A Novel Mapreduce Classification Rule Discovery with Ant Colony
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Hydrochemical Response of Heilongtan Springs to the 2010
THE HYDROCHEMICAL RESPONSE OF HEILONGTAN SPRING TO THE 2010–2012 DROUGHTS OF YUNNAN PROVINCE, KUNMING, CHINA Hong Liu International Joint research Center for Karstology, Yunnan University, No. 5 Xueyun Road, Wuhua District, Kun- ming, Yunnan, 650223, China, [email protected]; School of Resource Environment and Earth Science, Yunnan University, Yunnan University Chenggong Campus, East Outer Ring Road, Chenggong District, Kunming 650500, China Ruiyong Chen School of Resource Environment and Earth Science, Yunnan University, Yunnan University Chenggong Campus, East Outer Ring Road, Chenggong District, Kunming 650500, China Huacheng Huang School of Resource Environment and Earth Science, Yunnan University, Yunnan University Chenggong Campus, East Outer Ring Road, Chenggong District, Kunming 650500 Yinghua Zhang School of Resource Environment and Earth Science, Yunnan University, Yunnan University Chenggong Campus, East Outer Ring Road, Chenggong District, Kunming 650500, China Yongli Gao Department of Geological Sciences, University of Texas at San Antonio, One UTSA Circle, San Antonio, Texas, 78249, USA, [email protected] Abstract 2010–December 2012 covering two complete hydro- Karst waters from a mountainous recharge area drains logic years were used to investigate the response of hy- toward basin and emerges at the edge of the basin af- drochemical changes to prolonged and severe droughts ter encountering quaternary sediments. The flow paths in Yunnan from 2010 to 2012. During the drought, in are partly covered by Quaternary sediments or other addition to the decline of water table, the EC of spring sedimentary rocks, which makes the spring acts as an decreased progressively from 319.5 μS/cm (yearly av- artesian spring. The spring is more vulnerable to hu- erage, ranging from 294.0 to 339.1 μS/cm) in 2010 to man activities and climate change than the classic con- 299.2 μS/cm (ranging from 248.9 to 323.3 μS/cm) in fined karst spring. -

I Am Thinking of Having an Hiv Test
What do I do if I THINK my rights have been violated? VCT SITES IN KUNMING I am thInkIng Yunnan CDC: No. 158 Dongsi Street, Kunming. Tel: 3611773. kunming CDC: No. 126 Tuqiaoli, Xichang Road, Kunming. of havIng an Tel: 2270135 2242074. CDC of Wuhua District: No. 15 Xinzhuantan, Xichang Road. Tel: 4140767. hIv test. CDC of Panlong District: No. 117 Tuodong Road. Tel: 3111423. CDC of Xishan District: 14th Building, Xinlong Residential Quarter, Xianyuan Road, Xishan District. Tel: 8236355. CDC of guandu District: No. 365 Shuangqiao Road, What Your decision to know Guanshang, Guandu District. Tel: 7185209. do I need to your HIV status is CDC of Dongchuan District: Southern Section of Baiyun Road, very important. Dongchuan District. Tel: 2130178. It means that you If you believe your rights know about my CDC of Chengong County: No. 4 Fukang Road, Longcheng value your health have been violated … Township, Chenggong County Tel: 6201108. rights? and the health and CDC of Jinning County: Tianxin Village, Kunyang Township. well being of your Contact Tel: 7892264. sexual and drug injecting Yunnan University Legal aid Center CDC of anning City: No. 121 Lianran Township, Anning City. partners, as well as your 4th floor, 184 gulou Road Tel: 6802001. families. Before you undergo kunming, Yunnan, China CDC of fumin County: No. 24 Western Ring Road, Fumin voluntary counseling and testing (VCT) telephone: 0871-5182720 County. Tel: 8811204. email: [email protected] please read through this leaflet to learn CDC of Luquan County: No. 498 Wu Xing Road, Pinshan about your legal rights and responsibilities. -
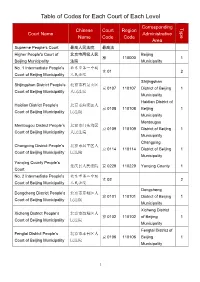
Table of Codes for Each Court of Each Level
Table of Codes for Each Court of Each Level Corresponding Type Chinese Court Region Court Name Administrative Name Code Code Area Supreme People’s Court 最高人民法院 最高法 Higher People's Court of 北京市高级人民 Beijing 京 110000 1 Beijing Municipality 法院 Municipality No. 1 Intermediate People's 北京市第一中级 京 01 2 Court of Beijing Municipality 人民法院 Shijingshan Shijingshan District People’s 北京市石景山区 京 0107 110107 District of Beijing 1 Court of Beijing Municipality 人民法院 Municipality Haidian District of Haidian District People’s 北京市海淀区人 京 0108 110108 Beijing 1 Court of Beijing Municipality 民法院 Municipality Mentougou Mentougou District People’s 北京市门头沟区 京 0109 110109 District of Beijing 1 Court of Beijing Municipality 人民法院 Municipality Changping Changping District People’s 北京市昌平区人 京 0114 110114 District of Beijing 1 Court of Beijing Municipality 民法院 Municipality Yanqing County People’s 延庆县人民法院 京 0229 110229 Yanqing County 1 Court No. 2 Intermediate People's 北京市第二中级 京 02 2 Court of Beijing Municipality 人民法院 Dongcheng Dongcheng District People’s 北京市东城区人 京 0101 110101 District of Beijing 1 Court of Beijing Municipality 民法院 Municipality Xicheng District Xicheng District People’s 北京市西城区人 京 0102 110102 of Beijing 1 Court of Beijing Municipality 民法院 Municipality Fengtai District of Fengtai District People’s 北京市丰台区人 京 0106 110106 Beijing 1 Court of Beijing Municipality 民法院 Municipality 1 Fangshan District Fangshan District People’s 北京市房山区人 京 0111 110111 of Beijing 1 Court of Beijing Municipality 民法院 Municipality Daxing District of Daxing District People’s 北京市大兴区人 京 0115 -

