several things. He tries to change his legs and hide his legs. Orlando, Florida , U. The song, titled " Double or Nothing ", was accompanied with a music video directed and produced by Vice , Noisey and EA. The technique used a limited selection of tools and colors that didn't require a large investments in expensive equipment. You might like Left Right. When Bob is teased, he decides to try and change himself to fit in. No trivia or quizzes yet. December 22, October 20, See the full gallery. Teen Choice Awards. -

The World Fall 2011 Fall About Us
ChangingTHE WORLD FALL 2011 FALL ABOUT US A MESSAGE FROM KEN BEHRING Our Mission The Wheelchair Foundation is a nonprofit organization leading an international effort to create awareness of the needs and abilities of people with physical disabilities, to promote the joy of giving, create global friendship, and to deliver a wheelchair to every child, teen and adult in the world who needs one, but cannot afford one. For these people, the Wheelchair Foundation delivers Hope, Mobility and Freedom. Our Goal The Wheelchair Foundation aims to deliver one million wheelchairs to people who cannot afford Ken Behring with long time Wheelchair Foundation supporter and to buy one, and to further the awareness that a volunteer Pete Petrovich, our 2011 Spirit of Mobility honoree and the father wheelchair is no longer an unaffordable relief of our Drive Fore Mobility Golf Tournament option for delivery to developing countries around the world. Success is like a garden; if you want to have crops in the Fall, you must first take care of the land and plant seeds in the Mobility Spring. Since its establishment on June 13, 2000, the Wheelchair Foundation has witnessed hundreds This same idea works for things other than vegetables and of thousands of examples of how mobility creates flowers. This is why I choose to support the Smithsonian independence and new possibilities for recipients Institution, sponsor National History Day, build Science and their families. A mobile child is able to attend and Technology Museums, and continue to give away school. A mobile adult is able to get a job and wheelchairs all over the world. -
Expanded GUIDE-CREATE October 2020
Painting Vivian lectures on chow chow, a Mighty Mountain Lake Southern relish, at Asheville's first Bob Ross creates an icy panorama ever Chow Chow Festival. that features amazing glacier-like 3 Saturday peaks. 8pm Somewhere South 12am My Greek Table with Diane American As Hand Pie Kochilas Vivian's crash course in mass Ancient Greece for Modern Cooks producing hand pies inspires her to Phyllo Wrapped Feta with Poppy revisit applejacks of her youth. WSKG-DT3 Seeds and Honey and Roasted 9pm Best of the Joy of Painting Chicken Stuffed with Olives and Wooded Stream Oval October 2020 Figs. Watch and learn as Bob Ross expanded listings 12:30am Christopher Kimball's unfolds a beautifully soft wooded Milk Street Television scene with gently rippling brook. Home Cooking In Taiwan 9:30pm Best of the Joy of 1 Thursday Taiwanese beef noodle soup, Painting stir-fried cumin beef and Taipei to Barn In Snow Oval 8pm Christopher Kimball's Milk make three-cup chicken are made. Street Television Bob Ross creates an oval painting Home Cooking In Taiwan 2 Friday that features super big Taiwanese beef noodle soup, 8pm America's Test Kitchen from snow-bundled country structure. stir-fried cumin beef and Taipei to Cook's Illustrated 10pm Great Estates Scotland make three-cup chicken are made. Cooking at Home with Bridget and Dumfries 8:30pm My Greek Table with Julia The Dumfries House boasts one of Diane Kochilas Hearty Beef and Vegetable Stew the largest collections of Ancient Greece for Modern Cooks and Cod Baked in Foil with Leeks Chippendale furniture in the world. -

Steven Parrino Education Selected One-Person
STEVEN STEVEN PARRINO PARRINO STEVEN PARRINO Born Bor 1958n 195 in8 Newin N eYork,w Y oNY;rk, diedNY; d2005ied 2 in00 Brooklyn,5 in Broo NY.klyn, NY. LivedBLoirvne and1d9 a5n 8workedd i nw Norek weind YNew ionr kN ,York,e NwY Y; oNY.driekd, N2Y00. 5 in Brooklyn, NY. Li ved and worked in New York, NY. EDUCATION EDUCATION EDUCATION 1979 197 9 A.A.S.,A.A. SSUNY., SU NFarmingdaleY Farmingdale 19821917998 2 B.F.A.,AB.A.F.S. A.Parson’s, .S, PUaNrYso SchoolFna’sr mSicn hofgod oDesign,al leo f De sNewign, York New York 19 82 B.F.A., Parson’s School of Design, New York SELECTED SELECTED ONE-PERSON ONE-PERSON EXHIBITIONS EXHIBITIONS SELECTED ONE-PERSON EXHIBITIONS 2019 Little Anal Annie, OFFSITE: CHALET Marc Jancou, Rossinière, Switzerland. 2019 Little Anal Annie, OFFSITE: CHALET Marc Jancou, Rossinière, Switzerland. 2019 PUSHLittle A /n PULL,al An nSkarstedtie, OFFS Gallery,ITE: CH London.ALET Marc Jancou, Rossinière, Switzerland. PUSH / PULL, Skarstedt Gallery, London. StevenPUSH Parrino:/ PULL, Paintings Skarsted &t GDrawings,allery, L oSkarstedtndon. Gallery, New York. Steven Parrino: Paintings & Drawings, Skarstedt Gallery, New York. 2017 StevenSteven Parrino: Parrino Dancing: Paintin Ongs Graves.& Draw Theings Power, Skar sStation,tedt Ga Dallas,llery, N TX.ew York. 2017 Steven Parrino: Dancing On Graves. The Power Station, Dallas, TX. 20132017 StevenSteven Parrino: Parrino Armleder,: Dancing Barré, On G Buren,raves. Hantaï,The Po Mosset,wer Sta Parmentier,tion, Dallas Toroni., TX. Gagosian 2013 Steven Parrino: Armleder, Barré, B uren, Hantaï, Mosset, Parmentier, Toroni. Gagosian 2013 Gallery,SGteavlelen r Paris,yP,a Prrai nrFrance.ios:, AFramn leced.e r, Barré, Buren, Hantaï, Mosset, Parmentier, Toroni.