Kunming South HSR Integrated Development Next to Kunming South HSR Station, a Key HSR Station in China
Disclaimer All statements contained in this presentation which are not statements of historical fact constitute “forward looking statements”. These forward-looking statements, including without limitation, those regarding Perennial Real Estate Holding Limited’s financial position and results, business strategy and plans and objectives of management for future operations involve known and unknown risks, uncertainties and other factors which may cause Perennial Real Estate Holdings Limited’s actual results, performance or achievements to be materially different from any future results, performance or achievements expected, expressed or implied by such forward-looking statements. Given the risks and uncertainties that may cause the actual future results, performance or achievements to be materially different from those expected, expressed or implied by the forward-looking statements in this presentation, you are advised not to place undue reliance on these statements. 2 Contents 3 4 Overview of the Investment Perennial-Led JV Vehicle Invests in Kunming South HSR Integrated Development Next to Kunming South HSR Station, a Key HSR Station in China . Perennial Real Estate Holdings Limited (“Perennial”), through its 45% owned joint venture vehicle, Perennial HC Holdings Pte. Ltd. (“JV Vehicle”), has been awarded the tender by the People’s Government of Chenggong District (呈贡区), Kunming, Yunnan Province to develop two plots of land with a total land area of approximately 65,054 square metres (“sqm”) which are sited next to the Kunming South High Speed Railway (“HSR”) Station (“Kunming South HSR Integrated Development 昆明南站综 合项目”) at a land tender price of RMB341.5 million (approximately S$67.6 million )1. Kunming South HSR Integrated Development has a maximum allowable Gross Floor Area (“GFA”) of approximately 627,6002 sqm and will be developed into a one-stop regional healthcare and commercial hub comprising medical care, eldercare, hospitality, meetings, incentives, conferences and exhibitions (“MICE”) and retail components. -

Affectionate Ballads” in Wuhua District, Kunming City
Journal of Frontiers in Art Research DOI: 10.23977/jfar.2021.010216 Clausius Scientific Press, Canada Volume 1, Number 2, 2021 Analysis on the Context of Four Pieces of “Affectionate Ballads” in Wuhua District, Kunming City Zhao Ying-na Yunnan Art University Wenhua College, Kunming 650000, China Keywords: Analysis, Context, Affectionate ballads Abstract: Kunming is the political, economic and cultural center of Yunnan Province. With the integration of customs and cultures of different ethnic groups in this urban area, the local folk music system has developed its distinctive musical context in terms of musical patterns, emotions or notions. In this paper, four pieces of “affectionate ballads” in Wuhua District, Kunming are taken as the example to explore the musical context that is unique in Kunming ballads. By analyzing the musical context, the paper attempts to interpret the musical functions and values contained in these “affectionate ballads” of Kunming’s folk music system. 1. Introduction Kunming is a multiethnic city. 26 ethnic groups have dwelled in the city for generations, among which Han, Yi, Hui, Bai, Miao, Hani, Zhuang, Dai and Lisu groups form their ethnic villages, or different groups live together in a villages or street. During the long period of production and living activities, they are mingling with each other while their own traditions, living styles, customs and cultural arts are still conserved. In Kunming, there are many genres of literature and arts, such as Dian drama, Huadeng opera, folk ballads and minority dramas, folk narrative poems and legends. After centuries of development, these literature and arts have become very popular in the public. -

Delineation of the Urban-Rural Boundary Through Data Fusion: Applications to Improve Urban and Rural Environments and Promote Intensive and Healthy Urban Development
International Journal of Environmental Research and Public Health Article Delineation of the Urban-Rural Boundary through Data Fusion: Applications to Improve Urban and Rural Environments and Promote Intensive and Healthy Urban Development Jun Zhang * , Xiaodie Yuan, Xueping Tan and Xue Zhang School of Architecture and Planning, Yunnan University, Kunming 650500, China; [email protected] (X.Y.); [email protected] (X.T.); [email protected] (X.Z.) * Correspondence: [email protected] Abstract: As one of the most important methods for limiting urban sprawl, the accurate delineation of the urban–rural boundary not only promotes the intensive use of urban resources, but also helps to alleviate the urban issues caused by urban sprawl, realizing the intensive and healthy development of urban cities. Previous studies on delineating urban–rural boundaries were only based on the level of urban and rural development reflected by night-time light (NTL) data, ignoring the differences in the spatial development between urban and rural areas; so, the comprehensive consideration of NTL and point of interest (POI) data can help improve the accuracy of urban–rural boundary delineation. In this study, the NTL and POI data were fused using wavelet transform, and then the urban–rural boundary before and after data fusion was delineated by multiresolution segmentation. Finally, the delineation results were verified. The verification result shows that the accuracy of Citation: Zhang, J.; Yuan, X.; Tan, X.; delineating the urban–rural boundary using only NTL data is 84.20%, and the Kappa value is Zhang, X. Delineation of the 0.6549; the accuracy using the fusion of NTL and POI data on the basis of wavelet transform is Urban-Rural Boundary through Data 93.2%, and the Kappa value is 0.8132. -

Detailed Conference Program Day1
G M S - ICPH8: Detail ed Conference Program Detail ed Conference Program The 8 th Inte rnational Conference on Public H ealth among GMS C ountries Moving toward the Universal Health Coverage: Strengthening Quality of Care SOKHA HOTEL, PHNOM PENH CAMBODIA November 05 - 06, 2016 Day1: 5 th November, 2016 R egistration and Ope ning Ceremony Time: 7:00 – 08 :00 Room: Ball Room 07:30 - 08:00 Arrival of the delegates 08:00 - 08:15 Traditional dance Welcome Remark & introduction about the conference 08:15 - 08:20 Assoc. Prof. Chhea Chhorvann , NIPH Director Opening remark 08:20 - 08:30 H.E. Dr. Mam Bun Heng , Minister of Health Plenary Session 1 Time: 09:00 – 10 : 3 0 Room: Ball Room Moderator: Dr. Robert Newman, Country Director , U.S Centers for Disease Control and Prevention (Cambodia) UHC and SDGs: Concepts and Measurement 09:00 - 09:30 Dr. Vivian Lin Director of Health Systems Division of the WHO Western Pacific Regional Office Academic Institution: How to Achieve UHC: Global Lessons 09:30 - 10.00 Prof. Werner Soors ITM, Belgium MOH Cambodia: UHC in Cambodian Health P olicy and Health Strategic Plan Dr. Lo Veasna Kiry 10:00 - 10:30 Director of Department of Planning and Health Information Department , MoH Cambodia 1 G M S - ICPH8: Detail ed Conference Program Coffee Break Time: 10:3 0 – 11 : 0 0 Parall el Session: Oral Presentation 1 Track : Burden of Diseases, Communicable Diseases 1 Room Malis Routh Time 11:00 – 12: 30 Chair : Assoc. Prof. Wongsa Laohasiriwong Khon Kaen University, Thailand Co - Chair Prof. -

International Journal of Business Anthropology
International Journal of Business Anthropology ISSN 2155-6237 Editor-in-Chief Gang Chen North American Business Press, Inc. Atlanta - Seattle – South Florida - Toronto Volume 8(2) ISSN 2155-6237 Authors have granted copyright consent to allow that copies of their article may be made for personal or internal use. This does not extend to other kinds of copying, such as copying for general distribution, for advertising or promotional purposes, for creating new collective works, or for resale. Any consent for republication, other than noted, must be granted through the publisher: North American Business Press, Inc. Atlanta - Seattle – South Florida – Toronto ©International Journal of Business Anthropology 2019 Sponsors: School of History and Culture, Jishou University The College of Sociology and Anthropology, Sun Yat-Sen University The Institute of Business Anthropology, Shantou University; Center for Social and Economic Behavior Studies, Yunnan University of Finance and Economics, China. For submission, subscription or copyright information, contact: [email protected] Individual Subscription: US$ 99 per year. Institutional Subscription: US$ 199 per year. Our journals are indexed by UMI-Proquest-ABI Inform, EBSCOHost, GoogleScholar, and listed with Cabell's Directory of Periodicals, Ulrich's Listing of Periodicals, Bowkers Publishing Resources, the Library of Congress, the National Library of Canada, and Australia's Department of Education Science and Training. Furthermore, our journals have been used to support the Academically Qualified (AQ) faculty classification by all recognized business school accrediting bodies. (ii) Editors: Founding Editors: Dr. Kanglong Luo Dr. Robert Guang Tian Dr. Dipak R. Pant Dr. Daming Zhou Dr. Sarah Lyon Dr. Alfons H. van Marrewijk Dr. -

Yunnan WLAN Hotspots 1/15
Yunnan WLAN hotspots NO. SSID Location_Name Location_Type Location_Address City Province 1 ChinaNet CuiHu and the surrounding area on foot Others CuiHu and the surrounding area on foot Kunming Yunnan 2 ChinaNet Hongta Sports Training Base Others Hongta Sports Training Base Kunming Yunnan 3 ChinaNet Center for Business Office Others No. 439 Beijing Road Kunming Kunming Yunnan 4 ChinaNet TaiLi business hall Others No. 39 South ring Road, Kunming City Kunming Yunnan 5 ChinaNet However, even the tranquility Board business hall Others However, even the town of Anning City even Ran Street No. 201 Kunming Yunnan 6 ChinaNet Dongchuan Village Road business hall Others Dongchuan Village Road, on the 17th Kunming Yunnan 7 ChinaNet Kunyang business hall Others Jinning County Kunyang the middle of the street Kunming Yunnan 8 ChinaNet Closing the business hall Others South Guandu District of Kunming customs in the next one (no No.) Kunming Yunnan 9 ChinaNet Songming county hall Others Songming County Huanglongbing Street I Kunming Yunnan 10 ChinaNet XUNDIAN Board Office of new business Others The new county transit roadside Telecom Tower, 1st Floor, (no number) Kunming Yunnan 11 ChinaNet New Asia Sports City stadium area Press Release Exhibition&stadium center Kunming Kwong Fuk Road and KunRei Road Kunming Yunnan 12 ChinaNet Kunming train the new South Station Hou car Room Railway Station/Bus Station Beijing Road South kiln Kunming Yunnan 13 ChinaNet Kunming Airport Airport KunMing Wujiaba Kunming Yunnan 14 ChinaNet Huazhou Hotel Hotel 223 East Road, Kunming City Kunming Yunnan 15 ChinaNet Kam Hotel Hotel 118 South Huan Cheng Road Kunming Kunming Yunnan 16 ChinaNet Greek Bridge Hotel Hotel Kunming Jiangbin West Road on the 1st Kunming Yunnan 17 ChinaNet Tyrone Hong Rui Hotel Hotel Kunming Spring City Road, No. -

Evaluation and Monitoring of Urban Public Greenspace Planning Using Landscape Metrics in Kunming
sustainability Article Evaluation and Monitoring of Urban Public Greenspace Planning Using Landscape Metrics in Kunming Min Liu 1,2, Xiaoma Li 3, Ding Song 4 and Hui Zhai 1,* 1 Faculty of Architecture and City Planning, Kunming University of Science and Technology, Kunming 650500, China; [email protected] 2 College of Landscape Architecture and Horticulture Sciences, Southwest Forestry University, Kunming 650224, China 3 College of Landscape Architecture and Art Design, Hunan Agricultural University, Changsha 410128, China; [email protected] 4 Campus Greening Center, Kunming University of Science and Technology, Kunming 650500, China; [email protected] * Correspondence: [email protected]; Tel.: +86-0871-6591-7181 Abstract: Urban greenspace planning plays a crucial role in improving the quality of human settle- ments and the living standard of citizens. Urban public greenspace (UPGS) is an important part of urban greenspaces. Existing literature rarely includes a scientific evaluation of greenspace plans (including of UPGS) and plan implementation effects. To bridge this gap, this study evaluated and monitored the UPGS plan enacted in 2010 in Kunming, China. Object-based image classification and visual interpretation of satellite images and Google Earth imagery were used to quantify the different periods of UPGS implementation. Six indicators and monitoring at four classic sites were applied to explore the change at two scales (overall scale and district scale) for monitoring the UPGS plan execu- tion. The results showed that UPGS structure greatly improved after plan implementation. However, Citation: Liu, M.; Li, X.; Song, D.; UPGS provision per capita has not reached the level of greenspace planning and the connectivity Zhai, H. -

Download Article (PDF)
International Conference on Engineering Management, Engineering Education and Information Technology (EMEEIT 2015) Measuring the Increase and Loss of the Public Facility Welfare ——A Case of Kunming City Fan Jun1 Xu Ning1 12013 doctoral students,School of Earth Sciences and Resources , China University of Geosciences, Beijing. Zip code, 100083. 2CECEP New Material Investment Co., Ltd. Zip code, 100082. KEY WORD:Public welfare facilities; space welfare; spatial differentiation ABSTRACT: The welfare of public facilities space is part of residential space welfare. The spatial difference of public facilities causes the difference of public facilities space welfare and the spatial differentiation. In this paper, the establishment of public facilities space welfare maximization model is combined with the Kunming regional characteristics, and then the largest public welfare facilities configuration space is determined. Introduction With the development of society, on the one hand there exists social differentiation, and the spatial differentiation emerged on the other hand. In the meanwhile, when spatial differentiation develops to a certain stage, it may lead to spatial mismatch. Spatial mismatch hypothesis, originally proposed by Kain (1968), it discussed that the employment dispersion of American cities contributed to African Americans’ low-income and high unemployment phenomenon. The study included Ellwood (1986); Ihlanfeldt and Sjoquist (1990, 1991); Ihlanfeldt (1992), (1993); Holzer ect (1994); Zax and Kain (1996), who focused on living environment and employment of vulnerable groups [1] - [7]; Brueckner (1997) analyzes the equilibrium under the spatial mismatch [8]. In China, the number of researchers were relatively few, they are Zhou Jiangping(2004), Li Chunbin (2006), Qian Yingying (2007), Zheng Siqi (2007) and Ma Guanghong (2008) and so on. -

Analysis of Internal Transcribed Spacer Regions II Gene and Morphology of Paragonimus from Yunnan Province, China
Analysis of Internal Transcribed Spacer Regions II Gene and Morphology of Paragonimus From Yunnan Province, China Binbin Yang ( [email protected] ) Weifang Medical University https://orcid.org/0000-0003-0041-0715 Juan Li Kunming medical University, School of Basic Medicine Benjiang Zhou Kunming Medical University, School of Basic Medicine Research Keywords: Paragonimus, Pagumogonimus skrjabini, Jinping country, Baoshan city Posted Date: July 15th, 2021 DOI: https://doi.org/10.21203/rs.3.rs-699536/v1 License: This work is licensed under a Creative Commons Attribution 4.0 International License. Read Full License Page 1/19 Abstract For a long time, there is no clear-cut to identify some species of paragonimus in Yunnan Province, China. This paper involved the distribution of Paragonimus in Jinping country and Baoshan city, Yunnan province. In this experiment, the metacercariae, excysted metacercariae, eggs, adult worms were obtained from different hosts were observed and measured. Cats have been described as the appropriate denitive host of paragonimus sp., which are closed to P. cheni according to morphology. Especially the ovaries of adult worms are few and has no third branches. With SEM observation, their spines in the surface are single, a sharp-pointed knife or half-moon in shape and the end of a few of spines are bifurcate. While the clustered sequences strains of this study in the ITS2 tree clustered of Yunan is out sider of P. skirjabini complex and have the genetically greater distances than other isolates of the P. skrjabini complex. Therefore, the Paragonimus sp. of this study from Jinping County and Baoshan city are the same subspecies of P.